




Vector Lakebase: Acabe com o silo de dados de IA
Toda equipe de IA encontra a mesma barreira — Gravidade dos dados
Toda equipe moderna de dados construiu alguma versão da mesma arquitetura. Uma lakehouse — tabelas Iceberg no S3, um pipeline Spark e Delta Lake para governança — fica no centro. Funciona bem. Então chegam os requisitos de IA.
Seu pipeline de RAG precisa responder a perguntas sobre 10 anos de documentos corporativos, então você copia tudo para um banco de dados vetorial. Seus agentes de IA precisam de acesso de baixa latência a embeddings do catálogo de produtos — outro pipeline, outra tarefa de sincronização. Seu treinamento de modelo multimodal exige deduplicação diária em um bilhão de embeddings de imagens — uma tarefa Spark que não consegue ver o índice.
Seis meses depois, você tem cinco sistemas em vez de dois. Sua equipe de engenharia de dados passa mais tempo mantendo pipelines de sincronização do que construindo recursos de IA. Você tem três cópias do mesmo conjunto de dados sem garantia de que elas concordem. Cada mudança de esquema se propaga para quatro lugares diferentes.
Isso não é uma falha de execução. É uma falha de arquitetura — especificamente, uma arquitetura que continua lutando contra uma propriedade fundamental dos dados: gravidade. Todo sistema que exige que você copie os dados primeiro está cobrando de você um imposto de gravidade. Quanto mais cargas de trabalho de IA você adiciona — pipelines de RAG, memória de agentes, treinamento de modelos, recomendações em tempo real — maior esse imposto se torna.
A solução certa não é um pipeline melhor. Deve ser um novo paradigma arquitetural: Vector Lakebase.
Três gerações de soluções arquiteturais, dois becos sem saída
Antes de nos aprofundarmos nos detalhes da Vector Lakebase, vale a pena observar como a arquitetura de busca vetorial evoluiu para abordar o problema da gravidade dos dados. Em linhas gerais, houve três gerações de soluções.
Geração 1: Bancos de dados vetoriais dedicados
Bancos de dados vetoriais dedicados como Milvus resolveram um problema real para sistemas de IA em produção: busca semântica com latência de milissegundos, com recall e desempenho que bancos de dados de uso geral não conseguiam igualar. Como criadores do banco de dados vetorial open-source Milvus, a Zilliz há muito se concentra em construir um sistema confiável e de alto desempenho para armazenar embeddings, construir índices e servir recuperação de baixa latência para RAG, agentes, sistemas de recomendação, busca semântica e aplicações multimodais. Essa base ainda importa. Sistemas de IA em produção ainda precisam de recuperação em velocidade de banco de dados, e bancos de dados vetoriais continuam sendo a camada de serving certa para muitas cargas de trabalho sensíveis à latência.
No entanto, à medida que as cargas de trabalho de IA amadurecem, o desafio se estende cada vez mais além do serving online. Grande parte dos dados de origem de uma organização já vive em armazenamento de objetos, data lakes, lakehouses e sistemas analíticos downstream. Para usar esses dados em um banco de dados vetorial dedicado, as equipes normalmente os copiam para um sistema de serving separado, criam pipelines de ingestão, mantêm tarefas de sincronização e gerenciam a consistência entre os dados de origem e o índice vetorial. Quando os modelos de embeddings mudam, como inevitavelmente acontece, as equipes precisam regenerar embeddings, reconstruir índices e manter vários sistemas alinhados.
Isso não é uma limitação do desempenho dos bancos de dados vetoriais. É uma fronteira arquitetural criada pela movimentação de dados. À medida que mais equipes querem usar os mesmos dados para recuperação em produção, experimentos com embeddings, avaliação offline, governança, linhagem e analytics, a superfície operacional cresce. Bancos de dados vetoriais dedicados resolveram extremamente bem o problema de recuperação online, mas, por si só, não eliminam o problema da gravidade dos dados.
Geração 2: Vector Lake
A próxima resposta natural foi aproximar a busca vetorial do lake: consultar vetores diretamente de arquivos Iceberg, Delta Lake ou Parquet sem primeiro movê-los para um sistema de serving dedicado. A motivação estava correta. Se os dados já vivem em armazenamento de objetos ou em uma lakehouse, por que duplicá-los em outro lugar apenas para torná-los pesquisáveis?
Mas, na prática, as arquiteturas de vector lake continuam incompletas para cargas de trabalho de IA em produção por três motivos.
Primeiro, elas não são projetadas para serving de baixa latência. A maioria das abordagens de vector lake carrega dados ou índices do armazenamento de objetos sob demanda e é otimizada mais para flexibilidade do que para o tratamento de solicitações concorrentes e sensíveis à latência. Isso pode ser aceitável para exploração offline, mas não é suficiente para aplicações de RAG, agentes, recomendação ou busca voltadas ao usuário. Quando um pipeline de recuperação está no caminho crítico de uma chamada de LLM, as equipes precisam de latência previsível abaixo de 100 ms em alta concorrência. Se a latência p99 frequentemente deriva para a faixa de segundos, o sistema ainda pode ser útil para análise, mas não pode servir como a camada de recuperação de produção.
Segundo, os sistemas de vector lake normalmente param na etapa de busca. Eles permitem que as equipes consultem dados vetoriais no lake, mas não fornecem um ambiente de execução mais amplo para fluxos de trabalho de dados de IA. Sistemas modernos de IA precisam de mais do que busca por vizinhos mais próximos. Eles precisam regenerar embeddings, avaliar a qualidade da recuperação, comprimir a memória de agentes, extrair frames de vídeo, processar dados multimodais, gerenciar metadados e preparar dados para fine-tuning ou pipelines downstream. Um sistema que apenas adiciona busca sobre arquivos do lake não aborda todo o ciclo de vida de dados vetoriais e multimodais.
Terceiro, a camada de armazenamento subjacente não foi criada para essa carga de trabalho. Iceberg e Delta Lake foram projetados para dados analíticos estruturados — sem tipos vetoriais nativos, sem estruturas de índice, cada consulta é uma varredura completa. Cargas de trabalho de IA precisam de buscas pontuais rápidas (não as varreduras sequenciais de row groups do Parquet — formatos como Vortex e Lance existem por esse motivo), índices integrados co-gerenciados com os dados e gerenciamento de dados não estruturados baseado em referências, em que imagens, áudio e vídeo são vinculados por referência em vez de incorporados como blobs. Nada disso existe no lake hoje. Um Vector Lake construído sobre Iceberg está lutando contra a camada de armazenamento em todos os níveis.
Geração 3: Vector Lakebase
Vector Lakebase é o que você obtém quando deixa de tratar o lake e o banco de dados vetorial como sistemas separados que precisam ser sincronizados e começa a construí-los como dois modos operacionais de uma única camada unificada. Para ser mais específico:
Um vector lakebase é uma nova arquitetura nativa de IA e nativa de lake, evoluída a partir de sistemas de bancos de dados vetoriais. Ela combina as capacidades de serving de alto QPS e baixa latência dos bancos de dados vetoriais com a abertura, escalabilidade e eficiência de custo dos data lakes multimodais, mantendo todas as cargas de trabalho na mesma fonte de verdade sem migração de dados. Ao separar computação de armazenamento, um vector lakebase armazena dados multimodais, vetores, atributos, índices e metadados diretamente em armazenamento de objetos de baixo custo usando formatos abertos. Cargas de trabalho de serving, descoberta e analytics podem então ser executadas de forma independente sobre os mesmos dados.
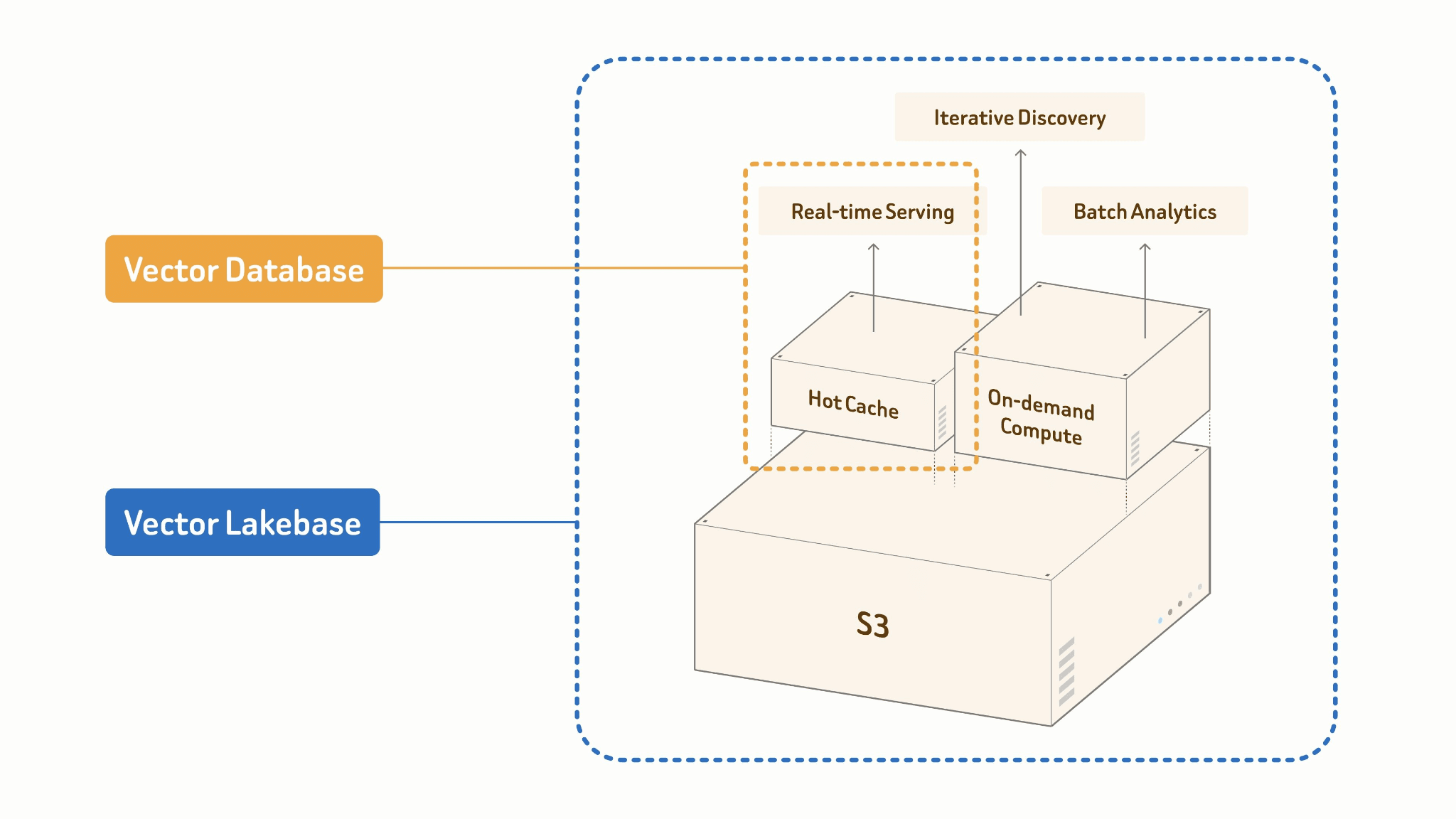
O princípio central: Uma Fonte de Verdade.
Sua tabela do lake é a única fonte de verdade. Serving online e processamento batch offline compartilham os mesmos dados, índice e schema. Não há pipeline entre eles porque não há fronteira entre eles.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplicação + desatualização
Vector Lake: [Lake + Index] ◀── apenas consulta batch # sem serving, sem processamento
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + Índice de alta performance
│ → consulta ANN, serving p99 <100 ms
└── Offline: Processamento batch + Construção de índice com custo eficiente
→ embed, cluster, dedup, engenharia de features
Os dois modos são projetados de forma diferente por necessidade. O serving online é executado sobre um cache quente e um índice em memória de alta performance — otimizado para concorrência e latência de cauda. Jobs em lote offline constroem índices de forma econômica em escala: varreduras colunares, construção acelerada por GPU, escritas em etapas de volta no lake. Mesmos dados, mesmo formato de índice, perfis de computação radicalmente diferentes.
Como isso se parece na prática? Em uma tabela Iceberg de 1 bilhão de vetores:
| Modo | Latência | Contexto |
|---|---|---|
| Varredura brute-force com Spark (sem índice) | Horas | O padrão atual para busca vetorial baseada em lake |
| Vector Lakebase — frio (índice recém-construído) | ~30 segundos | Índice construído a partir do Iceberg em ~20 minutos |
| Vector Lakebase — morno (cache em disco) | Dezenas de ms | Índice em cache no SSD local |
| Vector Lakebase — quente (em memória) | Unidades de ms | Serving de RAG e agentes em produção |
| Vector Lakebase — clustering / dedup | Horas | KMeans de 1B de vetores ou detecção de quase duplicatas, totalmente distribuído |
Você passa de horas para unidades de milissegundos — e nunca copia os dados para fora do lake.
Isso não é uma escolha de produto. É a direção para a qual a arquitetura de dados de IA está convergindo. Qualquer sistema que exija que os dados existam em dois lugares cobra de você um imposto permanente — em armazenamento, em horas de engenharia, em obsolescência. Sistemas que separam o armazenamento das operações de IA parecerão transitórios em retrospectiva.
O Que um Vector Lakebase Realmente Possibilita
Pelo menos três classes de workloads que antes exigiam sistemas separados agora podem ser tratadas com um vector lakebase.
Coleções Externas: Torne Seu Lake Pesquisável Sem Mover Nada
Você tem petabytes de embeddings em arquivos Parquet no S3. Torná-los pesquisáveis para uma nova aplicação RAG hoje significa carregá-los em um banco de dados vetorial — uma migração medida em dias ou semanas, além de uma obrigação contínua de sincronização.
As coleções externas do Vector Lakebase trabalham com a gravidade dos dados, em vez de contra ela. Você aponta para o bucket, define um mapeamento de esquema sobre suas colunas existentes e constrói um índice vetorial no lugar. Os dados permanecem no S3. O índice persiste de volta no S3. Quando os dados de origem são atualizados, você atualiza incrementalmente — apenas os arquivos alterados são reprocessados.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Sem migração, sem pipeline, sem novo custo de armazenamento. Seu sistema RAG consulta os mesmos dados que sua equipe de analytics já governa — por meio de Spark, Ray, LangChain, PyMilvus ou uma API REST. O índice se torna uma propriedade de primeira classe da tabela, não um sistema externo acoplado ao lado dela.
ETL, Engenharia de Features e Engenharia de Contexto
Este é o workload que tanto Vector Database quanto Vector Lake ignoram — e ele está se tornando a parte mais importante da stack de dados de IA.
Operações de dados nativas de IA não apenas movem dados entre sistemas — elas os enriquecem com significado semântico, no lugar, em escala:
- Adicionar uma coluna de embeddings a uma tabela existente: inferência em lote em 100 milhões de linhas, gravar os resultados de volta na mesma tabela.
- Dividir em chunks um corpus de documentos para RAG, mantendo documentos brutos e chunks versionados juntos.
- Atualizar de text-embedding-3-small para um modelo mais novo — fazer backfill de todos os 500 milhões de vetores in place, com embeddings antigos e novos coexistindo até você fazer o cutover.
- Criar e versionar os pacotes de contexto que seus agentes de IA recuperam em tempo de execução — o que é recuperado, como é estruturado, como é comprimido para uma janela de contexto.
À medida que os modelos se comoditizam, a qualidade do que você alimenta neles importa mais do que qual modelo você escolhe. Esta disciplina emergente — Engenharia de Contexto — pertence ao lake: perto dos dados, versionada junto a eles, reproduzível de ponta a ponta. Vector Lakebase a torna uma operação de primeira classe, não scripts ad-hoc colados com cron jobs.
Clustering, Deduplicação e Descoberta de Anomalias
Essencial para toda equipe que treina ou faz fine-tuning de seus próprios modelos — e totalmente ausente do paradigma de banco de dados vetorial:
- Deduplicação: Exemplos quase duplicados no seu dataset de fine-tuning de LLM inflam a loss de treinamento e enviesam o comportamento do modelo. Identifique quase duplicados, emita um conjunto canônico, grave labels de deduplicação de volta como uma coluna.
- Clustering: Entenda o que seu dataset realmente contém antes do treinamento. Agrupe seu espaço de embeddings — você frequentemente descobrirá que 40% de um dataset "diverso" são pequenas variações dos mesmos poucos tópicos.
- Descoberta de anomalias: Para veículos autônomos, robótica ou qualquer modelo crítico para segurança — encontre os 0,1% de amostras que não se parecem em nada com o restante. Marque-as, priorize para rotulagem e inclua-as no treinamento. Você não consegue encontrá-las sem um índice; não consegue agir sobre elas sem gravar os resultados de volta no lake.
Vector Lakebase trata essas operações distribuídas como de primeira classe: cientes de índice, paralelizadas nos dados onde eles vivem, gravando resultados em formatos abertos. A saída de uma execução de deduplicação se torna uma coluna na mesma tabela.
Quem Já Está Construindo sobre Isso
Os primeiros parceiros de design do Vector Lakebase abrangem dois dos problemas de dados de IA mais difíceis em escala.
Empresas líderes de direção autônoma e EV usam isso para minerar corner cases a partir de bilhões de embeddings de cenas de direção — os raros cenários de estrada que determinam se um sistema autônomo é seguro. Uma empresa de ponta em foundation models usa isso para detecção de quase duplicados em corpora de pré-treinamento — deduplicando bilhões de exemplos para melhorar a qualidade do modelo antes que uma única hora de GPU seja gasta em treinamento.
Já Temos o Databricks Lakebase. Precisamos de Outro?
É uma pergunta justa, e a resposta exige entender o que o Databricks Lakebase realmente é.
Databricks Lakebase — construído sobre a aquisição da Neon — integra um mecanismo PostgreSQL serverless à plataforma Databricks. O problema que ele resolve: OLTP e OLAP sempre foram sistemas separados. A Databricks está colapsando essa fronteira. Esse é um problema real que vale a pena resolver. Mas é um problema fundamentalmente diferente.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Usuário principal | Engenheiros de backend, engenheiros de dados | Engenheiros de ML, equipes de plataforma de IA |
| Dados principais | Linhas, contas, transações | Embeddings, documentos, multimodal |
| Modelo de armazenamento | Armazenamento Postgres + Delta Lake (separado) | Tabela única no lake, unificada |
| Embedding em lote / dedup | Fora do escopo | Operação de primeira classe |
| Engenharia de Contexto | Fora do escopo | Capacidade central |
| Constrói sobre o lake existente | Parcial | Sim — migração zero |
| Otimização de formato | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, dados não estruturados nativos |
| OLTP (transações) | ✓ | N/A |
Databricks Lakebase colapsa a fronteira OLTP/OLAP. Vector Lakebase colapsa a fronteira entre onde seus dados de IA vivem e onde suas operações de IA rodam. Eles são complementares, não concorrentes. Muitas equipes usarão ambos.
A Aposta Arquitetural
Em 2013, a Databricks perguntou: E se a análise SQL vivesse no lake? Essa pergunta valeu $40 bilhões.
A próxima pergunta é: E se as operações de dados nativas de IA — recuperação RAG, memória de agentes, embedding em lote, curadoria de dados de treinamento de modelos, engenharia de contexto — também vivessem no lake?
Essa é a aposta por trás do Vector Lakebase. Não é um novo banco de dados para o qual migrar. Não é uma camada de consulta acoplada ao seu lake existente. Uma base unificada onde seus dados vivem uma única vez, são indexados uma única vez e atendem a todas as cargas de trabalho de IA — sem duplicação, sem sobrecarga de ETL, sem lutar contra a gravidade.
A corrida da IA recompensa a velocidade. Cada semana que sua equipe passa criando pipelines de sincronização, depurando dados desatualizados ou migrando entre sistemas é uma semana que seus concorrentes passam lançando recursos de IA. A infraestrutura deve ser um acelerador, não um gargalo. As equipes que vencem não são aquelas com os melhores modelos — são aquelas que removeram o atrito entre seus dados e sua IA.
Construa sobre suas tabelas Iceberg ou data lake existentes. Sem migração. Sem duplicação. Avance rápido — seus dados permanecem onde estão e se tornam pesquisáveis, processáveis e prontos para IA em minutos.
Isso é o Vector Lakebase.
Zilliz Vector Lakebase está disponível em public preview
Lançamos o public preview do Zilliz Vector Lakebase — uma grande evolução do Zilliz Cloud de um banco de dados vetorial gerenciado para uma plataforma unificada de dados semânticos, combinando serving vetorial de baixa latência com a abertura, escalabilidade e economia de um data lake.
Principais capacidades do Zilliz Vector Lakebase:
- Serving em camadas otimizado para diferentes trade-offs de desempenho-custo em tempo real
- Busca sob demanda para cargas de trabalho de larga escala ou exploratórias sem computação sempre ativa
- Busca em data lake externo — indexe e pesquise diretamente sobre seus dados de lake existentes
- Busca de espectro completo em vetores, texto, JSON e dados geoespaciais com recuperação híbrida e reranking
- Armazenamento unificado nativo de lake construído sobre Vortex, um formato aberto com leituras aleatórias mais rápidas e baratas que Lance ou Parquet
Se sua stack atual separa serving e descoberta em sistemas distintos, talvez valha a pena dar uma olhada no Vector Lakebase. Experimente no Zilliz Cloud — novos cadastros com email profissional recebem $100 em créditos gratuitos — ou fale conosco sobre seu caso de uso.

Continue lendo

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.