




Desnormalização de Bancos de Dados: Um Guia Abrangente

Desnormalização de Bancos de Dados: Um Guia Abrangente
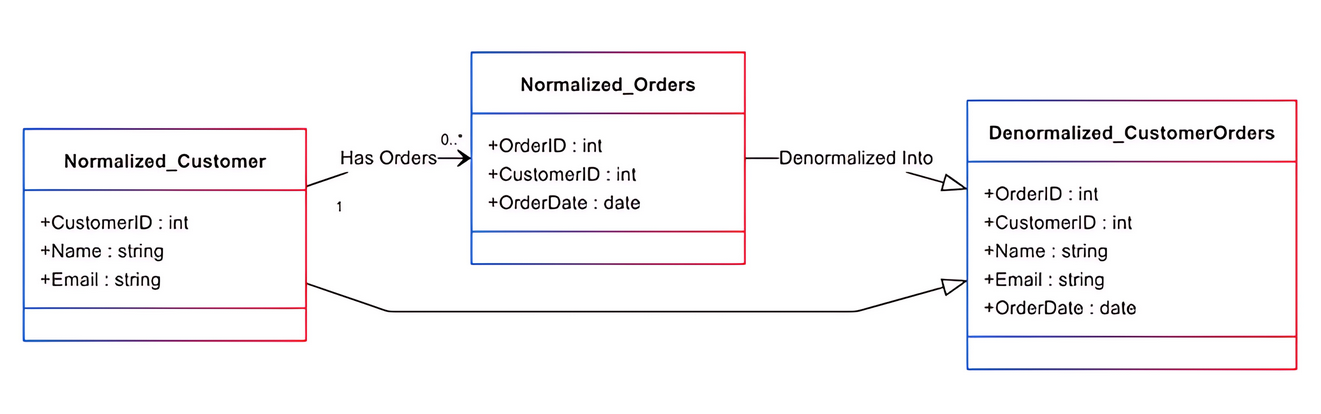
Figura 1: Ilustração da Desnormalização de Bancos de Dados
Por que alguns bancos de dados lidam com consultas mais rapidamente do que outros, mesmo ao lidar com grandes quantidades de informações? A resposta está na indexação do banco de dados, na otimização de consultas e na arquitetura de armazenamento. A recuperação rápida de dados é crucial, pois melhora o desempenho, a experiência do usuário e a eficácia geral.
A normalização tradicional de bancos de dados mantém a integridade dos dados ao organizá-los em tabelas com relacionamentos bem definidos. Embora a normalização melhore a precisão dos dados, ela tende a causar um gargalo de desempenho em sistemas que usam muitas junções. Com tantas tabelas e junções, torna-se mais difícil recuperar os dados, diminuindo a capacidade de resposta da aplicação.
Uma técnica usada para otimizar o desempenho de bancos de dados é a desnormalização. A desnormalização introduz dados redundantes no banco de dados para otimizar cargas com muitas leituras. Isso reduz a necessidade de junções complexas, melhorando assim o desempenho das consultas.
Este guia explicará o conceito de desnormalização de bancos de dados, comparará com a normalização e discutirá seus benefícios. Também revelaremos os casos de uso em que a desnormalização de bancos de dados é benéfica e os desafios que as empresas podem enfrentar ao implementá-la.
O Que É Desnormalização de Bancos de Dados?
A desnormalização de bancos de dados é uma técnica de otimização que adiciona dados duplicados a um esquema previamente normalizado. Essa técnica melhora o desempenho de leitura ao simplificar consultas e reduzir o número de junções.
Bancos de dados normalizados sofrem com múltiplas junções para buscar dados entre várias tabelas, tornando-os lentos ao trabalhar com grandes conjuntos de dados. A técnica de desnormalização é útil em sistemas que realizam operações de leitura em vez de operações de gravação.
Por exemplo, digamos que um banco de dados normalizado contenha três tabelas separadas: cliente, pedido e produto. Recuperar o histórico de pedidos de um cliente com detalhes do produto exige que o banco de dados junte várias tabelas, combinando dados de clientes, pedidos e produtos. Um esquema desnormalizado combina dados relacionados, como detalhes do produto, em uma tabela para minimizar junções e melhorar o desempenho de leitura.
No entanto, um aumento de desempenho para operações de leitura tem um custo para as operações de gravação. Atualizações consistentes de dados tornam-se mais complexas porque o banco de dados precisa manter informações redundantes.
Como Funciona
O processo de desnormalização transforma bancos de dados normalizados por meio de reestruturação para melhorar a velocidade e o desempenho de consultas e recuperação de dados. Enquanto o processo de normalização elimina duplicatas mantendo a consistência dos dados, a desnormalização adiciona dados duplicados especificamente para impulsionar as operações de leitura em aplicações.
Bancos de dados que precisam de relatórios em tempo real, consultas de alta velocidade e análises adotam amplamente essa técnica. Abaixo, discutiremos abordagens de desnormalização e seu impacto na eficácia do banco de dados.
 Abordagens de Desnormalização de Bancos de Dados
Abordagens de Desnormalização de Bancos de Dados
Figura 2: Abordagens de Desnormalização de Bancos de Dados
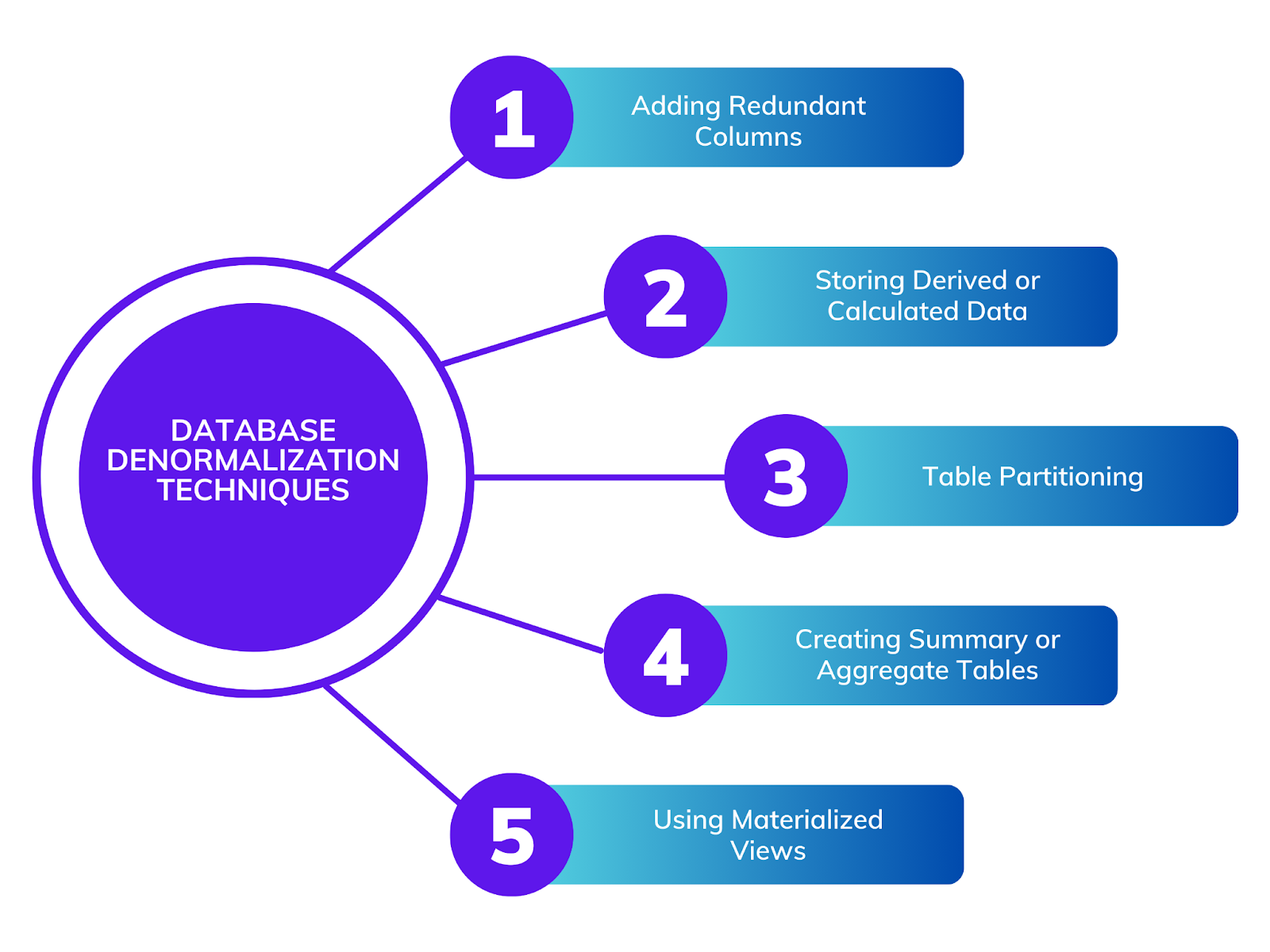
Adicionando Colunas Redundantes
Adicionar colunas redundantes é um método simples e padrão de desnormalização. Isso envolve adicionar dados em vários locais para reduzir operações de junção. Por exemplo, a tabela de pedidos de um banco de dados tem uma chave estrangeira chamada ID que a conecta à tabela de clientes. A tabela de clientes contém detalhes essenciais sobre cada cliente, como nome, ID e informações de contato.
Quando os detalhes dos pedidos dos clientes são analisados, uma operação de junção é necessária para extrair dados do cliente. A junção de tabelas pode ser particularmente cara e desacelerar o desempenho geral. Se as informações do cliente forem armazenadas na tabela de pedidos, isso elimina a necessidade de uma junção e leva a uma recuperação eficiente dos dados.
Embora esse método melhore consideravelmente a velocidade das consultas, ele aumenta os custos de redundância de dados. Quando os dados do cliente mudam, todas as cópias redundantes devem ser atualizadas para manter a consistência. Isso exige a otimização do desempenho e o gerenciamento da integridade dos dados por meio de atualizações ou triggers. O equilíbrio desse problema pode ser executado usando processos de atualização bem definidos.
Armazenamento de Dados Derivados ou Calculados
Outro método de desnormalização é armazenar e pré-computar cálculos frequentes. Em um sistema de banco de dados normalizado, os cálculos são feitos dinamicamente no momento da consulta. Embora isso garanta que os valores estejam atualizados, também afeta negativamente a carga computacional.
O desempenho do sistema sofre ao lidar com grandes conjuntos de dados ou numerosas solicitações de consulta. No entanto, o desempenho pode ser aprimorado adicionando esses valores como colunas adicionais dentro das linhas de tabelas existentes.
Por exemplo, o banco de dados pode pré-armazenar os valores totais dos pedidos na tabela de pedidos, para que os usuários não precisem recalcular essas informações ao solicitar seu histórico de pedidos. O sistema de banco de dados pode entregar o valor sem processamento extra porque esses valores já estão armazenados.
Essa técnica é benéfica no setor financeiro, no e-commerce e em sistemas de BI, que têm um alto volume de dados que requer cálculos agregados e complexos. No entanto, manter a integridade dos valores pré-computados é vital. Isso, consequentemente, exige atualizações periódicas ou ativações de triggers com base em mudanças nos dados.
Particionamento de Tabelas
O particionamento de tabelas é uma abordagem-chave de desnormalização que divide grandes tabelas em partições para melhorar o processamento de consultas e a velocidade de recuperação de dados. Ele fornece resultados excepcionais ao processar bancos de dados extensos que contêm logs de transações, registros de auditoria e conjuntos de dados históricos. Ele é ainda dividido em duas partes:
Particionamento Horizontal: A técnica de particionamento divide uma tabela em partições menores com base em critérios como parâmetros de data, áreas geográficas e divisões de usuários. Por exemplo, um varejista online com milhões de transações de vendas pode dividir sua tabela de pedidos de acordo com partições anuais. O desempenho melhora quando as consultas precisam de transações recentes porque elas exigem a varredura de um subconjunto reduzido de dados em vez da tabela completa.
Particionamento Vertical: O particionamento vertical funciona de forma diferente do particionamento horizontal porque separa tabelas em seções distintas baseadas em colunas. Ele divide tabelas em duas partes colocando colunas acessadas com frequência próximas às menos acessadas, de modo que as consultas só precisem recuperar os dados necessários. A abordagem se mostra benéfica para tabelas largas que contêm numerosos atributos porque permite que as consultas acessem apenas campos essenciais.
Ambos os métodos de particionamento melhoram a otimização do armazenamento e reduzem o tempo de execução das consultas, agregando valor significativo a bancos de dados de alto desempenho. No entanto, os métodos aumentam a complexidade da indexação e do particionamento e podem resultar em ineficiências nas consultas se estratégias adequadas não forem aplicadas.
Criação de Tabelas de Resumo ou Agregadas
Aplicações de geração de relatórios e processamento de análise de dados frequentemente extraem estatísticas resumidas em tempo real a partir de entradas brutas. Isso geralmente exige poder de processamento significativo. Portanto, uma abordagem é agregar tabelas. Em vez de recalcular, uma tabela de resumo pode ser usada como ponto de armazenamento, permitindo acesso instantâneo a dados pré-agregados.
Considere uma empresa de varejo que analisa o desempenho de vendas em várias regiões. Criar uma tabela de resumo com o total de vendas agregado por mês para cada região facilitaria a compreensão de insights de alto nível.
Essa tabela poderia ser atualizada em tempo real, por meio de triggers, ou com atualizações em lote agendadas. A tabela de resumo proporciona uma execução de consultas mais rápida porque contém menos linhas do que a tabela de transações original, o que melhora a responsividade de dashboards e relatórios.
Embora esse método melhore os insights de alto nível, ele também exige um mecanismo robusto de atualização de dados. O processamento em lote ou pipelines de ETL podem garantir a retenção de dados de resumo atualizados.
Usando Materialized Views
Materialized views são um recurso avançado de otimização que cria objetos físicos de banco de dados contendo resultados de execução de consultas. Views padrão exigem a execução dinâmica de consultas a cada acesso. No entanto, materialized views armazenam seus dados em disco para que os usuários possam recuperar informações instantaneamente sem processamento adicional.
Vamos considerar o exemplo de um site de e-commerce que monitora compras de clientes. Os proprietários do site podem criar uma materialized view que acompanha o gasto total por cliente em várias categorias de produtos. O banco de dados recupera resultados pré-computados em vez de realizar cálculos em tempo real, pois essa abordagem oferece respostas de consulta mais rápidas.
Materialized views podem ser atualizadas periodicamente ou de forma incremental, dependendo dos requisitos do sistema. A técnica oferece benefícios excepcionais para bancos de dados que exigem joins, agregações e transformações em várias etapas.
Comparação: Desnormalização vs. Normalização
A escolha entre normalização e desnormalização para o design de banco de dados depende dos requisitos de velocidade de desempenho, eficiência de armazenamento e consistência dos dados. Esta tabela mostra as distinções entre desnormalização e normalização.
| Aspecto | Normalização | Desnormalização |
| Propósito | Reduzir redundância | Melhorar o desempenho de leitura |
| Estrutura de Dados | Várias tabelas relacionadas | Menos tabelas, dados redundantes |
| Complexidade da Consulta | Joins complexos | Consultas simplificadas |
| Melhor Para | Aplicações com muitas gravações | Aplicações com muitas leituras |
| Integridade dos Dados | Alta | Potencialmente comprometida |
| Uso de Armazenamento | Eficiente | Aumentado |
| Manutenção | Simplificada | Mais complexa |
| Anomalias de Atualização | Minimizadas | Risco aumentado |
O processo de seleção de banco de dados exige a análise dos padrões de recuperação de dados, dos requisitos de velocidade de atualização e das especificações de desempenho do sistema. Um banco de dados devidamente equilibrado mantém a eficiência operacional e a escalabilidade.
Benefícios e Desafios
A desnormalização é um método de otimização que adiciona dados redundantes para impulsionar as operações de leitura e a velocidade de execução de consultas. No entanto, os ganhos de desempenho podem criar problemas com armazenamento e anomalias. Os benefícios da desnormalização exigem uma implementação equilibrada que evite o surgimento de riscos potenciais. Aqui estão alguns dos benefícios e desafios:
Benefícios da Desnormalização
Complexidade reduzida da aplicação: A desnormalização simplifica a lógica da aplicação ao eliminar a necessidade de joins complexos e consultas em várias tabelas. Isso melhora a legibilidade e a simplicidade das consultas, levando a uma maior produtividade dos desenvolvedores.
Melhor desempenho em sistemas distribuídos: A recuperação de dados de vários nós em bancos de dados distribuídos leva a um desempenho mais lento. A desnormalização coloca dados duplicados próximos aos seus principais pontos de acesso. Isso reduz a necessidade de recuperação de dados entre nós. A técnica se mostra valiosa para sistemas baseados em nuvem, bem como para arquiteturas escaladas horizontalmente.
Maior eficiência em data warehousing: Data warehouses exigem o tratamento eficiente de tarefas analíticas que executam cálculos complexos e procedimentos de agregação. A desnormalização beneficia o desempenho de leitura ao armazenar dados pré-unidos ou pré-agregados, eliminando a necessidade de transformações de dados em tempo real.
Facilita a análise em tempo real: Aplicações que realizam análises precisam de acesso imediato aos dados para obter insights rápidos. A desnormalização reduz a exigência de cálculos complexos em tempo real ao armazenar valores pré-computados com dados redundantes.
Relatórios otimizados: Bancos de dados desnormalizados mantêm dados pré-processados para a criação instantânea de relatórios e minimizam a necessidade de operações de transformação de dados. Essa abordagem beneficia substancialmente aplicações de business intelligence e dashboards executivos.
Desafios
Anomalias de dados: A duplicação de dados cria um risco maior de inconsistência de dados, porque as atualizações podem não se propagar corretamente entre todas as instâncias do sistema. A validação de dados e as verificações de consistência são importantes em sistemas desnormalizados para reduzir o risco de anomalias.
Aumento dos custos de armazenamento: Dados redundantes exigem espaço de armazenamento adicional, o que aumenta o tamanho total do banco de dados. Bancos de dados baseados em nuvem que usam modelos de preços baseados no uso podem experimentar custos mais altos devido aos requisitos de armazenamento.
Complexidade na sincronização de dados: A sincronização de dados exige que cada operação de atualização modifique todas as cópias dos dados simultaneamente, levando a limitações de desempenho. A má execução da sincronização de dados produz registros contendo imprecisões ou informações desatualizadas.
Potencial para problemas de integridade de dados: A execução inadequada de atualizações em várias instâncias produz dados inconsistentes. Isso degrada a qualidade operacional e a precisão dos relatórios. Sistemas de alta transação exigem recursos extras e sistemas de validação rigorosos para manter a integridade dos dados.
Flexibilidade reduzida: Ambientes com várias tabelas tornam as modificações de esquema mais difíceis. Isso leva a ciclos de desenvolvimento mais lentos e torna mais difícil para as organizações se adaptarem a novos requisitos de negócios.
É necessário um gerenciamento adequado para implementar a desnormalização a fim de evitar anomalias de dados, problemas de integridade e despesas de armazenamento. As organizações devem implementar a desnormalização com base em requisitos de desempenho identificados que correspondam às necessidades do sistema.
Casos de uso
Os benefícios da desnormalização tornam-se evidentes em casos de uso específicos, mas as organizações devem compreender suas implicações em diferentes situações. Aqui estão alguns dos principais casos de uso:
Data warehousing e sistemas OLAP: Sistemas de data warehousing e OLAP usam métodos de desnormalização para tornar consultas e agregações complexas mais eficientes. O uso de esquemas desnormalizados resulta em recuperação de dados mais rápida, pois elimina a exigência de várias junções de tabelas. Isso é essencial para aplicações de business intelligence e cargas de trabalho analíticas.
Aplicações de baixa latência: A desnormalização beneficia aplicações de baixa latência ao encurtar o tempo necessário para recuperar e processar dados em ambientes críticos, como plataformas de negociação financeira.
Aplicações com uso intensivo de leitura: Aplicações que realizam mais operações de leitura do que operações de escrita podem alcançar melhor desempenho usando a desnormalização. Sistemas como ferramentas de gerenciamento de conteúdo e relatórios podem alcançar melhor desempenho em solicitações de leitura ao adicionar dados duplicados.
Análises em tempo real: Aplicações que precisam de insights instantâneos podem se beneficiar da desnormalização ao acessar dados pré-agregados. Isso reduz o tempo de processamento das consultas, permitindo uma tomada de decisão rápida usando informações atualizadas.
Perguntas frequentes
A desnormalização de banco de dados é sempre melhor para o desempenho?
A desnormalização em sistemas com muitas escritas cria problemas de inconsistência de dados porque manter dados redundantes apresenta desafios significativos. Você deve avaliar os padrões de leitura e escrita da sua aplicação antes de decidir pela desnormalização de banco de dados.
A desnormalização substitui a normalização?
A desnormalização funciona como uma etapa adicional após a normalização para melhorar problemas de desempenho. O processo de normalização estrutura os dados para eliminar duplicação e manter a integridade dos dados, mas a desnormalização reintroduz duplicatas de dados para melhorar a velocidade de leitura.
Quais são os riscos da desnormalização?
Implementar a desnormalização cria três riscos principais: redundância de dados, maiores requisitos de armazenamento e inconsistências. O aumento da redundância de dados cria anomalias potenciais quando gerenciado incorretamente, enquanto o tamanho expandido dos dados exige maiores despesas com armazenamento.
Posso desnormalizar apenas parte do meu banco de dados?
Sim, a desnormalização de banco de dados funciona direcionando seções específicas do banco de dados para otimizar o desempenho. A implementação direcionada possibilita melhor eficiência de leitura em áreas específicas sem afetar a gerenciabilidade ou a integridade do banco de dados.
Como mantenho a consistência dos dados em um banco de dados desnormalizado?
Um banco de dados desnormalizado requer gatilhos de banco de dados, restrições e lógica de aplicação para manter os dados redundantes consistentes durante as atualizações. Implementar esses mecanismos mantém a sincronização dos dados em todas as cópias de dados.
Recursos relacionados
- O Que É Desnormalização de Bancos de Dados?
- Como Funciona
- Comparação: Desnormalização vs. Normalização
- Benefícios e Desafios
- Casos de uso
- Perguntas frequentes
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis