




Entendendo o Sharding de Banco de Dados

Entendendo o Sharding de Banco de Dados
Os sites e aplicações modernos dependem fortemente das tecnologias de base de dados para lidar com pedidos de leitura e escrita de vários utilizadores. No entanto, à medida que a popularidade de uma aplicação aumenta, o número de utilizadores aumenta e torna-se difícil fornecer uma experiência óptima ao cliente devido a falhas frequentes na base de dados.
Então, como é que os programadores podem aumentar a escala das suas bases de dados para responder à crescente procura? Embora a resposta possa variar consoante o caso de utilização, a fragmentação da base de dados é um método simples e económico. É fácil de implementar e oferece melhorias significativas no desempenho.
Apesar da sua simplicidade, a fragmentação de bases de dados pode ser um conceito confuso. Esta publicação explicará o seu significado, técnicas de implementação, alternativas, vantagens e desafios e casos de utilização para o ajudar a compreender quando e como aplicar o método de fragmentação mais adequado.
O que é fragmentação de banco de dados?
O sharding de banco de dados divide um banco de dados extenso em pedaços menores chamados shards e os distribui em várias máquinas. Cada máquina usa a mesma tecnologia, trabalhando em paralelo para processar grandes volumes de dados.
É um dos muitos métodos para ajudar a acelerar o processamento de dados e garantir [alta disponibilidade] (https://zilliz.com/learn/ensuring-high-availability-of-vetor-databases). Se uma única máquina ou servidor de base de dados falhar devido a uma sobrecarga de pedidos, os outros servidores podem continuar a processar pedidos de leitura e escrita, mantendo uma experiência de utilizador sem problemas.
No entanto, o sharding só funciona enquanto os dados estiverem disponíveis e acessíveis. Ele permite que os desenvolvedores distribuam organicamente a carga de trabalho e reduzam a latência.
A replicação e o particionamento são outras técnicas para evitar o tempo de inatividade. Estes métodos são mais apropriados para bases de dados mais pequenas. A replicação envolve a cópia de uma base de dados inteira em vários servidores, enquanto o particionamento divide uma base de dados e armazena-a numa única máquina. As secções seguintes explicarão estas abordagens com mais pormenor.
Como funciona o Sharding de banco de dados?
Sharding é uma forma de escalonamento horizontal em que os desenvolvedores instalam nós ou servidores adicionais para armazenar várias partições de dados. Cada partição torna-se uma tabela independente que partilha o mesmo esquema que a base de dados original. No entanto, as informações em cada shard são únicas e os desenvolvedores armazenam os pedaços individuais em vários computadores, chamados de nós.
Por exemplo, a tabela seguinte ilustra uma única base de dados que representa informações sobre clientes e os artigos que compraram.
| ID do cliente** | Nome | Item comprado |
| 10001 | A | Camisa |
| 10002 | B | Boné |
| 10003 | C | Camisa |
| 10004 | D | Sapatos |
Um desenvolvedor pode usar o sharding de banco de dados para dividir o banco de dados em partições menores, chamadas de shards lógicos, em máquinas separadas ou shards físicos.
**Servidor 1
| ID do cliente** | Nome** | Item comprado** |
| 10001 | A | Camisa |
| 10002 | B | Boné |
Servidor 2
| ID do cliente** | Nome** | Item comprado** |
| 10003 | C | Camisa |
| 10004 | D | Sapatos |
O Sharding funciona numa arquitetura de partilha de nada, em que um único nó num cluster de computadores processa os pedidos dos utilizadores de forma independente. Quando um utilizador tenta aceder à base de dados, apenas o fragmento que contém as informações do utilizador fica ativo e processa o pedido recebido.
Os programadores dividem os dados em fragmentos lógicos utilizando uma chave de fragmento. Podem selecionar a chave com base numa coluna que organiza os dados em grupos ou criar uma nova. As secções seguintes explicam como funciona uma chave de fragmentação e ajudam a desenvolver grupos de dados para uma fragmentação eficiente.
Métodos de fragmentação
Os desenvolvedores podem implementar várias técnicas de fragmentação com base no caso de uso e na natureza dos dados que desejam processar. Os métodos populares incluem fragmentação baseada em intervalo, fragmentação com hash, fragmentação de diretório e fragmentação geográfica.
Sharding baseado em intervalo
A fragmentação baseada em intervalo ou dinâmica divide um banco de dados em fragmentos com base em um intervalo de valores específico. O diagrama abaixo ilustra como um programador pode dividir uma tabela em fragmentos utilizando um intervalo de preços.
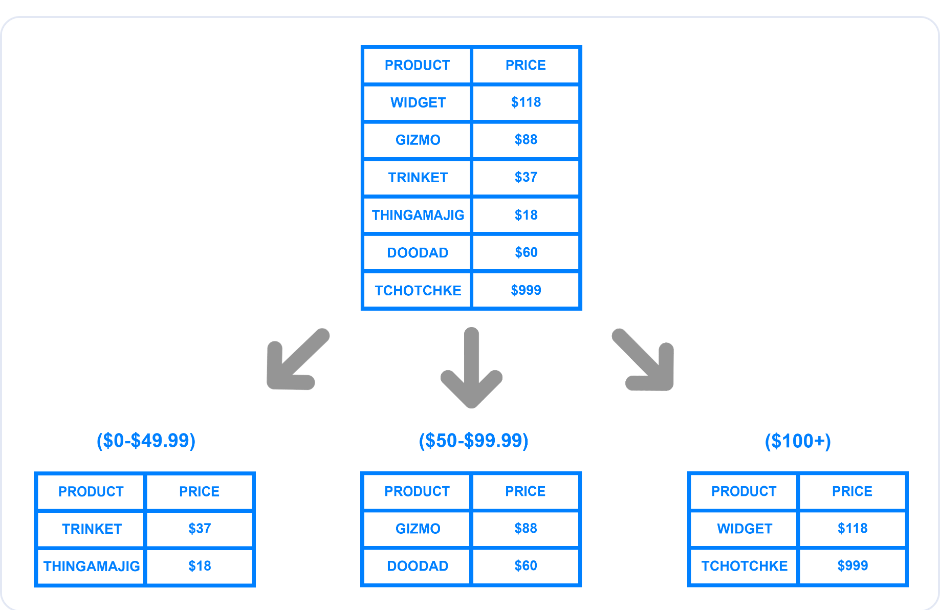 Fragmentação baseada em intervalo com base em preço.png
Fragmentação baseada em intervalo com base em preço.png
Fragmentação baseada em intervalo com base no preço_
O exemplo mostra três shards lógicos criados usando intervalos de preços. O desenvolvedor pode atribuir a cada pedaço uma chave de shard exclusiva e armazená-los em shards físicos ou máquinas separadas. Ao escrever um registo na base de dados, o sistema determinará o fragmento adequado ao qual os dados pertencem com base no intervalo de preços e actualizá-lo-á em conformidade.
Embora a implementação da fragmentação dinâmica seja simples, pode sobrecarregar um determinado fragmento se este contiver mais registos do que outros. No exemplo acima, se mais clientes comprarem itens com um preço superior a $100, o volume de dados no terceiro fragmento será maior do que o volume nos outros.
A distribuição desigual pode anular o objetivo da fragmentação, uma vez que apenas um único fragmento conterá a maior parte dos dados, provocando a lentidão do sistema. Além disso, o método requer uma tabela de pesquisa que armazena a chave única do fragmento e os intervalos correspondentes.
Sharding Hashed
O sharding com hash atribui uma chave de hash a cada registro com base em uma coluna específica. Os desenvolvedores geram chaves de hash usando uma função de hash que usa os valores na coluna como entrada. Eles podem dividir os dados determinando os registros que pertencem a uma chave ou valor de hash correspondente.
Por exemplo, os programadores podem selecionar uma coluna e utilizar os seus valores para gerar valores de hash. Esses valores podem servir como a chave de fragmento para cada pedaço, e os desenvolvedores podem armazená-los em máquinas diferentes. O diagrama abaixo ilustra o processo.
