




Denormalizzazione del database: una guida completa

Denormalizzazione del database: una guida completa
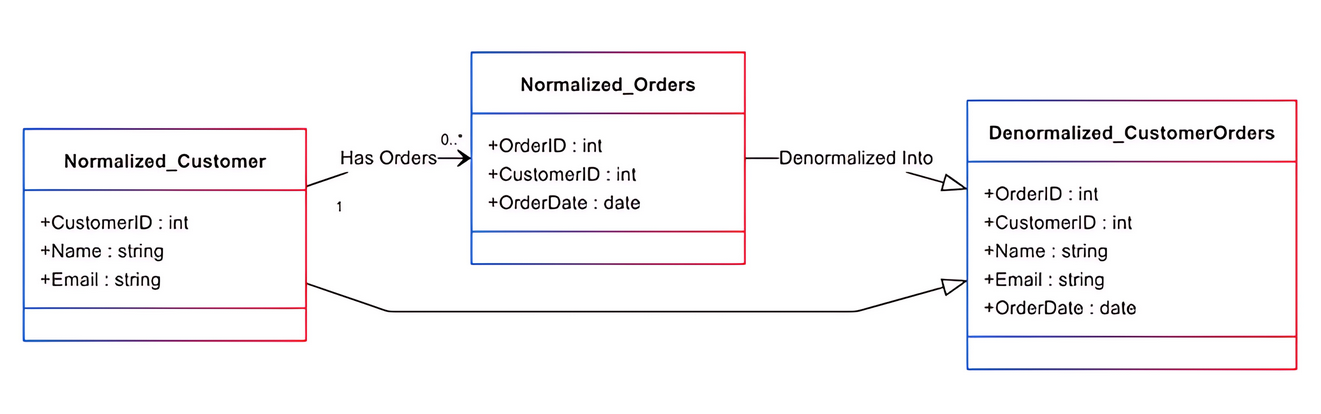
Figura 1: Illustrazione della denormalizzazione del database
Perché alcuni database gestiscono le query più rapidamente di altri, anche quando trattano grandi quantità di informazioni? La risposta risiede nell’indicizzazione del database, nell’ottimizzazione delle query e nell’architettura di archiviazione. Il recupero rapido dei dati è fondamentale, poiché migliora le prestazioni, l’esperienza utente e l’efficacia complessiva.
La normalizzazione tradizionale dei database mantiene l’integrità dei dati organizzandoli in tabelle con relazioni ben definite. Sebbene la normalizzazione migliori l’accuratezza dei dati, tende a causare un collo di bottiglia nelle prestazioni nei sistemi che utilizzano molte join. Con così tante tabelle e join, diventa più difficile recuperare i dati, rallentando la reattività dell’applicazione.
Una tecnica utilizzata per ottimizzare le prestazioni del database è la denormalizzazione. La denormalizzazione introduce dati ridondanti nel database per ottimizzare i carichi con molte letture. Ciò riduce la necessità di join complesse, migliorando così le prestazioni delle query.
Questa guida spiegherà il concetto di denormalizzazione del database, lo confronterà con la normalizzazione e ne discuterà i vantaggi. Esamineremo anche i casi d’uso in cui la denormalizzazione del database è vantaggiosa e le sfide che le aziende potrebbero affrontare durante la sua implementazione.
Che cos’è la denormalizzazione del database?
La denormalizzazione del database è una tecnica di ottimizzazione che aggiunge dati duplicati a uno schema precedentemente normalizzato. Questa tecnica migliora le prestazioni di lettura semplificando le query e riducendo il numero di join.
I database normalizzati risentono di molteplici join per recuperare dati tra varie tabelle, risultando lenti quando lavorano con grandi set di dati. La tecnica di denormalizzazione è utile nei sistemi che eseguono operazioni di lettura piuttosto che operazioni di scrittura.
Ad esempio, supponiamo che un database normalizzato contenga tre tabelle separate: clienti, ordini e prodotti. Recuperare lo storico degli ordini di un cliente con i dettagli dei prodotti richiede al database di unire più tabelle, combinando dati da clienti, ordini e prodotti. Uno schema denormalizzato combina dati correlati, come i dettagli dei prodotti, in un’unica tabella per ridurre al minimo le join e migliorare le prestazioni di lettura.
Tuttavia, un aumento delle prestazioni per le operazioni di lettura comporta un costo per le operazioni di scrittura. Gli aggiornamenti coerenti dei dati diventano più complessi perché il database deve mantenere informazioni ridondanti.
Come funziona
Il processo di denormalizzazione trasforma i database normalizzati attraverso una ristrutturazione per migliorare la velocità e le prestazioni delle query e del recupero dei dati. Mentre il processo di normalizzazione elimina i duplicati mantenendo la coerenza dei dati, la denormalizzazione aggiunge dati duplicati specificamente per potenziare le operazioni di lettura nelle applicazioni.
I database che necessitano di reportistica in tempo reale, query ad alta velocità e analisi adottano ampiamente questa tecnica. Di seguito, discuteremo gli approcci alla denormalizzazione e il loro impatto sull’efficacia del database.
 Approcci alla denormalizzazione del database
Approcci alla denormalizzazione del database
Figura 2: Approcci alla denormalizzazione del database
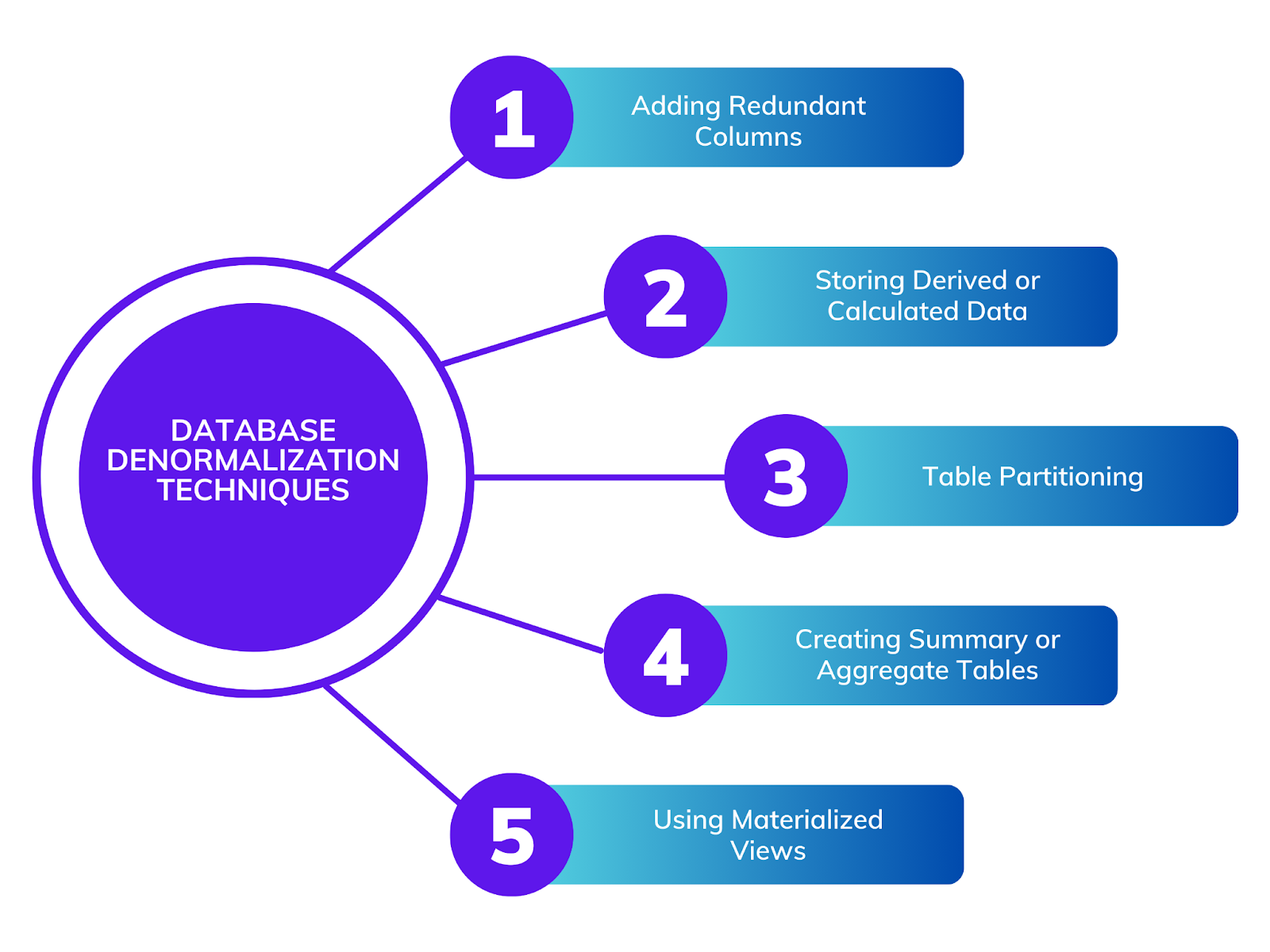
Aggiunta di colonne ridondanti
L’aggiunta di colonne ridondanti è un metodo semplice e standard di denormalizzazione. Consiste nell’aggiungere dati in più posizioni per ridurre le operazioni di join. Ad esempio, la tabella degli ordini di un database ha una chiave esterna denominata ID che la collega alla tabella dei clienti. La tabella dei clienti contiene dettagli essenziali su ciascun cliente, come nome, ID e informazioni di contatto.
Quando vengono analizzati i dettagli degli ordini dei clienti, è necessaria un'operazione di join per estrarre i dati dei clienti. L'unione delle tabelle può essere particolarmente costosa e rallentare le prestazioni complessive. Se le informazioni sul cliente sono memorizzate nella tabella degli ordini, si elimina la necessità di un join e si ottiene un recupero efficiente dei dati.
Sebbene questo metodo migliori considerevolmente la velocità delle query, aumenta i costi di ridondanza dei dati. Quando i dati del cliente cambiano, tutte le copie ridondanti devono essere aggiornate per garantire la coerenza. Ciò richiede l'ottimizzazione delle prestazioni e la gestione dell'integrità dei dati tramite aggiornamenti o trigger. Il bilanciamento di questo problema può essere eseguito utilizzando processi di aggiornamento ben definiti.
Memorizzazione di dati derivati o calcolati
Un altro metodo di denormalizzazione consiste nel memorizzare e precomputare calcoli frequenti. In un sistema di database normalizzato, i calcoli vengono eseguiti dinamicamente al momento della query. Sebbene ciò garantisca che i valori siano aggiornati, influisce anche negativamente sul carico computazionale.
Le prestazioni del sistema ne risentono quando si gestiscono grandi set di dati o numerose richieste di query. Tuttavia, le prestazioni possono essere migliorate aggiungendo questi valori come colonne aggiuntive all'interno delle righe delle tabelle esistenti.
Ad esempio, il database può prememorizzare gli importi totali degli ordini nella tabella degli ordini, in modo che gli utenti non debbano ricalcolare queste informazioni quando richiedono la cronologia dei loro ordini. Il sistema di database può fornire il valore senza elaborazione aggiuntiva perché questi valori sono già memorizzati.
Questa tecnica è vantaggiosa nel settore finanziario, nell'e-commerce e nei sistemi di BI, che hanno un elevato volume di dati che richiede calcoli aggregati e complessi. Tuttavia, mantenere l'integrità dei valori precomputati è fondamentale. Ciò rende successivamente necessari aggiornamenti periodici o attivazioni di trigger basati sui cambiamenti nei dati.
Partizionamento delle tabelle
Il partizionamento delle tabelle è un approccio chiave alla denormalizzazione che suddivide le tabelle di grandi dimensioni in partizioni per migliorare l'elaborazione delle query e la velocità di recupero dei dati. Fornisce risultati eccezionali quando si elaborano database estesi che contengono log delle transazioni, record di audit e set di dati storici. È ulteriormente suddiviso in due parti:
Partizionamento orizzontale: La tecnica di partizionamento divide una tabella in partizioni più piccole in base a criteri come parametri di data, aree geografiche e divisioni di utenti. Ad esempio, un rivenditore online con milioni di transazioni di vendita può dividere la propria tabella degli ordini in base a partizioni annuali. Le prestazioni migliorano quando le query richiedono transazioni recenti perché necessitano della scansione di un sottoinsieme di dati ridotto anziché dell'intera tabella.
Partizionamento verticale: Il partizionamento verticale funziona diversamente dal partizionamento orizzontale perché separa le tabelle in sezioni distinte basate sulle colonne. Divide le tabelle in due parti posizionando le colonne a cui si accede frequentemente accanto a quelle a cui si accede meno frequentemente, in modo che le query debbano recuperare solo i dati necessari. L'approccio si dimostra vantaggioso per le tabelle ampie contenenti numerosi attributi perché consente alle query di accedere solo ai campi essenziali.
Entrambi i metodi di partizionamento migliorano l'ottimizzazione dello storage e riducono il tempo di esecuzione delle query, aggiungendo un valore significativo ai database ad alte prestazioni. Tuttavia, i metodi aumentano la complessità dell'indicizzazione e del partizionamento e possono comportare inefficienze nelle query se non vengono applicate strategie adeguate.
Creazione di tabelle di riepilogo o aggregate
Le applicazioni di generazione di report e di elaborazione dell'analisi dei dati spesso estraggono statistiche di riepilogo in tempo reale dall'input grezzo. Questo in genere richiede una potenza di elaborazione significativa. Pertanto, un approccio consiste nell'aggregare le tabelle. Invece del ricalcolo, una tabella di riepilogo può essere utilizzata come punto di archiviazione, consentendo l'accesso istantaneo ai dati preaggregati.
Considera un’azienda retail che analizza le prestazioni di vendita in più regioni. Creare una tabella di riepilogo con le vendite totali aggregate per mese per ciascuna regione renderebbe facile comprendere gli insight di alto livello.
Questa tabella potrebbe essere aggiornata in tempo reale, tramite trigger, oppure con aggiornamenti batch pianificati. La tabella di riepilogo offre un’esecuzione delle query più rapida perché contiene meno righe rispetto alla tabella delle transazioni originale, migliorando la reattività di dashboard e report.
Sebbene questo metodo migliori gli insight di alto livello, richiede anche un solido meccanismo di aggiornamento dei dati. L’elaborazione batch o le pipeline ETL possono garantire la conservazione di dati di riepilogo aggiornati.
Utilizzo delle viste materializzate
Le viste materializzate sono una funzionalità avanzata di ottimizzazione che crea oggetti fisici di database contenenti i risultati dell’esecuzione delle query. Le viste standard richiedono l’esecuzione dinamica delle query a ogni accesso. Tuttavia, le viste materializzate memorizzano i loro dati su disco, così gli utenti possono recuperare le informazioni istantaneamente senza ulteriori elaborazioni.
Prendiamo l’esempio di un sito web di e-commerce che monitora gli acquisti dei clienti. I proprietari del sito possono creare una vista materializzata che tiene traccia della spesa totale per cliente all’interno di diverse categorie di prodotti. Il database recupera risultati precalcolati invece di eseguire calcoli in tempo reale, perché questo approccio offre risposte alle query più rapide.
Le viste materializzate possono essere aggiornate periodicamente o in modo incrementale a seconda dei requisiti del sistema. La tecnica offre vantaggi eccezionali ai database che richiedono join, aggregazioni e trasformazioni in più passaggi.
