




Comment Zilliz s’est retrouvé au centre du récit de NVIDIA sur les données non structurées à la GTC 2026
Lors du NVIDIA GTC cette année, au milieu de l’avalanche habituelle d’annonces sur les puces, les systèmes et l’infrastructure, Jensen Huang a présenté une diapositive qui comptait pour une autre raison.
Elle ne portait pas sur le prochain GPU. Elle ne portait pas sur la taille des modèles. Elle ne portait même pas vraiment sur l’inférence.
Elle portait sur les données.
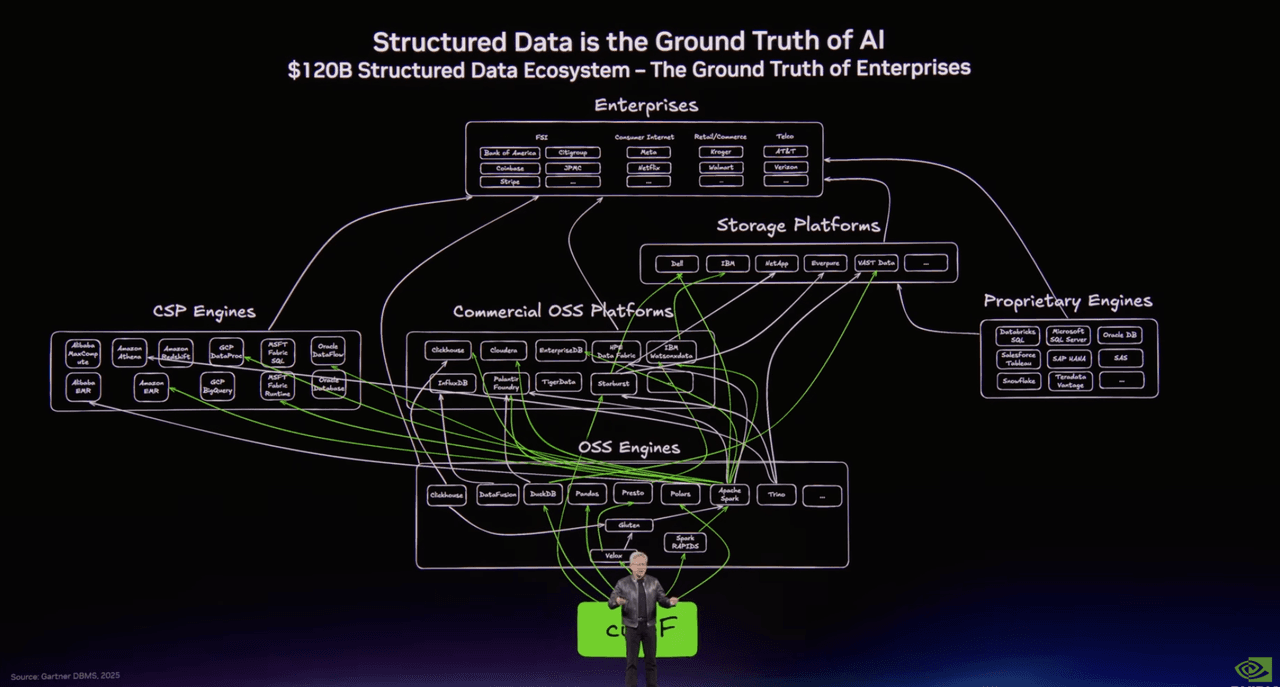
Une diapositive cartographiait le monde des données structurées : Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, la machinerie familière qui alimente l’analytique et l’ingénierie des données depuis des décennies.
Une autre cartographiait la pile émergente des données non structurées. Et là, au milieu de cette deuxième image, figuraient Milvus en open source et Zilliz Cloud dans la couche de base de données d’entreprise.

Le titre de la diapositive disait tout : Les données non structurées sont le contexte de l’IA.
Cette phrase est facile à approuver. Bien sûr, l’IA a besoin de contexte. Bien sûr, la plupart des données d’entreprise sont non structurées. Bien sûr, le texte, les images, la vidéo, l’audio, les journaux, les PDF et tout le reste comptent désormais plus que jamais. Mais une fois le slogan dépassé, une question plus difficile apparaît : si les données non structurées deviennent le véritable substrat des systèmes d’IA, à quoi ressemble réellement l’infrastructure de ce monde ?
C’est l’histoire la plus intéressante. Et c’est la raison pour laquelle Milvus est passé d’une base de données vectorielle spécialisée à une position bien plus stratégique dans la pile IA.
Pourquoi Zilliz (Milvus) apparaît constamment
Ce n’était pas la première fois que Zilliz apparaissait au GTC, et ce ne sera probablement pas la dernière.
Bien avant que les bases de données vectorielles ne deviennent une brique par défaut des systèmes d’IA modernes, Milvus a été conçu autour de l’idée que la recherche de similarité devrait fonctionner à une échelle très différente de celle des bases de données traditionnelles. L’accélération GPU n’était pas une réflexion après coup. Elle faisait partie de la logique de conception dès le départ.
Cela a compté lorsque l’IA a cessé d’être une histoire de recherche pour devenir une histoire d’infrastructure.
Au GTC 2023, Jensen Huang soulignait déjà l’intégration plus profonde entre les bibliothèques d’accélération de NVIDIA et des systèmes comme FAISS, Redis et Milvus. Un an plus tard, au GTC 2024, cette relation est devenue plus concrète avec Milvus 2.4, qui a apporté une accélération GPU complète à l’indexation et à la recherche vectorielles en combinant les GPU NVIDIA avec CAGRA de RAPIDS cuVS. Le résultat n’était pas une accélération cosmétique. Dans certains contextes de benchmark, les performances de recherche se sont améliorées jusqu’à 50x par rapport à HNSW.
Au moment où Milvus 2.6 est arrivé, la conversation avait encore évolué. La question n’était plus de savoir si l’accélération GPU comptait. Il s’agissait de savoir comment l’utiliser de manière rentable. Milvus 2.6 a introduit des modèles de déploiement plus flexibles pour CAGRA, notamment des architectures hybrides GPU-CPU qui utilisent le GPU pour la construction du graphe et le CPU pour la récupération. C’est important, car la plupart des entreprises ne veulent pas le système le plus rapide possible à n’importe quel prix. Elles veulent un système qui reste suffisamment rapide tout en demeurant économiquement raisonnable.
Ce détail mérite qu’on s’y arrête, car il dit quelque chose de plus large sur les raisons pour lesquelles Milvus est devenu important. Ce n’est pas seulement une histoire de performances de recherche vectorielle. C’est une histoire de ce qui se passe lorsque la récupération vectorielle cesse d’être une fonctionnalité expérimentale et devient une partie de l’infrastructure de production.
Ce qu’il faut pour faire fonctionner la recherche vectorielle en production
La vitesse seule cesse d’être le sujet.
Mais une fois que la récupération vectorielle sort des démonstrations pour entrer dans de vrais systèmes, la vitesse seule cesse d’être le sujet.
La question la plus difficile est de savoir ce qu’il faut pour rendre la récupération praticable à l’échelle de l’entreprise, sans transformer la pile environnante en un fouillis de pipelines fragiles, de forte pression mémoire et de coûts d’infrastructure en hausse.
Une partie de ce défi commence en amont. Dans l’ancien modèle, transformer un PDF, une image ou un document en quelque chose de recherchable signifiait généralement assembler une couche de parsing séparée, une logique de découpage, des services d’embedding et des écritures en base de données. Le système de récupération ne commençait à fonctionner qu’après qu’une longue chaîne de prétraitement avait déjà terminé son travail. Milvus 2.6 a commencé à faire disparaître cette frontière avec une approche Data-in, Data-out, permettant d’écrire du contenu brut directement dans le système et de l’embedder à l’intérieur de la base de données elle-même.
Une autre partie se situe à l’intérieur de la couche de récupération. Différentes charges de travail exigent différents compromis, d’où la prise en charge de plusieurs types d’index plutôt que l’imposition d’une stratégie de récupération unique à chaque cas d’usage. La compression entre également dans l’équation. Des fonctionnalités telles qu’Int8 et RaBitQ ne sont pas des ajouts spectaculaires, mais elles répondent à un objectif plus important : réduire la pression mémoire et les coûts sans sacrifier la qualité de la récupération.
Et une autre partie est tout simplement opérationnelle. Milvus a introduit une architecture de journalisation write-ahead repensée qui a supprimé la nécessité de Kafka et Pulsar dans la pile, réduisant à la fois la complexité et la surcharge. Ce type d’ingénierie fait rarement les gros titres, mais c’est exactement celui qui détermine si une infrastructure reste intéressante en théorie ou devient utilisable en pratique.
Le stockage se révèle être une autre ligne de faille.
À mesure que les systèmes d’IA se développent, le coût de prétendre que toutes les données doivent être traitées de la même manière, tout le temps, augmente lui aussi. Sur une grande plateforme multi-tenant, seule une petite partie des données peut réellement être active un jour donné. La plupart restent froides. Mais les architectures traditionnelles à chargement complet continuent de traiter toutes les données comme si elles méritaient la même résidence locale, la même posture de performance et la même empreinte de coût.
À petite échelle, cela paraît inefficace. À l’échelle de l’entreprise, cela devient difficile à justifier.
Milvus 2.6 a répondu à cela avec le stockage hiérarchisé. Les données chaudes restent locales, là où la latence compte. Les données froides sont chargées à la demande depuis un stockage objet moins coûteux. Et la frontière entre les deux évolue dynamiquement selon l’utilisation réelle du système. Cela ressemble à une optimisation système modeste. En pratique, cela change l’économie de la récupération. Lorsque les bonnes données résident dans le bon niveau, les coûts de stockage peuvent chuter de plus de 70 %.
Rien de tout cela n’est particulièrement glamour. Mais c’est généralement ainsi que l’infrastructure mûrit : non pas grâce à une percée spectaculaire unique, mais par une série de décisions de conception qui rendent le système plus rapide, moins cher et plus facile à vivre.
Et toutes ces fonctionnalités sont disponibles dans Zilliz Cloud, le service entièrement géré de Milvus.
Le vrai problème des données non structurées
Le changement le plus important, toutefois, ne concerne pas vraiment Milvus seul. Il concerne le type de données dont les systèmes d’IA dépendent désormais.
Les données structurées ont évolué de manière longue et ordonnée. Lignes, colonnes, schémas, index, entrepôts, moteurs de requête. Les outils ont mûri pendant des décennies parce que les données elles-mêmes correspondaient aux hypothèses sur lesquelles ces systèmes étaient construits. Vous saviez à quoi ressemblait un enregistrement. Vous saviez quels champs interroger. Vous saviez comment les indexer.
Les données non structurées cassent ce modèle.
Un contrat n’est pas une ligne. Une image médicale, une transcription de support, un dépôt de code ou un flux de surveillance ne le sont pas non plus. Ces objets peuvent être stockés, mais les stocker est la partie facile. La partie difficile consiste à les rendre consultables d’une manière qui comprend le sens plutôt que des correspondances exactes de champs.
C’est pourquoi les embeddings ont tout changé. Dès lors que du texte, des images, de l’audio et d’autres formes de contenu pouvaient être projetés dans un espace vectoriel de grande dimension, la récupération n’avait plus à dépendre d’une correspondance symbolique exacte. Les systèmes pouvaient récupérer par similarité, intention et contexte.
Ce fut la percée.
Ce fut aussi le début d’un nouveau problème d’infrastructure.
Une fois que les données non structurées deviennent interrogeables, les entreprises sont immédiatement confrontées à l’économie du passage à l’échelle. Des millions de documents deviennent des centaines de millions d’embeddings. Une mise à niveau de modèle signifie ré-encoder tout le corpus historique en embeddings. La qualité de la récupération dépend de la qualité de l’index. La latence compte en production. Le coût de stockage aussi. Tout comme la charge opérationnelle nécessaire pour maintenir tout cela synchronisé.
En d’autres termes, la récupération sémantique a résolu le problème d’accès, mais a révélé le problème des systèmes.
C’est dans ce contexte que Milvus prend tout son sens.
Pourquoi une base de données vectorielle ne suffisait pas
Pour la première vague d’entreprises AI-native, la réponse était simple : utiliser une base de données vectorielle comme couche de récupération, la connecter à un modèle, puis construire l’application à partir de là. Ce modèle a fonctionné, et il fonctionne encore, surtout lorsque la recherche sémantique est au cœur du produit.
Mais les grandes entreprises ont tendance à se heurter à un mur différent.
La question n’est pas de savoir si elles peuvent faire fonctionner la recherche vectorielle. La question est ce qui se passe ensuite.
Les fichiers bruts résident dans du stockage objet ou des data lakes. Les embeddings résident dans une base de données vectorielle. Les métadonnées résident dans un système relationnel. Le traitement hors ligne se fait ailleurs. Les journaux de recherche s’accumulent dans un autre pipeline. Puis le modèle d’embedding change, ou la logique de classement change, ou la base de connaissances doit être organisée, ou quelqu’un veut comprendre pourquoi un système de récupération échoue sans cesse sur des cas limites. Soudain, le système n’est plus un seul système. C’est un assemblage hétéroclite.
Cet assemblage crée trois problèmes familiers.
- Le premier est celui des silos de données. Les données nécessaires pour exécuter une fonctionnalité d’IA sont réparties entre plusieurs systèmes, chacun avec son propre format, son propre cycle de vie et son propre modèle opérationnel.
- Le deuxième est le coût d’itération. Lorsqu’un modèle d’embedding change, la réécriture n’est pas incrémentale par défaut. Elle peut devenir un effort de réindexation et de migration s’étalant sur des mois.
- Le troisième est la boucle rompue entre le service en ligne et l’amélioration hors ligne. Le système sert des requêtes en production, mais les signaux qui pourraient l’améliorer, les résultats de déduplication, les étiquettes de clustering, les scores de qualité et les analyses d’échecs, résident souvent dans des environnements séparés et ne reviennent jamais proprement dans la couche de récupération.
C’est à ce moment-là que l’achat d’une base de données vectorielle cesse de ressembler à la réponse et commence à ressembler au début d’une question architecturale plus vaste.
Si le véritable problème est l’amélioration continue à grande échelle, alors l’architecture doit changer.
De la base de données vectorielle à l’AI Lakebase
Avant le boom de l’IA, Databricks a contribué à populariser le modèle Lakehouse en supprimant la séparation maladroite entre les data lakes et les data warehouses. Au lieu de maintenir des systèmes séparés pour le stockage, l’analyse et le traitement à grande échelle, les entreprises pouvaient travailler à partir d’une fondation plus unifiée.
L’ère de l’IA impose une remise en question similaire, mais autour des données non structurées.
Si vous examinez de près les schémas d’infrastructure que Jensen Huang utilise, le centre de gravité est en train de se déplacer. À l’ère des données structurées, des frameworks comme Spark se trouvaient au cœur du pipeline. À l’ère des données non structurées, une infrastructure vectorielle comme Milvus commence à remplir ce rôle. Non pas parce que la recherche vectorielle est la seule chose qui compte, mais parce qu’elle se situe de plus en plus à la jonction entre les données brutes, les embeddings, les index et la récupération applicative.
Cela ouvre une possibilité plus large : et si la recherche vectorielle n’était pas traitée comme une couche de service distincte ajoutée sur le côté de la pile ? Et si elle était intégrée directement au data lake de l’entreprise et aux workflows de données environnants ?
Architecture AI Lakebase
C’est l’idée derrière AI Lakebase.
L’objectif d’AI Lakebase n’est pas d’ajouter une énième catégorie de produits à un marché déjà saturé. L’objectif est de remplacer un modèle fragmenté par un modèle plus cohérent.
- En bas se trouve une couche de stockage unifiée. Une partie de ces données réside dans des collections natives Zilliz optimisées pour une recherche vectorielle haute performance. Une partie reste dans les formats ouverts que l’entreprise utilise déjà, Iceberg, Lance, Paimon, ainsi que des fichiers bruts dans le stockage objet. L’important est que les données n’aient pas besoin d’être copiées dans cinq systèmes différents simplement pour devenir utilisables.
- Au-dessus de cela se trouve la couche de service de production, conçue pour la recherche en temps réel. Dans Zilliz Cloud, cela signifie des clusters de service propulsés par Cardinal, optimisés pour une latence de l’ordre de la milliseconde, avec différents modes pour la performance, la capacité et le placement des données hot-cold par niveaux. En pratique, cela signifie que les données fréquemment consultées restent locales tandis que les données froides sont chargées à la demande depuis un stockage moins coûteux. Le résultat n’est pas seulement une meilleure conception système. C’est aussi un contrôle des coûts.
- Vient ensuite la couche de calcul élastique : des clusters à la demande pour l’ETL, la déduplication, le clustering, l’analyse de la qualité des données, le re-embedding, l’évaluation et l’investigation interactive. Ce ne sont pas des systèmes annexes ajoutés après coup. Ils font partie de la même fondation.
Les trois couches partagent les mêmes données plutôt que de maintenir plusieurs copies déconnectées.
Cela ressemble à une histoire de rationalisation architecturale, et c’en est une. Mais c’est plus que cela.
Mais le point le plus important est ce que cette architecture rend possible.
AI Lakebase est plus qu’une rationalisation architecturale
La plupart des systèmes d’IA actuels peuvent servir. Bien moins nombreux sont ceux qui peuvent s’améliorer systématiquement.
Ce n’est généralement pas parce que le modèle est incorrect. C’est parce que l’infrastructure autour de lui rend le feedback coûteux.
Un système de production génère constamment des signaux. Chaque requête vous apprend quelque chose. Chaque échec de recherche vous apprend quelque chose. Chaque réponse de faible qualité, chaque résultat répété, chaque interaction sans issue, chaque cluster de documents similaires, chaque fragment bruité dans le corpus, tout cela constitue des informations qui pourraient être utilisées pour améliorer le système.
Mais dans la plupart des piles, ces signaux sont dispersés entre les logs de service, les pipelines hors ligne, les notebooks, les tableaux de bord et les scripts ponctuels. Le système fonctionne, mais il n’apprend pas réellement de sa propre expérience.
Le cadre proposé par AI Lakebase pour résoudre cela est Continuous Serving/Continuous Discovery (AI CS/CD).
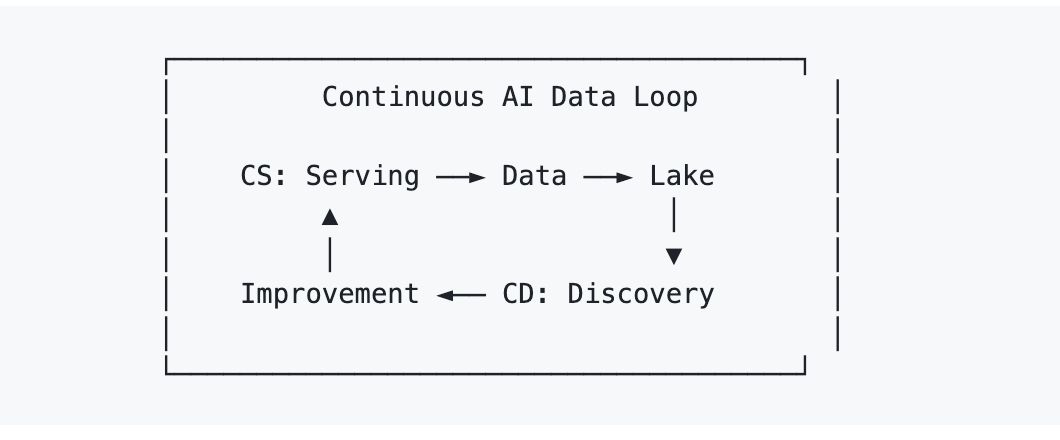
- Continuous Serving est la partie évidente : le système en direct gère la recherche et la génération en production.
- Continuous Discovery est la partie moins évidente : le système analyse en continu ce qu’il a accumulé, les lacunes de couverture, les modes de défaillance, la structure des clusters, les problèmes de qualité des données, et réinjecte les améliorations qui en résultent dans le même environnement opérationnel.
C’est important parce qu’une fois que le service et la découverte partagent la même fondation de données, les améliorations cessent de ressembler à des migrations et commencent à ressembler à des itérations. Les résultats de déduplication peuvent être réinjectés dans la recherche en direct. Les scores de qualité peuvent influencer le classement en production. Les étiquettes de clusters peuvent devenir des signaux de recherche. Le re-embedding peut se faire de manière incrémentale via le calcul élastique plutôt que comme un événement massif réalisé en une seule fois.
L’architecture commence à se comporter moins comme une base de données statique et davantage comme une boucle d’amélioration vivante.
C’est un changement bien plus significatif que « base de données vectorielle, mais plus rapide ».
Développer rapidement et itérer rapidement avec AI Lakebase
De nombreuses entreprises d’infrastructure peuvent revendiquer l’échelle. Beaucoup peuvent revendiquer la vitesse. Moins nombreuses sont celles qui peuvent plausiblement revendiquer à la fois l’échelle et l’itération continue dans le même système.
Zilliz soutient que la prochaine phase de l’infrastructure d’IA d’entreprise nécessite les deux.
- Scale Fast signifie une infrastructure multi-région et multi-cloud capable de prendre en charge des charges de travail de production à très grande échelle, et pas seulement des exécutions de benchmarks ou des environnements de démonstration.
- Iterate Fast signifie que le système est conçu de sorte que la découverte hors ligne et le service en ligne fassent partie de la même boucle opérationnelle. L’amélioration est intégrée, et non ajoutée après coup.
Cette distinction est importante, car l’IA en production échoue de deux manières opposées. Certains systèmes passent à l’échelle mais stagnent. Ils deviennent volumineux, coûteux et de plus en plus difficiles à améliorer. D’autres itèrent rapidement dans de petits environnements, mais ne deviennent jamais des systèmes de production durables. Le véritable objectif n’est ni l’un ni l’autre. C’est un système capable de croître et d’apprendre simultanément.
C’est la promesse qui sous-tend le passage de la base de données vectorielle à l’AI Lakebase.
La base de données vectorielle ne disparaît pas dans cette transition. Elle compte toujours. Elle reste le moteur de service pour la récupération en temps réel. Mais elle cesse d’être le point d’aboutissement de l’architecture. Elle devient une couche dans un système plus large, tout comme les bases de données relationnelles existent toujours dans un monde Lakehouse sans définir à elles seules l’ensemble de l’architecture.
Et c’est peut-être la manière la plus utile de lire la phrase de Jensen Huang à la GTC.
Si les données non structurées sont le contexte de l’IA, alors le plafond des applications d’IA sera déterminé non seulement par les modèles, mais aussi par le degré de maturité atteint par l’infrastructure dédiée aux données non structurées.
Cette infrastructure est encore inachevée. Le marché en est encore à ses débuts. Mais ses contours commencent à se dessiner.
Et, de plus en plus, Milvus se trouve en plein milieu.
Restez à l’écoute !
AI Lakebase sera la mise à niveau architecturale derrière Milvus 3.0 et une évolution majeure de Zilliz Cloud. Si vous souhaitez avoir un aperçu précoce de la direction que cela prend, contactez-nous pour un accès anticipé.
Continuer à lire

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.