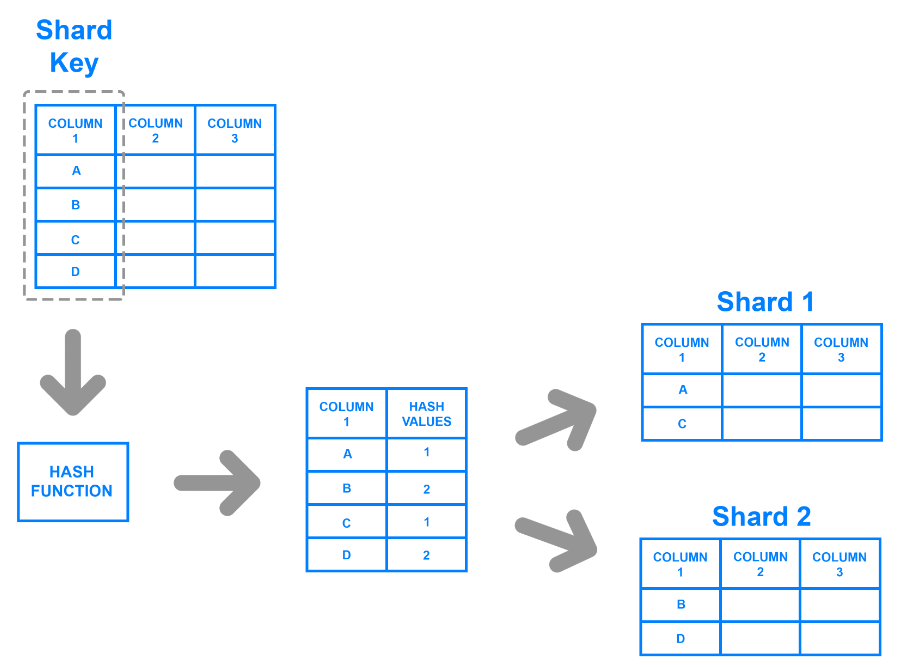 Hashed sharding.png
Hashed sharding.png
A fragmentação com hash resolve o problema da distribuição desigual, uma vez que a função ou algoritmo de hashing não necessita de uma chave de fragmentação definida pelo utilizador para particionar os dados. No entanto, torna-se difícil consultar dados de fragmentos individuais, uma vez que as chaves não agrupam os dados com base em nenhum critério significativo. Um algoritmo gera aleatoriamente os valores de hash e divide os dados de forma ad-hoc.
Por exemplo, na fragmentação baseada em intervalos, as chaves reflectem os intervalos de um determinado valor na tabela e relacionam-se com a estrutura de dados de forma mais significativa. Consultar fragmentos com base em intervalos de valores é mais rápido do que consultar dados com base em chaves de hash.
Além disso, a adição de mais fragmentos ou a atualização dos sistemas exige que o programador volte a executar todo o algoritmo de hashing em todos os registos. Este processo é necessário para equilibrar o volume de dados entre as máquinas, mas pode implicar um tempo de inatividade e recursos informáticos significativos.
Sharding de diretório
A fragmentação de diretório é mais flexível do que os métodos discutidos acima. Ele divide os dados com base nos valores de uma coluna específica e usa uma tabela de pesquisa para determinar a qual shard um registro pertence.
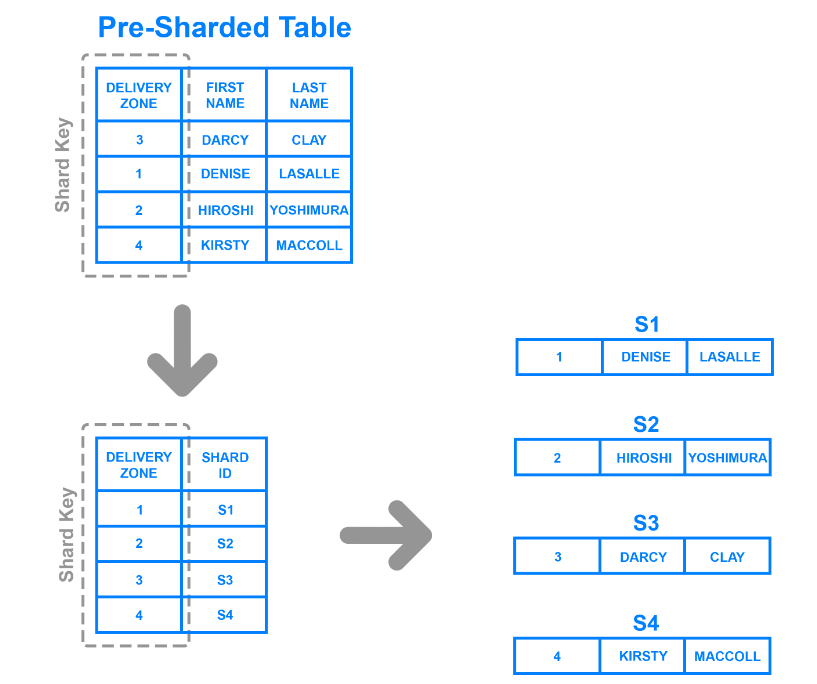 Fragmentação de diretório com base na zona de entrega.png
Fragmentação de diretório com base na zona de entrega.png
Directory sharding based on delivery zone
Por exemplo, a ilustração mostra como usar a coluna Zona de entrega como a chave do fragmento e dividir os dados de acordo com as zonas às quais um cliente pertence. O método criou quatro shards distintos, pois a tabela tem quatro zonas.
Ao contrário da fragmentação baseada em intervalos, as partições de dados são mais versáteis, uma vez que não têm de aderir a intervalos de valores rigorosos. Além disso, permite que os programadores actualizem os fragmentos mais rapidamente, uma vez que não têm de gerar chaves algoritmicamente para todos os valores de uma determinada coluna.
No entanto, a técnica requer uma tabela de pesquisa para atender às solicitações de entrada, diminuindo a velocidade de processamento. Além disso, a seleção de uma coluna que resulta num número extenso de fragmentos pode aumentar significativamente o tamanho da tabela de pesquisa e a latência.
Selecionando uma chave de fragmento
A fragmentação eficiente do banco de dados exige que os desenvolvedores determinem uma chave de fragmentação apropriada para garantir a distribuição igual dos dados entre os fragmentos. Em uma distribuição desigual, shards específicos podem se tornar hotspots de dados contendo mais dados do que outros.
A chave de fragmentação também deve simplificar o processo de consulta para aumentar a velocidade de processamento e evitar o tempo de inatividade. Além disso, a determinação de uma chave de fragmento adequada depende da seleção da coluna correta.
A lista abaixo destaca três factores importantes que os programadores podem considerar ao escolher a coluna mais adequada para gerar a chave de fragmento.
- Cardinalidade:** A cardinalidade especifica o número máximo de fragmentos que um desenvolvedor pode criar com base em valores distintos em uma coluna. Por exemplo, a seleção de uma coluna contendo três valores distintos resultará em três fragmentos. A fragmentação baseada em diretório é útil quando a cardinalidade de uma coluna é baixa.
- Frequência:** A frequência refere-se à porcentagem de dados pertencentes a uma chave de fragmento específica. Por exemplo, na fragmentação baseada em intervalos de preços, intervalos de preços específicos podem conter cerca de 80% do total de registos, resultando num hotspot de dados.
- Shards dinâmicos:** O volume de dados em shards dinâmicos muda à medida que a demanda por um aplicativo muda. Por exemplo, à medida que a aplicação se torna popular, a demografia dos utilizadores pode mudar, e as inscrições de clientes na faixa etária dos 20-25 anos podem aumentar. O sharding baseado em faixa etária pode resultar em um hotspot de dados, pois mais dados estarão presentes no shard correspondente à faixa etária de 20 a 25 anos.
Para garantir uma fragmentação eficaz da base de dados, os programadores devem considerar a cardinalidade e a frequência de uma chave de fragmentação e determinar se esta resultará em fragmentações dinâmicas.
Comparação com alternativas
O sharding de banco de dados é um método para dimensionar bancos de dados. Outros métodos incluem escalonamento vertical, replicação e particionamento. Entender como eles diferem do sharding ajudará os desenvolvedores a usar o método de dimensionamento correto para cenários específicos.
Escalonamento vertical
O dimensionamento vertical envolve a atualização da capacidade de um servidor existente. Os desenvolvedores podem instalar CPUs adicionais, discos rígidos e outros softwares para melhorar o desempenho.
O método ajuda nos casos em que uma única máquina é adequada para lidar com os pedidos dos utilizadores e apenas são necessárias melhorias incrementais para aumentar o desempenho.
Embora seja menos dispendioso do que a fragmentação, apenas aumenta a capacidade do servidor de forma limitada, uma vez que apenas uma única máquina está disponível para processar os pedidos dos utilizadores.
Replicação
A replicação ocorre quando os programadores fazem cópias da mesma base de dados e armazenam-nas em vários computadores. Assim como o sharding, o método garante alta disponibilidade, pois se um computador falhar, os outros permanecem ativos.
A fragmentação e a replicação são semelhantes, pois distribuem o processamento em várias máquinas. No entanto, a fragmentação divide os dados em várias partes, enquanto a replicação copia os dados completos sem os dividir.
A fragmentação é mais adequada para grandes bases de dados, uma vez que a replicação requer servidores com elevada capacidade de armazenamento. A manutenção e atualização de cada réplica em máquinas diferentes é dispendiosa e morosa.
Particionamento
O particionamento divide um banco de dados em vários grupos e os armazena em uma única máquina. O método é adequado quando se pretende melhorar o desempenho da consulta e o tamanho da base de dados não é suficientemente grande para justificar o armazenamento de partições em máquinas diferentes.
Pode ajudar a otimizar o arquivamento de dados, permitindo aos programadores particionar os dados de acordo com a data e a hora. Podem mover registos específicos com carimbos de data/hora mais antigos do que um determinado limite para uma tabela de arquivo e utilizar outra tabela para armazenar os registos mais recentes.
Benefícios da fragmentação de banco de dados
A fragmentação de bases de dados é uma estratégia valiosa para uma gestão eficiente dos dados. As empresas que dependem de dados extensos para operar seus sites, aplicativos e outros softwares orientados por dados devem adotar a fragmentação para maximizar os benefícios de sua tecnologia de banco de dados.
A lista abaixo menciona alguns benefícios que a fragmentação oferece às organizações em mais detalhes.
Escalabilidade:** Ao dividir os dados em várias máquinas, a fragmentação permite às empresas escalar os seus sistemas de bases de dados de forma mais eficiente para suportar cargas de trabalho crescentes.
Tempo de inatividade mínimo:** A fragmentação garante alta disponibilidade operando em uma arquitetura sem compartilhamento. A estratégia permite uma melhor experiência do utilizador, uma vez que a falha de uma máquina não afectará o desempenho das outras.
Fácil de atualizar:** A implementação de actualizações de desempenho é mais eficiente, uma vez que os programadores podem atualizar separadamente máquinas individuais sem desligar todo o sistema.
Desafios da fragmentação de banco de dados
Embora a fragmentação ofereça benefícios significativos, os desenvolvedores podem enfrentar alguns desafios que aumentam a complexidade da implementação. A lista abaixo destaca esses problemas com possíveis estratégias de atenuação.
Distribuição desigual:** A incerteza em relação ao volume e à variedade de dados pode causar o aparecimento de pontos de acesso. Apesar de uma chave de fragmento eficaz, a natureza dos dados pode mudar, exigindo que os desenvolvedores selecionem ou criem uma nova chave. Os programadores devem avaliar cuidadosamente a adequação da fragmentação da base de dados em cenários específicos. É possível que a replicação ou o escalonamento vertical seja mais prático do que a fragmentação em diferentes situações.
Gestão complexa:** A gestão de várias máquinas é complexa, uma vez que os programadores têm de monitorizar constantemente o estado de cada nó para identificar e resolver problemas rapidamente. Sistemas de monitorização robustos com mecanismos de alerta em tempo real podem ajudar a mitigar estes problemas, notificando as equipas relevantes em caso de falhas no servidor.
Custos de manutenção:** A manutenção de vários servidores no local é dispendiosa e requer pessoal adicional com conhecimentos especializados para resolver problemas durante a manutenção. As organizações podem migrar para a [infraestrutura em nuvem] (https://zilliz.com/blog/zilliz-cloud-available-in-11-regions-across-3-major-cloud-providers) para hospedar vários fragmentos e fazer com que o fornecedor da nuvem realize verificações de manutenção regulares nos bastidores.
Casos de uso de fragmentação de banco de dados
Embora as seções acima destaquem brevemente os casos de uso em que a fragmentação é benéfica, a lista abaixo categoriza e explica esses cenários com mais detalhes.
Aplicações Web de grande escala:** Os sites de comércio eletrónico com uma base de utilizadores extensa, as plataformas de redes sociais, as aplicações de transporte de automóveis e os sites de jogos são candidatos ideais para a fragmentação da base de dados. A fragmentação pode ajudar os administradores desses sites a equilibrar a carga de forma mais eficaz e evitar o tempo de inatividade durante as horas de pico.
Análise de grandes volumes de dados:** Para os utilizadores que analisam grandes volumes de dados, a fragmentação pode ajudar a melhorar a velocidade de processamento, distribuindo a carga por vários servidores.
Redes de distribuição de conteúdo (CDNs):** Uma CDN é um grupo de servidores distribuídos em diferentes locais para atender a solicitações de usuários em localizações geográficas próximas. Os programadores podem fragmentar as bases de dados de acordo com a localização dos utilizadores e distribuir os dados por estes servidores para obter tempos de resposta mais rápidos.
FAQs sobre fragmentação de banco de dados
- **Qual é a diferença entre sharding e particionamento?
Enquanto a fragmentação e o particionamento dividem os dados em pedaços mais pequenos, a fragmentação distribui cada pedaço por diferentes máquinas ou nós. Em contrapartida, o particionamento armazena cada pedaço numa única máquina.
- **Qual é a diferença entre sharding e replicação?
A replicação copia toda a base de dados e armazena-a em máquinas diferentes. Em comparação com o sharding, que divide a base de dados em linhas e armazena cada parte em vários servidores, a replicação oferece uma maior disponibilidade, mas requer mais recursos informáticos e capacidade de armazenamento.
- **Como é que se escolhe a chave de fragmentação correta?
A escolha de uma chave de fragmento adequada exige que os programadores determinem a coluna correta para dividir os dados. Uma chave de fragmento deve ter baixa cardinalidade e frequência igual.
A cardinalidade refere-se ao número máximo de fragmentos possíveis de acordo com os valores da coluna. Por exemplo, a seleção de uma coluna que contenha quatro valores distintos resultará em quatro fragmentos. A frequência refere-se à proporção de dados que cada fragmento contém.
Além disso, selecione ou crie fragmentos que permaneçam estáticos durante todo o ciclo de vida da aplicação. Os fragmentos cujo volume de dados é suscetível de mudar podem resultar em hotspots, com alguns fragmentos a receberem mais volume do que outros.
- **Quais são os principais desafios da fragmentação de bases de dados?
A fragmentação da base de dados aumenta as despesas de consulta, uma vez que os programadores têm de escrever consultas para aceder a dados de várias máquinas para efetuar análises.
Também aumenta os custos de infraestrutura, uma vez que as organizações têm de manter vários servidores e monitorizar o seu estado para evitar interrupções.
Além disso, a atualização e o reequilíbrio dos shards são complexos se o volume e a variedade dos dados aumentarem. Uma técnica de fragmentação adequada numa situação pode já não ser prática noutras.
- **A fragmentação de bases de dados é adequada para pequenas aplicações?
Embora a fragmentação de bases de dados seja uma técnica valiosa para melhorar a velocidade de processamento e o rendimento, é inadequada para pequenas aplicações. A sua implementação só é prática quando o volume de dados atinge um ponto em que se torna insustentável manter uma única base de dados num único servidor.
Recursos relacionados
Embora os desenvolvedores geralmente apliquem o sharding a conjuntos de dados estruturados, os recursos a seguir ajudarão a entender o conceito no contexto de dados não estruturados e bancos de dados vetoriais:
- O que é fragmentação de banco de dados?
- Como funciona o Sharding de banco de dados?
- Métodos de fragmentação
- Selecionando uma chave de fragmento
- Comparação com alternativas
- Benefícios da fragmentação de banco de dados
- Desafios da fragmentação de banco de dados
- Casos de uso de fragmentação de banco de dados
- FAQs sobre fragmentação de banco de dados
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis