




Arrêtez de construire une infrastructure de données IA pour la mauvaise étape
La plupart des décisions d’infrastructure IA sont prises dès la première semaine et regrettées quand on les réexamine en deuxième année.
Le problème vient presque jamais du modèle, et rarement de la logique applicative. Il revient toujours à la même chose : l’infrastructure de données doit être conçue pour le stade où se trouve l’équipe.
À chaque stade, le mode d’échec va dans les deux sens. Surdimensionnez trop tôt et vous vous ralentissez. Sous-estimez, et vous reconstruisez sous pression. Les deux produisent le même résultat : une surcharge d’itération qui s’accumule.
Stage 1: Le Prototype — Faites-le Simplement Fonctionner
Au début, la vitesse compte beaucoup plus que l’infra de données — ou en réalité, il n’y a pas du tout besoin d’une soi-disant « infra de données ».
L’objectif n’est pas la scalabilité. L’objectif n’est pas la gouvernance. L’objectif n’est pas l’optimisation.
L’objectif est simplement de faire fonctionner l’application.
L’erreur la plus courante à ce stade est de confondre sophistication et qualité. Les équipes ajoutent des pipelines d’ingestion en streaming avant même d’avoir des documents à ingérer. Elles mettent en place une réplication de niveau production avant même d’avoir un seul véritable utilisateur. Elles s’inquiètent de la cohérence des données entre plusieurs systèmes avant d’avoir assez de données pour que la cohérence ait de l’importance.
Résultat : des semaines de travail d’infrastructure qui auraient pu être livrées sous forme d’un simple changement d’idée.
Quant au sujet brûlant de la « vector database », il importe à peine. Milvus, Elasticsearch, pgvector, ou même une bibliothèque de recherche légère — n’importe lequel fera l’affaire. L’écart de qualité de récupération entre les options est négligeable comparé à l’écart entre avoir un prototype fonctionnel et ne pas en avoir.

Ce dont vous avez réellement besoin à ce stade :
- Votre système de fichiers local
- N’importe quelle base de données ou bibliothèque de recherche légère
Stage 2: Product-Market Fit — Plus de Bases de Données, Plus de Problèmes
Une fois que de vrais utilisateurs commencent à interagir avec le système, l’attention passe de la construction d’une démo à l’amélioration continue du produit, mais un autre piège apparaît.
L’idée reçue semble raisonnable : davantage de types de bases de données spécialisées mènent à une meilleure qualité de récupération.
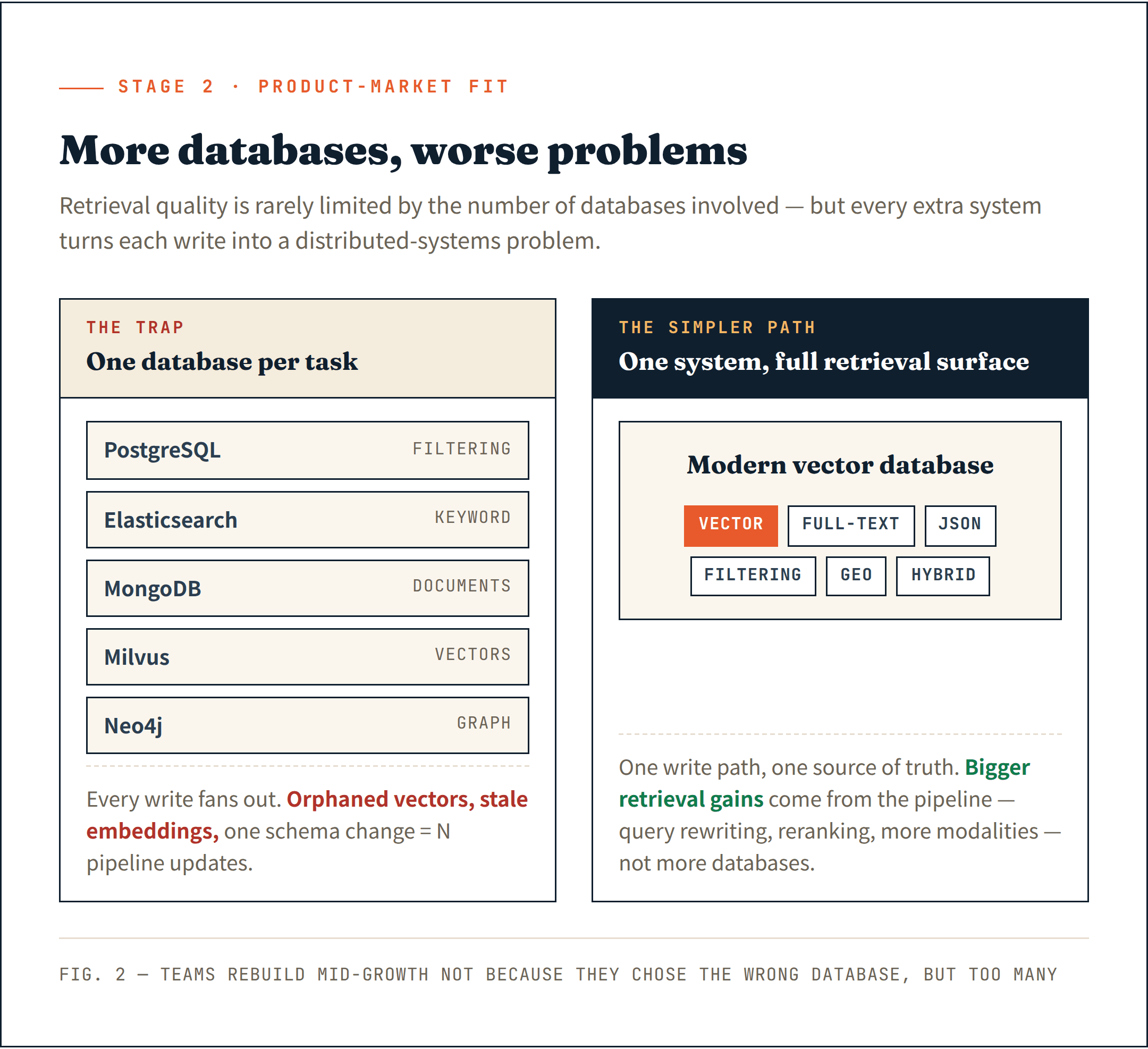
Certaines équipes commencent à assembler un système par tâche de récupération — PostgreSQL pour le filtrage, Elasticsearch pour la recherche par mots-clés, MongoDB pour les documents, Milvus pour les vecteurs, et Neo4j pour les relations de graphe. La pile de récupération croît plus vite que le produit lui-même.
Puis arrive le problème de synchronisation.
Les documents vivent dans un système. Les embeddings dans un autre. Les métadonnées dans un troisième. Chaque opération d’écriture devient un problème de systèmes distribués. Une suppression échouée laisse des vecteurs orphelins. Une insertion partielle crée des embeddings obsolètes. Un changement de schéma exige de mettre à jour plusieurs pipelines à la fois.
La leçon difficile : la qualité de récupération est rarement limitée par le nombre de bases de données impliquées.
Les gains les plus importants viennent du pipeline de récupération lui-même — réécriture dynamique des requêtes, recherche itérative, divulgation progressive, meilleur reranking. Côté données, ajouter un autre champ d’embedding ou une autre modalité améliore souvent davantage la qualité de récupération que l’ajout d’une autre base de données spécialisée.
Les bases de données vectorielles modernes se sont discrètement étendues bien au-delà des vecteurs. Recherche plein texte, filtrage JSON, recherche géospatiale et récupération hybride — la plupart des systèmes matures les prennent désormais en charge nativement. L’hypothèse d’une base de données spécialisée par tâche est de plus en plus dépassée.
Un système unique qui gère toute la surface de récupération est plus simple à exploiter et fournit une base plus propre pour ce qui vient ensuite.
J’ai vu trop d’équipes contraintes de reconstruire leur infra de données en pleine croissance — non pas parce qu’elles avaient choisi la mauvaise base de données, mais parce qu’elles en avaient choisi trop.
Ce dont vous avez réellement besoin à ce stade :
- Un service de base de données managé — laissez le fournisseur gérer la fiabilité pendant que vous vous concentrez sur le produit
- Un système unique avec un large support sémantique : vectoriel, texte intégral, JSON, filtrage, hybride — pas une base de données par tâche
- Suffisamment de marge pour atteindre l’ordre de grandeur suivant sans reconstruire
Étape 3 : Croissance à grande échelle — chaque charge de travail ne devrait pas partager le même calcul
C’est l’étape où la pression sur les coûts devient indéniable. La raison est simple : les données croissent toujours plus vite que votre chiffre d’affaires.
L’erreur la plus courante : supposer que la solution de base de données traditionnelle qui vous a mené jusqu’ici vous emmènera plus loin.
Contrairement à l’étape 2, il n’y a plus de marge facile pour reconstruire à ce stade. Une migration d’infrastructure à grande échelle sous pression de croissance est soit extrêmement coûteuse, soit extrêmement risquée, soit les deux.
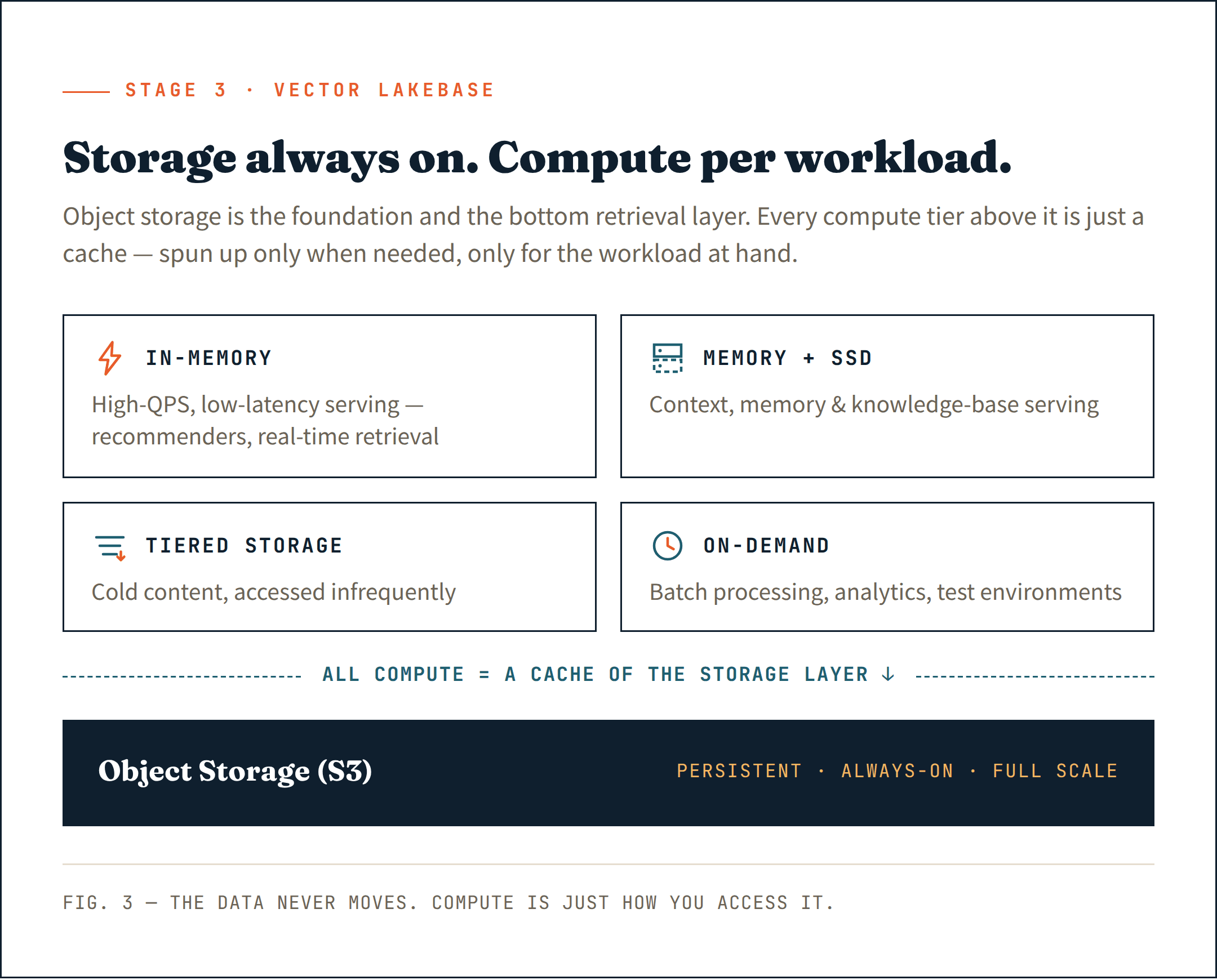
La bonne approche consiste à tout placer sur un stockage objet (comme S3) — non pas seulement comme magasin persistant, mais comme couche de base de votre architecture de récupération. C’est l’option la moins chère, la plus durable et la plus évolutive qui existe. Traitez-la comme la fondation, pas comme une considération secondaire.
Au-dessus de cette couche, introduisez du calcul uniquement là où il est réellement nécessaire. Des clusters longue durée pour le service sensible à la latence. Des ressources de calcul éphémères pour l’ingestion et l’indexation. Du calcul à la demande pour l’analytique et les tâches par lots. Chaque charge de travail reçoit le calcul dont elle a besoin — et rien de plus.
