




Che cos'è un Vector Lakebase?
TL;DR
- Una Vector Lakebase è un’architettura dati unificata, nativa del lake, per l’AI che combina serving di livello vector database con storage lake aperto, indici riutilizzabili a livello di lake e un livello semantico condiviso.
- Permette agli stessi dati non strutturati di alimentare il serving online (RAG, agenti, ricerca semantica) e la scoperta offline (clustering, deduplicazione, re-embedding, governance) — senza copiare dati tra sistemi.
- Zilliz Vector Lakebase è un’implementazione di questa architettura: un’evoluzione di Zilliz Cloud da database vettoriale gestito a piattaforma dati AI unificata.
Che cos’è una Vector Lakebase?
Una Vector Lakebase è un’architettura dati unificata, nativa del lake, per l’AI. Combina serving di livello vector database, storage lake aperto, indici riutilizzabili a livello di lake e un livello semantico condiviso, così gli stessi dati non strutturati possono supportare applicazioni AI online, scoperta interattiva e analytics offline — senza copiarli tra sistemi. Risponde a una domanda diversa rispetto al solo retrieval: cosa succede quando i team AI in produzione hanno bisogno degli stessi dati per retrieval, scoperta, analytics, governance, feedback e miglioramento continuo?
È meglio intenderla come un’espansione del database vettoriale, non come un suo sostituto. La ricerca vettoriale resta il percorso di serving a bassa latenza; una Vector Lakebase colloca quel percorso all’interno di una base più ampia che può anche archiviare, indicizzare, governare e migliorare continuamente i dati che lo circondano.
Perché i workload AI moderni hanno bisogno di una Vector Lakebase
I database vettoriali hanno risolto il primo problema dati dell’AI moderna: retrieval semantico rapido su larga scala, che alimenta RAG, agenti e ricerca semantica. Quel problema conta ancora — più che mai, man mano che i sistemi AI si diffondono.
Ma i team AI in produzione hanno sempre più bisogno di qualcosa di più del retrieval dagli stessi dati — deduplicazione e clustering per set di training, rilevamento di anomalie e drift, re-embedding quando i modelli cambiano, governance e lineage, e feedback dal comportamento in produzione.
La maggior parte degli stack gestisce questi workflow come sistemi separati: un data lake per i file grezzi, un database vettoriale per il retrieval online, pipeline batch per il preprocessing e job separati per embedding e indici. I dati vengono copiati tra loro, gli indici vengono ricostruiti e il serving online e la scoperta offline finiscono fuori sincronia.
Una Vector Lakebase elimina questa frammentazione fornendo una base dati logica unica per serving e scoperta. Mantiene il percorso di retrieval a bassa latenza per cui i database vettoriali sono progettati, ma lo collega a una base nativa del lake in cui dati, vettori, indici, metadati e contesto semantico possono essere archiviati, governati, versionati, riutilizzati e migliorati nel tempo. L’obiettivo non è sostituire il database vettoriale con il lake; è integrare ricerca vettoriale, contesto semantico ed elaborazione di dati non strutturati in un’unica architettura. (Per il contesto di settore e l’ingegneria alla base di questo cambiamento, consulta Why We Built Vector Lakebase.)
Principi fondamentali di progettazione di Vector Lakebase: One Data, One Index, One Semantic Layer
Un’architettura Vector Lakebase si basa su tre principi: One Data, One Index e One Semantic Layer. Descrivono dove risiede il sistema di record, come vengono gestiti gli indici e come viene organizzato il significato.

One Data: il lake come base dati condivisa
One Data significa che lo storage lake aperto diventa la base condivisa per i dati AI non strutturati. File grezzi, dati puliti, vettori, campi scalari, metadati, artefatti di indice, etichette semantiche, lineage e risultati di elaborazione offline risiedono tutti all’interno di un’unica base dati logica.
In questa architettura, il database vettoriale non è un nuovo silo di dati. Diventa parte del percorso di serving a bassa latenza. I dati autorevoli rimangono lake-native, mentre i sistemi online memorizzano nella cache dati hot e indici quando necessario. Questo riduce l’archiviazione duplicata, la governance e la migrazione tra sistemi, e consente agli stessi dati di supportare applicazioni online, elaborazione offline, addestramento dei modelli, valutazione e governance.
Ad esempio, un documento utilizzato in un sistema RAG può anche far parte di un job di clustering offline, di un workflow di esplorazione dei dati di addestramento, di una revisione di conformità e di un futuro processo di re-embedding. In un’architettura frammentata, ogni workflow crea la propria copia o rappresentazione derivata. In un Vector Lakebase, questi workflow operano sulla stessa base dati logica.
One Index: gli indici diventano asset a livello di lake
One Index significa che gli indici non sono bloccati all’interno di un singolo motore di serving online. Diventano asset di dati che possono essere costruiti, versionati, riutilizzati e serviti attraverso diverse modalità di calcolo. Questo è importante perché gli indici sono costosi e operativamente rilevanti — codificano il modo in cui un sistema recupera e organizza i dati. Se ogni workflow deve costruire il proprio indice, i team sprecano calcolo, creano comportamenti di retrieval incoerenti e rendono la governance più difficile.
In un Vector Lakebase, un indice logico può mappare diverse forme di serving in base al pattern di accesso e al costo. Gli indici hot supportano il retrieval online a livello di millisecondi; i dati warm vengono serviti tramite cache o storage a livelli; i dati cold rimangono nel lake per esplorazione, governance e analisi offline. La stessa lineage dell’indice può supportare serving RAG, ricerca semantica, memoria degli agenti, esplorazione dei dati ed elaborazione batch — consentendo ai team di scegliere il profilo di latenza e costo più adatto senza rompere il modello dati.
One Semantic Layer: il significato diventa un livello di sistema condiviso
One Semantic Layer significa che il sistema gestisce più degli embedding. Un embedding è solo una rappresentazione dell’asset sottostante. Una base dati utile per l’AI ha bisogno anche di entità, etichette, riepiloghi, argomenti, frammenti di contesto, informazioni sulla fonte, versioni dei modelli, policy di accesso, lineage e segnali di feedback. Questo livello semantico consente ai team di organizzare i dati non strutturati in base al significato, anziché solo in base a percorso del file, tabella, bucket o collection.
Un sistema RAG può recuperare contesto affidabile dal livello semantico. Un agente AI può comprendere attività precedenti, memorie e risultati delle chiamate agli strumenti. Un workflow di dati di addestramento può individuare lacune di copertura, duplicati, outlier e bias. Un sistema di governance può risalire da una risposta, feature o campione ai dati di origine e alla versione del modello che li ha prodotti.
Il livello semantico è anche il centro del flywheel dei dati: le applicazioni online generano query, clic, citazioni, correzioni e feedback; la scoperta offline trasforma questi segnali in metadati migliori, dataset più puliti, indici migliorati e contesto più solido; e questi miglioramenti ritornano nel serving. Quel loop è dove un Vector Lakebase diventa più di storage più retrieval.
Come funziona Vector Lakebase: il flywheel CS/CD, in quattro fasi
Un Vector Lakebase funziona come un loop continuo tra serving e discovery — lo chiamiamo CS/CD (Continuous Serving and Continuous Discovery). Il serving genera feedback e nuovi dati, la discovery li trasforma in dati più puliti e indici migliori, e questi miglioramenti ritornano nel serving.
Operativamente, lo stesso loop attraversa quattro fasi: ingestione dei dati, vettorizzazione e arricchimento, serving delle query ed elaborazione offline.
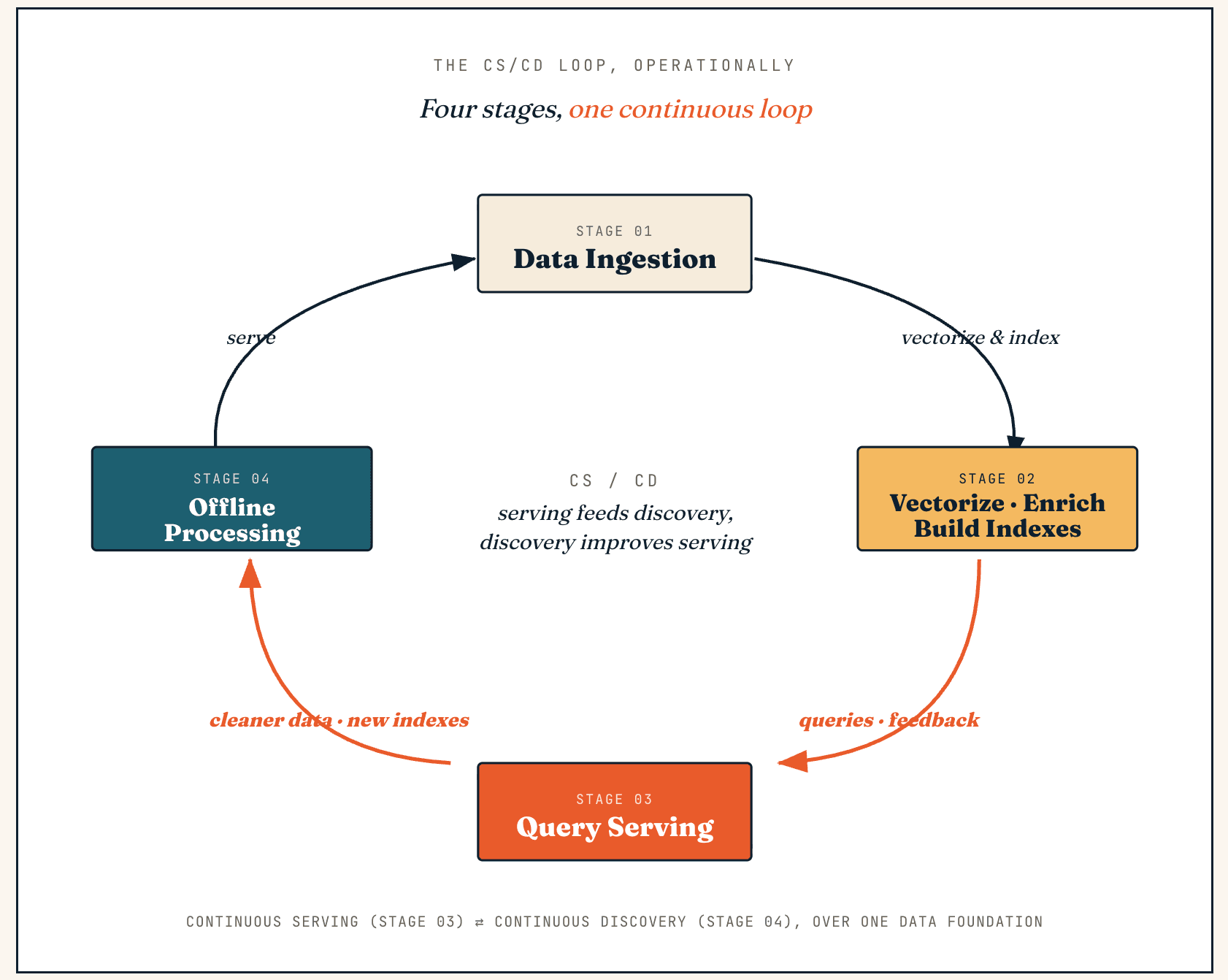
Ingestione dei dati
I dati possono entrare nel sistema tramite un’API di database vettoriale, una pipeline documentale, object storage o un formato lake aperto esistente. I dati possono includere documenti, vettori, campi scalari, metadati aziendali, immagini, audio, video, codice, log, conversazioni, ticket di supporto o tracce degli agenti.
Con la crescita dei dati non strutturati, l'ingestion deve supportare anche pulizia, normalizzazione, controllo degli accessi, tracciamento delle fonti e lineage. Il sistema deve sapere non solo che cosa sono i dati, ma da dove provengono, quale modello li ha elaborati, chi può accedervi e come possono essere utilizzati. Questo è particolarmente importante per l'AI aziendale. Un sistema RAG o un agente non può trattare ogni elemento di dati recuperato come ugualmente affidabile. Il contesto deve avere consapevolezza della fonte, delle autorizzazioni, della freschezza e, a volte, di regole di governance specifiche del business.
Vettorizzazione, arricchimento e costruzione degli indici
Dopo l'ingestion, il sistema genera rappresentazioni vettoriali usando modelli di embedding e job di elaborazione dei dati. Arricchisce inoltre i dati con metadati — entità, etichette, riassunti, argomenti, informazioni sulla fonte, autorizzazioni, timestamp e versioni dei modelli. Poi costruisce strutture di query sui dati del lake: indici vettoriali, indici di parole chiave, indici full-text, indici JSON, indici scalari e altre strutture necessarie per il recupero ibrido.
Dal punto di vista architetturale, questo è il punto chiave: gli indici non sono legati a un singolo motore di serving. Possono essere versionati, pubblicati, riutilizzati e ricondotti allo snapshot dei dati da cui sono stati costruiti — il che rende la gestione del ciclo di vita degli indici parte della data foundation, non un dettaglio implementativo nascosto dentro una singola applicazione.
Serving delle query
Una Vector Lakebase fornisce percorsi di recupero per RAG, ricerca agentica, ricerca semantica, recupero multimodale, memoria AI, raccomandazione e altri workload applicativi AI. Il percorso di query può usare un database vettoriale o un livello di cache per i dati hot che richiedono bassa latenza, e accedere a dati e indici lake-native per workload più freddi o meno frequenti.
Una query può combinare ricerca vettoriale, ricerca per parole chiave, ricerca full-text, filtraggio dei metadati, predicati scalari, autorizzazioni e ranking ibrido — perché il recupero AI in produzione raramente si basa solo sulla similarità vettoriale. Un buon risultato spesso dipende da rilevanza semantica, freschezza, diritti di accesso, qualità della fonte, metadati di business e intento dell'utente.
Elaborazione offline
L'elaborazione offline include clustering, deduplicazione, rilevamento di anomalie, analisi della qualità dei dati, esplorazione dei dati di training, evoluzione dello schema, re-embedding, valutazione e ricostruzione degli indici. Questi workflow vengono eseguiti su grandi batch di dati e non richiedono sempre latenza nell'ordine dei millisecondi, ma hanno bisogno di accedere agli stessi vettori, metadati, indici e contesto semantico usati dalle applicazioni online.
Il loro output viene riscritto nel lake, nel sistema di indici e nel layer semantico — dataset più puliti, etichette migliori, frammenti di contesto migliorati, nuove versioni degli indici o segnali di feedback aggiornati — e pubblicato come snapshot atomico, così la produzione non legge mai indici costruiti solo a metà. Questo è il loop operativo centrale: il serving genera feedback, la discovery migliora i dati e i dati migliorati tornano al serving.
Tre forme di workload per Vector Lakebase
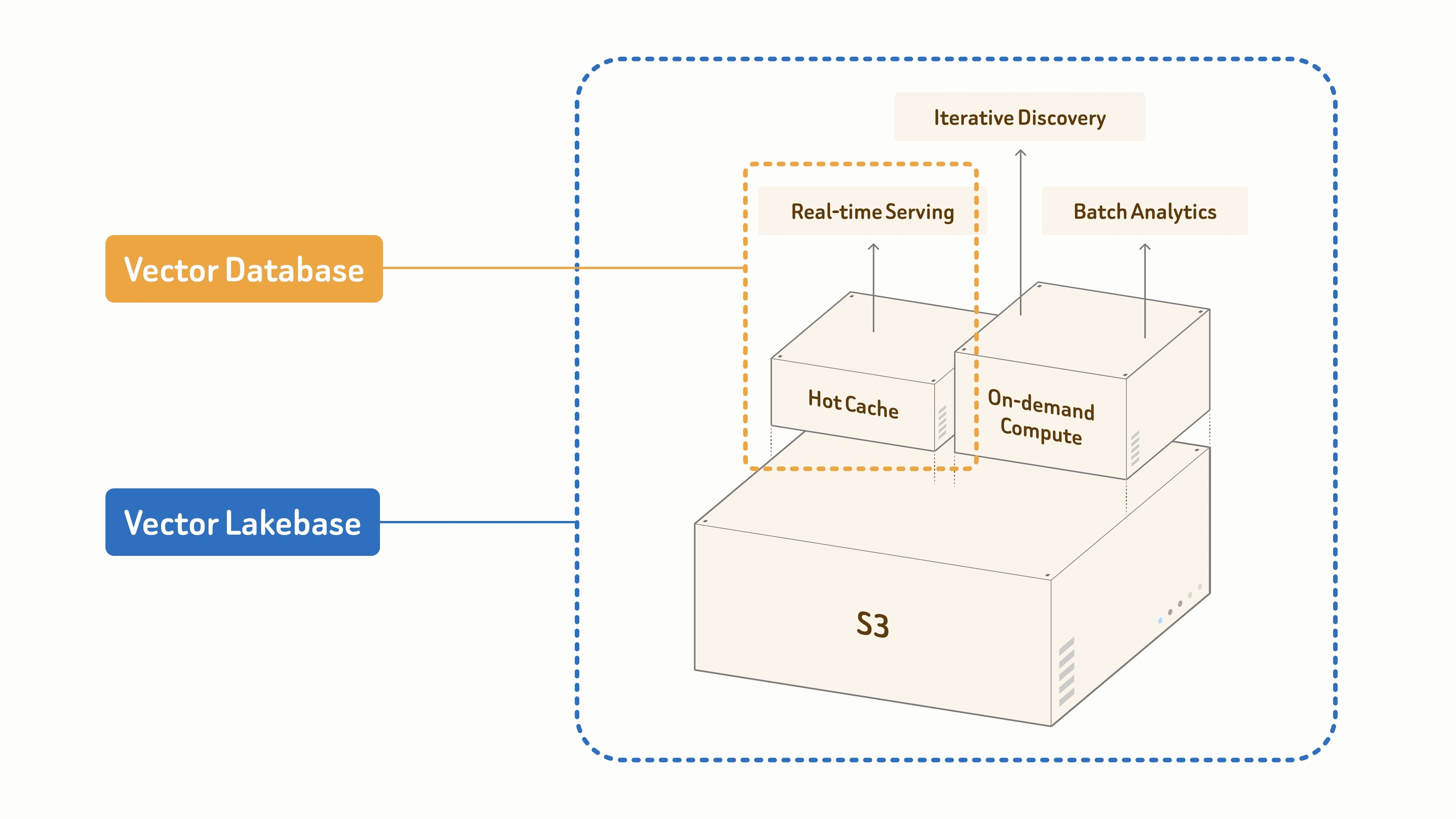
I workload di dati AI non hanno un'unica forma. Alcuni richiedono serving a livello di millisecondi tutto il giorno. Alcuni richiedono una ricerca interattiva per una breve sessione di analisi. Alcuni richiedono grandi job di elaborazione offline che vengono eseguiti, pubblicano risultati e scompaiono. Un singolo modello di storage online sempre attivo non può coprire in modo efficiente tutti questi casi.
Un database vettoriale tradizionale è ottimizzato principalmente per la prima forma di workload. Una Vector Lakebase è progettata per tutte e tre su un unico dataset logico.
In Zilliz Vector Lakebase, questi workload corrispondono a tre modalità di compute — long-running (residente, serving in millisecondi), on-demand (interattiva, fatturata al minuto, il ponte tra serving e discovery) e offline batch (grandi job che rilasciano le risorse di compute al termine).
| Tipo di workload | Esempi tipici | Modello di calcolo |
|---|---|---|
| Serving in tempo reale | RAG in produzione, memoria degli agenti, ricerca semantica, raccomandazione, personalizzazione, ricerca AI | Cluster di serving di lunga durata con indici hot, cache warm e latenza prevedibile |
| Scoperta interattiva | Analisi dei feedback, ispezione delle tracce degli agenti, ricerca di anomalie, recupero di cold data, esplorazione semantica | Calcolo on-demand che parte quando necessario e rilascia le risorse al termine della sessione |
| Analisi batch | Deduplicazione del corpus, clustering, re-embedding completo, preparazione dei dati di training, ricostruzione degli indici | Calcolo batch per job di grandi dimensioni che vengono eseguiti, pubblicano i risultati e scompaiono |
Casi d’uso comuni delle Vector Lakebase
Poiché una Vector Lakebase unifica serving e scoperta su un’unica fondazione, i suoi casi d’uso si dividono in due gruppi.
 图片12
图片12
Casi d’uso di retrieval (condivisi con un database vettoriale, ora su una fondazione governata):
- RAG — documenti, basi di conoscenza, codice e log come contesto ricercabile, mantenuto aggiornato, autorizzato e reindicizzabile quando i modelli cambiano.
- Memoria degli agenti AI e uso degli strumenti — archiviare e recuperare la memoria degli agenti, quindi analizzarla offline e reimmettere i risultati.
- Ricerca agentica e multimodale — ricerca vettoriale, per parole chiave, full-text e sui metadati attraverso testo, immagini, audio, video ed entità.
- Sistemi di raccomandazione e altro ancora.
Casi d’uso del ciclo di vita dei dati (oltre ciò che copre da solo un database vettoriale):
- Ingegneria delle feature e del contesto — derivare entità, riassunti, argomenti, etichette e cluster, archiviati accanto ai dati da cui provengono.
- Esplorazione dei dati di training — raggruppare campioni in cluster, trovare quasi-duplicati, ispezionare outlier e tracciare gli esempi fino alla fonte.
- Preprocessing dei dati non strutturati — deduplicazione, rilevamento di anomalie, arricchimento e filtraggio della qualità, riscritti nel lake.
Come una Vector Lakebase si rapporta ai database vettoriali e alle Lakebase
Una Vector Lakebase è correlata a due architetture: database vettoriali e Lakebase. Non sostituisce nessuna delle due. La tabella seguente offre una panoramica rapida; le sezioni successive spiegano ciascuna relazione.
| Database vettoriale | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Dati primari | Embedding vettoriali + dati non strutturati associati | Dati non strutturati e multimodali, più l’intero ciclo di vita attorno a essi | Dati applicativi strutturati / transazionali |
| Compito principale | Retrieval semantico a bassa latenza | Unificare serving online e scoperta offline su un’unica fondazione | Portare le funzionalità di database (OLTP) nello storage lake aperto |
| Indici | Costruiti e mantenuti all’interno del motore di serving | Asset a livello di lake: costruiti, versionati, riutilizzati tra modalità di calcolo | Indici di tabella / SQL |
| Calcolo | Serving always-on | Di lunga durata + on-demand + batch offline | Transazionale |
| Storage di riferimento | Spesso accoppiato al motore | Storage lake aperto | Storage lake aperto |
| Miglior aderenza | Ricerca vettoriale rapida per applicazione online | Serving e miglioramento continuo dei dati non strutturati su larga scala | Dati applicativi transazionali sul lake |
| Relazione con la vector lakebase | Diventa il motore di serving all’interno di una Vector Lakebase | - | La controparte per dati strutturati della stessa idea lake-native |
Vector Lakebase vs. database vettoriali
Una Vector Lakebase non sostituisce i database vettoriali. Se un’organizzazione ha bisogno solo di ricerca vettoriale a bassa latenza per una singola applicazione, un database vettoriale può essere sufficiente — rimane il sistema giusto per il retrieval in produzione quando latenza, scala, filtraggio e affidabilità operativa sono importanti. Milvus, ad esempio, è progettato per questo tipo di ricerca vettoriale in produzione.
Il calcolo cambia quando un’organizzazione deve riutilizzare gli stessi dati non strutturati, embedding, indici e contesto semantico tra molti team, modelli, applicazioni e workflow di elaborazione.
In quel mondo, il database vettoriale non dovrebbe essere l’unico luogo in cui dati e indici risiedono; diventa il motore di serving all’interno di un’architettura più ampia per dati non strutturati. Il suo ruolo diventa più specifico e più importante — fornisce il percorso di serving di cui le applicazioni AI hanno bisogno, mentre il Vector Lakebase fornisce la base dati più ampia attorno a quel percorso. Il risultato non è meno ricerca vettoriale; è ricerca vettoriale collegata all’intero ciclo di vita dei dati non strutturati.
Se ho bisogno solo di un database vettoriale, Vector Lakebase è comunque una buona scelta?
È un punto di partenza perfettamente valido — perché il database vettoriale fa già parte di un Vector Lakebase. Puoi usare il livello del cluster di serving esattamente come un database vettoriale standalone (ricerca ANN a bassa latenza, ricerca ibrida, filtraggio dei metadati, recupero full-text, filtraggio JSON, gestione degli indici, affidabilità in produzione) e non toccare mai la scoperta interattiva o l’analisi batch il primo giorno. La differenza è che non sei vincolato a un’architettura solo per il retrieval: se in seguito il carico di lavoro si espande verso la ricerca su dati freddi, la deduplicazione su larga scala, il re-embedding, la preparazione dei dati di training o la governance semantica, l’architettura più ampia è già in atto — nessuna ricostruzione, nessuna duplicazione dei dati.
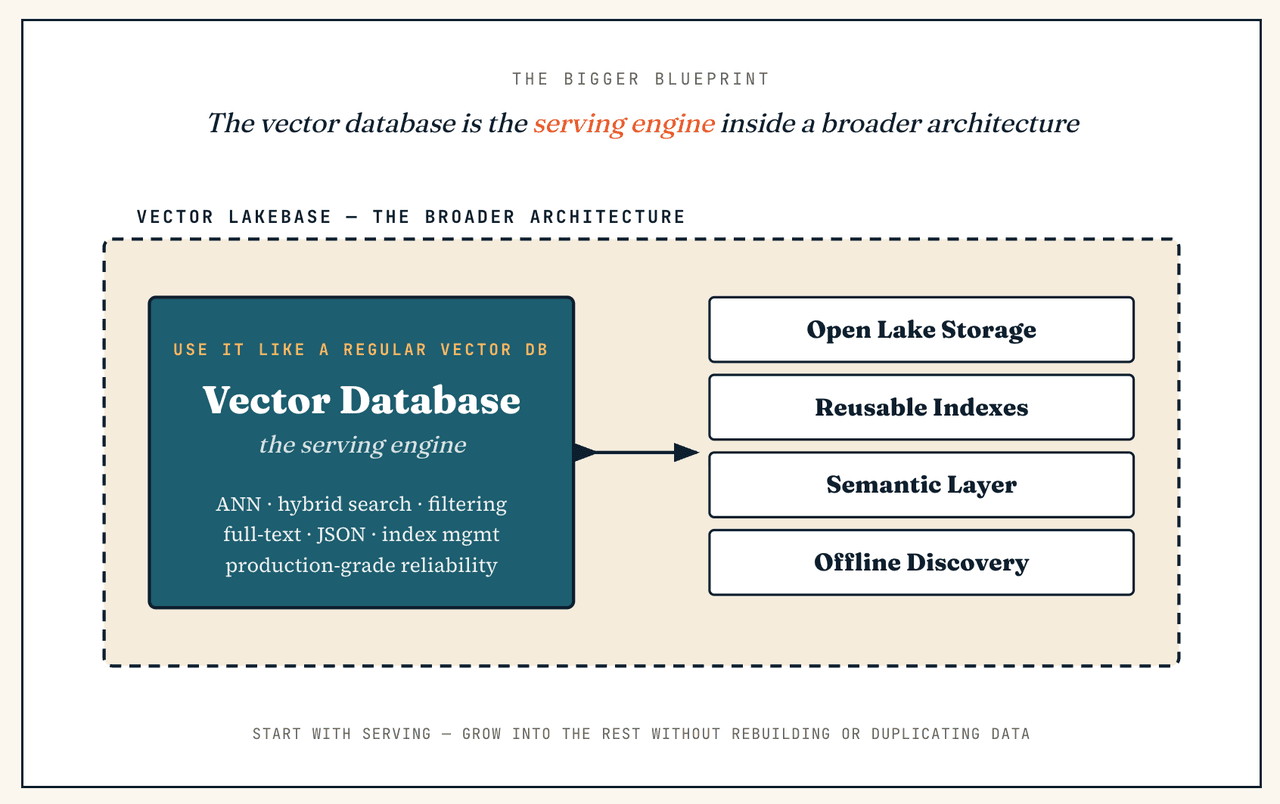
Vector Lakebase vs. Lakebase
Un Vector Lakebase è correlato a un Lakebase, ma non è semplicemente "Lakebase più vettori."

Un’architettura in stile Lakebase porta capacità simili a quelle di un database nello storage lake aperto per dati applicativi strutturati — record strutturati, transazioni, schemi, compute elastico e governance unificata, interrogati tramite campi e relazioni note.
Un Vector Lakebase affronta un diverso centro di gravità: dati non strutturati e multimodali per l’AI. Il problema non è come archiviare lo stato applicativo su un lake; è come gestire rappresentazioni semantiche, indici vettoriali, metadati, contesto, feedback e workflow di scoperta offline su dati non strutturati — che richiedono interpretazione semantica, retrieval, raffinamento e feedback anziché lookup su campi noti. È meglio descritto non come un sostituto del Lakebase, ma come l’idea di Lakebase estesa all’era dei vettori, degli indici e del contesto semantico.
