




Costruire RAG con Milvus, vLLM e Llama 3.1
L'Università della California - Berkeley ha donato vLLM, una libreria veloce e facile da usare per l'inferenza e il servizio di LLM, alla LF AI & Data Foundation come progetto in fase di incubazione nel luglio 2024. In qualità di progetto membro, diamo il benvenuto a vLLM nella famiglia LF AI & Data! 🎉
I modelli linguistici di grandi dimensioni (LLM e i database vettoriali sono solitamente abbinati per costruire la Retrieval Augmented Generation (RAG), una popolare architettura applicativa di IA per affrontare le allucinazioni dell'IA. Questo blog mostra come costruire ed eseguire una RAG con Milvus, vLLM e Llama 3.1. In particolare, vi mostrerò come incorporare e memorizzare le informazioni testuali come vector embeddings in Milvus e come utilizzare questo archivio vettoriale come base di conoscenza per recuperare in modo efficiente i pezzi di testo rilevanti per le domande degli utenti. Infine, sfrutteremo vLLM per utilizzare il modello Llama 3.1-8B di Meta per generare risposte aumentate dal testo recuperato. Tuffiamoci!
Introduzione a Milvus, vLLM e Meta Llama 3.1
Database vettoriale Milvus
Milvus è un database vettoriale open-source, appositamente costruito, distribuito per l'archiviazione, l'indicizzazione e la ricerca di vettori per carichi di lavoro di IA generativa (GenAI). La sua capacità di eseguire ricerca ibrida, filtraggio dei metadati, reranking e gestione efficiente di trilioni di vettori rende Milvus una scelta obbligata per i carichi di lavoro di IA e apprendimento automatico. Milvus può essere eseguito in locale, su un cluster o ospitato nel Zilliz Cloud completamente gestito.
vLLM
vLLM è un progetto open-source avviato presso lo SkyLab della UC Berkeley e incentrato sull'ottimizzazione delle prestazioni dei servizi LLM. Utilizza una gestione efficiente della memoria con PagedAttention, batching continuo e kernel CUDA ottimizzati. Rispetto ai metodi tradizionali, vLLM migliora le prestazioni di servizio fino a 24 volte e dimezza l'utilizzo della memoria della GPU.
Secondo il documento "Efficient Memory Management for Large Language Model Serving with PagedAttention", la cache KV utilizza circa il 30% della memoria della GPU, causando potenziali problemi di memoria. La cache KV è memorizzata in una memoria contigua, ma la modifica delle dimensioni può causare la frammentazione della memoria, che è inefficiente per il calcolo.

