




Como Escolher o Melhor Modelo de Embedding para RAG em 2026: 10 Modelos Comparados
TL;DR: Testamos 10 modelos de embedding em quatro cenários de produção que benchmarks públicos não cobrem: recuperação cross-modal, recuperação cross-lingual, recuperação de informações-chave e compressão de dimensões. Nenhum modelo vence em tudo. Gemini Embedding 2 é o melhor generalista. O Qwen3-VL-2B de código aberto supera APIs de código fechado em tarefas cross-modal. Se você precisa comprimir dimensões para economizar armazenamento, escolha Voyage Multimodal 3.5 ou Jina Embeddings v4.
Por que o MTEB não é suficiente para escolher um modelo de embedding
A maioria dos protótipos de RAG começa com o text-embedding-3-small da OpenAI. É barato, fácil de integrar e, para recuperação de texto em inglês, funciona bem o suficiente. Mas o RAG em produção supera isso rapidamente. Seu pipeline passa a incluir imagens, PDFs, documentos multilíngues — e um modelo de embedding somente de texto deixa de ser suficiente.
O ranking do MTEB mostra que existem opções melhores. O problema? O MTEB testa apenas recuperação de texto em um único idioma. Ele não cobre recuperação cross-modal (consultas de texto contra coleções de imagens), busca cross-lingual (uma consulta em chinês encontrando um documento em inglês), precisão em documentos longos, nem quanta qualidade você perde ao truncar dimensões de embedding para economizar armazenamento no seu banco de dados vetorial.
Então, qual modelo de embedding você deve usar? Depende dos seus tipos de dados, dos seus idiomas, dos comprimentos dos seus documentos e de você precisar ou não de compressão de dimensões. Construímos um benchmark chamado CCKM e testamos 10 modelos lançados entre 2025 e 2026 exatamente nessas dimensões.
O que é o benchmark CCKM?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) testa quatro capacidades que benchmarks padrão não cobrem:
| Dimensão | O que testa | Por que é importante |
|---|---|---|
| Recuperação cross-modal | Corresponder descrições de texto à imagem correta quando há distratores quase idênticos presentes | Pipelines de RAG multimodal precisam de embeddings de texto e imagem no mesmo espaço vetorial |
| Recuperação cross-lingual | Encontrar o documento correto em inglês a partir de uma consulta em chinês, e vice-versa | Bases de conhecimento em produção geralmente são multilíngues |
| Recuperação de informações-chave | Localizar um fato específico escondido em um documento de 4K–32K caracteres (agulha no palheiro) | Sistemas RAG frequentemente processam documentos longos como contratos e artigos de pesquisa |
| Compressão de dimensões MRL | Medir quanta qualidade o modelo perde quando você trunca embeddings para 256 dimensões | Menos dimensões = menor custo de armazenamento no seu banco de dados vetorial, mas a que custo de qualidade? |
O MTEB não cobre nada disso. O MMEB adiciona multimodalidade, mas ignora negativos difíceis, então os modelos pontuam alto sem provar que conseguem lidar com distinções sutis. O CCKM foi projetado para cobrir o que eles deixam passar.
Quais modelos de embedding testamos? Gemini Embedding 2, Jina Embeddings v4 e mais
Testamos 10 modelos abrangendo tanto serviços de API quanto opções de código aberto, além do CLIP ViT-L-14 como baseline de 2021.
| Modelo | Fonte | Parâmetros | Dimensões | Modalidade | Característica principal |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Não divulgado | 3072 | Texto / imagem / vídeo / áudio / PDF | Todas as modalidades, cobertura mais ampla | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Texto / imagem / PDF | MRL + adaptadores LoRA |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Não divulgado | 1024 | Texto / imagem / vídeo | Equilibrado entre tarefas |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Texto / imagem / vídeo | Open-source, multimodal leve |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Texto / imagem | Arquitetura CLIP modernizada |
| Cohere Embed v4 | Cohere | Não divulgado | Fixo | Texto | Recuperação empresarial |
| OpenAI text-embedding-3-large | OpenAI | Não divulgado | 3072 | Texto | Mais amplamente usado |
| BGE-M3 | BAAI | 568M | 1024 | Texto | Open-source, mais de 100 idiomas |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Texto | Leve, focado em inglês |
| nomic-embed-text | Nomic AI | 137M | 768 | Texto | Ultraleve |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Texto / imagem | Linha de base |
Recuperação cross-modal: quais modelos lidam com busca de texto para imagem?
Se seu pipeline RAG lida com imagens junto com texto, o modelo de embedding precisa colocar ambas as modalidades no mesmo espaço vetorial. Pense em busca de imagens em e-commerce, bases de conhecimento mistas de imagem-texto ou qualquer sistema em que uma consulta de texto precise encontrar a imagem certa.
Método
Pegamos 200 pares imagem-texto do COCO val2017. Para cada imagem, o GPT-4o-mini gerou uma descrição detalhada. Em seguida, escrevemos 3 negativos difíceis por imagem — descrições que diferem da correta por apenas um ou dois detalhes. O modelo precisa encontrar a correspondência certa em um conjunto de 200 imagens e 600 distratores.
Um exemplo do conjunto de dados:
 Malas vintage de couro marrom com adesivos de viagem, incluindo Califórnia e Cuba, colocadas em um bagageiro de metal contra um céu azul — usadas como imagem de teste no benchmark de recuperação cross-modal
Malas vintage de couro marrom com adesivos de viagem, incluindo Califórnia e Cuba, colocadas em um bagageiro de metal contra um céu azul — usadas como imagem de teste no benchmark de recuperação cross-modal
Descrição correta: "A imagem mostra malas vintage de couro marrom com vários adesivos de viagem, incluindo 'California', 'Cuba' e 'New York', colocadas em um bagageiro de metal contra um céu azul claro."
Negativo difícil: Mesma frase, mas "California" vira "Florida" e "blue sky" vira "overcast sky." O modelo precisa realmente entender os detalhes da imagem para diferenciar essas opções.
Pontuação:
- Gerar embeddings para todas as imagens e todos os textos (200 descrições corretas + 600 negativos difíceis).
- Texto para imagem (t2i): Cada descrição busca, entre 200 imagens, a correspondência mais próxima. Ganha um ponto se o principal resultado estiver correto.
- Imagem para texto (i2t): Cada imagem busca, entre todos os 800 textos, a correspondência mais próxima. Ganha um ponto apenas se o principal resultado for a descrição correta, não um negativo difícil.
- Pontuação final: hard_avg_R@1 = (precisão t2i + precisão i2t) / 2
Resultados
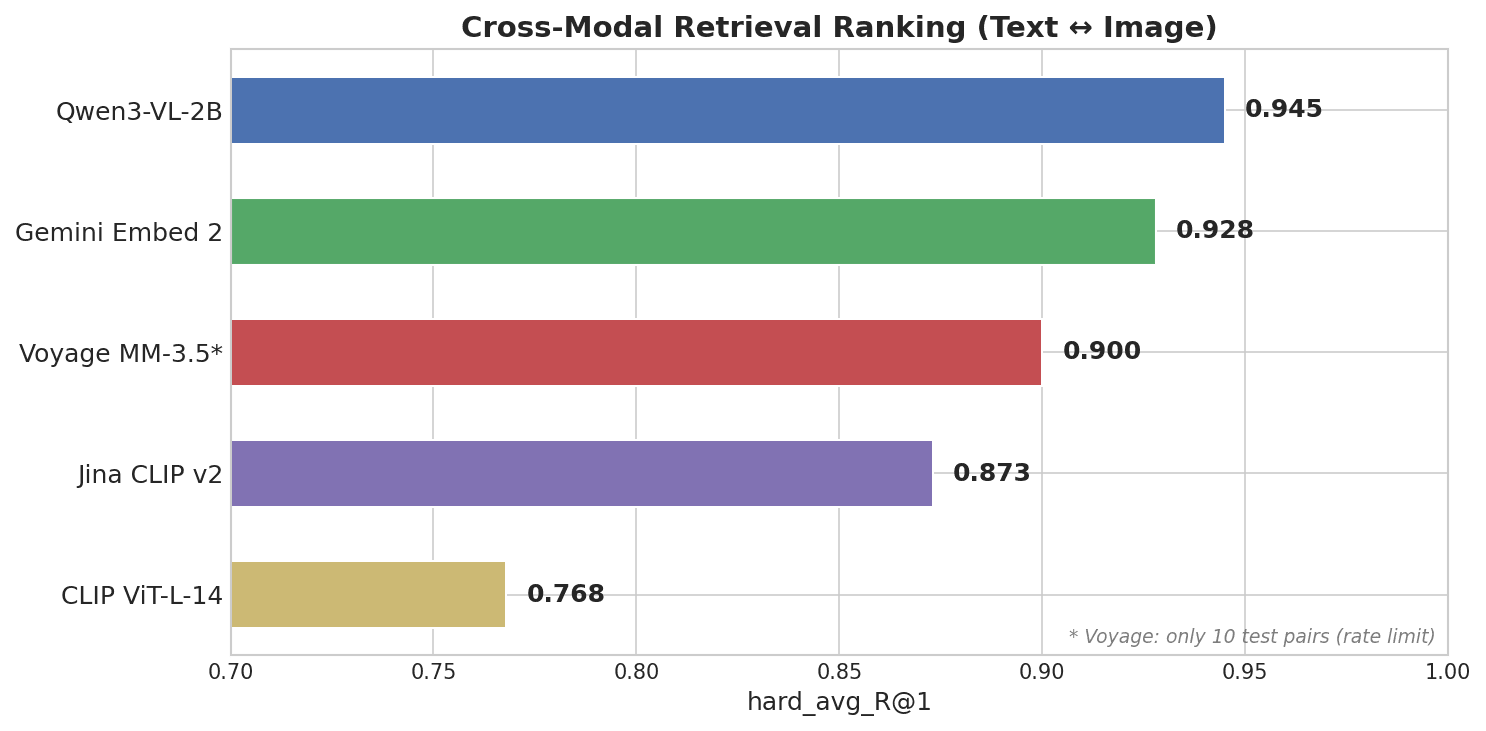 Gráfico de barras horizontal mostrando o ranking de recuperação cross-modal: Qwen3-VL-2B lidera com 0,945, seguido por Gemini Embed 2 com 0,928, Voyage MM-3.5 com 0,900, Jina CLIP v2 com 0,873 e CLIP ViT-L-14 com 0,768
Gráfico de barras horizontal mostrando o ranking de recuperação cross-modal: Qwen3-VL-2B lidera com 0,945, seguido por Gemini Embed 2 com 0,928, Voyage MM-3.5 com 0,900, Jina CLIP v2 com 0,873 e CLIP ViT-L-14 com 0,768
Qwen3-VL-2B, um modelo open-source de 2B parâmetros da equipe Qwen da Alibaba, ficou em primeiro lugar — à frente de todas as APIs closed-source.
Lacuna de modalidade explica a maior parte da diferença. Modelos de embedding mapeiam texto e imagens para o mesmo espaço vetorial, mas, na prática, as duas modalidades tendem a se agrupar em regiões diferentes. A lacuna de modalidade mede a distância L2 entre esses dois agrupamentos. Lacuna menor = recuperação cross-modal mais fácil.
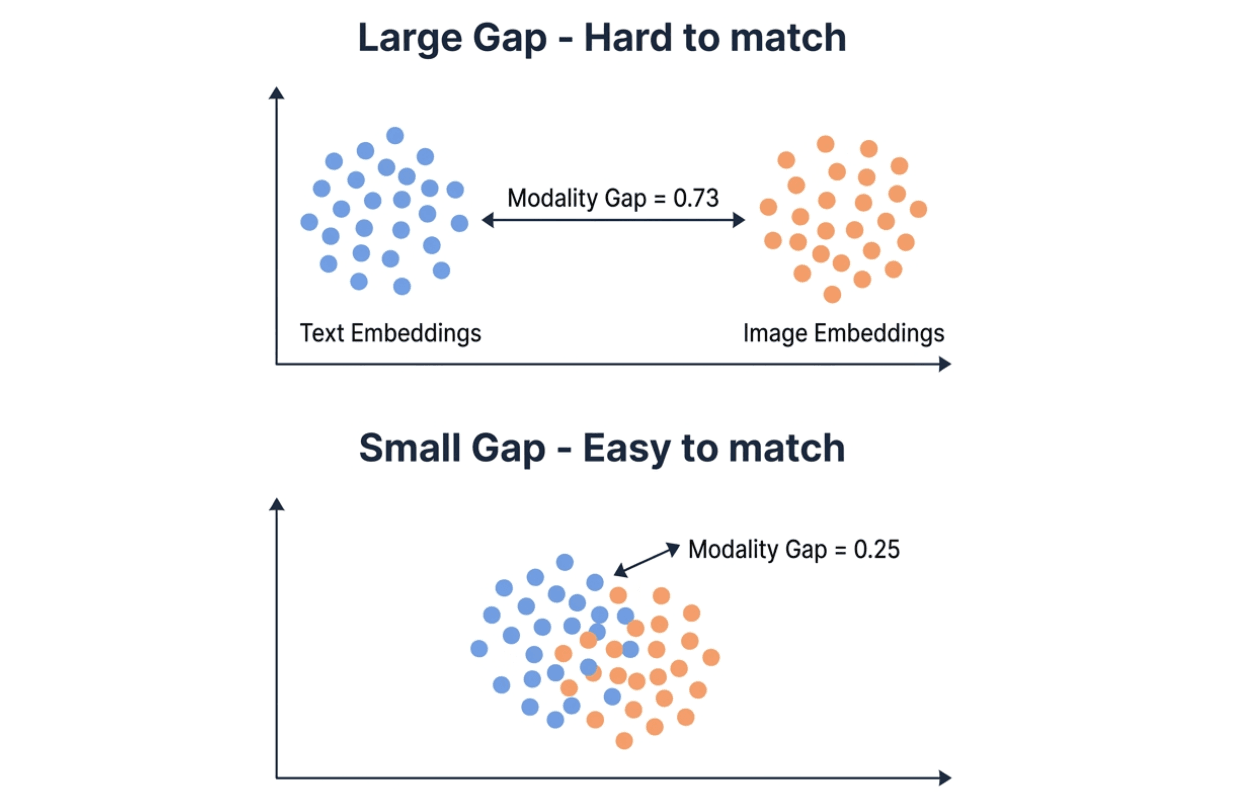 Visualização comparando uma grande lacuna de modalidade (0,73, clusters de embeddings de texto e imagem distantes) versus uma pequena lacuna de modalidade (0,25, clusters sobrepostos) — uma lacuna menor facilita a correspondência cross-modal
Visualização comparando uma grande lacuna de modalidade (0,73, clusters de embeddings de texto e imagem distantes) versus uma pequena lacuna de modalidade (0,25, clusters sobrepostos) — uma lacuna menor facilita a correspondência cross-modal
| Modelo | Pontuação (R@1) | Lacuna de modalidade | Parâmetros |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Desconhecido (fechado) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Desconhecido (fechado) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
A lacuna de modalidade do Qwen é 0,25 — aproximadamente um terço dos 0,73 do Gemini. Em um banco de dados vetorial como o Milvus, uma pequena lacuna de modalidade significa que você pode armazenar embeddings de texto e imagem na mesma coleção e pesquisar em ambos diretamente. Uma grande lacuna pode tornar a busca por similaridade cross-modal menos confiável, e talvez você precise de uma etapa de re-ranqueamento para compensar.
Recuperação cross-lingual: quais modelos alinham significado entre idiomas?
Bases de conhecimento multilíngues são comuns em produção. Um usuário faz uma pergunta em chinês, mas a resposta está em um documento em inglês — ou o contrário. O modelo de embedding precisa alinhar o significado entre idiomas, não apenas dentro de um único idioma.
Método
Criamos 166 pares de frases paralelas em chinês e inglês em três níveis de dificuldade:
 Níveis de dificuldade cross-lingual: o nível Fácil mapeia traduções literais como 我爱你 para I love you; o nível Médio mapeia frases parafraseadas como 这道菜太咸了 para This dish is too salty com negativos difíceis; o nível Difícil mapeia expressões idiomáticas chinesas como 画蛇添足 para gilding the lily com negativos difíceis semanticamente diferentes
Níveis de dificuldade cross-lingual: o nível Fácil mapeia traduções literais como 我爱你 para I love you; o nível Médio mapeia frases parafraseadas como 这道菜太咸了 para This dish is too salty com negativos difíceis; o nível Difícil mapeia expressões idiomáticas chinesas como 画蛇添足 para gilding the lily com negativos difíceis semanticamente diferentes
Cada idioma também recebe 152 distratores negativos difíceis.
Pontuação:
- Gerar embeddings para todo o texto em chinês (166 corretos + 152 distratores) e todo o texto em inglês (166 corretos + 152 distratores).
- Chinês → Inglês: Cada frase em chinês pesquisa 318 textos em inglês em busca de sua tradução correta.
- Inglês → Chinês: O mesmo no sentido inverso.
- Pontuação final: hard_avg_R@1 = (precisão zh→en + precisão en→zh) / 2
Resultados
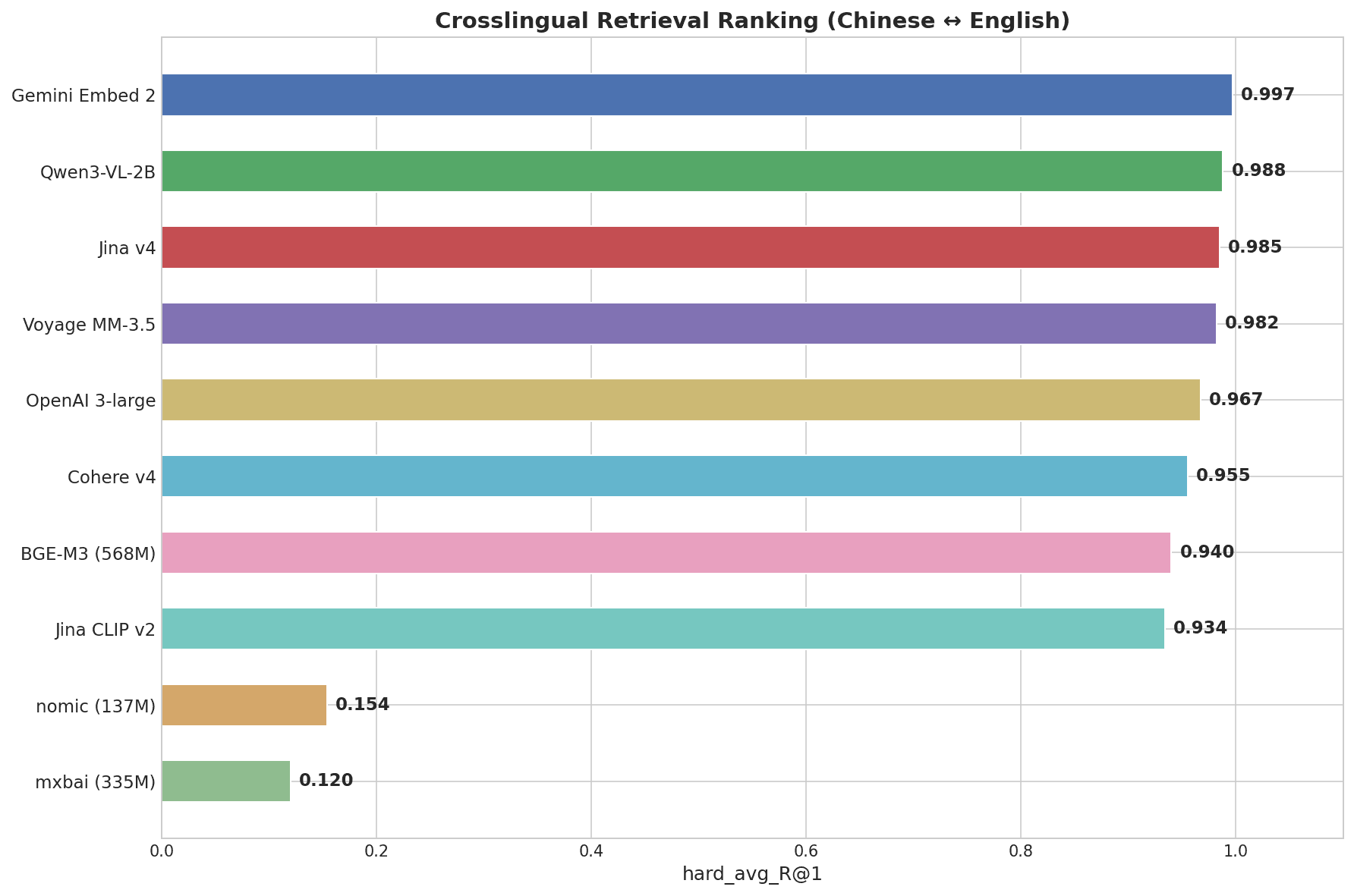 Gráfico de barras horizontal mostrando o ranking de recuperação cross-lingual: Gemini Embed 2 lidera com 0,997, seguido por Qwen3-VL-2B com 0,988, Jina v4 com 0,985, Voyage MM-3.5 com 0,982, até mxbai com 0,120
Gráfico de barras horizontal mostrando o ranking de recuperação cross-lingual: Gemini Embed 2 lidera com 0,997, seguido por Qwen3-VL-2B com 0,988, Jina v4 com 0,985, Voyage MM-3.5 com 0,982, até mxbai com 0,120
Gemini Embedding 2 obteve 0,997 — a pontuação mais alta entre todos os modelos testados. Foi o único modelo a obter 1,000 perfeito no nível Difícil, onde pares como "画蛇添足" → "gilding the lily" exigem compreensão semântica genuína entre idiomas, não correspondência de padrões.
| Modelo | Pontuação (R@1) | Fácil | Médio | Difícil (expressões idiomáticas) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
Os 7 principais modelos todos superam 0,93 na pontuação geral — a diferenciação real acontece no nível Difícil (expressões idiomáticas chinesas). nomic-embed-text e mxbai-embed-large, ambos modelos leves focados em inglês, pontuam perto de zero em tarefas cross-lingual.
Recuperação de informações-chave: os modelos conseguem encontrar uma agulha em um documento de 32K tokens?
Sistemas RAG frequentemente processam documentos extensos — contratos jurídicos, artigos de pesquisa, relatórios internos contendo dados não estruturados. A questão é se um modelo de embedding ainda consegue encontrar um fato específico enterrado em milhares de caracteres de texto ao redor.
Método
Usamos artigos da Wikipedia de comprimentos variados (4K a 32K caracteres) como o palheiro e inserimos um único fato fabricado — a agulha — em diferentes posições: início, 25%, 50%, 75% e fim. O modelo precisa determinar, com base em um embedding de consulta, qual versão do documento contém a agulha.
Exemplo:
- Agulha: "A Meridian Corporation reportou receita trimestral de $847,3 milhões no 3º trimestre de 2025."
- Consulta: "Qual foi a receita trimestral da Meridian Corporation?"
- Palheiro: Um artigo da Wikipedia de 32.000 caracteres sobre fotossíntese, com a agulha escondida em algum lugar dentro dele.
Pontuação:
- Gerar embeddings para a consulta, o documento com a agulha e o documento sem ela.
- Se a consulta for mais semelhante ao documento que contém a agulha, contar como um acerto.
- Calcular a acurácia média em todos os comprimentos de documento e posições da agulha.
- Métricas finais: overall_accuracy e degradation_rate (quanto a acurácia cai do documento mais curto para o mais longo).
Resultados
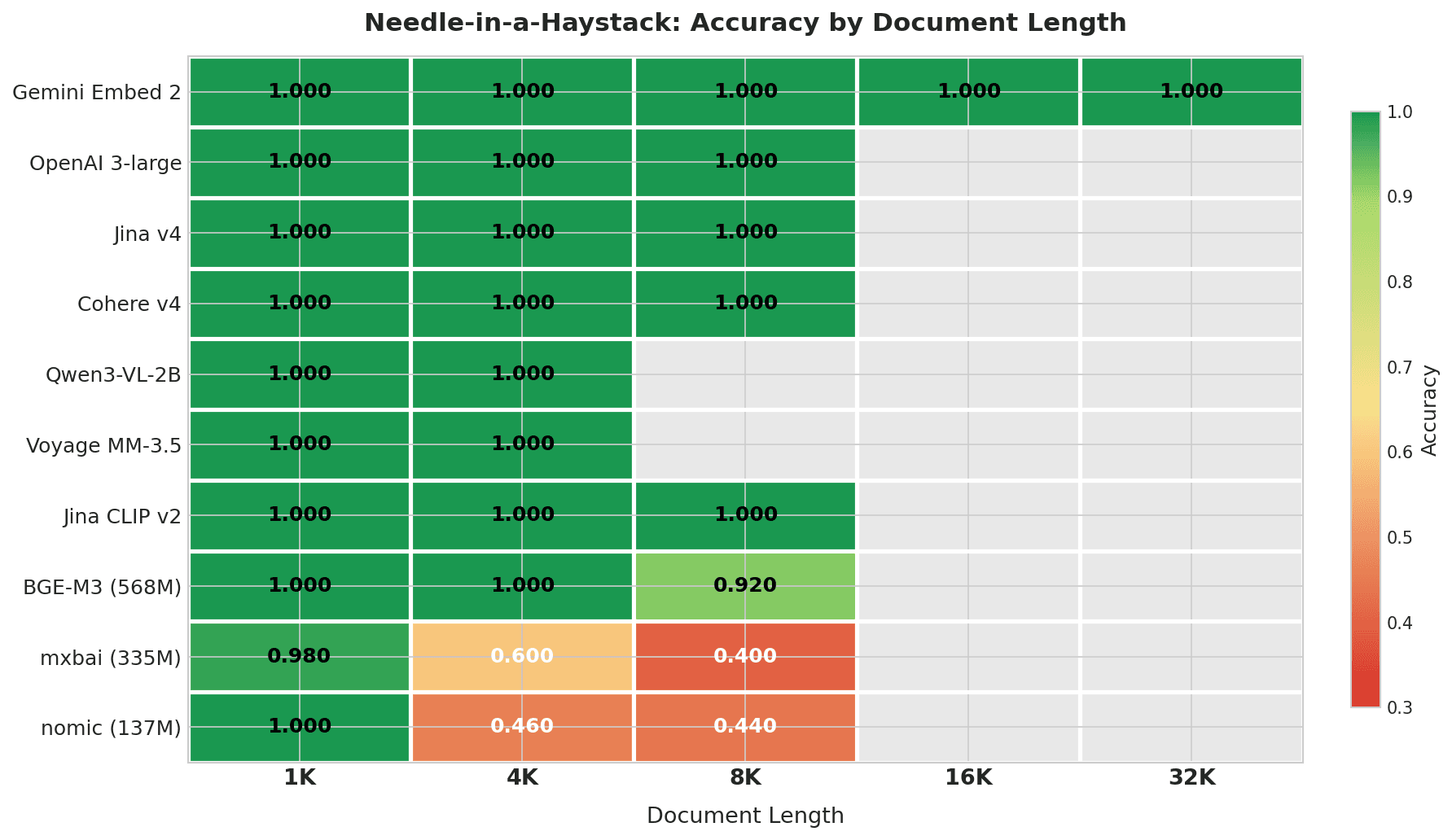 Mapa de calor mostrando a acurácia Needle-in-a-Haystack por comprimento de documento: Gemini Embed 2 pontua 1.000 em todos os comprimentos até 32K; os 7 principais modelos pontuam perfeitamente dentro de suas janelas de contexto; mxbai e nomic degradam acentuadamente a partir de 4K+
Mapa de calor mostrando a acurácia Needle-in-a-Haystack por comprimento de documento: Gemini Embed 2 pontua 1.000 em todos os comprimentos até 32K; os 7 principais modelos pontuam perfeitamente dentro de suas janelas de contexto; mxbai e nomic degradam acentuadamente a partir de 4K+
Gemini Embedding 2 é o único modelo testado em toda a faixa de 4K–32K, e pontuou perfeitamente em todos os comprimentos. Nenhum outro modelo neste teste tem uma janela de contexto que alcance 32K.
| Modelo | 1K | 4K | 8K | 16K | 32K | Geral | Degradação |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" significa que o comprimento do documento excede a janela de contexto do modelo.
Os 7 principais modelos pontuam perfeitamente dentro de suas janelas de contexto. BGE-M3 começa a escorregar em 8K (0.920). Os modelos leves (mxbai e nomic) caem para 0,4–0,6 com apenas 4K caracteres — aproximadamente 1.000 tokens. Para mxbai, essa queda reflete em parte sua janela de contexto de 512 tokens truncando a maior parte do documento.
Compressão de Dimensão MRL: Quanta Qualidade Você Perde em 256 Dimensões?
Matryoshka Representation Learning (MRL) é uma técnica de treinamento que torna as primeiras N dimensões de um vetor significativas por si só. Pegue um vetor de 3072 dimensões, trunque-o para 256, e ele ainda preserva a maior parte de sua qualidade semântica. Menos dimensões significam menores custos de armazenamento e memória no seu banco de dados vetorial — passar de 3072 para 256 dimensões é uma redução de armazenamento de 12x.
 Ilustração mostrando truncamento de dimensão MRL: 3072 dimensões com qualidade total, 1024 a 95%, 512 a 90%, 256 a 85% — com economia de armazenamento de 12x em 256 dimensões
Ilustração mostrando truncamento de dimensão MRL: 3072 dimensões com qualidade total, 1024 a 95%, 512 a 90%, 256 a 85% — com economia de armazenamento de 12x em 256 dimensões
Método
Usamos 150 pares de frases do benchmark STS-B, cada um com uma pontuação de similaridade anotada por humanos (0–5). Para cada modelo, geramos embeddings nas dimensões completas e depois truncamos para 1024, 512 e 256.
 Exemplos de dados STS-B mostrando pares de frases com pontuações de similaridade humana: A girl is styling her hair vs A girl is brushing her hair pontuam 2,5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach pontuam 3,6
Exemplos de dados STS-B mostrando pares de frases com pontuações de similaridade humana: A girl is styling her hair vs A girl is brushing her hair pontuam 2,5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach pontuam 3,6
Pontuação:
- Em cada nível de dimensão, calcule a similaridade de cosseno entre os embeddings de cada par de frases.
- Compare o ranking de similaridade do modelo com o ranking humano usando ρ de Spearman (correlação de postos).
O que é o ρ de Spearman? Ele mede o quão bem dois rankings concordam. Se humanos classificam o par A como o mais similar, B em segundo, C como o menos similar — e as similaridades de cosseno do modelo produzem a mesma ordem A > B > C — então ρ se aproxima de 1,0. Um ρ de 1,0 significa concordância perfeita. Um ρ de 0 significa nenhuma correlação.
Métricas finais: spearman_rho (quanto maior, melhor) e min_viable_dim (a menor dimensão em que a qualidade permanece dentro de 5% do desempenho em dimensão completa).
Resultados
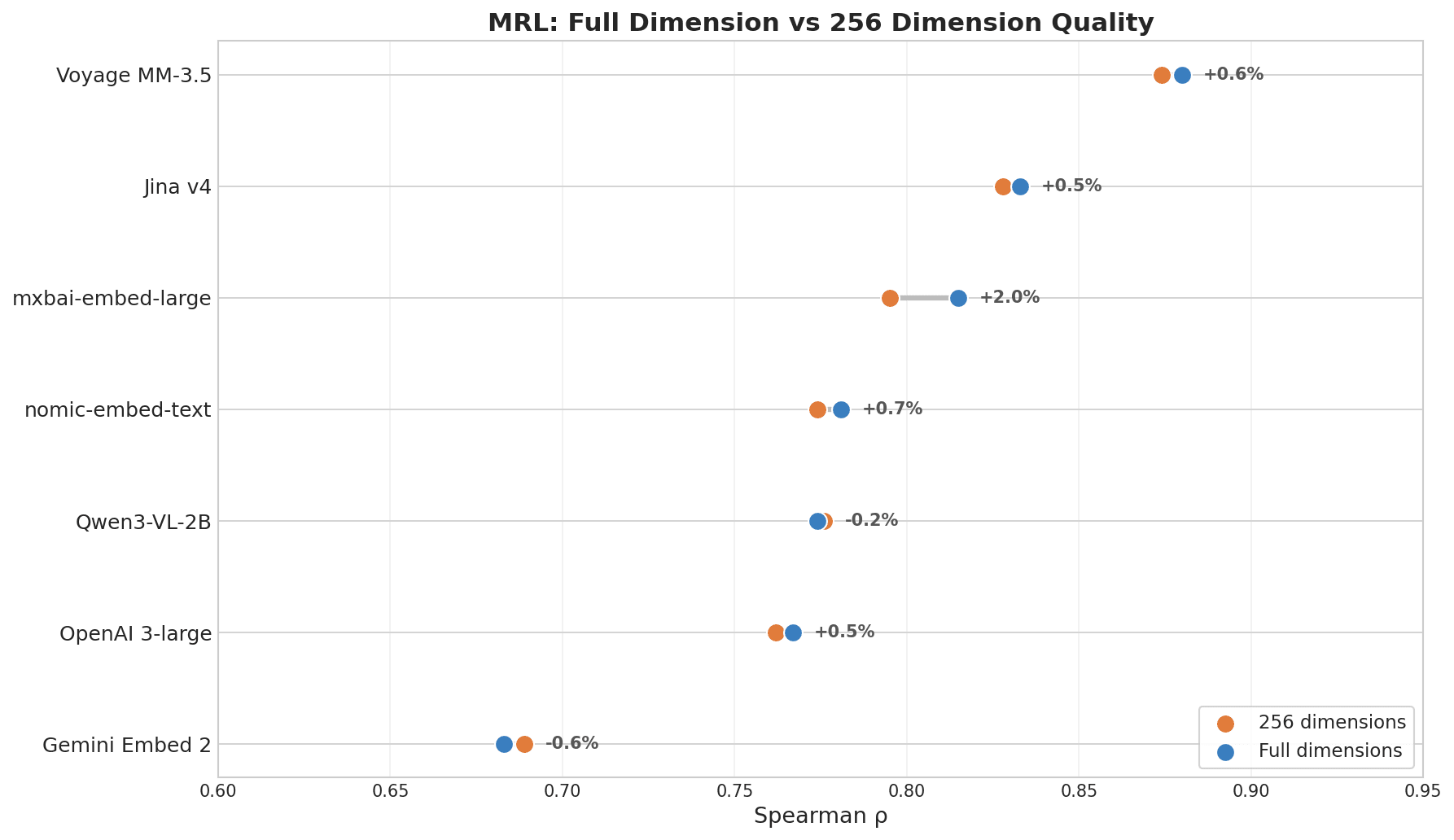 Gráfico de pontos mostrando MRL em dimensão completa vs qualidade em 256 dimensões: Voyage MM-3.5 lidera com mudança de +0,6%, Jina v4 +0,5%, enquanto Gemini Embed 2 aparece no fim com -0,6%
Gráfico de pontos mostrando MRL em dimensão completa vs qualidade em 256 dimensões: Voyage MM-3.5 lidera com mudança de +0,6%, Jina v4 +0,5%, enquanto Gemini Embed 2 aparece no fim com -0,6%
Se você está planejando reduzir custos de armazenamento no Milvus ou em outro banco de dados vetorial truncando dimensões, este resultado importa.
| Modelo | ρ (dim completa) | ρ (256 dim) | Decaimento |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage e Jina v4 lideram porque ambos foram explicitamente treinados com MRL como objetivo. A compressão de dimensões tem pouco a ver com o tamanho do modelo — o que importa é se o modelo foi treinado para isso.
Uma observação sobre a pontuação do Gemini: o ranking MRL reflete o quão bem um modelo preserva a qualidade após o truncamento, não o quão boa é sua recuperação em dimensão completa. A recuperação em dimensão completa do Gemini é forte — os resultados multilíngues e de informações-chave já provaram isso. Ele simplesmente não foi otimizado para encolhimento. Se você não precisa de compressão de dimensões, esta métrica não se aplica a você.
Qual modelo de embedding você deve usar?
Nenhum modelo vence em tudo. Aqui está o scorecard completo:
| Modelo | Params | Multimodal | Multilíngue | Info-chave | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Não divulgado | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Não divulgado | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Não divulgado | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Não divulgado | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" significa que o modelo não oferece suporte a essa modalidade ou capacidade. CLIP é uma linha de base de 2021 para referência.
Aqui está o que se destaca:
- Cross-modal: Qwen3-VL-2B (0,945) em primeiro, Gemini (0,928) em segundo, Voyage (0,900) em terceiro. Um modelo open-source de 2B superou todas as APIs de código fechado. O fator decisivo foi a lacuna de modalidade, não a contagem de parâmetros.
- Cross-lingual: Gemini (0,997) lidera — o único modelo a pontuar perfeitamente no alinhamento em nível de expressões idiomáticas. Os 8 principais modelos todos superam 0,93. Modelos leves apenas em inglês pontuam perto de zero.
- Informações-chave: APIs e grandes modelos open-source pontuam perfeitamente até 8K. Modelos abaixo de 335M começam a degradar em 4K. Gemini é o único modelo que lida com 32K com uma pontuação perfeita.
- Compressão de dimensão MRL: Voyage (0,880) e Jina v4 (0,833) lideram, perdendo menos de 1% em 256 dimensões. Gemini (0,668) fica em último — forte em dimensão completa, não otimizado para truncamento.
Como escolher: Um fluxograma de decisão
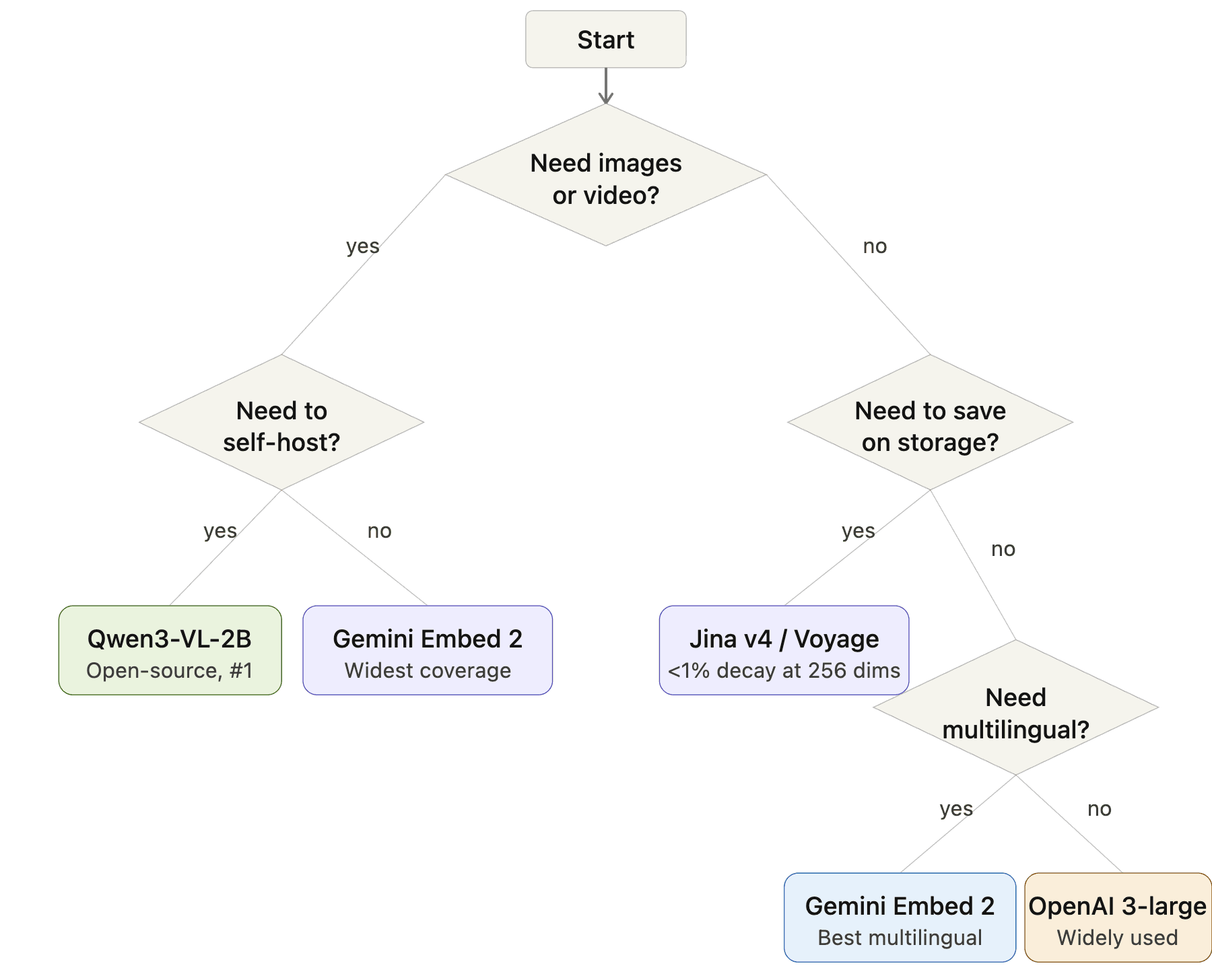 Fluxograma de seleção de modelo de embedding: Início → Precisa de imagens ou vídeo? → Sim: Precisa fazer self-host? → Sim: Qwen3-VL-2B, Não: Gemini Embedding 2. Sem imagens → Precisa economizar armazenamento? → Sim: Jina v4 ou Voyage, Não: Precisa de multilinguismo? → Sim: Gemini Embedding 2, Não: OpenAI 3-large
Fluxograma de seleção de modelo de embedding: Início → Precisa de imagens ou vídeo? → Sim: Precisa fazer self-host? → Sim: Qwen3-VL-2B, Não: Gemini Embedding 2. Sem imagens → Precisa economizar armazenamento? → Sim: Jina v4 ou Voyage, Não: Precisa de multilinguismo? → Sim: Gemini Embedding 2, Não: OpenAI 3-large
O melhor generalista: Gemini Embedding 2
No geral, Gemini Embedding 2 é o modelo mais forte neste benchmark.
Pontos fortes: Primeiro em cross-lingual (0,997) e recuperação de informações-chave (1,000 em todos os comprimentos até 32K). Segundo em cross-modal (0,928). A cobertura de modalidades mais ampla — cinco modalidades (texto, imagem, vídeo, áudio, PDF), enquanto a maioria dos modelos chega a no máximo três.
Pontos fracos: Último em compressão MRL (ρ = 0,668). Superado em cross-modal pelo Qwen3-VL-2B open-source.
Se você não precisa de compressão de dimensão, o Gemini não tem concorrente real na combinação de recuperação cross-lingual + documentos longos. Mas, para precisão cross-modal ou otimização de armazenamento, modelos especializados se saem melhor.
Limitações
- Não incluímos todos os modelos que valem a pena considerar — o NV-Embed-v2 da NVIDIA e o v5-text da Jina estavam na lista, mas não entraram nesta rodada.
- Focamos nas modalidades de texto e imagem; embedding de vídeo, áudio e PDF (apesar de alguns modelos alegarem suporte) não foi coberto.
- Recuperação de código e outros cenários específicos de domínio ficaram fora do escopo.
- Os tamanhos das amostras foram relativamente pequenos, então diferenças de classificação estreitas entre modelos podem estar dentro do ruído estatístico.
Os resultados deste artigo estarão desatualizados em até um ano. Novos modelos são lançados constantemente, e o ranking se reorganiza a cada lançamento. O investimento mais duradouro é construir seu próprio pipeline de avaliação — definir seus tipos de dados, seus padrões de consulta, os comprimentos dos seus documentos e submeter novos modelos aos seus próprios testes quando forem lançados. Benchmarks públicos como MTEB, MMTEB e MMEB valem a pena monitorar, mas a decisão final deve sempre vir dos seus próprios dados.
Nosso código de benchmark é open-source no GitHub — faça um fork dele e adapte-o ao seu caso de uso.
Depois de escolher seu modelo de embedding, você precisa de um lugar para armazenar e pesquisar esses vetores em escala. Milvus é o banco de dados vetorial open-source mais amplamente adotado do mundo, com mais de 43 mil estrelas no GitHub, criado exatamente para isso — ele suporta dimensões truncadas por MRL, coleções multimodais mistas, busca híbrida combinando vetores densos e esparsos, e escala de um laptop a bilhões de vetores.
- Comece com o guia de início rápido do Milvus, ou instale com
pip install pymilvus. - Entre no Milvus Slack ou no Milvus Discord para fazer perguntas sobre integração de modelos de embedding, estratégias de indexação vetorial ou escalabilidade em produção.
- Agende uma sessão gratuita do Milvus Office Hours para revisar sua arquitetura RAG — podemos ajudar com seleção de modelos, design de esquema de coleção e ajuste de desempenho.
- Se você preferir evitar o trabalho de infraestrutura, o Zilliz Cloud (Milvus gerenciado) oferece um nível gratuito para começar.
Algumas perguntas que surgem quando engenheiros estão escolhendo um modelo de embedding para RAG em produção:
P: Devo usar um modelo de embedding multimodal mesmo que eu só tenha dados de texto no momento?
Depende do seu roadmap. Se seu pipeline provavelmente adicionará imagens, PDFs ou outras modalidades nos próximos 6–12 meses, começar com um modelo multimodal como Gemini Embedding 2 ou Voyage Multimodal 3.5 evita uma migração dolorosa depois — você não precisará gerar embeddings novamente para todo o seu conjunto de dados. Se você tem certeza de que será apenas texto no futuro previsível, um modelo focado em texto como OpenAI 3-large ou Cohere Embed v4 oferecerá melhor preço/desempenho.
P: Quanto armazenamento a compressão de dimensão MRL realmente economiza em um banco de dados vetorial?
Passar de 3072 dimensões para 256 dimensões é uma redução de 12x no armazenamento por vetor. Para uma coleção do Milvus com 100 milhões de vetores em float32, isso equivale aproximadamente a 1,14 TB → 95 GB. O ponto-chave é que nem todos os modelos lidam bem com truncamento — Voyage Multimodal 3.5 e Jina Embeddings v4 perdem menos de 1% de qualidade em 256 dimensões, enquanto outros degradam significativamente.
P: O Qwen3-VL-2B é realmente melhor que o Gemini Embedding 2 para busca cross-modal?
No nosso benchmark, sim — o Qwen3-VL-2B marcou 0,945 contra 0,928 do Gemini em recuperação cross-modal difícil com distratores quase idênticos. O principal motivo é a lacuna de modalidade muito menor do Qwen (0,25 vs 0,73), o que significa que embeddings de texto e imagem se agrupam mais próximos no espaço vetorial. Dito isso, o Gemini cobre cinco modalidades enquanto o Qwen cobre três, então se você precisa de embedding de áudio ou PDF, o Gemini é a única opção.
P: Posso usar esses modelos de embedding diretamente com o Milvus?
Sim. Todos esses modelos geram vetores float padrão, que você pode inserir no Milvus e pesquisar com similaridade de cosseno, distância L2 ou produto interno. O PyMilvus funciona com qualquer modelo de embedding — gere seus vetores com o SDK do modelo e depois armazene-os e pesquise-os no Milvus. Para vetores truncados por MRL, basta definir a dimensão da coleção para o seu alvo (por exemplo, 256) ao criar a coleção.

Continue lendo

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.