




Smetti di costruire infrastrutture dati per l'IA per la fase sbagliata
La maggior parte delle decisioni sull'infrastruttura AI viene presa nella prima settimana e rimpianta quando ci si guarda indietro al secondo anno.
Il problema non è quasi mai il modello, e raramente la logica applicativa. Si torna sempre alla stessa cosa: l'infrastruttura dati dovrebbe essere costruita per la fase in cui si trova il team.
In ogni fase, la modalità di fallimento agisce in entrambe le direzioni. Se sovra-ingegnerizzi troppo presto, ti rallenti. Se sottovaluti, ricostruisci sotto pressione. Entrambe creano lo stesso risultato: un sovraccarico di iterazione che si accumula.
Fase 1: Il prototipo — Fallo semplicemente funzionare
All'inizio, la velocità conta molto più dell'infra dati — o meglio, non c'è proprio bisogno di una cosiddetta "infra dati".
L'obiettivo non è la scalabilità. L'obiettivo non è la governance. L'obiettivo non è l'ottimizzazione.
L'obiettivo è semplicemente far funzionare l'applicazione.
L'errore più comune in questa fase è confondere la sofisticazione con la qualità. I team aggiungono pipeline di ingestione in streaming prima di avere documenti da ingerire. Configurano una replica di livello production-grade prima di avere un singolo utente reale. Si preoccupano della coerenza dei dati tra più sistemi prima di avere abbastanza dati perché la coerenza abbia importanza.
Il risultato: settimane di lavoro sull'infrastruttura che avrebbero potuto essere consegnate come una semplice modifica dell'idea.
Quanto al tema caldo "vector database", conta a malapena. Milvus, Elasticsearch, pgvector, o persino una libreria di ricerca leggera — qualunque di queste farà il suo lavoro. Il divario nella qualità del retrieval tra le opzioni è trascurabile rispetto al divario tra avere un prototipo funzionante e non averne uno.

Ciò di cui hai davvero bisogno in questa fase:
- Il tuo file system locale
- Qualsiasi database leggero o libreria di ricerca
Fase 2: Product-Market Fit — Più database, problemi peggiori
Una volta che utenti reali iniziano a interagire con il sistema, l'attenzione si sposta dalla costruzione di una demo al miglioramento continuo del prodotto, ma compare una trappola diversa.
L'equivoco suona ragionevole: tipi di database più specializzati portano a una migliore qualità del retrieval.
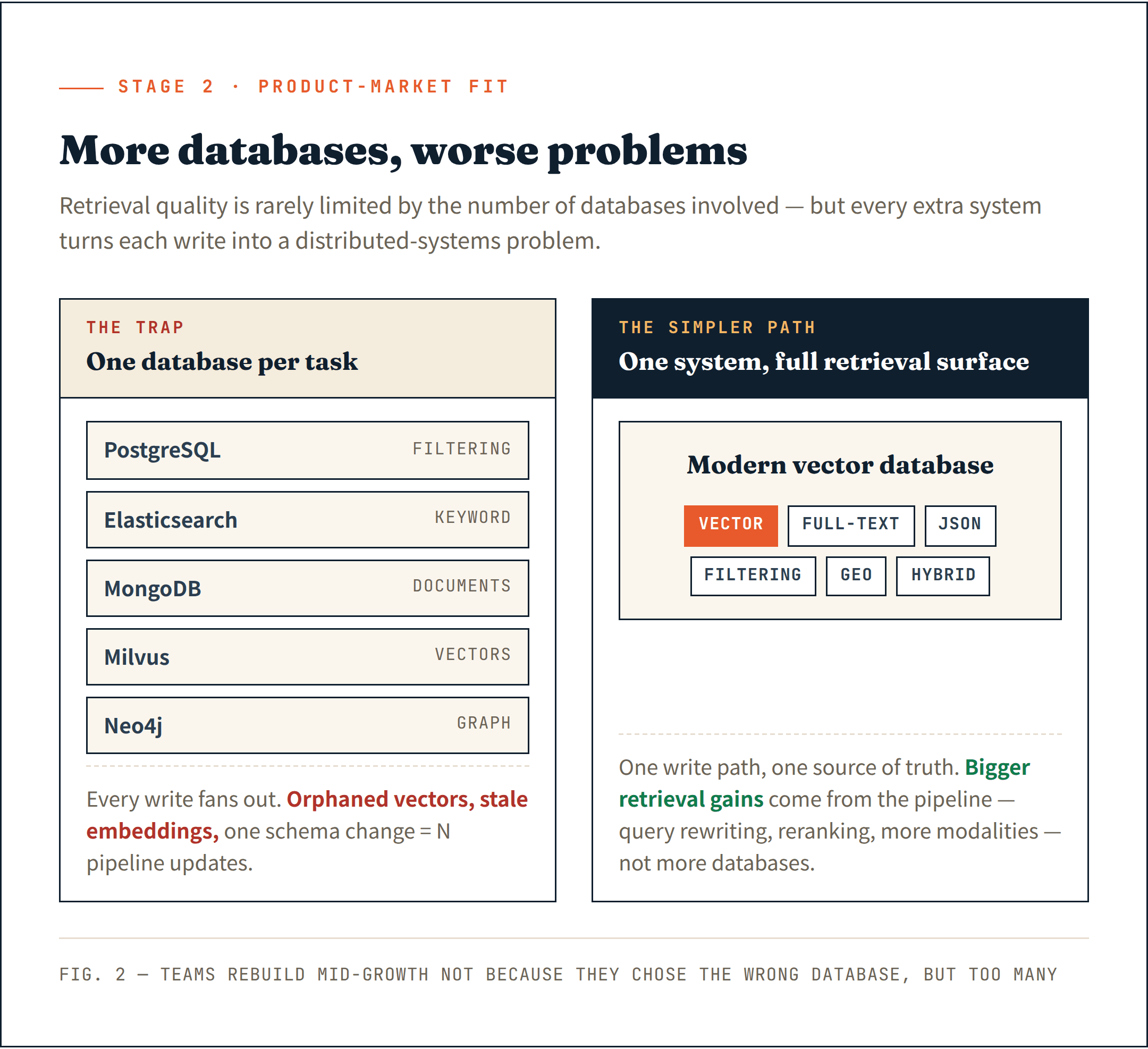
Alcuni team iniziano ad assemblare un sistema per ogni attività di retrieval — PostgreSQL per il filtraggio, Elasticsearch per la ricerca per parole chiave, MongoDB per i documenti, Milvus per i vettori e Neo4j per le relazioni nei grafi. Lo stack di retrieval cresce più velocemente del prodotto stesso.
Poi arriva il problema della sincronizzazione.
I documenti vivono in un sistema. Gli embedding in un altro. I metadati in un terzo. Ogni operazione di scrittura diventa un problema di sistemi distribuiti. Un'eliminazione fallita lascia vettori orfani. Un inserimento parziale crea embedding obsoleti. Una modifica dello schema richiede l'aggiornamento di più pipeline contemporaneamente.
La dura lezione: la qualità del retrieval è raramente limitata dal numero di database coinvolti.
I guadagni maggiori derivano dalla pipeline di retrieval stessa — riscrittura dinamica delle query, ricerca iterativa, divulgazione progressiva, migliore reranking. Sul lato dati, aggiungere un altro campo di embedding o un'altra modalità migliora spesso la qualità del retrieval più che aggiungere un altro database specializzato.
I moderni vector database si sono silenziosamente espansi ben oltre i vettori. Ricerca full-text, filtraggio JSON, ricerca geospaziale e retrieval ibrido — la maggior parte dei sistemi maturi ora supporta queste funzionalità nativamente. L'ipotesi di un database specializzato per ogni attività è sempre più superata.
Un singolo sistema che gestisce l'intera superficie di retrieval è più semplice da operare e fornisce una base più pulita per ciò che viene dopo.
Ho visto troppi team costretti a ricostruire la propria infra dati nel pieno della crescita — non perché avessero scelto il database sbagliato, ma perché ne avevano scelti troppi.
Ciò di cui hai davvero bisogno in questa fase:
- Un servizio di database gestito — lascia che sia il fornitore a occuparsi dell’affidabilità mentre tu ti concentri sul prodotto
- Un unico sistema con ampio supporto semantico: vettori, full-text, JSON, filtri, ibrido — non un database per ogni attività
- Sufficiente margine per crescere fino al successivo ordine di grandezza senza ricostruire
Fase 3: Crescita su larga scala — Non ogni workload dovrebbe condividere lo stesso compute
Questa è la fase in cui la pressione sui costi diventa innegabile. Il motivo è semplice: i dati crescono sempre più velocemente dei tuoi ricavi.
L’errore più comune: presumere che la soluzione di database tradizionale che ti ha portato fin qui ti porterà anche oltre.
A differenza della Fase 2, a questo punto non c’è spazio facile per ricostruire. Una migrazione infrastrutturale su larga scala sotto pressione di crescita è estremamente costosa, estremamente rischiosa, o entrambe le cose.
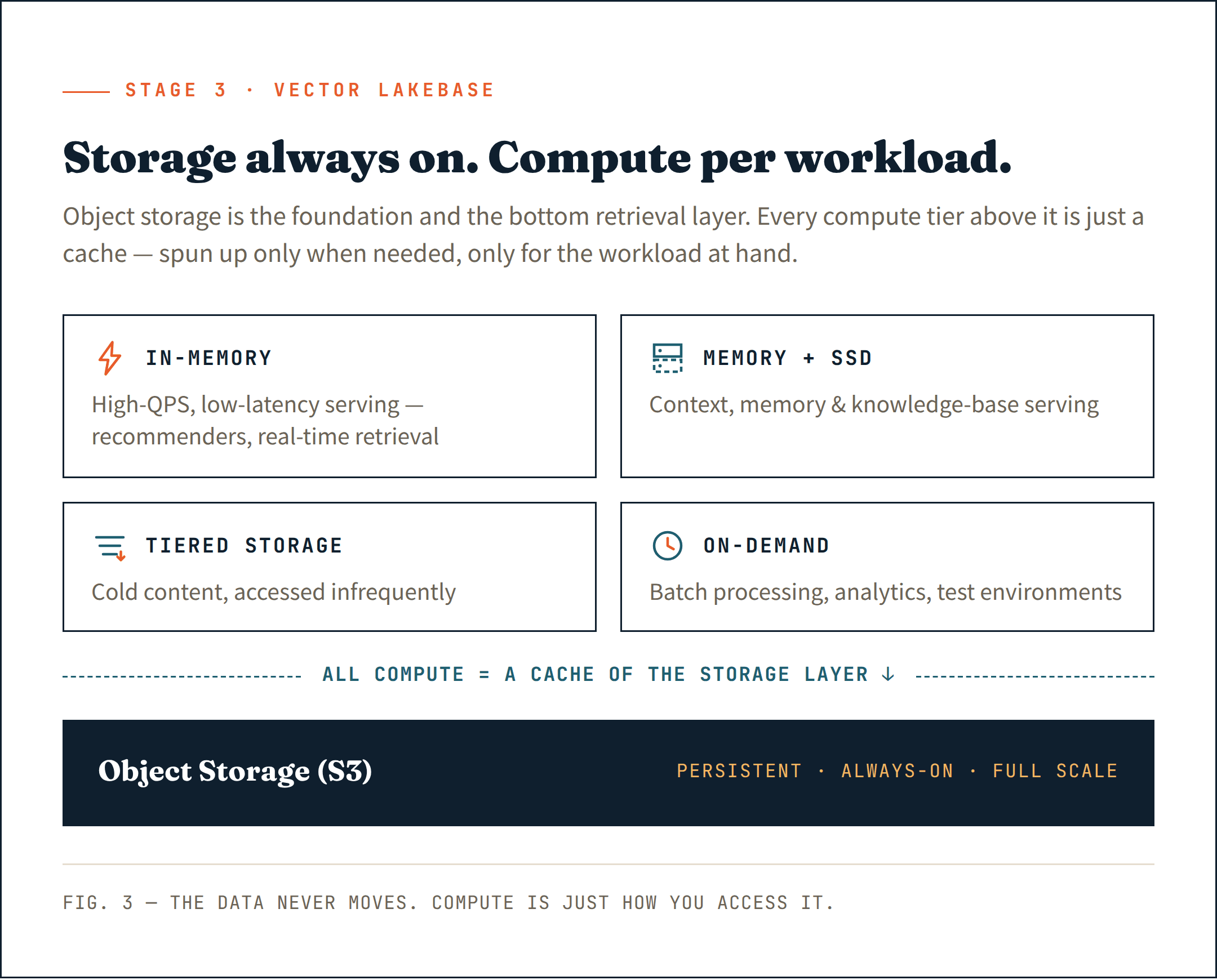
La mossa giusta è mettere tutto su object storage (come S3) — non solo come archivio persistente, ma come livello di base della tua architettura di retrieval. È l’opzione più economica, più durevole e più scalabile che esista. Trattala come la fondazione, non come un ripensamento.
Sopra quel livello, introduci compute solo dove è effettivamente necessario. Cluster long-running per il serving sensibile alla latenza. Risorse di compute effimere per ingestion e indicizzazione. Compute on-demand per analytics e job batch. Ogni workload ottiene il compute di cui ha bisogno — e niente di più.
Questa è l’essenza di una Vector Lakebase: storage sempre attivo alla massima scala, compute che non lo è — avviato solo quando necessario, solo per il workload in questione.
Ancora più importante, tutto il compute — sia long-running sia on-demand — agisce come cache del livello di object storage. I dati vivono sempre nello storage. Il compute è solo il modo in cui vi accedi.
Abbina ogni workload al giusto tier di compute:
- In-memory per workload ad alto QPS e bassa latenza — sistemi di raccomandazione AI, retrieval in tempo reale
- Memory + SSD per il serving di contesto, memoria e knowledge base
- Tiered storage per contenuti cold a cui si accede di rado
- On-demand compute per elaborazione batch, analytics interne e ambienti di test
Fatto nel modo giusto, questo approccio riduce i costi infrastrutturali del 50% o più rispetto a un design unificato — offrendo al contempo una qualità del servizio molto migliore per ogni workload.
Le soluzioni serverless spesso cedono in questa fase — non tecnicamente, ma economicamente. Una volta che i tuoi dati superano i terabyte, i costi di inserimento e storage iniziano a dominare. Il motivo è strutturale: le architetture serverless incorporano overhead di pooling, indicizzazione e costi dei dati persistenti nei ricarichi su scrittura e storage. Non stai più pagando per ciò che usi. Stai pagando per l’astrazione.
Il primo principio per l’infrastruttura dati in questa fase è semplice: la tua fondazione deve scalare con i tuoi dati, non contro di essi. Un’unica architettura costretta a servire ogni workload ugualmente bene finisce per non servirne bene nessuno — e il costo di quel compromesso si moltiplica con ogni gigabyte che aggiungi.
Ciò di cui hai effettivamente bisogno in questa fase:
- Object storage (S3) sia come fondazione sia come livello inferiore di retrieval — persistente, sempre attivo alla massima scala, il livello da cui tutto il compute legge
- Una Vector Lakebase: dati che non si spostano mai, compute che si avvia per workload e niente di più
- Il giusto tier di compute per ogni tipo di workload
Fase 4: Scala enterprise — La fiducia diventa parte del prodotto
A questa fase, la maggior parte dei team crede che la parte difficile sia alle spalle. Non è così.
L’errore comune: i team pensano ancora che il problema sia tecnico.
Hanno ottimizzato l’infrastruttura. Hanno controllato i costi. Presumono che scalare verso l’enterprise sia una questione di aggiungere capacità e spuntare una casella di sicurezza.
Non è così.
Le domande che bloccano gli accordi enterprise non hanno nulla a che fare con le prestazioni:
In che modo i nostri dati sono isolati da quelli degli altri clienti?
Chi ha accesso a cosa, e potete dimostrarlo?
Potete servirci nella nostra regione?
Possiamo distribuire questo all’interno del nostro account cloud?
Ma i requisiti dei singoli accordi sono solo una parte del problema. Nella Fase 3, la disomogeneità era tecnica — workload diversi, livelli di calcolo diversi. In questa fase, è strutturale: la vostra base clienti richiede un’infrastruttura dati a livello di piattaforma per gestirla.
Avete utenti gratuiti che necessitano di un serving condiviso ed efficiente in termini di costi. Avete clienti individuali paganti che si aspettano una migliore disponibilità. Avete clienti enterprise che richiedono isolamento completo dei dati, calcolo dedicato e la possibilità di verificare tutto. Servire tutti e tre con la stessa architettura significa che state spendendo troppo per il vostro livello gratuito, servendo in modo insufficiente i vostri clienti enterprise, o entrambe le cose.
La risposta giusta è un’infrastruttura a livelli, allineata a ciascun segmento di clientela:
- Cluster condivisi per utenti gratuiti e individuali — condivisi, ottimizzati per i costi
- Cluster isolati per ogni cliente enterprise — calcolo dedicato, storage dedicato, controlli di accesso dedicati
- BYOC per i clienti che richiedono la distribuzione all’interno del proprio account cloud

Il punto BYOC è dove la maggior parte dei team commette un errore critico. SaaS e BYOC sembrano due prodotti. Se si separano a livello di architettura, vi ritrovate a mantenere due codebase, due pipeline di distribuzione e due runbook operativi — a tempo indeterminato. I team che hanno fatto bene questa scelta hanno trattato BYOC come un modello di distribuzione anziché come un prodotto separato. Stesso data plane, stessa interfaccia di controllo, target di distribuzione diverso.
L’affidabilità globale è l’altro elemento che viene rimandato troppo a lungo. Su scala enterprise, il multi-region non è una funzionalità premium — è un’aspettativa di base. I clienti enterprise in diverse aree geografiche non tollereranno una distribuzione in una singola regione, né accetteranno i vostri impegni SLA. Senza un’interfaccia unificata per l’infrastruttura dati attraverso cloud e regioni, finite per gestire livelli dati diversi in ambienti diversi — la sincronizzazione dei dati in tempo reale diventa un problema di sistemi distribuiti a sé stante, e la complessità operativa aumenta con ogni nuova regione che aggiungete.
I team con cui ho parlato che avevano raggiunto accordi enterprise importanti descrivevano la stessa dolorosa scoperta: nulla di tutto questo era stato progettato fin dall’inizio. Era stato aggiunto in seguito, sotto la pressione di un ciclo di vendita attivo. Un team ha impiegato quattro mesi per adattare l’isolamento a livello di dati a un’architettura che non era stata costruita per quello. L’hanno rilasciato. Ma sapevano esattamente perché era fragile.
La preparazione per l’enterprise non è una checklist. È una conseguenza di decisioni architetturali prese molto prima.
Ciò di cui avete effettivamente bisogno in questa fase:
- Un’interfaccia unificata per l’infrastruttura dati — coerente tra cloud, coerente tra regioni
- Cluster globali progettati per alta affidabilità e serving multi-region
- Serving a livelli: cluster condivisi per utenti gratuiti, cluster isolati per ogni cliente enterprise
- SaaS e BYOC sulla stessa architettura — un unico data plane, target di distribuzione diversi
- Standard aperti e open source alla base — nessun vendor lock-in su scala enterprise
Cosa hanno in comune i team che sono scalati bene
Il pattern è costante.
Ogni fase introduce una classe di problemi completamente diversa. La Fase 1 è un problema di velocità. La Fase 2 è un problema di complessità. La Fase 3 è un problema di costi e architettura. La Fase 4 è un problema di fiducia e piattaforma.

I team che hanno attraversato ogni fase senza una ricostruzione dolorosa l’hanno capito presto. Hanno smesso di chiedersi "di quale database ho bisogno adesso?" e hanno iniziato a chiedersi "cosa richiederà la prossima fase — e la mia decisione attuale chiude quella porta?"
Nella Fase 1, un database vettoriale è esattamente lo strumento giusto. Lo dico senza riserve.
Dalla Fase 3 in poi, ciò che diventa necessario è qualcosa di natura diversa: una Vector Lakebase. Storage sempre attivo a piena scala. Compute adeguato a ciascun workload. Una piattaforma in grado di servire un utente gratuito, un cliente pagante e un account enterprise dalla stessa architettura, senza fork.
I team che ci sono arrivati più velocemente non erano più intelligenti né meglio finanziati.
Hanno semplicemente capito prima che la decisione sull’infrastruttura non era una scelta temporanea.
Era la base su cui sarebbe stato costruito tutto il resto.
Zilliz Vector Lakebase è disponibile in public preview
Abbiamo lanciato la public preview di Zilliz Vector Lakebase — un’importante evoluzione di Zilliz Cloud, da database vettoriale gestito a piattaforma unificata di dati semantici che combina il database vettoriale di produzione con una base dati condivisa, lake-native.
Funzionalità principali di Zilliz Vector Lakebase:
- Serving a livelli ottimizzato per diversi compromessi performance-costo in tempo reale
- Ricerca on-demand per workload su larga scala o esplorativi senza compute always-on
- Ricerca su data lake esterni — indicizza e cerca direttamente sui dati del tuo lake esistente
- Ricerca full-spectrum su vettori, testo, JSON e dati geospaziali con retrieval ibrido e reranking
- Storage unificato lake-native basato su Vortex, un formato aperto con letture casuali più rapide ed economiche rispetto a Lance o Parquet
Se il tuo stack attuale separa serving e discovery in sistemi distinti, Vector Lakebase potrebbe meritare un’occhiata. Provala su Zilliz Cloud — le nuove registrazioni con email aziendale ricevono $100 di crediti gratuiti — oppure parla con noi del tuo caso d’uso.
Scopri di più sulle Vector Lakebase
- Da Vector Database a Vector Lakebase
- Abbiamo passato 8 anni a rendere i database vettoriali più veloci. Poi ci siamo fermati.
- Perché abbiamo creato Vector Lakebase: ripensare l’architettura dei dati non strutturati per l’AI
- Vector Lakebase: porre fine al silo di dati dell’AI
- Zilliz Cloud On-Demand Compute: paga solo per ciò che usi
- La Vector Search di Notion è eccellente. Il loro prossimo problema è più difficile.

Continua a leggere

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.