Immagine 1. Gestione della memoria cache KV nei sistemi esistenti (2023 Paged Attention_ paper)
Utilizzando la memoria virtuale per la cache KV, vLLM alloca la memoria fisica della GPU solo se necessaria, eliminando la frammentazione della memoria ed evitando la preallocazione. Nei test, vLLM ha superato HuggingFace Transformers (HF) e Text Generation Inference (TGI), ottenendo un throughput fino a 24 volte superiore a HF e 3,5 volte superiore a TGI sulle GPU NVIDIA A10G e A100.
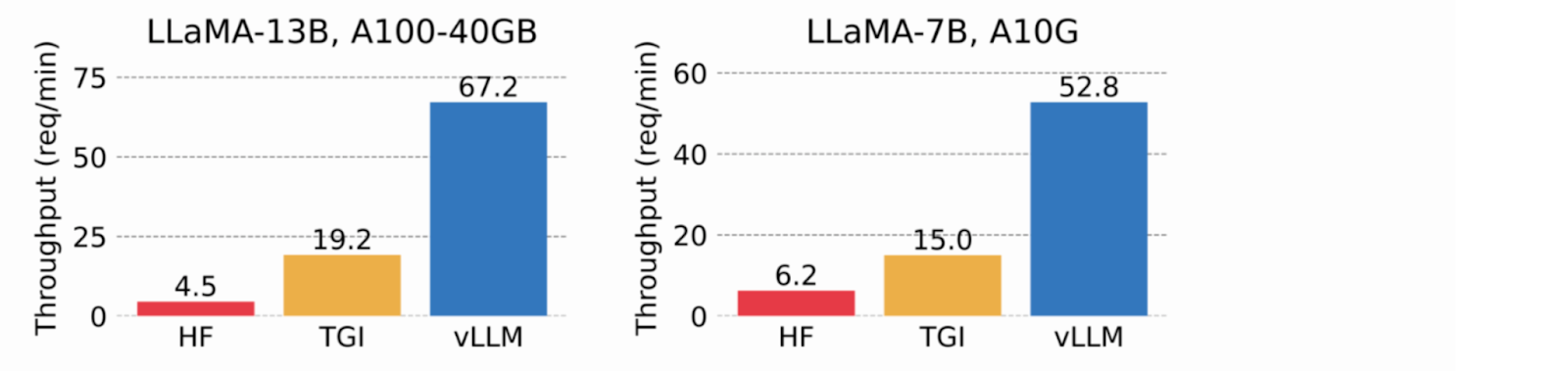
Immagine 2. Il throughput del servizio quando ogni richiesta richiede il completamento di tre output paralleli. vLLM raggiunge un throughput 8,5x-15x superiore a HF e 3,3x-3,5x superiore a TGI (2023_ vLLM blog_).
Meta's Llama 3.1
Meta's Llama 3.1 è stato annunciato il 23 luglio 2024. Il modello 405B offre prestazioni all'avanguardia su diversi benchmark pubblici e ha una finestra di contesto di 128.000 token in ingresso, con vari usi commerciali consentiti. Oltre al modello da 405 miliardi di parametri, Meta ha rilasciato una versione aggiornata di Llama3 70B (70 miliardi di parametri) e 8B (8 miliardi di parametri). I pesi del modello sono disponibili per il download [sul sito web di Meta] (https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
Un'intuizione chiave è stata che la messa a punto dei dati generati può aumentare le prestazioni, ma gli esempi di scarsa qualità possono ridurle. Il team di Llama ha lavorato a lungo per identificare e rimuovere questi cattivi esempi utilizzando il modello stesso, modelli ausiliari e altri strumenti.
Costruire ed eseguire il RAG-Retrieval con Milvus
Preparare il set di dati
Per questa dimostrazione ho usato il dataset ufficiale Milvus documentation, che ho scaricato e salvato in locale.
da langchain.document_loaders import DirectoryLoader
# Carica i file HTML già salvati in una directory locale
percorso = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(path=percorso, glob=pattern_globale)
docs = loader.load()
# Stampa num documenti e un'anteprima.
print(f "caricato {len(docs)} documenti")
print(docs[0].page_content)
pprint.pprint(docs[0].metadata)
 loaded 22 docs
loaded 22 docs
Scaricare un modello di incorporamento
Successivamente, scaricare un modello di incorporamento gratuito e open-source da HuggingFace.
importare torch
da sentence_transformers import SentenceTransformer
# Inizializza le impostazioni di torch per il codice indipendente dal dispositivo.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Scaricare il modello dall'hub dei modelli di huggingface.
nome_modello = "BAAI/bge-large-en-v1.5"
encoder = SentenceTransformer(nome_modello, device=DEVICE)
# Ottenere i parametri del modello e salvarli in seguito.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Ispezionare i parametri del modello.
print(f "nome_modello: {nome_modello}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

Sminuzza e codifica i dati personalizzati come vettori.
Utilizzerò una lunghezza fissa di 512 caratteri con una sovrapposizione del 10%.
da langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# Definire lo splitter.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap)
# Tagliare i documenti.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} documenti divisi in {len(chunks)} documenti figli.")
# L'input del codificatore è doc.page_content come stringhe.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')]
# Inferenza dell'incorporamento usando l'encoder HuggingFace.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Normalizzare le incorporazioni.
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus si aspetta un elenco di `numpy.ndarray` di numeri `numpy.float32`.
valori_convertiti = lista(map(np.float32, embeddings))
# Creare dict_list per l'inserimento in Milvus.
dict_list = []
per chunk, vector in zip(chunks, converted_values):
# Assemblare il vettore di incorporamento, il chunk di testo originale e i metadati.
chunk_dict = {
'chunk': chunk.page_content,
'source': chunk.metadata.get('source', ""),
'vector': vector,
}
dict_list.append(chunk_dict)

Salvare i vettori in Milvus
Inserisce l'embedding vettoriale codificato nel database dei vettori di Milvus.
# Connettere un client al server Milvus Lite.
da pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Creare una raccolta con schema flessibile e AUTOINDEX.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventualmente",
auto_id=True,
overwrite=True)
# Inserire i dati nella collezione Milvus.
print("Iniziare a inserire le entità")
ora_inizio = time.time()
mc.insert(
NOME_RACCOLTA,
dati=lista_di_detti,
progress_bar=True)
end_time = time.time()
print(f "Tempo di inserimento di Milvus per i vettori {len(dict_list)}: ", end="")
print(f"{arrotondamento(ora_fine - ora_inizio, 2)} secondi")

