




Criação de RAG com Milvus, vLLM e Llama 3.1
A Universidade da Califórnia - Berkeley doou vLLM, uma biblioteca rápida e fácil de usar para inferência e serviço LLM, à LF AI & Data Foundation como um projeto em fase de incubação em julho de 2024. Como um projeto de membro companheiro, gostaríamos de dar as boas-vindas ao vLLM que se junta à família LF AI & Data! 🎉
Modelos de Linguagem Grandes (LLMs) e bases de dados vectoriais são normalmente emparelhados para construir Retrieval Augmented Generation (RAG), uma arquitetura de aplicação de IA popular para abordar AI Hallucinations. Este blogue irá mostrar-lhe como construir e executar um RAG com Milvus, vLLM e Llama 3.1. Mais especificamente, mostrarei como incorporar e armazenar informações de texto como vetor embeddings no Milvus e utilizar este armazenamento de vectores como uma base de conhecimentos para recuperar eficazmente pedaços de texto relevantes para as perguntas dos utilizadores. Finalmente, utilizaremos o vLLM para servir o modelo Llama 3.1-8B do Meta para gerar respostas aumentadas pelo texto recuperado. Vamos mergulhar de cabeça!
Introdução ao Milvus, vLLM e Llama 3.1 do Meta
Banco de dados vetorial do Milvus
A Milvus é uma base de dados vetorial distribuída, de código aberto, criada para o efeito, para armazenar, indexar e pesquisar vectores para cargas de trabalho de IA generativa (GenAI). A sua capacidade para efetuar pesquisa híbrida, filtragem de metadados, reranking e tratar eficientemente triliões de vectores faz do Milvus uma escolha de eleição para cargas de trabalho de IA e aprendizagem automática. O Milvus pode ser executado localmente, num cluster ou alojado no Zilliz Cloud totalmente gerido.
vLLM
vLLM é um projeto de código aberto iniciado no UC Berkeley SkyLab focado na otimização do desempenho do serviço LLM. Ele usa gerenciamento eficiente de memória com PagedAttention, batching contínuo e kernels CUDA otimizados. Em comparação com os métodos tradicionais, o vLLM melhora o desempenho da veiculação em até 24 vezes, reduzindo o uso de memória da GPU pela metade.
De acordo com o documento "Efficient Memory Management for Large Language Model Serving with PagedAttention", o cache KV usa cerca de 30% da memória da GPU, levando a possíveis problemas de memória. A cache KV é armazenada em memória contígua, mas a alteração do tamanho pode causar fragmentação da memória, o que é ineficiente para a computação.

Imagem 1. Gestão da memória cache KV nos sistemas existentes (2023 Paged Attention paper)
Ao usar a memória virtual para o cache KV, o vLLM aloca apenas a memória física da GPU conforme necessário, eliminando a fragmentação da memória e evitando a pré-alocação. Em testes, o vLLM superou o desempenho do HuggingFace Transformers (HF) e do Text Generation Inference (TGI), alcançando uma taxa de transferência até 24x maior que o HF e 3,5x maior que o TGI nas GPUs NVIDIA A10G e A100.
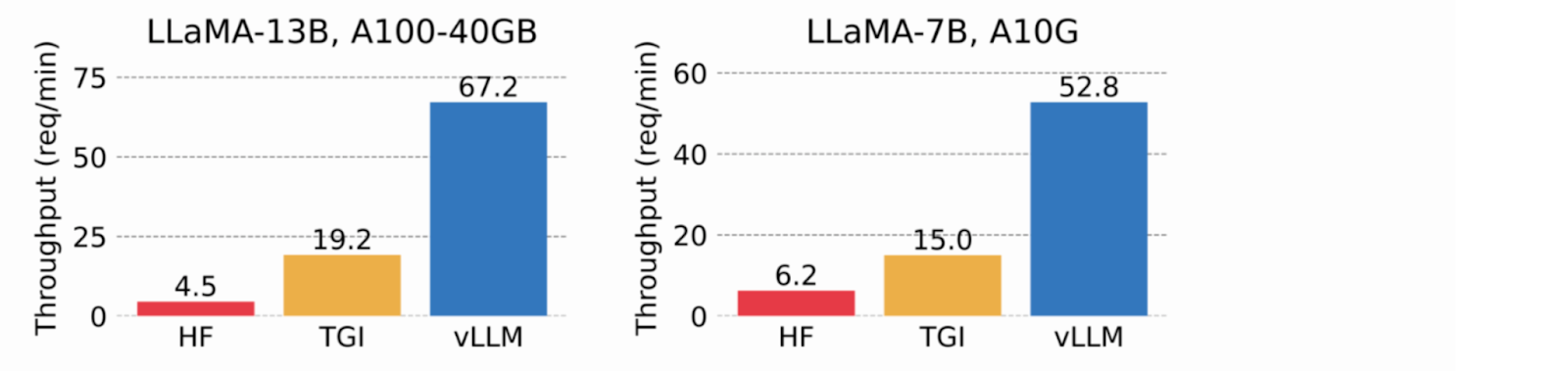
Imagem 2. O vLLM atinge uma taxa de transferência 8,5x-15x superior à do HF e 3,3x-3,5x superior à do TGI (2023 blog do vLLM).
Lhama do Meta 3.1
O Meta's Llama 3.1 foi anunciado em 23 de julho de 2024. O modelo 405B oferece desempenho de ponta em vários benchmarks públicos e tem uma janela de contexto de 128.000 tokens de entrada com vários usos comerciais permitidos. Juntamente com o modelo de 405 mil milhões de parâmetros, a Meta lançou uma versão actualizada do Llama3 70B (70 mil milhões de parâmetros) e 8B (8 mil milhões de parâmetros). Os pesos dos modelos estão disponíveis para descarregar [no sítio Web da Meta] (https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
Uma das principais conclusões foi que o ajuste fino dos dados gerados pode aumentar o desempenho, mas exemplos de baixa qualidade podem degradá-lo. A equipa do Llama trabalhou exaustivamente para identificar e remover estes maus exemplos utilizando o próprio modelo, modelos auxiliares e outras ferramentas.
Construir e executar o RAG-Retrieval com Milvus
Prepare o seu conjunto de dados
Usei a [documentação oficial do Milvus] (https://milvus.io/docs/) como conjunto de dados para esta demonstração, que descarreguei e guardei localmente.
from langchain.document_loaders import DirectoryLoader
# Carrega arquivos HTML já salvos em um diretório local
caminho = "../../RAG/rtdocs_new/"
padrão_global = '*.html'
loader = DirectoryLoader(path=path, glob=global_pattern)
docs = loader.load()
# Imprimir documentos numéricos e uma pré-visualização.
print(f "carregou {len(docs)} documentos")
print(docs[0].page_content)
pprint.pprint(docs[0].metadata)
 carregado 22 docs
carregado 22 docs
Descarregar um modelo de incorporação
A seguir, descarregue um embedding model gratuito e de código aberto da HuggingFace.
import torch
from sentence_transformers import SentenceTransformer
# Inicializar as configurações do torch para código agnóstico de dispositivo.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Descarregar o modelo do hub de modelos huggingface.
nome_do_modelo = "BAAI/bge-large-en-v1.5"
codificador = SentenceTransformer(nome_do_modelo, dispositivo=DEVICE)
# Obter os parâmetros do modelo e guardá-los para mais tarde.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Inspecionar os parâmetros do modelo.
print(f "nome_do_modelo: {nome_do_modelo}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

Agrupa e codifica seus dados personalizados como vetores.
Eu vou usar um comprimento fixo de 512 caracteres com 10% de sobreposição.
from langchain.text_splitter import RecursiveCharacterTextSplitter
TAMANHO_DO_CONJUNTO = 512
sobreposição_de_cachos = np.round(CHUNK_SIZE * 0.10, 0)
print(f "tamanho_do_conjunto: {Tamanho_do_conjunto}, sobreposição_do_conjunto: {sobreposição_do_conjunto}")
# Definir o divisor.
child_splitter = RecursiveCharacterTextSplitter(
tamanho_do_cachorro=tamanho_do_cachorro,
sobreposição_de_cachos=sobreposição_de_cachos)
# Separa os documentos em pedaços.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} documentos divididos em {len(chunks)} documentos filhos.")
# A entrada do codificador é doc.page_content como strings.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')]
# Inferência de incorporação utilizando o codificador HuggingFace.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Normalizar os embeddings.
incrustações = np.array(incrustações / np.linalg.norm(incrustações))
# Milvus espera uma lista de `numpy.ndarray` de números `numpy.float32`.
valores_convertidos = list(map(np.float32, embeddings))
# Criar dict_list para inserção no Milvus.
lista_dit = []
for chunk, vetor in zip(chunks, converted_values):
# Montar o vetor de incorporação, o pedaço de texto original e os metadados.
ditado_de_cachos = {
'pedaço': pedaço.conteúdo_da_página,
'fonte': chunk.metadata.get('fonte', ""),
'vetor': vetor,
}
lista_dit.append(pedaço_dict)

Guardar os vectores em Milvus
Ingerir a incorporação do vetor codificado na base de dados de vectores Milvus.
# Conectar um cliente ao servidor Milvus Lite.
from pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Criar uma coleção com um esquema flexível e AUTOINDEX.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
# Inserir dados na coleção Milvus.
print("Iniciar a inserção de entidades")
start_time = time.time()
mc.insert(
NOME_DA_COLECÇÃO,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f "Milvus insere tempo para {len(dict_list)} vectores: ", end="")
print(f"{round(end_time - start_time, 2)} segundos")

Efetuar uma pesquisa vetorial
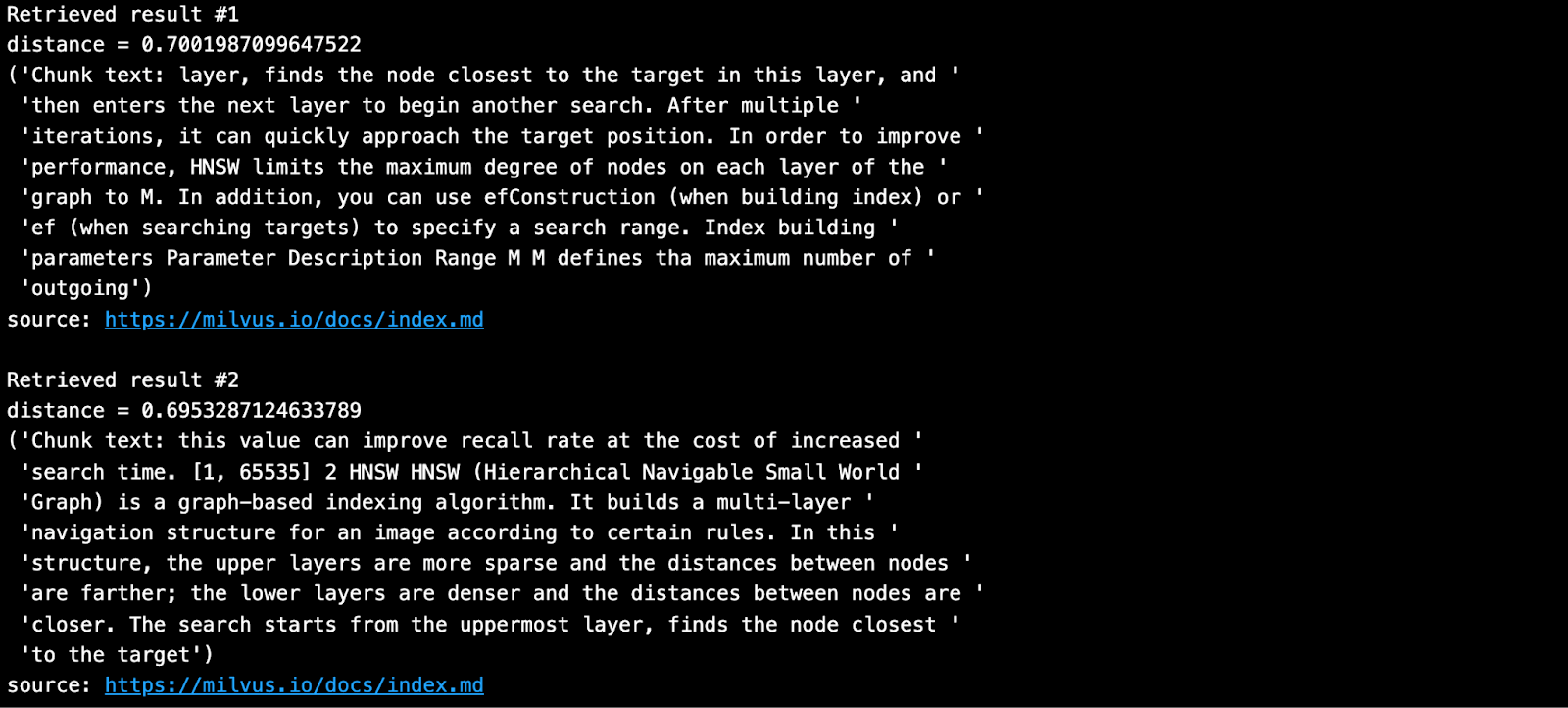
Faça uma pergunta e procure os pedaços vizinhos mais próximos da sua base de conhecimentos em Milvus.
SAMPLE_QUESTION = "O que significam os parâmetros de HNSW?"
# Incorporar a pergunta utilizando o mesmo codificador.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Normalizar os embeddings para comprimento unitário.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# Converter os embeddings em lista de lista de np.float32.
embeddings_consulta = list(map(np.float32, embeddings_consulta))
# Definir campos de metadados que podem ser filtrados.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vetor')
# Definir o número de resultados top-k que pretende obter.
TOP_K = 2
# Execute a pesquisa vetorial semântica utilizando a sua consulta e a base de dados vetorial.
resultados = mc.search(
NOME_DA_COLECÇÃO,
data=query_embeddings,
output_fields=OUTPUT_FIELDS,
limit=TOP_K,
consistency_level="Eventually")
O resultado recuperado é como mostrado abaixo.
Construir e executar a geração RAG com vLLM e Llama 3.1-8B
Instale o vLLM e os modelos do HuggingFace
O vLLM baixa grandes modelos de linguagem do HuggingFace por padrão. Em geral, sempre que você quiser usar um novo modelo no HuggingFace, você deve fazer um pip install--update ou -U. Além disso, você precisará de uma GPU para executar a inferência dos modelos Llama 3.1 do Meta com vLLM.
Para uma lista completa de todos os modelos suportados pelo vLLM, veja esta página de documentação.
# (Recomendado) Crie um novo ambiente conda.
conda create -n myenv python=3.11 -y
conda activate myenv
# Instale o vLLM com CUDA 12.1.
pip install -U vllm transformers torch
importar vllm, torch
from vllm import LLM, SamplingParams
# Limpar a cache de memória da GPU.
torch.cuda.empty_cache()
# Verifica a GPU.
!nvidia-smi
Para aprender mais sobre como instalar o vLLM, veja sua página installation.
Obter um token HuggingFace
Alguns modelos no HuggingFace, como o Meta Llama 3.1, requerem que o usuário aceite sua licença antes de poder baixar os pesos. Portanto, você deve criar uma conta no HuggingFace, aceitar a licença do modelo, e gerar um token.
Ao visitar esta [página do Llama3.1] (https://huggingface.co/meta-llama/Meta-Llama-3.1-70B) no HuggingFace, você receberá uma mensagem pedindo para concordar com os termos. Clique em "Accept License" para aceitar os termos do Meta antes de descarregar os pesos do modelo. A aprovação geralmente leva menos de um dia.
**Depois de receber a aprovação, tem de gerar um novo token HuggingFace. Os seus tokens antigos não funcionarão com as novas permissões.
Antes de instalar o vLLM, faça login no HuggingFace com seu novo token. Abaixo, eu usei Colab secrets para armazenar o token.
# Faça login no HuggingFace usando seu novo token.
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Executar a geração de RAGs
Na demonstração, nós rodamos o modelo Llama-3.1-8B, que requer GPU e memória considerável para rodar. O exemplo a seguir foi executado no Google Colab Pro (US$ 10/mês) com uma GPU A100. Para saber mais sobre como executar o vLLM, pode consultar a [Quickstart documentation] (https://docs.vllm.ai/en/latest/getting_started/quickstart.html).
# 1. Escolha um modelo
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# 2. Limpa a cache de memória da GPU, vais precisar de tudo!
torch.cuda.empty_cache()
# 3. Instanciar uma instância do modelo vLLM.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Escreve um texto utilizando contextos e fontes retirados do Milvus.
# Separa todos os contextos por um espaço.
contextos_combinados = ' '.join(contextos)
# Lance Martin, LangChain, diz para colocar os melhores contextos no final.
contextos_combinados = ' '.join(reversed(contextos))
# Separa todas as fontes únicas por vírgula.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""Primeiro, verifique se o contexto fornecido é relevante para a
a pergunta do utilizador. Em segundo lugar, apenas se o Contexto fornecido for fortemente relevante, responder à pergunta utilizando o Contexto. Caso contrário, se o contexto não for muito relevante, responda à pergunta sem utilizar o contexto.
Seja claro, conciso e relevante. Responda claramente, em menos de 2 frases.
Fontes de fundamentação: {source_combined}
Contexto: {contextos_combinados}
Pergunta do utilizador: {SAMPLE_QUESTION}
"""
prompts = [SYSTEM_PROMPT]
Agora, gere uma resposta usando os pedaços recuperados e a pergunta original inserida no prompt.
# Parâmetros de amostragem
parâmetros_amostragem = parâmetros_amostragem(temperatura=0.2, top_p=0.95)
# Invocar o modelo vLLM.
outputs = llm.generate(prompts, sampling_params)
# Imprime os outputs.
for output in outputs:
prompt = output.prompt
texto_gerado = output.outputs[0].text
# !r chama repr(), que imprime uma string entre aspas.
print()
print(f "Pergunta: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Texto gerado: {texto_gerado!r}")

A resposta acima parece-me perfeita!
Se estiveres interessado nesta demonstração, podes experimentá-la e dizer-nos o que pensas. Também podes juntar-te à nossa comunidade Milvus no Discord para conversares diretamente com todos os criadores do GenAI.
Referências
vLLM documentação oficial e página de modelo.
Apresentação do vLLM 2023](https://www.youtube.com/watch?v=80bIUggRJf4) na Ray Summit
Blogue do vLLM: vLLM: Serviço LLM fácil, rápido e barato com PagedAttention
Blog útil sobre como executar o servidor vLLM: Implantando o vLLM: um guia passo a passo

Continue lendo

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.