




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
이 통합 기능을 무료로 사용하세요.
밀버스와 질리즈 클라우드의 벡터 검색 기능을 결합한 데이터 처리 기능
데이터브릭스는 데이터 처리와 머신 러닝 작업을 간소화하는 통합 분석 플랫폼입니다. 오픈 소스 분산 컴퓨팅 시스템인 Apache Spark를 기반으로 구축되었습니다. 데이터 엔지니어, 데이터 과학자, 분석가들이 빅데이터 프로젝트에서 협업할 수 있는 협업 환경을 제공합니다. 데이터브릭은 Spark 클러스터 관리의 복잡성을 제거하여 사용자가 데이터 분석과 머신 러닝 작업에 집중할 수 있도록 해줍니다. 대화형 노트북, 자동화된 클러스터 관리, 다양한 데이터 소스 및 머신 러닝 라이브러리에 대한 기본 지원 기능을 제공합니다. 전반적으로 데이터브릭스는 Spark의 사용성과 확장성을 향상시켜 조직이 대규모 데이터 세트에서 인사이트를 더 쉽게 도출할 수 있도록 해줍니다.
Spark Milvus 커넥터는 Apache Spark와 Milvus 간의 시너지 효과를 창출하여 사용자가 Spark의 처리 능력과 Milvus의 벡터 데이터 저장 및 쿼리 기능을 함께 활용할 수 있게 해줍니다. 이러한 통합을 통해 Milvus와 다른 스토리지 시스템 또는 데이터베이스 간의 원활한 데이터 전송 및 통합, Milvus 내의 간소화된 데이터 처리 및 분석, Spark MLlib 및 기타 AI 라이브러리를 활용한 효율적인 벡터 처리 작업 등 다양한 가치 있는 애플리케이션을 활용할 수 있습니다.
동일한 커넥터를 질리즈 클라우드와 데이터브릭스 간에 사용할 수 있어, AI 기반 검색에 중요한 오프라인 처리에서 온라인으로의 데이터 전환을 간소화합니다.
통합의 주요 특징은 다음과 같습니다:
- 간단한 유틸리티 함수 호출을 통해 벡터 생성 Spark 작업을 활성화하여 사용자 정의 글루 코드나 추가 Spark 작업이 필요 없이 데이터를 Milvus에 직접 로드할 수 있습니다.
- Spark-Milvus 커넥터를 사용해 Spark 데이터프레임 레코드를 Milvus에 직접 삽입하면 통합이 간소화되어 연결 설정 코드와 API 호출이 필요 없습니다.
작동 방식
Spark에서 Milvus로 데이터를 전송하는 과정을 자세히 살펴보겠습니다. 기존에는 이 작업을 수행하려면 복잡한 백엔드 글루 코드가 필요했습니다. 하지만 Spark-Milvus 커넥터를 사용하면 Spark 애플리케이션 내에서 단일 함수 호출로 간소화할 수 있습니다.
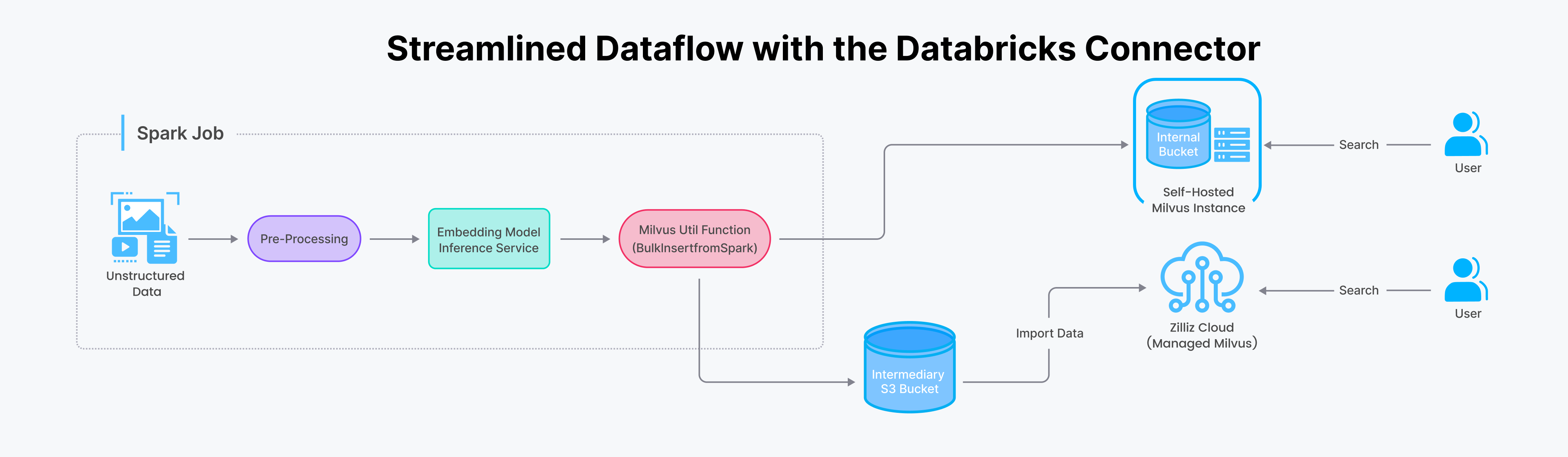 데이터브릭스 커넥터로 간소화된 데이터 흐름.png
데이터브릭스 커넥터로 간소화된 데이터 흐름.png
Spark/Databricks 커넥터를 사용하면 실시간 업데이트를 위한 스트리밍과 대용량 데이터 세트의 일괄 처리 두 가지 방법으로 데이터를 질리즈 클라우드(또는 Milvus)로 가져올 수 있습니다. 효과적인 사용 방법에 대한 단계별 가이드는 예제 노트북을 참조하세요.
스파크 및 데이터브릭스 커넥터 사용 방법 알아보기
질리즈 클라우드, 스파크 및 데이터브릭스 커넥터 사용을 시작하는 데 도움이 되는 다음 리소스를 확인하세요.
스파크 밀버스 커넥터
- 문서
- 깃허브 리포지토리](https://github.com/zilliztech/spark-milvus)
데이터브릭스 커넥터
- 예제 노트북](https://zilliz.com/databricks_zilliz_demos)