| Dimensione | Lakebase | Vector Lakebase |
|---|---|---|
| Dati primari | Dati applicativi strutturati, record transazionali, stato applicativo | Documenti, immagini, audio, video, log, codice, conversazioni, vettori, metadati e contesto semantico |
| Astrazioni principali | Tabelle, transazioni, schemi, branch, cloni | Vettori, indici, chunk, entità, etichette, riepiloghi, permessi, feedback e relazioni semantiche |
| Carichi di lavoro principali | Letture e scritture applicative, transazioni, analisi in tempo reale | RAG, memoria degli agenti, ricerca agentica, retrieval multimodale, scoperta, context engineering, workflow per dati di training |
| Modello di query | SQL, query transazionali, query analitiche | Ricerca vettoriale, ricerca ibrida, ricerca full-text, filtraggio JSON, retrieval multimodale, scoperta semantica |
| Modello semantico | Significato di business espresso principalmente tramite schema | Significato espresso tramite embedding, metadati, entità, riepiloghi, versioni dei modelli, lineage e feedback |
| Valore per l’AI | Porta capacità simili a quelle di un database nello storage lake aperto | Porta contesto AI, indicizzazione vettoriale, retrieval semantico e scoperta offline ai dati non strutturati lake-native |
Cosa non è un Vector Lakebase
Poiché Vector Lakebase è un nuovo pattern architetturale, vale la pena chiarire cosa non è.
- Non è solo un data lake con embedding memorizzati in una colonna. Memorizzare gli embedding in una tabella lake preserva i vettori, ma non offre nessuna delle funzionalità di indicizzazione, serving, metadati semantici, retrieval ibrido, ciclo di feedback o percorso di retrieval a bassa latenza di cui i sistemi di AI in produzione hanno bisogno. I vettori sono utili quando possono essere cercati, governati, versionati, filtrati, collegati ai dati sorgente e migliorati nel tempo — non semplicemente memorizzati.
- Non è solo un database vettoriale collegato a object storage. Mettere object storage dietro un database vettoriale può ridurre i costi di archiviazione, ma non affronta il riutilizzo degli indici, la scoperta offline, la governance, il versioning o la coerenza tra dati elaborati e dati serviti. La parte difficile non è dove risiedono i byte; è come dati, indici, metadati, segnali semantici e modalità di calcolo lavorano insieme come un unico sistema operativo.
- Non è un sistema di analytics offline. La scoperta offline è solo un lato dell’architettura. Un Vector Lakebase serve anche traffico di produzione, supporta percorsi di retrieval hot, gestisce indici, applica il controllo degli accessi e restituisce contesto rilevante ad applicazioni e agenti. Il punto non è scegliere tra serving e analytics — è collegarli.
- Non è un allontanamento dai database vettoriali. Questo potrebbe essere il punto più importante che abbiamo menzionato ripetutamente. Vector Lakebase non rende i database vettoriali meno rilevanti. Offre loro un’architettura più ampia in cui operare.
Zilliz Vector Lakebase è disponibile in public preview
Abbiamo lanciato la public preview di Zilliz Vector Lakebase — un’importante evoluzione di Zilliz Cloud da database vettoriale gestito puro a piattaforma unificata di dati semantici che combina il serving vettoriale a bassa latenza con l’apertura, la scalabilità e l’economia di un data lake.
Funzionalità principali di Zilliz Vector Lakebase:
- Serving a livelli ottimizzato per diversi compromessi prestazioni-costo in tempo reale
- Ricerca on-demand per workload su larga scala o esplorativi senza compute sempre attivo
- Ricerca su data lake esterni — indicizza e cerca direttamente sui tuoi dati lake esistenti
- Ricerca AI a spettro completo su vettori, testo, JSON e dati geospaziali con retrieval ibrido e reranking
- Storage unificato lake-native basato su Vortex, un formato aperto con letture casuali più rapide ed economiche rispetto a Lance o Parquet
Se il tuo stack attuale separa serving e discovery in sistemi distinti, Vector Lakebase potrebbe meritare attenzione. Provalo su Zilliz Cloud — le nuove registrazioni con email di lavoro ricevono $100 di crediti gratuiti — oppure contattaci per parlarci del tuo caso d’uso.
Scopri di più sui Vector Lakebase
- Da Vector Database a Vector Lakebase
- Abbiamo passato 8 anni a rendere la ricerca vettoriale più veloce. Poi l’AI ha cambiato il modello di calcolo
- Perché abbiamo creato Vector Lakebase: ripensare l’architettura dei dati non strutturati per l’AI
- Vector Lakebase: porre fine al silo dei dati AI
- Zilliz Cloud On-Demand Compute: paga solo per ciò che usi
- La ricerca vettoriale di Notion è eccellente. Il loro prossimo problema è più difficile.
Continua a leggere

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.