




Réduction de la dimensionnalité : Simplifier les données complexes pour faciliter l'analyse
**La réduction de la dimensionnalité est un processus utilisé en science des données et en apprentissage automatique pour réduire le nombre de variables, ou "dimensions", dans un ensemble de données tout en conservant autant d'informations pertinentes que possible. Cette réduction simplifie l'analyse, la visualisation et le traitement des données, en particulier dans les ensembles de données à haute dimension. Des techniques telles que l'analyse en composantes principales (ACP) et le t-Distributed Stochastic Neighbor Embedding (t-SNE) identifient des modèles et des relations au sein des données, en les projetant sur un nombre réduit de dimensions. En éliminant les caractéristiques les moins significatives, la réduction de la dimensionnalité permet d'améliorer l'efficacité des calculs et d'atténuer l'ajustement excessif, ce qui la rend essentielle pour la gestion de données complexes, en particulier dans des domaines tels que l'analyse d'images et de textes.
Réduction de la dimensionnalité : Simplifier les données complexes pour faciliter l'analyse
La réduction de la dimensionnalité simplifie un ensemble de données en réduisant le nombre de variables d'entrée ou de caractéristiques tout en conservant les informations importantes. Elle joue un rôle essentiel dans la science des données et l'apprentissage automatique. Elle permet de mieux gérer les grands ensembles de données, d'améliorer les performances des modèles et d'économiser de précieuses ressources informatiques.
Imaginez que vous disposiez d'une feuille de calcul complexe et volumineuse, remplie de nombreuses colonnes de données. Si certaines de ces colonnes ne sont pas utiles ou doivent être clarifiées pour l'analyse, la réduction de la dimensionnalité les réduit pour faciliter la reconnaissance des modèles.
La malédiction de la dimensionnalité
La [malédiction de la dimensionnalité] (https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning) fait référence aux problèmes qui surviennent lors de l'analyse et de l'organisation des données dans des espaces à haute dimension. À mesure que le nombre de caractéristiques (ou dimensions) augmente, le volume de l'espace s'accroît si rapidement que les données disponibles deviennent éparses. Cette rareté fait qu'il est difficile pour les algorithmes de trouver des modèles significatifs, ce qui rend l'analyse des données inefficace et peu fiable.
Pour comprendre l'impact, imaginez que vous essayez de mesurer la distance entre des points dans un espace unidimensionnel, comme une ligne droite. Les points sont suffisamment proches pour être facilement mesurés. Si vous élargissez l'espace à deux dimensions, comme une feuille de papier plane, les points s'éloignent davantage. Si vous passez à trois dimensions, comme une pièce, les points s'étalent encore plus. Au fur et à mesure que les dimensions augmentent, les points deviennent si éloignés les uns des autres qu'ils semblent presque isolés, et le calcul de la distance devient moins utile. C'est ce qui se produit dans les données à haute dimension, où les techniques courantes d'analyse des données peuvent ne pas fonctionner efficacement parce que les relations entre les points de données sont diluées, comme le montre la figure.
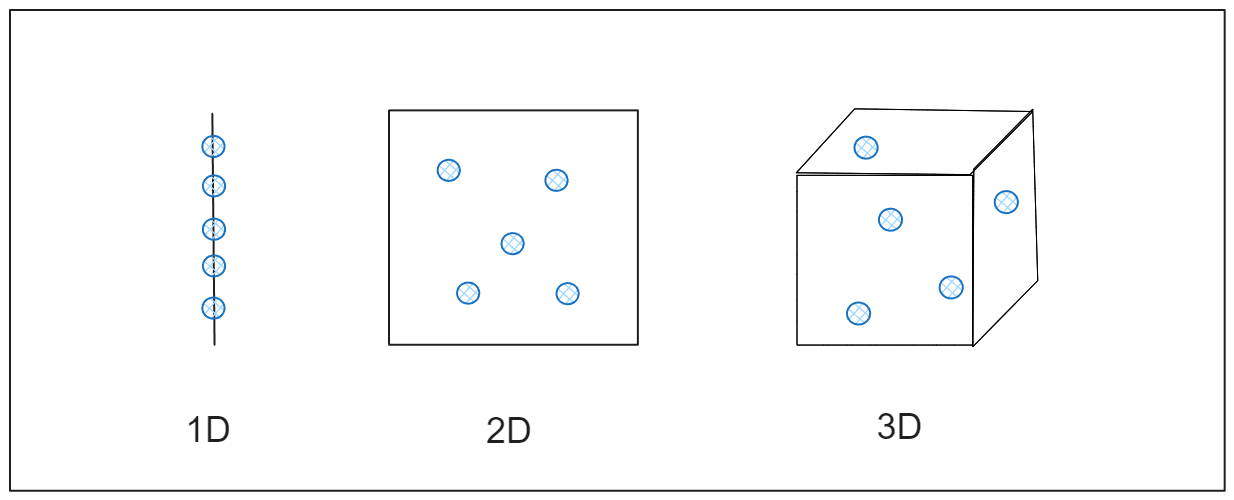 Figure- How Data Expands Across Dimensions.png
Figure- How Data Expands Across Dimensions.png
Figure: Comment les données s'étendent à travers les dimensions
Une analogie simple consiste à trouver des amis dans un parc. Vous pouvez vous localiser rapidement si vous et vos amis êtes dispersés dans un petit parc. Mais imaginez que le parc prenne la taille d'une grande ville. Maintenant, même avec le même nombre d'amis, il devient difficile d'en trouver un parce que tout le monde est trop éloigné. De même, dans les espaces à haute dimension, les points de données sont dispersés, ce qui empêche les algorithmes de les organiser ou de les analyser efficacement.
Techniques clés de réduction de la dimensionnalité
Bien qu'il existe différentes [stratégies de réduction de la dimensionnalité] (https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality), on peut les classer en deux grandes catégories : Sélection de caractéristiques et Extraction de caractéristiques. Ces deux méthodes visent à simplifier les données, mais de manière différente.
Sélection des caractéristiques
La sélection des caractéristiques réduit la dimensionnalité en sélectionnant un sous-ensemble des caractéristiques les plus pertinentes de l'ensemble de données original. Au lieu de transformer les données, cette approche conserve les caractéristiques telles quelles, mais supprime celles qui ne contribuent pas de manière significative à l'analyse ou à la performance du modèle. L'objectif est de supprimer les caractéristiques redondantes ou non pertinentes afin de simplifier l'ensemble de données et d'en faciliter l'utilisation.
Trois méthodes sont couramment utilisées pour la sélection des caractéristiques :
Méthodes de filtrage : Elles utilisent des tests statistiques pour classer les caractéristiques en fonction de leur importance. Les exemples incluent les scores de corrélation, le gain d'information et les tests chi-carré. Elles sont simples et fonctionnent indépendamment du modèle d'apprentissage automatique.
Méthodes d'enveloppement** : Elles évaluent différents sous-ensembles de caractéristiques et utilisent les performances du modèle pour déterminer la meilleure combinaison. Bien qu'elles soient plus précises, elles peuvent être coûteuses en termes de calcul. Les techniques telles que l'élimination récursive des caractéristiques (RFE), la sélection en amont et l'élimination en aval entrent dans cette catégorie.
Méthodes intégrées : Ces techniques intègrent la sélection des caractéristiques dans le processus d'apprentissage du modèle. Les modèles tels que les arbres de décision, la régression Lasso et la régression ridge identifient automatiquement les caractéristiques importantes dans le cadre de leur apprentissage.
Extraction de caractéristiques
L'extraction de caractéristiques transforme les caractéristiques d'origine dans un espace de dimension inférieure, créant ainsi de nouvelles caractéristiques qui capturent toujours les informations essentielles. Cette approche est utile lorsque vous comprimez des données tout en conservant des relations significatives entre les caractéristiques. Contrairement à la sélection de caractéristiques, l'extraction de caractéristiques crée des représentations entièrement nouvelles des données.
Les techniques les plus largement adaptées sont l'analyse en composantes principales (ACP), l'intégration des voisins stochastiques distribués (t-SNE) et l'analyse discriminante linéaire (LDA). Examinons-les en détail.