Confronto: denormalizzazione vs. normalizzazione
La scelta tra normalizzazione e denormalizzazione per la progettazione del database dipende dai requisiti di velocità delle prestazioni, efficienza di archiviazione e coerenza dei dati. Questa tabella mostra le differenze tra denormalizzazione e normalizzazione.
| Aspetto | Normalizzazione | Denormalizzazione |
| Scopo | Ridurre la ridondanza | Migliorare le prestazioni di lettura |
| Struttura dei dati | Più tabelle correlate | Meno tabelle, dati ridondanti |
| Complessità delle query | Join complessi | Query semplificate |
| Ideale per | Applicazioni con molte scritture | Applicazioni con molte letture |
| Integrità dei dati | Alta | Potenzialmente compromessa |
| Uso dello storage | Efficiente | Aumentato |
| Manutenzione | Semplificata | Più complessa |
| Anomalie di aggiornamento | Ridotte al minimo | Rischio aumentato |
Il processo di selezione del database richiede l’analisi dei modelli di recupero dei dati, dei requisiti di velocità di aggiornamento e delle specifiche di prestazione del sistema. Un database adeguatamente bilanciato mantiene efficienza operativa e scalabilità.
Vantaggi e sfide
La denormalizzazione è un metodo di ottimizzazione che aggiunge dati ridondanti per potenziare le operazioni di lettura e la velocità di esecuzione delle query. Tuttavia, gli incrementi di prestazioni possono creare problemi di archiviazione e anomalie. I vantaggi della denormalizzazione richiedono un’implementazione bilanciata che impedisca l’insorgere di potenziali rischi. Ecco alcuni dei vantaggi e delle sfide:
Vantaggi della denormalizzazione
Complessità applicativa ridotta: la denormalizzazione semplifica la logica applicativa eliminando la necessità di join complessi e query su più tabelle. Ciò migliora la leggibilità e la semplicità delle query, portando a una maggiore produttività degli sviluppatori.
Prestazioni migliorate nei sistemi distribuiti: Il recupero dei dati da più nodi nei database distribuiti porta a prestazioni ritardate. La denormalizzazione colloca i dati duplicati vicino ai loro principali punti di accesso. Questo riduce la necessità di recupero dei dati da nodo a nodo. La tecnica si dimostra preziosa sia per i sistemi basati sul cloud sia per le architetture scalate orizzontalmente.
Maggiore efficienza del data warehousing: I data warehouse richiedono una gestione efficiente delle attività analitiche che eseguono calcoli complessi e procedure di aggregazione. La denormalizzazione migliora le prestazioni di lettura archiviando dati pre-uniti o pre-aggregati, eliminando la necessità di trasformazioni dei dati in tempo reale.
Facilita l'analisi in tempo reale: Le applicazioni che eseguono analisi necessitano di accesso immediato ai dati per ottenere insight rapidi. La denormalizzazione riduce la necessità di calcoli complessi in tempo reale archiviando valori precalcolati con dati ridondanti.
Reporting ottimizzato: I database denormalizzati mantengono dati preelaborati per la creazione istantanea di report e riducono al minimo la necessità di operazioni di trasformazione dei dati. Questo approccio avvantaggia notevolmente le applicazioni di business intelligence e i dashboard dirigenziali.
Sfide
Anomalie dei dati: La duplicazione dei dati crea un rischio più elevato di incoerenza dei dati perché gli aggiornamenti potrebbero non propagarsi correttamente tra tutte le istanze del sistema. La convalida dei dati e i controlli di coerenza sono importanti nei sistemi denormalizzati per ridurre il rischio di anomalie.
Aumento dei costi di archiviazione: I dati ridondanti richiedono spazio di archiviazione aggiuntivo, aumentando la dimensione totale del database. I database basati sul cloud che utilizzano modelli di prezzo basati sull'utilizzo potrebbero sostenere costi più elevati a causa dei requisiti di archiviazione.
Complessità nella sincronizzazione dei dati: La sincronizzazione dei dati richiede che ogni operazione di aggiornamento modifichi simultaneamente tutte le copie dei dati, portando a limitazioni delle prestazioni. Una scarsa esecuzione della sincronizzazione dei dati produce record contenenti inesattezze o informazioni obsolete.
Potenziale di problemi di integrità dei dati: L'esecuzione impropria degli aggiornamenti su più istanze produce dati incoerenti. Questo degrada la qualità operativa e l'accuratezza dei report. I sistemi ad alta transazionalità richiedono risorse aggiuntive e rigorosi sistemi di convalida per mantenere l'integrità dei dati.
Flessibilità ridotta: Gli ambienti con più tabelle rendono le modifiche dello schema più difficili. Questo porta a cicli di sviluppo più lenti e rende più difficile per le organizzazioni adattarsi ai nuovi requisiti aziendali.
È necessaria una gestione adeguata per implementare la denormalizzazione al fine di prevenire anomalie dei dati, problemi di integrità e spese di archiviazione. Le organizzazioni dovrebbero implementare la denormalizzazione in base ai requisiti di prestazione identificati che corrispondono alle esigenze del loro sistema.
Casi d'uso
I vantaggi della denormalizzazione diventano evidenti in particolari casi d'uso, ma le organizzazioni dovrebbero comprenderne le implicazioni in situazioni diverse. Ecco alcuni dei principali casi d'uso:
Data warehousing e sistemi OLAP: I sistemi di data warehousing e OLAP utilizzano metodi di denormalizzazione per rendere più efficienti le query complesse e le aggregazioni. L'utilizzo di schemi denormalizzati comporta un recupero dei dati più rapido perché elimina la necessità di più join tra tabelle. Questo è essenziale per le applicazioni di business intelligence e i carichi di lavoro analitici.
Applicazioni a bassa latenza: La denormalizzazione avvantaggia le applicazioni a bassa latenza riducendo il tempo necessario per recuperare ed elaborare i dati in ambienti critici come le piattaforme di trading finanziario.
Applicazioni ad alta intensità di lettura: Le applicazioni che eseguono più operazioni di lettura che di scrittura possono ottenere prestazioni migliori utilizzando la denormalizzazione. Sistemi come la gestione dei contenuti e gli strumenti di reporting possono ottenere migliori prestazioni delle richieste di lettura aggiungendo dati duplicati.
Analisi in tempo reale: Le applicazioni che necessitano di insight immediati possono trarre vantaggio dalla denormalizzazione accedendo a dati pre-aggregati. Questo riduce il tempo di elaborazione delle query, consentendo un rapido processo decisionale utilizzando informazioni aggiornate.
Domande frequenti
La denormalizzazione del database è sempre migliore per le prestazioni?
La denormalizzazione nei sistemi con molte scritture crea problemi di incoerenza dei dati perché mantenere dati ridondanti presenta sfide significative. Devi valutare i modelli di lettura e scrittura della tua applicazione prima di decidere sulla denormalizzazione del database.
La denormalizzazione sostituisce la normalizzazione?
La denormalizzazione funziona come un passaggio aggiuntivo successivo alla normalizzazione per migliorare i problemi di prestazioni. Il processo di normalizzazione struttura i dati per eliminare la duplicazione e mantenere l'integrità dei dati, ma la denormalizzazione reintroduce duplicati di dati per migliorare la velocità di lettura.
Quali sono i rischi della denormalizzazione?
L'implementazione della denormalizzazione crea tre rischi principali: ridondanza dei dati, maggiori requisiti di archiviazione e incoerenze. L'aumento della ridondanza dei dati crea potenziali anomalie quando gestita in modo improprio, mentre l'espansione della dimensione dei dati richiede maggiori spese di archiviazione.
Posso denormalizzare solo una parte del mio database?
Sì, la denormalizzazione del database funziona puntando a sezioni specifiche del database per ottimizzare le prestazioni. L'implementazione mirata consente una migliore efficienza di lettura in aree specifiche senza influire sulla gestibilità o sull'integrità del database.
Come mantengo la coerenza dei dati in un database denormalizzato?
Un database denormalizzato richiede trigger di database, vincoli e logica applicativa per mantenere coerenti i dati ridondanti durante gli aggiornamenti. L'implementazione di questi meccanismi mantiene la sincronizzazione dei dati in tutte le copie dei dati.
Risorse correlate
- Che cos’è la denormalizzazione del database?
- Come funziona
- Confronto: denormalizzazione vs. normalizzazione
- Vantaggi e sfide
- Casi d'uso
- Domande frequenti
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente