




Pourquoi nous avons créé Vector Lakebase : repenser l’architecture des données non structurées pour l’IA
Récemment, nous avons lancé Zilliz Vector Lakebase, la prochaine évolution de Zilliz Cloud, passant d’un pur système de base de données vectorielle à une fondation de données unifiée, native du lake, pour les charges de travail d’IA. L’annonce a suscité beaucoup d’intérêt. Elle a aussi fait émerger presque immédiatement des questions sur la direction que prenait Zilliz.
Zilliz s’éloignait-il des bases de données vectorielles ? Ou, pour le dire plus directement : les bases de données vectorielles sont-elles déjà en train de devenir obsolètes ?
Je comprends pourquoi ces questions sont apparues. Depuis des années, Zilliz est connu pour construire des systèmes de bases de données vectorielles prêts pour la production (Milvus open source et Zilliz Cloud entièrement managé). Ainsi, lorsque nous avons commencé à parler d’une évolution vers une fondation de données native du lake pour l’IA, certaines personnes se sont naturellement demandé si cela signifiait un changement de direction.
La réponse courte est NON. Absolument PAS. Au contraire, Vector Lakebase est notre réponse à ce qui se passe après le succès des bases de données vectorielles.
Au cours des dernières années, les bases de données vectorielles sont devenues l’une des couches d’infrastructure fondamentales de la stack IA. L’adoption a progressé plus vite que nous n’aurions pu l’imaginer lorsque nous avons lancé Milvus il y a près de dix ans. La catégorie est bien réelle, et le besoin de recherche sémantique ne fait que devenir plus important.
Mais une autre chose nous est également apparue clairement : la recherche vectorielle n’est plus l’ensemble du problème.
À mesure que les systèmes d’IA passent d’assistants statiques à des agents fonctionnant en continu, les entreprises demandent quelque chose de plus large à leur infrastructure de données non structurées. Elles ne veulent pas seulement un système capable de récupérer des informations. Elles veulent un système capable d’améliorer les données, de les réorganiser, de les analyser, de les affiner et de réinjecter ces améliorations en production. Cela change l’architecture.
Cette évolution me rappelle un cycle antérieur de l’histoire de l’infrastructure : l’évolution des bases de données à l’ère de l’internet mobile. Les détails sont différents, mais le schéma est familier. Un nouveau type d’application crée un nouveau type de pression sur les données. La première génération d’infrastructure résout le problème immédiat de service. Puis, à mesure que les données augmentent, l’architecture doit s’étendre.
Je pense que les bases de données vectorielles entrent maintenant dans cette prochaine étape.
L’internet mobile a déjà traversé ce cycle une fois
Vers 2010, alors que les applications mobiles explosaient, MongoDB est devenu l’un des produits d’infrastructure emblématiques de cette période.
La raison était simple. Les applications mobiles généraient d’énormes volumes de données semi-structurées : événements utilisateurs, activité sociale, télémétrie des appareils, signaux comportementaux, journaux produits. Rien de tout cela ne s’intégrait proprement dans les modèles de bases de données relationnelles que la plupart des équipes utilisaient à l’époque. Les équipes produit livraient rapidement, les schémas changeaient constamment, et le premier problème consistait simplement à accepter les données sans ralentir l’application. MongoDB a très bien résolu ce problème immédiat : ingérer les données d’abord. La structuration et l’analyse pouvaient venir plus tard.

Plusieurs années plus tard, l’industrie a commencé à poser une question différente. Une fois toutes ces données existantes, comment les entreprises pouvaient-elles réellement les utiliser ? Ce changement a contribué à l’essor des entrepôts de données modernes tels que Snowflake et Redshift. L’accent est passé du stockage opérationnel à l’insight analytique. Les entreprises voulaient des rapports BI, des cohortes d’utilisateurs, de l’attribution, des prévisions et des analyses de croissance. Les données ont cessé d’être uniquement un sous-produit opérationnel et sont devenues un actif métier.
Puis un autre goulot d’étranglement est apparu.
La séparation entre les systèmes transactionnels et les systèmes analytiques est devenue de plus en plus douloureuse. Les pipelines de données entre les environnements OLTP et OLAP étaient fragiles, coûteux et épuisants sur le plan opérationnel. Les mêmes jeux de données étaient copiés à plusieurs reprises entre les systèmes, souvent avec des retards de synchronisation et de subtiles incohérences.
C’est l’environnement qui a donné naissance à l’architecture Lakehouse. Databricks, Iceberg, Hudi et les systèmes associés ont tous convergé autour de la même idée de base : une seule copie logique des données devrait prendre en charge plusieurs modèles de calcul sans nécessiter des déplacements interminables entre les systèmes.
Avec le recul, cette progression semble presque inévitable. Mais à l’époque, rien de tout cela n’était évident. L’essor de MongoDB ne prédisait pas Snowflake. Snowflake ne prédisait pas le Lakehouse. Chaque transition est apparue parce que la génération précédente d’infrastructure avait réussi à grande échelle, puis avait révélé une nouvelle catégorie de contraintes.
Ce schéma est important parce que l’infrastructure d’IA donne de plus en plus l’impression de suivre une trajectoire similaire.
La recherche a résolu le premier problème, pas le dernier
Lorsque les grands modèles de langage ont été adoptés par le grand public en 2023, les bases de données vectorielles sont devenues l’une des premières catégories d’infrastructure à émerger fortement. La raison était pratique. Les systèmes RAG avaient besoin d’un moyen natif de stocker des embeddings et d’effectuer une recherche sémantique. La plupart des bases de données traditionnelles n’étaient pas conçues pour la recherche vectorielle en haute dimension, les index ANN, la recherche hybride et le filtrage à faible latence à grande échelle.
À bien des égards, les bases de données vectorielles ont résolu le même type de problème que MongoDB avait résolu auparavant. Un nouveau modèle d’application a créé une nouvelle abstraction de données, et les développeurs avaient besoin d’une infrastructure capable de la prendre en charge. Cette fois, l’abstraction était la représentation sémantique : des embeddings générés à partir de données non structurées par des modèles neuronaux.
Cette première phase d’adoption s’est déroulée très rapidement. Mais seulement quelques années plus tard, les questions que nous entendons de la part des clients sont devenues beaucoup plus complexes. Ils ne demandent plus seulement comment récupérer efficacement des vecteurs. Ils demandent :
- Comment dédupliquer et affiner en continu les données d’entraînement ?
- Comment analyser des milliards d’embeddings pour détecter des problèmes de clustering et de qualité ?
- Comment identifier la dérive, les biais ou les redondances dans des jeux de données multimodaux ?
- Comment tracer et optimiser les historiques d’exécution des agents ?
- Comment retraiter et améliorer les données à mesure que les modèles évoluent ?
- Comment rechercher dans des données froides sans maintenir tous les calculs actifs en permanence ?
- Comment utiliser des données qui résident déjà dans Iceberg, Lance, Parquet et le stockage objet pour plusieurs charges de travail d’IA ?
Ce ne sont plus des problèmes purement liés à la recherche. Ils nécessitent un traitement hors ligne à grande échelle, des workflows de découverte itératifs, de la gouvernance des données, de l’exploration analytique et des boucles de rétroaction continues entre les systèmes en ligne et le calcul hors ligne. De plus en plus, nous avons remarqué quelque chose d’important chez les équipes d’IA avancées : le goulot d’étranglement n’était plus seulement la capacité des modèles. C’était la vitesse d’itération.
Une expérience l’a rendu douloureusement évident. Nous avons vu des équipes essayer de retraiter de grands jeux de données vectorielles : reclusteriser des embeddings, supprimer les doublons, régénérer des index, ré-embedder des corpus entiers. Dans certains cas, le simple fait de déplacer un milliard de vecteurs d’un système à un autre pouvait prendre des jours. Pas des heures. Des jours.
Pendant ce temps, les cycles d’itération au sein des équipes d’IA de pointe évoluent dans la direction opposée. Les chercheurs veulent expérimenter en continu. Les data engineers subissent une pression pour nettoyer, évaluer et rafraîchir les jeux de données plus rapidement. Les modèles s’améliorent. Les modèles d’embedding changent. Les agents créent de nouvelles traces chaque jour. Mais la pile d’infrastructure sous-jacente n’a pas été conçue pour des boucles d’affinement continu sur des données non structurées.
C’est à ce moment-là que nous avons commencé à penser que l’industrie formulait le problème de manière trop étroite.
L’infrastructure de données non structurées n’est pas simplement une couche de recherche. Elle devient un système fonctionnant en continu.
Des systèmes de recherche aux systèmes continus : CS/CD
En interne, nous avons commencé à décrire cette architecture comme une boucle continue entre le service et la découverte. Avec le temps, nous avons commencé à l’appeler CS/CD : Continuous Serving and Continuous Discovery.
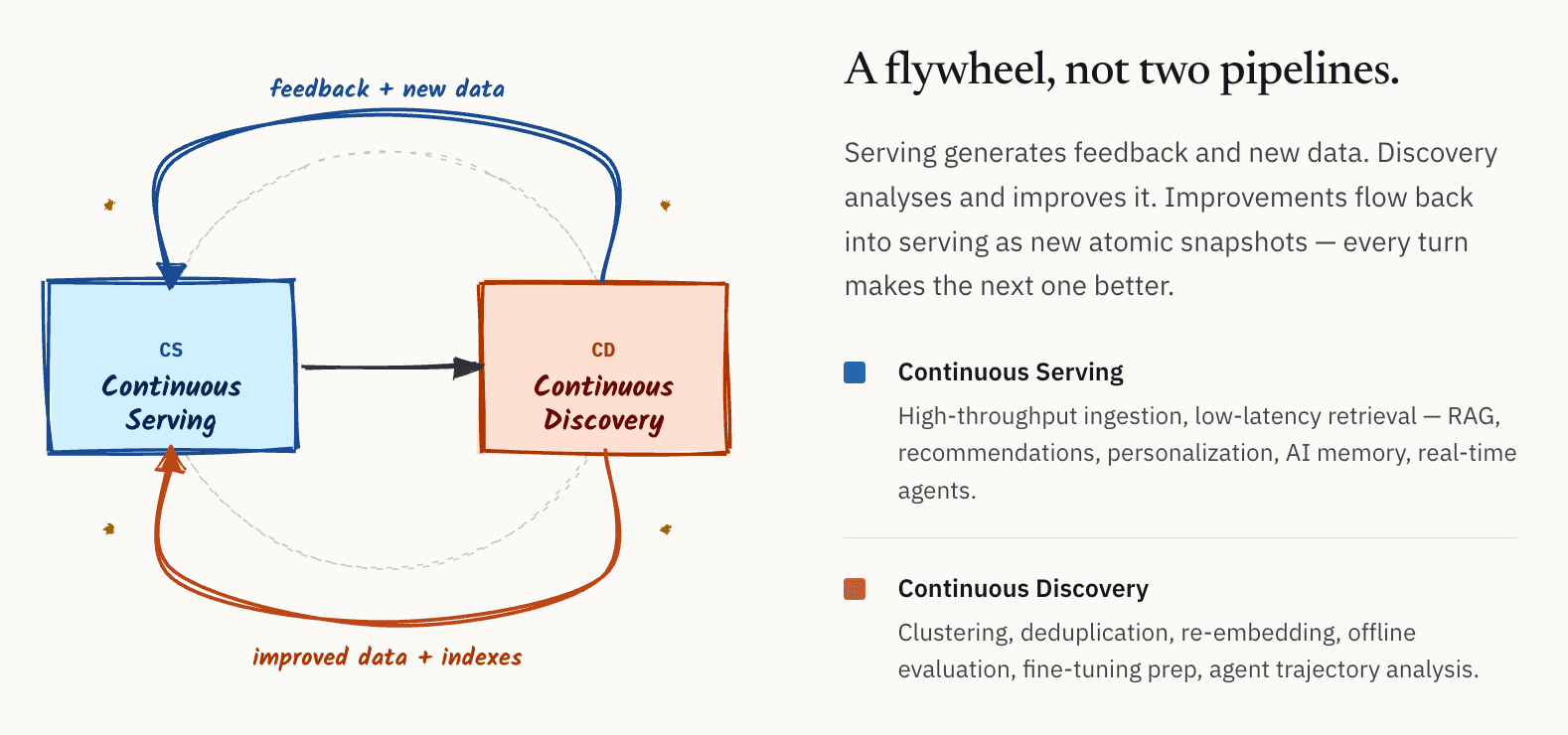
L’idée est conceptuellement simple.
- D’un côté, il y a la couche de service : ingestion à haut débit, récupération à faible latence pour les systèmes RAG en ligne, les systèmes de recommandation, la personnalisation, la mémoire IA et les agents en temps réel.
- De l’autre côté, il y a la couche de découverte : clustering, déduplication, ré-embedding, évaluation hors ligne, analyse de la qualité, préparation au fine-tuning de modèles et analyse des trajectoires d’agents.
Le point important est que ce ne sont pas des workflows indépendants. Ils forment un volant d’inertie. Les systèmes de service génèrent en continu du feedback et de nouvelles données. Les systèmes de découverte analysent et améliorent ces données. Les améliorations qui en résultent, notamment de meilleurs embeddings, des jeux de données plus propres, des index améliorés et des métadonnées affinées, retournent ensuite dans la couche de service.
Chaque itération devrait améliorer la suivante. Du moins en théorie.
En pratique, la plupart des organisations ne peuvent toujours pas exploiter efficacement cette boucle, car l’infrastructure sous-jacente reste fragmentée.
Aujourd’hui, si une équipe veut effectuer un traitement hors ligne à grande échelle sur des données vectorielles de production, le workflow typique reste péniblement manuel. Les données doivent d’abord être exportées de la base de données vectorielle vers un lac de données ou un environnement batch. Les index ne peuvent généralement pas être réutilisés. Les pipelines de synchronisation deviennent fragiles. Les mises à jour incrémentales sont difficiles. Les résultats traités doivent finalement être réimportés dans le système de service, souvent sans garantie de cohérence atomique entre les nouvelles données et les nouveaux index.
Il en résulte un workflow lent, fragile et coûteux. Et parce qu’il est si coûteux à maintenir, de nombreuses organisations évitent tout simplement de pratiquer la découverte continue. Les données restent là, récupérables mais largement inexplorées.
Cela nous a de plus en plus rappelé l’écart historique entre les systèmes OLTP et OLAP, sauf que la fragmentation se situe désormais entre la récupération sémantique en ligne et le traitement hors ligne de données non structurées.
Pourquoi les architectures existantes finissent par atteindre leurs limites
Une chose dont nous sommes devenus de plus en plus convaincus est qu’aucun des deux côtés de la pile d’infrastructure actuelle n’a tort.
Les bases de données vectorielles et les systèmes Lakehouse résolvent tous deux des problèmes importants. Le problème est que chaque architecture a été optimisée autour d’une seule moitié de la charge de travail émergente.
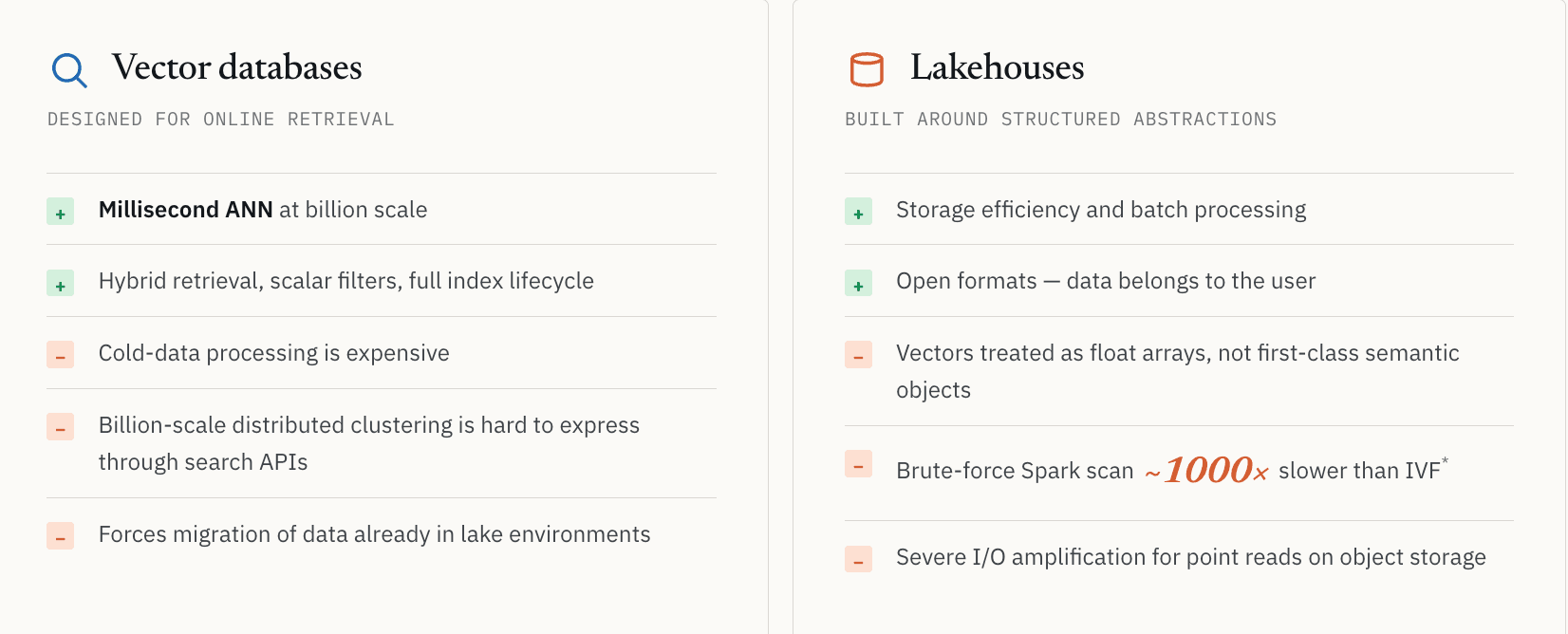
Les bases de données vectorielles ont été conçues principalement pour la récupération en ligne.
Prenons l’open source Milvus comme exemple. Il résout extrêmement bien la recherche vectorielle à grande échelle. Mais lorsque les charges de travail dépassent le service pour entrer dans la découverte à grande échelle, des limites architecturales naturelles apparaissent.
Le traitement des données froides devient coûteux. Le clustering distribué à l’échelle du milliard est difficile à exprimer via des API de recherche en ligne. De nombreux systèmes supposent que les données doivent rester chargées dans l’infrastructure en ligne pour rester interrogeables. Les entreprises qui stockent déjà d’immenses jeux de données non structurées dans des environnements de lac de données font face à des coûts de migration et à une fragmentation de la gouvernance lorsqu’on leur demande de tout déplacer vers un système de récupération dédié.
Ce ne sont pas des bugs d’implémentation. Ce sont les conséquences d’une optimisation pour la récupération en ligne à faible latence.
Les Lakehouses résolvent l’efficacité du stockage et le traitement batch, mais ont été conçus autour d’abstractions de données structurées
L’approche inverse, en partant du côté Lakehouse, introduit un autre ensemble de compromis.
Les Lakehouses résolvent élégamment l’efficacité du stockage et le traitement batch. Mais ils ont été conçus autour d’abstractions de données structurées. Dans la plupart des architectures de lac de données, les vecteurs sont encore traités comme de longs tableaux de nombres à virgule flottante plutôt que comme des objets sémantiques de première classe. Les formats de fichiers comme Parquet n’ont pas été conçus autour des index ANN, des index inversés ou des chemins de récupération sémantique à faible latence.
Nous l’avons constaté directement avec un client pharmaceutique effectuant une recherche de similarité moléculaire. Un scan Spark par force brute sur les données du lake était environ 1000x plus lent que la récupération vectorielle indexée utilisant une recherche basée sur IVF. Le chiffre exact dépend de la distribution des données, des paramètres d’index et du matériel, mais la leçon reste la même : sans le bon index, de nombreuses charges de travail sémantiques ne sont pas économiquement viables.
Il existe aussi un problème de stockage plus fondamental. Le stockage objet peut introduire une amplification d’E/S importante pour les charges de travail orientées récupération. La recherche sémantique trouve souvent un petit nombre d’ID, mais l’application a tout de même besoin des enregistrements complets derrière ces ID. Avec les formats colonnaires traditionnels, récupérer quelques petits enregistrements peut nécessiter la lecture de grands blocs de stockage. C’est acceptable pour les scans. C’est mal adapté au service à faible latence.
Au fil du temps, notre conclusion est devenue difficile à éviter : l’industrie ne devrait pas avoir à choisir entre bases de données vectorielles et architectures de lake. Elle a besoin d’une architecture dans laquelle la récupération et la découverte à grande échelle sont des parties natives du même système opérationnel.
Ce que nous entendons par Vector Lakebase
Cette prise de conscience nous a conduits vers ce que nous appelons désormais Vector Lakebase. L’idée centrale n’est pas « une base de données vectorielle plus un data lake ». Je pense que cette formulation passe à côté du point architectural le plus profond.
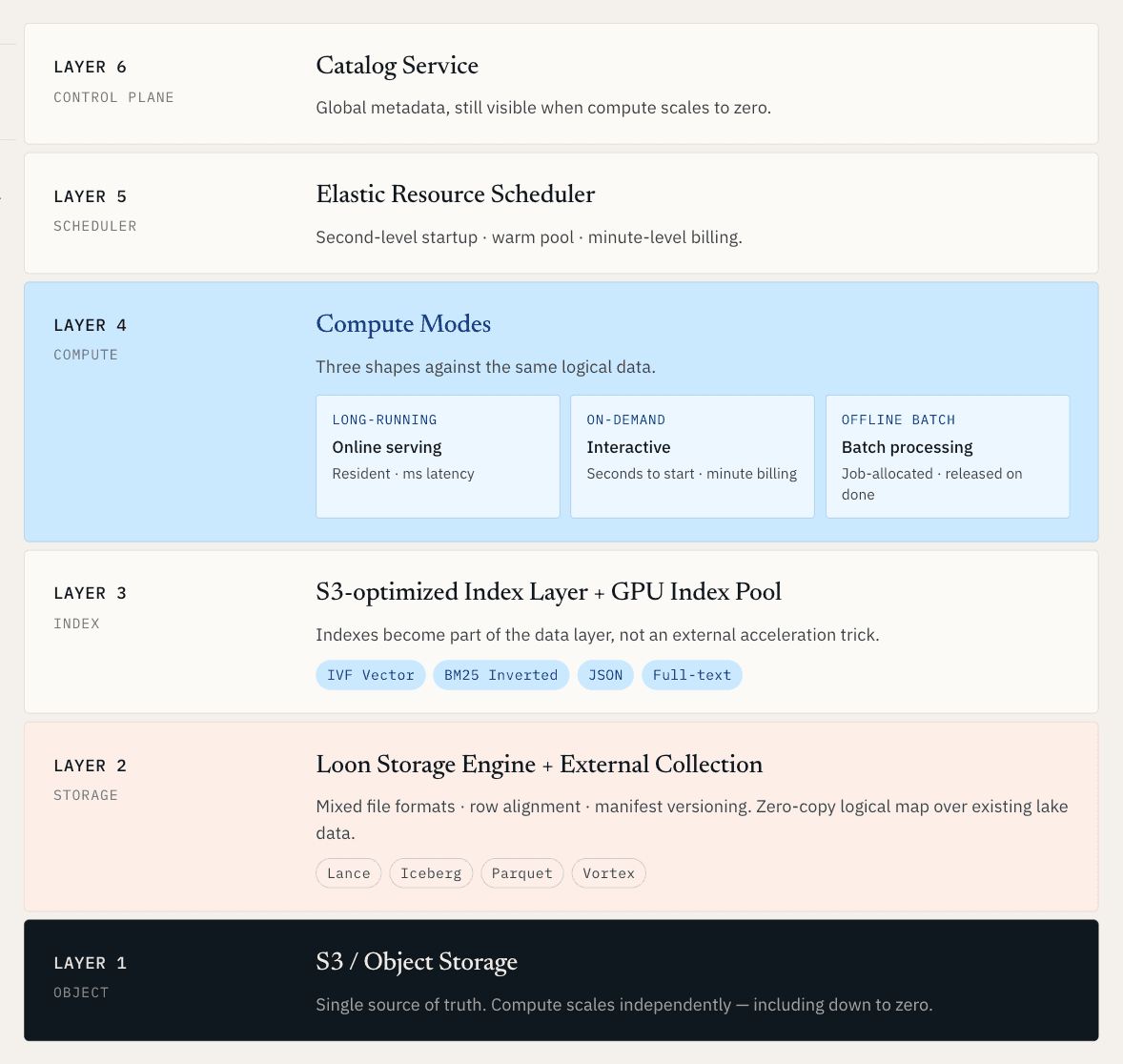
L’objectif est de créer une couche opérationnelle unifiée pour les données non structurées, dans laquelle le service en ligne, la découverte hors ligne et le calcul élastique fonctionnent tous sur la même fondation logique de données.
Pour les données brutes, cela signifie que les vecteurs, documents, métadonnées, logs et index sont gérés ensemble sur un stockage natif du lake. Pour les données qui résident déjà dans Iceberg, Lance, Parquet ou un stockage objet, cela signifie que le système peut mapper et indexer ces données sans imposer une migration complète.
Dès que l’on part de cette exigence, l’architecture doit résoudre plusieurs problèmes difficiles à la fois. Le calcul doit pouvoir évoluer indépendamment du stockage. Les index doivent devenir une partie de la couche de données, et non une astuce d’accélération externe. Les nouvelles données et les nouveaux index doivent être publiés ensemble sous forme de snapshots cohérents. Et les données de lake existantes doivent devenir recherchables sans créer une autre copie.
Ces idées semblent simples. Les faire fonctionner tout en préservant les performances que les gens attendent d’une base de données vectorielle est la partie difficile. C’est là que les décisions d’ingénierie de plus bas niveau commencent à compter.
Le coût de la séparation du stockage et du calcul et comment nous y répondons
La séparation stockage-calcul est nécessaire pour la boucle CS/CD, mais elle n’est pas gratuite.
Démarrage à froid lent
Si le calcul peut descendre à zéro, la première requête dans un workflow à la demande ou hors ligne peut toucher des données entièrement froides. Le nœud n’a pas d’index local, pas de cache chaud et aucune donnée résidente. Tout doit venir du stockage objet.
Pour les petits jeux de données, c’est gérable. Pour les grandes charges de travail vectorielles, cela devient rapidement inacceptable. Prenons un milliard de vecteurs à 768 dimensions. Un index HNSW conventionnel peut avoisiner 340 Go. Récupérer cet index complet depuis S3 peut prendre plus de quatre minutes. Personne ne veut attendre quatre minutes avant qu’une recherche puisse commencer.
Notre réponse consiste à rendre le chemin à froid beaucoup plus petit. En utilisant une quantification de type RaBitQ en 1+3 bits, nous pouvons compresser cet index d’environ 340 Go à environ 13 Go. La recherche s’exécute en deux étapes. La première étape utilise une représentation 1 bit pour le filtrage grossier, avec environ 85 à 90 pour cent de rappel tout en réduisant la taille des données à environ un trentième de l’original. La deuxième étape utilise la représentation 1+3 bits pour reranker et affiner les résultats jusqu’à environ 95 pour cent de rappel. Cela fait passer le démarrage à froid de plusieurs minutes à environ 5 à 10 secondes.
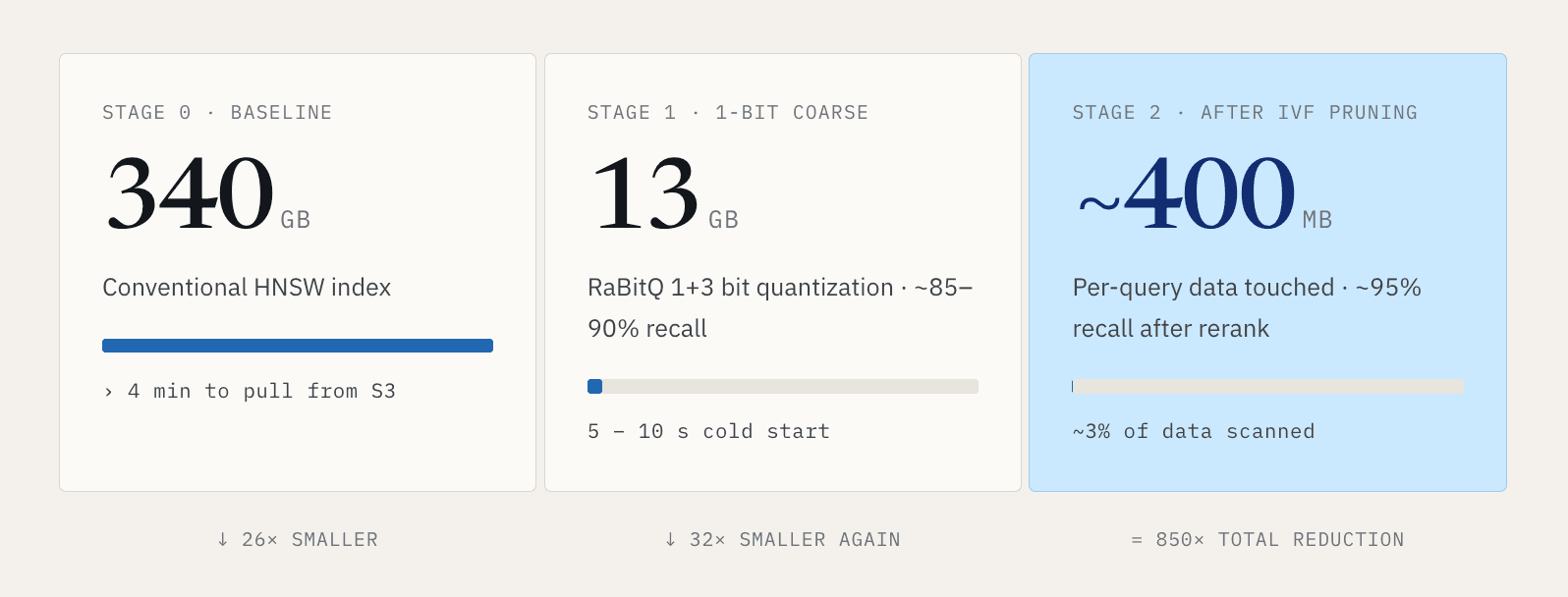
Nous utilisons ensuite le clustering IVF pour réduire la quantité de données consultées par requête. Dans une configuration représentative, chaque requête analyse environ 3 % des données. Le parcours devient : 340 Go d’index conventionnel, compressés à 13 Go, avec une seule requête touchant environ 400 Mo après élagage.
C’est la différence entre la recherche vectorielle élastique en tant qu’idée et la recherche vectorielle élastique en tant que système utilisable.
Amplification des E/S
Le démarrage à froid n’est qu’un aspect du problème. L’autre aspect est l’accès aux enregistrements.
La recherche vectorielle renvoie des ID. Mais les applications ont besoin d’enregistrements complets : fragments de texte, métadonnées, pointeurs de documents, autorisations, horodatages, attributs d’image ou autres champs. Dans une disposition Parquet standard, une petite lecture ponctuelle peut forcer le système à télécharger un grand groupe de lignes. Une requête peut n’avoir besoin que de quelques kilo-octets de données utiles, mais finir par extraire des dizaines de mégaoctets depuis le stockage objet. Réduire la taille des groupes de lignes aide les lectures ponctuelles, mais nuit à la compression et à l’efficacité des analyses.
C’est pourquoi nous avons construit Loon, le moteur de stockage reconstruit derrière Zilliz Vector Lakebase.
Loon utilise des formats de fichiers mixtes, l’alignement des lignes et le versionnement basé sur des manifestes. Les champs scalaires peuvent utiliser des dispositions en colonnes qui restent efficaces pour le filtrage et les analyses. Les champs vectoriels et les données fortement sollicitées par des requêtes ponctuelles peuvent utiliser des dispositions mieux adaptées à une récupération à faible latence. Les groupes de colonnes alignent les ID de lignes afin que le système puisse récupérer les champs dont il a besoin sans faire transiter par le réseau de grands blocs sans rapport.
Sous le capot, Loon utilise Vortex, un format de fichier open source placé sous l’égide de la Linux Foundation. Vortex prend en charge des dispositions flexibles et des encodages imbriqués, y compris les requêtes ponctuelles sans décompresser de grands blocs non pertinents.
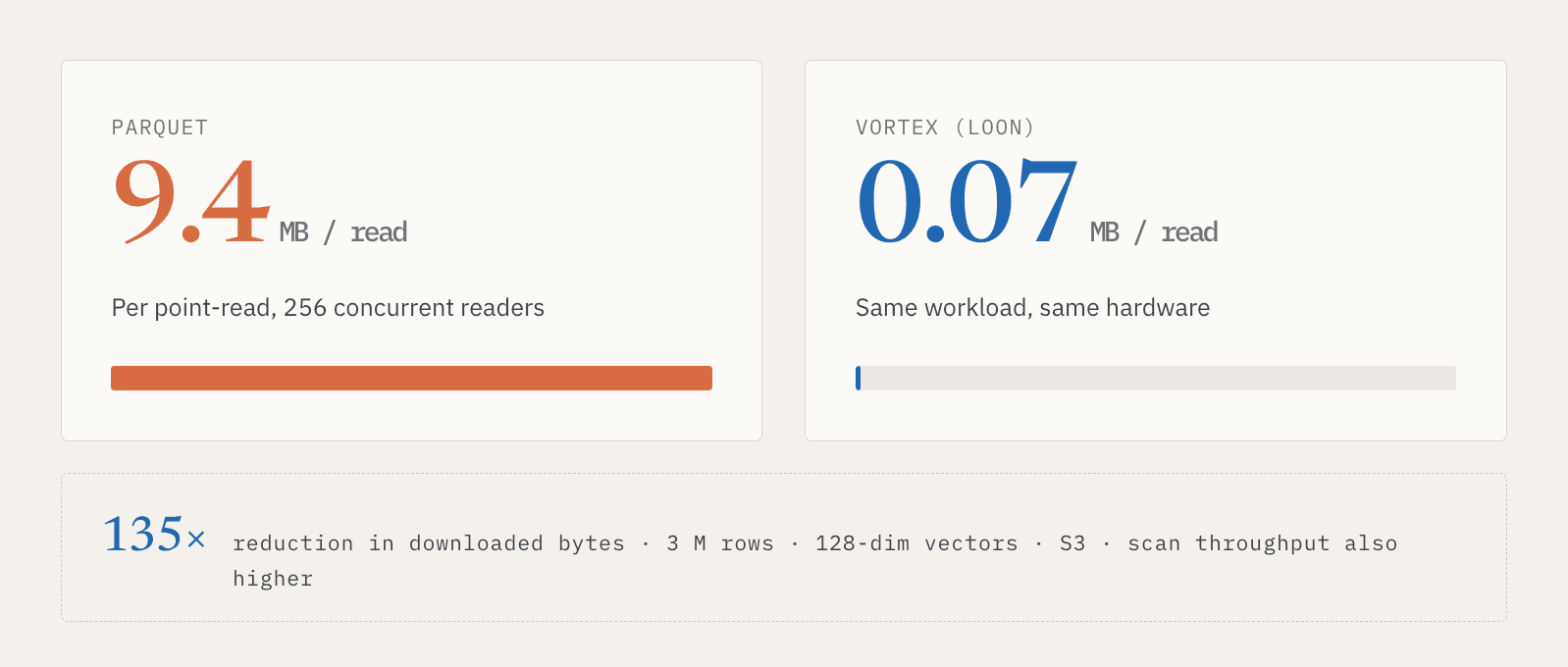
Dans un test interne portant sur 3 millions de lignes, des vecteurs à 128 dimensions, un stockage S3 et 256 lecteurs simultanés, les lectures ponctuelles Parquet ont téléchargé environ 9,4 Mo par lecture. Vortex a téléchargé environ 0,07 Mo. Cela représente une réduction de 135x des données téléchargées. Le débit des analyses complètes était également plus élevé dans cette configuration.
L’idée n’est pas seulement qu’un format est plus rapide pour un benchmark donné. L’idée est que le service et la découverte nécessitent des schémas d’accès différents sur les mêmes données logiques. Les systèmes en ligne ont besoin de lectures ponctuelles rapides. Les systèmes batch ont besoin d’analyses efficaces. Une Vector Lakebase doit prendre en charge les deux sans obliger les utilisateurs à conserver deux copies des données.
Vector Lakebase : une fondation de données unique, plusieurs modes de calcul
Une fois la couche de données partagée, le calcul ne peut pas être universel.
Les différentes charges de travail d’IA ont des formes très différentes. Certaines nécessitent une faible latence prévisible toute la journée. Certaines nécessitent une session de recherche interactive pendant dix minutes. Certaines nécessitent une grosse tâche batch qui s’exécute pendant la nuit puis disparaît.
C’est pourquoi Zilliz Vector Lakebase prend en charge trois modes de calcul.
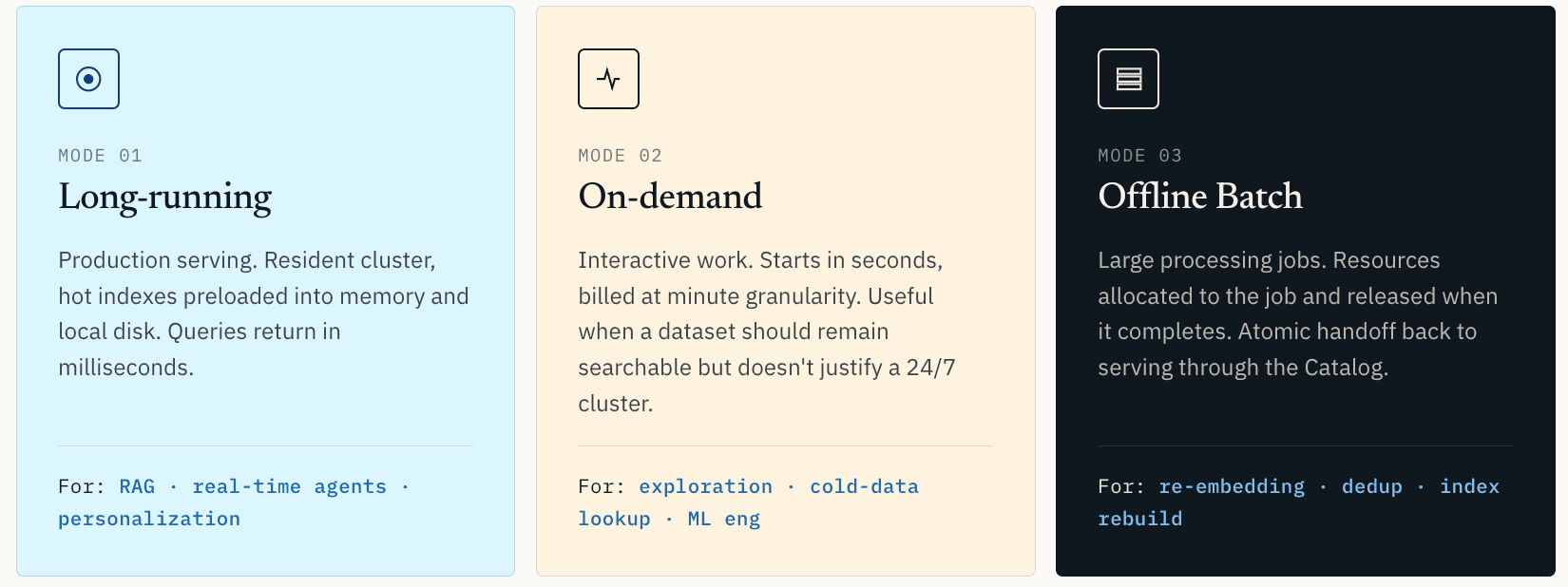
- Le calcul longue durée est destiné au service en production. Le cluster reste résident. Les index et données chauds sont préchargés en mémoire et sur disque local. Les requêtes répondent en quelques millisecondes. C’est le mode approprié pour le RAG en production, la recommandation en temps réel, la personnalisation, les agents en ligne et toute charge de travail où la latence fait partie de l’expérience utilisateur.
- Le calcul à la demande est destiné au travail interactif. Il démarre en quelques secondes et est facturé avec une granularité à la minute. Il est utile pour l’exploration de similarités, l’inspection d’anomalies, la récupération de données froides ou les flux de travail d’ingénierie ML où le jeu de données doit rester consultable sans justifier un cluster 24/7.
- Le calcul Offline Batch est destiné aux grandes tâches de traitement : clustering vectoriel, déduplication de données d’entraînement, ré-embedding complet, reconstruction d’index et analyses de qualité des données. Les ressources sont allouées à la tâche et libérées lorsqu’elle se termine.
Le transfert vers le service se fait via le catalogue sous la forme d’un nouvel instantané. Le service continue de lire l’ancien instantané jusqu’à ce que les nouvelles données et les nouveaux index soient prêts. Ensuite, la nouvelle version devient visible de manière atomique. Ce basculement atomique est important. La découverte n’est utile que si les améliorations peuvent revenir en production sans exposer des index à moitié construits ou des données incohérentes.
 architecture.png
architecture.png
Un exemple client montre pourquoi cette distinction est importante. Un client spécialisé dans la conduite autonome disposait d’un milliard de vecteurs à 768 dimensions, mais n’avait besoin que d’environ 20 minutes de temps de requête en ligne par jour. L’exécution de la charge de travail sous forme de cluster de longue durée coûtait environ $7,000 par mois. Le passage au mode à la demande a réduit le coût mensuel à environ $500. Le même client avait un workflow de déduplication qui passait auparavant environ 70 heures à effectuer des recherches ANN une par une. Sa refonte sous forme de tâche batch hors ligne a réduit le temps de calcul à environ 10 heures sur la même classe de ressources.

La leçon n’est pas qu’un mode de calcul est meilleur qu’un autre. La leçon est que les charges de travail de données pour l’IA n’ont pas une forme unique, et que l’architecture ne devrait pas les y contraindre.
La planification des ressources devient une partie du Vector Lakebase
Les trois modes de calcul ne fonctionnent que si la planification des ressources est aussi élastique que le calcul lui-même.
Les planificateurs de bases de données traditionnels supposent généralement un pool fixe de machines. Étant donné ces nœuds, le système décide où placer les données et comment équilibrer les charges. Ce modèle fonctionne bien lorsque la charge de travail est stable. Il convient mal aux charges de travail d’IA qui apparaissent par rafales : une session de recherche à la demande, une courte inspection de données froides, une tâche de déduplication nocturne, puis des heures sans activité.
Dans ce monde, la meilleure question n’est pas seulement de savoir où les données doivent s’exécuter. Elle est de savoir si le calcul doit s’exécuter tout court.
C’est pourquoi Vector Lakebase doit planifier les données et les ressources ensemble. En pratique, cela signifie maintenir un Warm Pool de nœuds préparés, attacher rapidement les données lorsque le travail arrive, garder les ressources chaudes brièvement après la requête, puis les libérer lorsqu’elles ne sont plus utiles.
Cela modifie également l’économie du système. Ce n’est pas la même chose qu’une tarification serverless par requête, et ce n’est pas non plus la même chose qu’une capacité mensuelle dédiée. Pour de nombreuses charges de travail de données pour l’IA, l’usage à la minute est l’unité la plus naturelle : payer le calcul pendant que la boucle s’exécute, puis le laisser disparaître.
Il y a derrière cela un changement architectural plus vaste, d’un plan de contrôle qui gère un noyau essentiellement statique vers un noyau qui comprend les ressources, l’état du cache, les instantanés et les coûts. Cela mérite son propre article. Pour cet article, le point important est plus simple : sans ce modèle de ressources, Long-running, On-demand et Offline Batch seraient trois choix de déploiement distincts, et non trois parties d’un même système de données élastique.
External Collection : rencontrer les données là où elles vivent déjà
Il y a une autre réalité pour laquelle nous avons dû concevoir le système.
La plupart des entreprises disposent déjà de grandes quantités de données non structurées dans des environnements de lake : tables Lance, tables Iceberg, jeux de données Parquet et répertoires de stockage d’objets. Leur demander de tout déplacer dans un nouveau système avant de pouvoir les utiliser n’est pas réaliste.
C’est pourquoi nous avons construit External Collection au sein de Zilliz Vector Lakebase. External Collection n’est pas seulement un mappage zéro copie. Elle construit une couche d’indexation indépendante au-dessus des données externes. Les données d’origine restent là où elles sont et continuent d’être gouvernées par la plateforme existante du client, tandis que Zilliz construit et gère les index vectoriels, les index inversés et les index JSON nécessaires pour rendre ces données consultables via le même chemin de récupération que les données natives.
Notre principe interne est devenu simple : One Data. One Index. Pas de stockage dupliqué. Pas de pipelines à double écriture. Pas de chemins de découverte fragmentés.
Cela signifie que la boucle CS/CD peut couvrir davantage que les données déjà importées dans une base de données vectorielle. Elle peut inclure les actifs de données non structurées que les entreprises possèdent déjà dans leurs lacs.
Ce qui définit la première génération de Vector Lakebase
Ces idées ne sont pas seulement une architecture sur le papier. Nous les livrons déjà dans Zilliz Vector Lakebase, et le processus de sa construction a rendu notre vision de la catégorie beaucoup plus concrète.
Une Vector Lakebase de première génération doit réussir plusieurs choses en même temps.

- Premièrement, la séparation stockage-calcul avec une mise en cache multicouche. Les données résident dans le stockage objet, et le calcul peut évoluer indépendamment, y compris jusqu’à zéro. Mais la séparation seule ne suffit pas. La recherche vectorielle en ligne a encore besoin de mémoire, de disque local, de nœuds chauds et d’une exécution tenant compte du cache pour maintenir les requêtes chaudes rapides au niveau de la milliseconde.
- Deuxièmement, une gestion unifiée des données non structurées multimodales. Le système doit gérer non seulement les vecteurs, mais aussi les documents sources, les images, l’audio, la vidéo, les embeddings, les métadonnées scalaires, les autorisations et les index. Un système qui ne stocke que des vecteurs est un service d’indexation, pas une fondation de données.
- Troisièmement, des capacités natives de base de données vectorielle. La recherche ANN en millisecondes, la gestion du cycle de vie des index, la recherche hybride, le filtrage scalaire, la recherche plein texte, le filtrage JSON et plusieurs métriques de similarité doivent être intégrés. Connecter un Lakehouse à une base de données vectorielle externe ne supprime pas la fragmentation. Cela crée simplement un autre pipeline.
- Quatrièmement, plusieurs modes de calcul. Le service en ligne, l’interaction à la demande et le traitement par lots hors ligne doivent fonctionner sur les mêmes données logiques. Le calcul à la demande est particulièrement important, car il devient le pont entre le service de production et le traitement hors ligne à grande échelle.
- Cinquièmement, des formats ouverts et aucune migration imposée. La couche de stockage doit être lisible par des moteurs externes tels que Spark, Ray et Daft. Les tables Iceberg existantes, les jeux de données Lance et les fichiers Parquet doivent pouvoir rejoindre le système sans copie inutile. Les données appartiennent à l’utilisateur, pas au moteur.
- Sixièmement, les ressources doivent suivre les données. Le calcul peut disparaître lorsqu’il n’est pas nécessaire, tandis que les métadonnées restent visibles et interrogeables. Une requête peut réactiver les ressources en quelques secondes. Les locataires inactifs ne doivent pas payer pour du calcul dédié qu’ils n’utilisent pas. Il ne s’agit pas seulement d’autoscaling ; cela exige que le moteur prenne des décisions de ressources conjointement avec les décisions de données.
Ce sont nos convictions actuelles, pas le dernier mot. Nous continuerons à les réviser à mesure que le système mûrit. Mais une pression semble peu susceptible de changer : les données non structurées continueront de croître, tandis que les budgets d’infrastructure n’augmenteront pas au même rythme. Cela signifie que les systèmes d’IA doivent devenir plus itératifs, plus efficaces et plus continuellement adaptatifs.
Les bases de données vectorielles ne disparaissent pas
Donc, pour revenir à la question initiale : cela signifie-t-il que les bases de données vectorielles vont disparaître ? Pas du tout.
Au contraire, la recherche sémantique devient plus importante dans cette architecture. Mais son rôle change.
Les bases de données vectorielles deviennent le moteur de service au sein d’un système de données non structurées plus vaste, tout comme les bases de données transactionnelles sont restées essentielles à l’intérieur de l’ère plus large du Lakehouse. Les systèmes OLTP n’ont pas été remplacés par les Lakehouses. Ils sont devenus une couche au sein d’une pile d’architecture plus vaste. Je pense que les bases de données vectorielles connaissent actuellement la même transition.
Le changement plus large qui se produit sous l’infrastructure d’IA ne concerne pas simplement la recherche. Il s’agit de construire des boucles opérationnelles continues autour des données non structurées elles-mêmes. Le service génère des retours. La découverte améliore la qualité des données. Ces améliorations retournent en production. Chaque tour de boucle rend le système meilleur.
Tout le reste, y compris les formats de stockage, les hiérarchies de mise en cache, les systèmes d’indexation, les modèles de calcul élastique et l’ordonnancement des ressources, existe pour rendre ce volant d’inertie économiquement viable à grande échelle.
Nous ne savons toujours pas exactement ce que deviendra Vector Lakebase au cours des cinq prochaines années. Lorsque nous avons commencé Milvus il y a près de dix ans, nous n’aurions pas non plus pu prédire où les bases de données vectorielles elles-mêmes nous mèneraient.
Mais une chose semble claire désormais. Les données non structurées continueront de croître. Les modèles continueront d’évoluer. Les agents généreront davantage de traces, de retours et d’états. Les équipes devront améliorer leurs données plus rapidement sans laisser les coûts d’infrastructure augmenter sans limite.
Les systèmes qui réussiront seront ceux qui feront que le service continu et la découverte continue donneront l’impression de faire partie de la même machine. C’est la direction vers laquelle nous construisons.
Zilliz Vector Lakebase est disponible en préversion publique
Nous avons lancé la préversion publique de Zilliz Vector Lakebase — une évolution majeure de Zilliz Cloud, qui passe d’une base de données vectorielle gérée à une plateforme de données sémantiques unifiée, combinant le service vectoriel à faible latence avec l’ouverture, l’évolutivité et l’économie d’un lac de données.
Fonctionnalités principales de Zilliz Vector Lakebase :
- Service à plusieurs niveaux optimisé pour différents compromis performance-coût en temps réel
- Recherche à la demande pour les charges de travail à grande échelle ou exploratoires, sans calcul toujours actif
- Recherche dans un lac de données externe — indexez et recherchez directement dans vos données de lac existantes
- Recherche sur tout le spectre des vecteurs, du texte, du JSON et des données géospatiales, avec récupération hybride et reranking
- Stockage unifié natif du lac, fondé sur Vortex, un format ouvert offrant des lectures aléatoires plus rapides et moins coûteuses que Lance ou Parquet
Si votre pile actuelle sépare le service et la découverte en systèmes distincts, Vector Lakebase pourrait valoir le détour. Essayez-le sur Zilliz Cloud — les nouvelles inscriptions avec une adresse e-mail professionnelle bénéficient de 100 $ de crédits gratuits — ou contactez-nous au sujet de votre cas d’utilisation.
Note : Les chiffres de performance et de coût présentés dans cet article proviennent des résultats open source de VectorDB Benchmark, de tests internes et de scénarios clients anonymisés. Les résultats réels varient selon l’échelle des données, leur distribution, les paramètres d’indexation, le profil de la charge de travail et la configuration des ressources.

Continuer à lire

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.