Eseguire una ricerca vettoriale
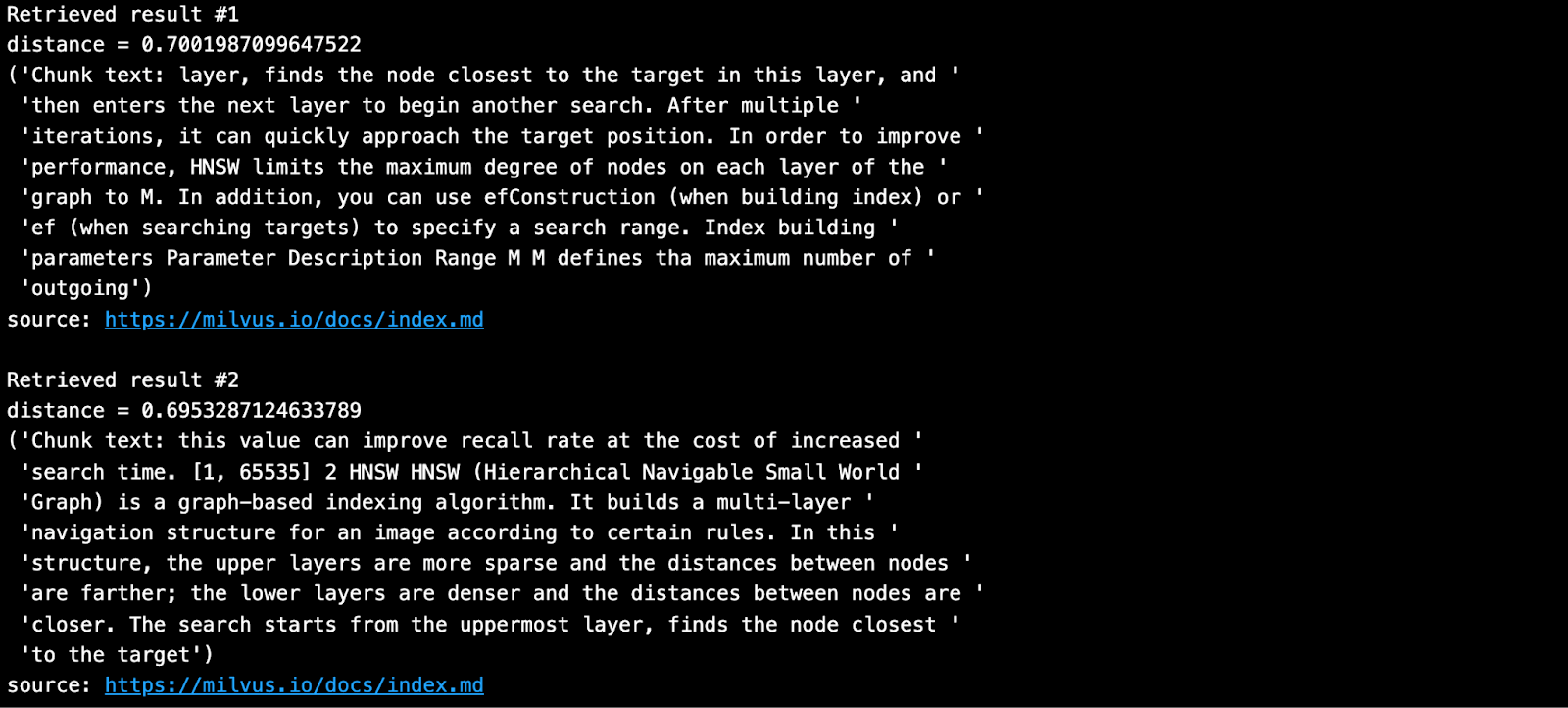
Porre una domanda e cercare i pezzi più vicini dalla propria base di conoscenze in Milvus.
SAMPLE_QUESTION = "Cosa significano i parametri di HNSW?".
# Incorpora la domanda usando lo stesso codificatore.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Normalizzare le incorporazioni a lunghezza unitaria.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# Convertire gli embeddings in liste di np.float32.
query_embeddings = list(map(np.float32, query_embeddings))
# Definire i campi dei metadati su cui filtrare.
OUTPUT_FIELDS = elenco(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# Definire il numero di risultati top-k da recuperare.
TOP_K = 2
# Eseguire la ricerca vettoriale semantica usando la query e il database dei vettori.
risultati = mc.search(
NOME_RACCOLTA,
dati=query_embeddings,
campi_uscita=OUTPUT_FIELDS,
limite=TOP_K,
consistency_level="Eventualmente")
Il risultato recuperato è quello mostrato di seguito.
Costruire ed eseguire la generazione RAG con vLLM e Llama 3.1-8B
Installare vLLM e i modelli di HuggingFace
Per impostazione predefinita, vLLM scarica modelli linguistici di grandi dimensioni da HuggingFace. In generale, ogni volta che si vuole usare un modello nuovo su HuggingFace, si deve fare un pip install--update o -U. Inoltre, è necessaria una GPU per eseguire l'inferenza dei modelli Llama 3.1 di Meta con vLLM.
Per un elenco completo di tutti i modelli supportati da vLLM, vedere questa pagina di documentazione.
# (consigliato) Creare un nuovo ambiente conda.
conda create -n myenv python=3.11 -y
conda attivare myenv
# Installare vLLM con CUDA 12.1.
pip install -U vllm transformers torch
importare vllm, torch
da vllm importare LLM, SamplingParams
# Cancella la cache di memoria della GPU.
torch.cuda.empty_cache()
# Controllare la GPU.
nvidia-smi
Per saperne di più su come installare vLLM, vedere la pagina installation.
Ottenere un token HuggingFace
Alcuni modelli su HuggingFace, come Meta Llama 3.1, richiedono che l'utente accetti la loro licenza prima di poter scaricare i pesi. Pertanto, è necessario creare un account HuggingFace, accettare la licenza del modello e generare un token.
Quando si visita questa pagina Llama3.1 su HuggingFace, viene visualizzato un messaggio che chiede di accettare i termini. Fare clic su "Accetta licenza" per accettare i termini di Meta prima di scaricare i pesi del modello. L'approvazione di solito richiede meno di un giorno.
Dopo aver ricevuto l'approvazione, è necessario generare un nuovo token HuggingFace. I vecchi token non funzioneranno con le nuove autorizzazioni.
Prima di installare vLLM, accedere a HuggingFace con il nuovo token. Di seguito, ho usato i segreti di Colab per memorizzare il token.
# Accedere a HuggingFace usando il nuovo token.
da huggingface_hub import login
da google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Eseguire la generazione RAG
Nella demo, viene eseguito il modello Lama-3.1-8B, che richiede una GPU e una notevole quantità di memoria. Il seguente esempio è stato eseguito su Google Colab Pro ($10/mese) con una GPU A100. Per saperne di più su come eseguire vLLM, è possibile consultare la Quickstart documentation.
# 1. Scegliere un modello
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Istruzione"
# 2. Svuotare la cache della memoria della GPU, ne avrà bisogno tutta!
torch.cuda.empty_cache()
# 3. Istanziare un'istanza del modello vLLM.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0,5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Scrivere un prompt utilizzando contesti e fonti recuperati da Milvus.
# Separare tutti i contesti insieme con uno spazio.
contesti_combinati = ' '.join(contesti)
# Lance Martin, LangChain, dice di mettere i contesti migliori alla fine.
contesti_combinati = ' '.join(reversed(contexts))
# Separare tutte le fonti uniche insieme con una virgola.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""Per prima cosa, verificare se il contesto fornito è pertinente alla domanda dell'utente.
domanda dell'utente. In secondo luogo, solo se il contesto fornito è fortemente pertinente, rispondere alla domanda utilizzando il contesto. Altrimenti, se il contesto non è fortemente pertinente, rispondere alla domanda senza utilizzare il contesto.
Essere chiari, concisi e pertinenti. Rispondete in modo chiaro, in meno di 2 frasi.
Fonti di riferimento: {fonte_combinata}
Contesto: {contesti_combinati}
Domanda dell'utente: {DOMANDA_DI_ESEMPIO}
"""
prompts = [SYSTEM_PROMPT]
Ora, generare una risposta usando i pezzi recuperati e la domanda originale inserita nel prompt.
# Parametri di campionamento
sampling_params = SamplingParams(temperature=0.2, top_p=0.95)
# Invocare il modello vLLM.
output = llm.generate(prompt, sampling_params)
# Stampa gli output.
per output in outputs:
prompt = output.prompt
testo_generato = output.outputs[0].text
# !r chiama repr(), che stampa una stringa tra virgolette.
print()
print(f "Domanda: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Testo generato: {testo_generato!r}")

La risposta qui sopra mi sembra perfetta!
Se sei interessato a questa demo, sentiti libero di provarla e facci sapere cosa ne pensi. Sei anche invitato a unirti alla nostra comunità Milvus su Discord per conversare direttamente con tutti gli sviluppatori di GenAI.
Riferimenti
Presentazione di vLLM 2023 al Ray Summit
blog vLLM: vLLM: Servizio LLM facile, veloce ed economico con PagedAttention
Blog utile sull'esecuzione del server vLLM: Deploying vLLM: a Step-by-Step Guide

Continua a leggere

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.