Analyse en composantes principales (ACP)
L'analyse en composantes principales (ACP) est une technique populaire utilisée pour la réduction de la dimensionnalité. Son objectif principal est de simplifier un grand ensemble de variables en un ensemble plus petit qui capture encore la plupart des informations contenues dans les données d'origine.
Pour comprendre simplement l'ACP, il suffit de considérer un ensemble de données comme un objet multidimensionnel, comme un nuage de points dans l'espace. L'ACP trouve les directions (ou axes) où les données varient le plus et projette les données sur ces nouveaux axes. Le premier axe, appelé composante principale, capture la plus grande variance (ou dispersion) des données. Le deuxième axe capte la variance suivante, et ainsi de suite. En se concentrant sur les quelques premières composantes, l'ACP réduit le nombre de dimensions tout en conservant intacte la structure principale des données.
Les diagrammes suivants montrent comment l'ACP permet de simplifier les données. À gauche, un nuage de points répartis dans deux directions. L'ACP trouve la direction principale dans laquelle les données varient le plus, comme le montre la flèche noire. Le côté droit montre que les données sont aplaties dans cette direction.
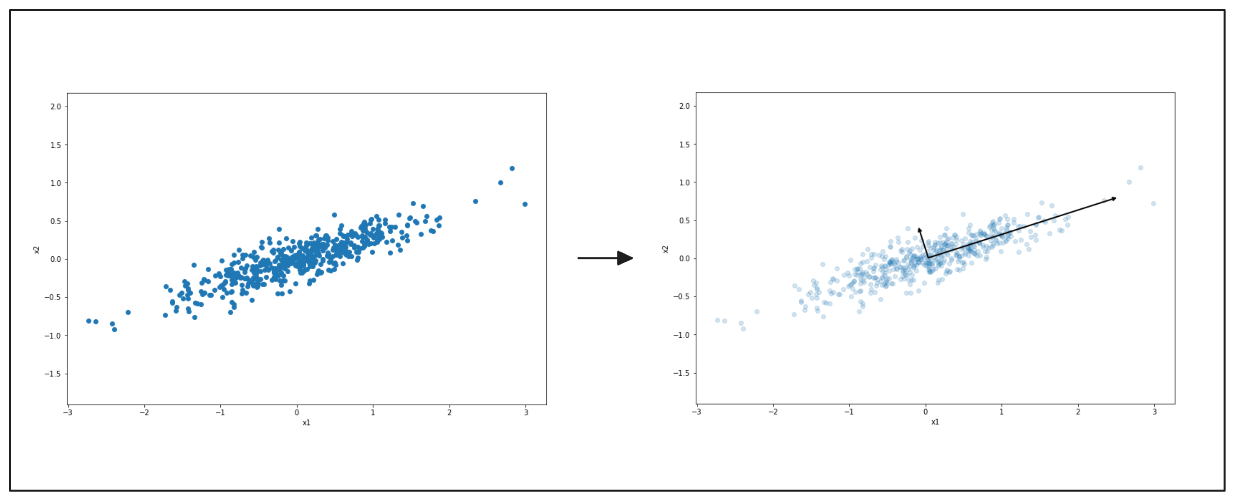 Figure- ACP mettant en évidence la direction principale de variation des données..png
Figure- ACP mettant en évidence la direction principale de variation des données..png
Figure: L'ACP met en évidence le sens principal de la variation des données.
À nouveau, sur la gauche, vous voyez des données réparties en deux dimensions. La flèche noire indique la direction principale de la variation. À droite, les données sont comprimées sur cette ligne, ce qui les réduit à une forme plus simple. Ce processus permet de travailler plus facilement avec les données tout en conservant les principales tendances.
Figure- Représentation simplifiée des données avec l'ACP.png](https://assets.zilliz.com/Figure_Simplified_Data_Representation_with_PCA_f7d49bc32b.png)
Figure: Représentation simplifiée des données avec l'ACP
**Les avantages de l'ACP
Réduction de la complexité** : La simplification des ensembles de données comportant de nombreuses variables rend l'analyse plus rapide et plus efficace.
Supprime le bruit** : L'ACP filtre le bruit et les informations non pertinentes en conservant les composantes présentant la plus grande variance.
Améliore la visualisation** : L'ACP permet de visualiser des données à haute dimension en deux ou trois dimensions, en révélant des modèles qui pourraient autrement être cachés.
**Les inconvénients de l'ACP
Perte d'informations** : Certaines données peuvent être perdues lors de la réduction de la dimensionnalité, ce qui affecte les performances du modèle.
Difficulté d'interprétation** : Les nouvelles caractéristiques créées par l'ACP sont des combinaisons des caractéristiques originales, ce qui les rend difficiles à interpréter de manière significative.
Hypothèse de linéarité** : L'ACP fonctionne mieux lorsque les relations entre les variables sont linéaires, ce qui n'est pas toujours le cas.
**Applications pratiques
Compression d'images** : Réduit la taille des fichiers d'images tout en conservant les principales caractéristiques visuelles.
Finance** : Simplifie des ensembles de données complexes afin d'identifier des modèles dans les mouvements de prix des actions.
Génétique** : Analyse de grands ensembles de données génomiques pour découvrir des structures de données significatives.
Versatilité** : Utile pour simplifier et interpréter des données à haute dimension dans divers domaines.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
Le t-Distributed Stochastic Neighbor Embedding (t-SNE) permet de visualiser des données de haute dimension. Il projette les données en deux ou trois dimensions afin d'identifier les groupes et les modèles. t-SNE est largement apprécié pour sa capacité à maintenir les relations locales entre les points de données, ce qui permet de révéler la structure sous-jacente de l'ensemble de données. Cette méthode est plus adaptée aux ensembles de données dans l'espace 3D.
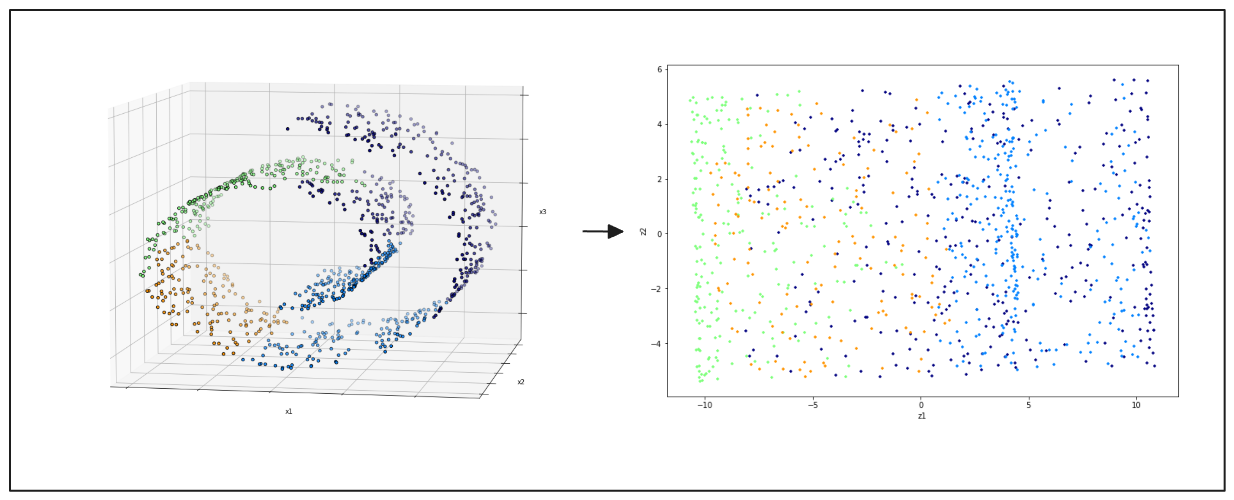 Figure- gauche- points de données 3D en rouleau suisse, droite- résultat de la projection 2D de l'ACP.png
Figure- gauche- points de données 3D en rouleau suisse, droite- résultat de la projection 2D de l'ACP.png
Figure: à gauche : points de données 3D du rouleau suisse, à droite : résultat de la projection 2D de l'ACP
Avantages de l'utilisation de t-SNE
Préservation de la structure locale** : le t-SNE excelle à maintenir les points de données proches dans l'espace de dimension inférieure, ce qui le rend efficace pour la visualisation des grappes.
Il est utile pour les données complexes : Il est particulièrement efficace pour traiter les relations non linéaires et explorer les schémas complexes dans les données.
Excellent pour la visualisation** : t-SNE produit des diagrammes de dispersion visuellement intuitifs et attrayants qui aident à comprendre la disposition des données.
**Les inconvénients de l'utilisation de l'ENT-T
L'utilisation de t-SNE peut être lente et gourmande en ressources, en particulier en ce qui concerne le traitement des données : L'exécution de t-SNE peut être lente et gourmande en ressources, en particulier pour les grands ensembles de données.
Nécessite l'ajustement des paramètres** : Les paramètres tels que la perplexité et le taux d'apprentissage doivent être définis avec soin, et les résultats peuvent varier de manière significative en fonction de ces paramètres.
Dénature la structure globale** : Si le t-SNE préserve bien les relations locales, il peut déformer la structure globale des données et s'avérer moins utile pour comprendre les relations à grande échelle.
**Applications pratiques
Visualisation de données à haute dimension** : Utile pour explorer les structures en grappes.
Reconnaissance d'images** : Visualisation de la distribution des caractéristiques des images.
Traitement du langage naturel** (NLP)] (https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing) : explore les enchâssements de mots.
Génomique : Identifie des groupes de données génétiques significatifs.
Popularité** : Largement utilisé par les scientifiques des données pour obtenir des informations visuelles, malgré ses limites.
Analyse discriminante linéaire (LDA)
Contrairement à l'ACP, la LDA vise à maximiser la séparation entre les différentes classes des données. Pour ce faire, elle projette les données sur un espace de dimension inférieure qui sépare au mieux les catégories sur la base de leurs étiquettes.
LDA est couramment utilisé dans les scénarios où la [classification des données] (https://zilliz.com/glossary/classification) est l'objectif principal. Il est particulièrement utile lorsqu'il s'agit d'ensembles de données dont les classes sont clairement délimitées. Parmi les applications pratiques, citons la reconnaissance faciale, le diagnostic médical et la classification de textes.
Quelle est la différence entre la LDA et l'ACP ?
Objectif : LDA se concentre sur la maximisation de la séparabilité des classes, tandis que l'ACP vise à capturer le plus de variance possible dans les données sans tenir compte des étiquettes de classe.
Supervision et non-supervision** : LDA est une [technique supervisée] (https://zilliz.com/glossary/supervised-machine-learning) qui utilise des étiquettes de classe dans ses calculs. L'ACP, en revanche, est non supervisée et n'utilise aucune information sur les étiquettes.
Variance des données** : LDA réduit les dimensions en trouvant les axes qui maximisent la distance entre les moyennes des différentes classes tout en minimisant la dispersion au sein de chaque classe. L'ACP ne prend pas en compte les informations relatives aux classes et son seul objectif est de réduire la redondance des données.
Autres techniques et méthodes émergentes
Outre les techniques traditionnelles de réduction de la dimensionnalité telles que l'ACP, le t-SNE et la LDA, plusieurs autres méthodes et tendances émergentes gagnent du terrain dans l'analyse des données.
Autoencodeurs
Les autoencodeurs sont des [réseaux neuronaux] (https://zilliz.com/glossary/neural-networks) utilisés pour l'apprentissage non supervisé qui visent à compresser les données dans une représentation de dimension inférieure, puis à les reconstruire sous leur forme originale. Le réseau se compose d'un encodeur qui réduit la dimensionnalité et d'un décodeur qui reconstruit l'entrée à partir de la représentation comprimée. Les autoencodeurs sont utiles pour traiter les relations non linéaires dans les données et peuvent apprendre des représentations de caractéristiques complexes.
Analyse en composantes indépendantes (ICA)
L'analyse en composantes indépendantes (ICA) est une technique informatique permettant de séparer un signal multivarié en composantes additives et indépendantes. Contrairement à l'ACP, qui se concentre sur la variance, l'ICA recherche des sources statistiquement indépendantes. Cette méthode est souvent utilisée dans des applications telles que la séparation aveugle des sources, par exemple pour isoler différentes sources audio d'un enregistrement mixte.
Approximation et projection uniformes d'un milieu (UMAP)
La méthode UMAP (Uniform Manifold Approximation and Projection) est une technique relativement nouvelle de réduction de la dimensionnalité qui préserve les structures locales et globales des données. Elle est basée sur l'apprentissage des manifolds et vise à maintenir les relations entre les points de données au cours du processus de réduction. UMAP est plus rapide et produit souvent de meilleures visualisations que t-SNE.
Avantages de la réduction de la dimensionnalité
La réduction de la dimensionnalité offre plusieurs avantages clés qui améliorent l'analyse des ensembles de données complexes :
Modèles simplifiés : Un nombre réduit de caractéristiques permet d'obtenir des modèles plus simples, plus faciles à former et à analyser, ce qui peut s'avérer crucial pour les applications soumises à des contraintes de temps.
Réduction des besoins de stockage et de calcul** : Le traitement de données de dimensions inférieures permet de réduire le stockage et d'accélérer les temps de traitement, ce qui peut réduire les coûts d'exploitation, en particulier pour les grands ensembles de données.
Amélioration des performances des modèles** : En prenant en compte les caractéristiques les plus significatives, les modèles peuvent devenir plus précis et plus robustes, car ils sont moins susceptibles d'être affectés par des données non pertinentes.
Améliore l'interprétabilité** : La réduction des dimensions peut aider à mettre en évidence les relations essentielles dans les données qui aident les parties prenantes à comprendre les décisions du modèle et les modèles sous-jacents.
Facilite la visualisation des données** : La transformation de données à haute dimension en deux ou trois dimensions permet des représentations visuelles plus claires, aidant à découvrir des informations qui peuvent ne pas être évidentes dans les dimensions supérieures.
Aide à la réduction du bruit** : En supprimant les dimensions les moins importantes, la réduction de la dimensionnalité peut diminuer la quantité de bruit, ce qui permet d'obtenir des ensembles de données plus propres qui contribuent à des analyses plus fiables.
La réduction de la dimensionnalité permet de réduire le bruit, ce qui se traduit par des ensembles de données plus propres qui contribuent à des analyses plus fiables : Le processus peut aider à identifier les caractéristiques les plus importantes, offrant ainsi la possibilité de créer des caractéristiques améliorées qui peuvent conduire à une meilleure performance du modèle.
Permet un prototypage plus rapide** : Avec moins de dimensions à prendre en compte, les scientifiques des données peuvent itérer sur le développement du modèle rapidement pour tester et affiner les modèles.
Les défis de la réduction de la dimensionnalité
Les techniques de réduction de la dimensionnalité s'accompagnent de plusieurs défis qu'il convient d'examiner attentivement :
Risque de perte d'informations importantes : La réduction des dimensions peut entraîner l'élimination involontaire de caractéristiques essentielles, ce qui peut avoir une incidence négative sur les performances du modèle et conduire à une interprétation erronée des résultats.
Choisir la bonne technique** : L'efficacité des méthodes de réduction de la dimensionnalité varie en fonction de la nature de l'ensemble de données et des objectifs analytiques spécifiques. Cette variabilité fait qu'il est crucial de comprendre les forces et les limites de chaque technique afin d'éviter des résultats inefficaces.
Coût de calcul** : Les techniques telles que le t-SNE peuvent être gourmandes en ressources et moins adaptées aux grands ensembles de données. Les exigences en termes de temps et de mémoire peuvent limiter considérablement leur applicabilité dans les scénarios où le temps est compté.
Équilibrer la réduction et la précision** : Atteindre le bon niveau de réduction de la dimensionnalité tout en s'assurant que le modèle conserve suffisamment d'informations pour des prédictions précises est un défi constant. Une réduction excessive peut simplifier les données à l'excès, ce qui a un impact sur la capacité du modèle à saisir la complexité nécessaire.