C’est l’essence d’un Vector Lakebase : un stockage toujours activé à pleine échelle, un calcul qui ne l’est pas — lancé uniquement lorsque c’est nécessaire, uniquement pour la charge de travail concernée.
Plus important encore, tout le calcul — qu’il soit longue durée ou à la demande — agit comme un cache de la couche de stockage objet. Les données vivent toujours dans le stockage. Le calcul n’est que la manière dont vous y accédez.
Associez chaque charge de travail au bon niveau de calcul :
- En mémoire pour les charges de travail à QPS élevé et faible latence — systèmes de recommandation IA, récupération en temps réel
- Mémoire + SSD pour le service de contexte, de mémoire et de base de connaissances
- Stockage hiérarchisé pour le contenu froid rarement consulté
- Calcul à la demande pour le traitement par lots, l’analytique interne et les environnements de test
Bien mise en œuvre, cette approche réduit les coûts d’infrastructure de 50 % ou plus par rapport à une conception unifiée — tout en offrant une qualité de service bien meilleure pour chaque charge de travail.
Les solutions serverless s’effondrent souvent à ce stade — non pas techniquement, mais économiquement. Une fois que vos données atteignent les téraoctets, les coûts d’insertion et de stockage commencent à dominer. La raison est structurelle : les architectures serverless intègrent les frais généraux de mutualisation, l’indexation et les coûts des données persistantes dans les majorations d’écriture et de stockage. Vous ne payez plus pour ce que vous utilisez. Vous payez pour l’abstraction.
Le premier principe de l’infra de données à ce stade est simple : votre fondation doit évoluer avec vos données, pas contre elles. Une architecture unique forcée de servir chaque charge de travail aussi bien finit par n’en servir aucune correctement — et le coût de ce compromis se compose avec chaque gigaoctet que vous ajoutez.
Ce dont vous avez réellement besoin à ce stade :
- Le stockage objet (S3) comme fondation et couche de récupération inférieure — persistant, toujours activé à pleine échelle, la couche depuis laquelle tout le calcul lit
- Un Vector Lakebase : des données qui ne bougent jamais, un calcul qui se lance par charge de travail et rien de plus
- Le bon niveau de calcul pour chaque type de charge de travail
Étape 4 : Échelle entreprise — la confiance devient une partie du produit
À ce stade, la plupart des équipes pensent que le plus difficile est derrière elles. Ce n’est pas le cas.
L’erreur courante : les équipes pensent encore que le problème est technique.
Elles ont optimisé l’infrastructure. Elles ont maîtrisé les coûts. Elles supposent que passer à l’échelle entreprise consiste à ajouter de la capacité et à cocher une case de sécurité.
Ce n’est pas le cas.
Les questions qui bloquent les contrats entreprise n’ont rien à voir avec la performance :
Comment nos données sont-elles isolées de celles des autres clients ?
Qui a accès à quoi, et pouvez-vous le prouver ?
Pouvez-vous nous servir dans notre région ?
Pouvons-nous déployer cela dans notre propre compte cloud ?
Mais les exigences propres à chaque contrat ne sont qu’une partie du problème. À la phase 3, l’hétérogénéité était technique — différentes charges de travail, différents niveaux de calcul. À ce stade, elle est structurelle : votre base de clients exige une infrastructure de données au niveau plateforme pour la gérer.
Vous avez des utilisateurs gratuits qui ont besoin d’un service partagé rentable. Vous avez des clients individuels payants qui s’attendent à une meilleure disponibilité. Vous avez des clients entreprise qui exigent une isolation complète des données, du calcul dédié et la capacité d’auditer absolument tout. Servir les trois depuis la même architecture signifie que vous dépensez trop pour votre offre gratuite, que vous servez insuffisamment vos clients entreprise, ou les deux.
La bonne réponse est une infrastructure par niveaux, adaptée à chaque segment de clients :
- Clusters partagés pour les utilisateurs gratuits et individuels — mutualisés, optimisés pour les coûts
- Clusters isolés par client entreprise — calcul dédié, stockage dédié, contrôles d’accès dédiés
- BYOC pour les clients qui exigent un déploiement dans leur propre compte cloud

Le point BYOC est là où la plupart des équipes commettent une erreur critique. SaaS et BYOC ressemblent à deux produits. S’ils divergent au niveau de l’architecture, vous maintenez deux bases de code, deux pipelines de déploiement et deux runbooks opérationnels — indéfiniment. Les équipes qui ont réussi ont traité BYOC comme un modèle de déploiement plutôt que comme un produit distinct. Même data plane, même interface de contrôle, cible de déploiement différente.
La fiabilité mondiale est l’autre élément que l’on reporte trop longtemps. À l’échelle entreprise, le multi-régions n’est pas une fonctionnalité premium — c’est une attente de base. Les clients entreprise répartis dans différentes zones géographiques ne toléreront pas un déploiement dans une seule région, et n’accepteront pas non plus vos engagements de SLA. Sans interface unifiée d’infrastructure de données entre clouds et régions, vous finissez par exploiter différentes couches de données dans différents environnements — la synchronisation des données en temps réel devient son propre problème de systèmes distribués, et la complexité opérationnelle se multiplie à chaque nouvelle région que vous ajoutez.
Les équipes avec lesquelles j’ai échangé et qui avaient atteint de véritables contrats entreprise ont décrit la même découverte douloureuse : rien de tout cela n’avait été conçu dès le départ. Cela avait été ajouté après coup, sous la pression d’un cycle de vente en cours. Une équipe a passé quatre mois à rétrofiter l’isolation au niveau des données dans une architecture qui n’avait pas été construite pour cela. Ils l’ont livrée. Mais ils savaient exactement pourquoi elle était fragile.
La préparation à l’entreprise n’est pas une checklist. C’est la conséquence de décisions architecturales prises bien plus tôt.
Ce dont vous avez réellement besoin à ce stade :
- Une interface unifiée d’infrastructure de données — cohérente entre clouds, cohérente entre régions
- Des clusters mondiaux conçus pour une haute fiabilité et un service multi-régions
- Un service par niveaux : clusters partagés pour les utilisateurs gratuits, clusters isolés par client entreprise
- SaaS et BYOC sur la même architecture — un seul data plane, différentes cibles de déploiement
- Des standards ouverts et de l’open source à la base — pas de verrouillage fournisseur à l’échelle entreprise
Ce que les équipes qui ont bien évolué ont en commun
Le schéma est constant.
Chaque phase introduit une classe de problèmes complètement différente. La phase 1 est un problème de vitesse. La phase 2 est un problème de complexité. La phase 3 est un problème de coût et d’architecture. La phase 4 est un problème de confiance et de plateforme.

Les équipes qui ont traversé chaque phase sans reconstruction douloureuse l’ont compris tôt. Elles ont cessé de se demander « de quelle base de données ai-je besoin maintenant ? » et ont commencé à se demander « qu’exigera la prochaine phase — et ma décision actuelle ferme-t-elle cette porte ? »
À l’étape 1, une base de données vectorielle est exactement le bon outil. Je le dis sans réserve.
À partir de l’étape 3, ce qui devient nécessaire est d’une autre nature — un Vector Lakebase. Un stockage toujours activé à pleine échelle. Un calcul adapté à chaque charge de travail. Une plateforme capable de servir un utilisateur gratuit, un client payant et un compte d’entreprise à partir de la même architecture, sans duplication.
Les équipes qui y sont parvenues plus rapidement n’étaient pas plus intelligentes ni mieux financées.
Elles ont simplement compris plus tôt que la décision d’infrastructure n’était pas un choix temporaire.
C’était la fondation sur laquelle tout le reste serait construit.
Zilliz Vector Lakebase est disponible en aperçu public
Nous avons lancé l’aperçu public de Zilliz Vector Lakebase — une évolution majeure de Zilliz Cloud, passant d’une base de données vectorielle managée à une plateforme de données sémantiques unifiée qui associe la base de données vectorielle de production à une fondation de données partagée et lake-native.
Fonctionnalités principales de Zilliz Vector Lakebase :
- Service par niveaux optimisé pour différents compromis performance-coût en temps réel
- Recherche à la demande pour les charges de travail à grande échelle ou exploratoires, sans calcul toujours actif
- Recherche dans les data lakes externes — indexez et recherchez directement dans vos données de lake existantes
- Recherche sur tout le spectre des données vectorielles, texte, JSON et géospatiales avec récupération hybride et reranking
- Stockage unifié lake-native construit sur Vortex, un format ouvert offrant des lectures aléatoires plus rapides et moins coûteuses que Lance ou Parquet
Si votre stack actuelle sépare le serving et la découverte en systèmes distincts, Vector Lakebase pourrait valoir le détour. Essayez-le sur Zilliz Cloud — les nouvelles inscriptions avec une adresse e-mail professionnelle bénéficient de 100 $ de crédits gratuits — ou contactez-nous pour discuter de votre cas d’usage.
En savoir plus sur les Vector Lakebases
- De la base de données vectorielle au Vector Lakebase
- Nous avons passé 8 ans à rendre les bases de données vectorielles plus rapides. Puis nous avons arrêté.
- Pourquoi nous avons construit Vector Lakebase : repenser l’architecture des données non structurées pour l’IA
- Vector Lakebase : mettez fin au silo de données de l’IA
- Zilliz Cloud On-Demand Compute : ne payez que ce que vous utilisez
- La recherche vectorielle de Notion est excellente. Leur prochain problème est plus difficile.

Continuer à lire

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.