Applications de la réduction de la dimensionnalité dans divers secteurs d'activité
Les techniques de réduction de la dimensionnalité trouvent des applications dans divers domaines, améliorant l'analyse des données et la performance des modèles. Voici quelques scénarios pratiques dans lesquels ces méthodes sont couramment utilisées :
Traitement d'images : Dans des domaines tels que la vision par ordinateur, la réduction de la dimensionnalité permet de compresser les données d'image tout en préservant les caractéristiques essentielles. Par exemple, dans le domaine de la reconnaissance faciale, l'ACP peut réduire des milliers de valeurs de pixels en caractéristiques plus petites, ce qui accélère le traitement sans perdre de détails essentiels. De même, dans le domaine de l'imagerie médicale, la réduction de la dimensionnalité met en évidence les zones importantes des images IRM pour une analyse plus rapide.
Traitement du langage naturel** : La réduction de la dimensionnalité est utilisée pour simplifier les données textuelles à haute dimension, telles que les enchâssements de mots. Des méthodes telles que t-SNE permettent de visualiser les relations entre les mots et les groupes de mots, ce qui facilite l'analyse des sentiments et la modélisation des sujets.
Génomique : En bio-informatique, les techniques de réduction de la dimensionnalité sont essentielles pour analyser les données génétiques, où le nombre de variables (gènes) peut être extrêmement élevé. La réduction des dimensions permet d'identifier les marqueurs génétiques clés liés aux maladies.
Finances : La réduction de la dimensionnalité aide à la gestion des risques et à l'optimisation des portefeuilles en simplifiant les grands ensembles de données d'indicateurs financiers. Les analystes peuvent choisir les caractéristiques les plus pertinentes qui influencent le comportement du marché.
Systèmes de recommandation**] (https://zilliz.com/learn/Introduction-to-Recommendation-systems) : Dans le filtrage collaboratif et basé sur le contenu, la réduction de la dimensionnalité aide à créer des algorithmes de recommandation plus efficaces en identifiant des modèles sous-jacents dans les préférences des utilisateurs et les caractéristiques des articles.
Santé : L'analyse des données des patients implique souvent des ensembles de données à haute dimension. La réduction de la dimensionnalité permet d'identifier les facteurs significatifs affectant les résultats des patients, améliorant ainsi la modélisation prédictive de la progression de la maladie.
Analyse marketing : Dans le domaine du marketing, il est essentiel de comprendre le comportement des clients. La réduction de la dimensionnalité permet aux entreprises de segmenter facilement les clients en réduisant la complexité des données clients, ce qui permet d'élaborer des stratégies de marketing ciblées.
Fabrication et contrôle de la qualité** : Dans les applications industrielles, la réduction de la dimensionnalité permet d'analyser les données des capteurs des machines afin d'identifier les modèles et les anomalies, ce qui permet d'améliorer le contrôle de la qualité et la maintenance prédictive.
Comment la réduction de la dimensionnalité améliore-t-elle les performances des bases de données vectorielles ?
La réduction de la dimensionnalité améliore considérablement les performances des bases de données vectorielles telles que Milvus (créée par les ingénieurs de Zilliz), qui est conçue pour gérer les données non structurées à grande échelle et leurs représentations vectorielles à haute dimension. Voici comment ils sont interconnectés :
Stockage efficace des données : Milvus peut stocker des données vectorielles à haute dimension générées par des modèles d'apprentissage automatique. L'application de techniques de réduction de la dimensionnalité, telles que l'ACP ou le t-SNE, permet de compresser ces vecteurs, ce qui réduit les besoins de stockage et améliore les vitesses de récupération.
Amélioration des performances des requêtes** : Dans une base de données vectorielle, la recherche dans des données de haute dimension peut être très coûteuse en temps de calcul. La réduction de la dimensionnalité minimise la dimensionnalité des vecteurs, ce qui accélère les [recherches de similarité] (https://zilliz.com/blog/similarity-metrics-for-vector-search) et les [requêtes sur les plus proches voisins] (https://zilliz.com/glossary/anns).
Visualisation améliorée des données** : Lors de l'utilisation de Zilliz ou Milvus pour l'analyse des données, les techniques de réduction de la dimensionnalité peuvent faciliter la visualisation d'ensembles de données complexes. Cela permet aux utilisateurs de mieux comprendre les distributions de données, les relations et les modèles dans les données à haute dimension stockées dans la base de données.
Faciliter les flux de travail d'apprentissage automatique** : Dans les pipelines d'apprentissage automatique, la réduction de la dimensionnalité peut contribuer à rationaliser le prétraitement des données. La réduction de la complexité des caractéristiques d'entrée améliore la formation des modèles d'apprentissage automatique, ce qui se traduit par une amélioration des performances et de l'interprétabilité.
Conclusion
La réduction de la dimensionnalité est une technique importante en science des données et en apprentissage automatique qui simplifie les ensembles de données complexes tout en préservant les informations essentielles. La réduction du nombre de caractéristiques améliore les performances des modèles, facilite la visualisation et facilite l'analyse des données dans différents domaines. Malgré ses difficultés, telles que le risque de perdre des informations importantes et la nécessité de sélectionner soigneusement les techniques, les avantages de la réduction de la dimensionnalité la rendent inestimable pour découvrir des informations et améliorer l'efficacité des processus analytiques.
FAQ sur la réduction de la dimensionnalité
- Qu'est-ce que la réduction de la dimensionnalité ?
La réduction de la dimensionnalité est une technique utilisée pour réduire le nombre de caractéristiques ou de dimensions dans un ensemble de données tout en préservant autant d'informations pertinentes que possible. Cette simplification facilite l'analyse, la visualisation et la modélisation de données complexes.
- Pourquoi la réduction de la dimensionnalité est-elle importante en science des données ?
Elle permet d'améliorer les performances des modèles, de réduire les besoins de stockage et de calcul, d'améliorer la visualisation des données et de simplifier l'interprétation des modèles, ce qui la rend essentielle pour une analyse efficace des données dans diverses applications.
- Quelles sont les techniques courantes de réduction de la dimensionnalité ?
Les techniques courantes comprennent l'analyse en composantes principales (ACP), l'intégration des voisins stochastiques distribués (t-SNE), l'analyse discriminante linéaire (LDA), les méthodes de sélection des caractéristiques et les techniques émergentes telles que les autoencodeurs et l'UMAP.
- Quels sont les défis associés à la réduction de la dimensionnalité ?
Les défis comprennent le risque de perdre des informations importantes, la difficulté de choisir la bonne technique pour des ensembles de données spécifiques, les coûts de calcul de certaines méthodes et l'équilibre entre la réduction de la dimensionnalité et la précision du modèle.
- Comment la réduction de la dimensionnalité profite-t-elle aux bases de données vectorielles comme Milvus ?
La réduction de la dimensionnalité améliore les performances des bases de données vectorielles en optimisant le stockage des données, en améliorant les performances des requêtes, en facilitant la visualisation des données et en rationalisant les flux de travail d'apprentissage automatique.
Ressources connexes
Techniques d'interrogation avancées dans les bases de données vectorielles](https://zilliz.com/learn/advanced-querying-techniques-in-vector-databases)
Rationalisation des données : stratégies efficaces pour réduire la dimensionnalité
La malédiction de la dimensionnalité dans l'apprentissage automatique
Normalisation par lots ou par couches - débloquer l'efficacité des réseaux neuronaux
[Qu'est-ce que Milvus ?] (https://zilliz.com/what-is-milvus)
- La malédiction de la dimensionnalité
- Techniques clés de réduction de la dimensionnalité
- Autres techniques et méthodes émergentes
- Avantages de la réduction de la dimensionnalité
- Les défis de la réduction de la dimensionnalité
- Applications de la réduction de la dimensionnalité dans divers secteurs d'activité
- Comment la réduction de la dimensionnalité améliore-t-elle les performances des bases de données vectorielles ?
- Conclusion
- FAQ sur la réduction de la dimensionnalité
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement