




ColPali : Recherche de documents améliorée avec des modèles de langage de vision et la stratégie d'intégration de ColBERT
Retrieval Augmented Generation (RAG) est une technique qui combine les capacités des grands modèles de langage (LLMs avec des sources de connaissances externes pour améliorer la précision et la pertinence des réponses. Une application courante du RAG est l'extraction de contenu à partir de sources telles que les PDF, car ces fichiers contiennent souvent des données précieuses, mais sont difficiles à rechercher et à indexer. La difficulté réside dans le fait que des informations importantes peuvent être négligées en fonction de l'outil utilisé pour l'extraction. Par exemple, le texte incorporé dans les images peut ne pas être détecté lors de l'extraction, ce qui rend impossible sa récupération ultérieure.
ColPali, un modèle de recherche de documents, aborde ce problème grâce à sa nouvelle architecture basée sur des modèles de langage de vision (VLM). Il indexe les documents à l'aide de leurs caractéristiques visuelles, en capturant les éléments textuels et visuels. En générant des représentations multi-vectorielles du texte et des images de type ColBERT, ColPali encode les images des documents directement dans un espace d'intégration unifié, éliminant ainsi le besoin d'extraction et de segmentation traditionnelles du texte.
Figure : Pipeline d'extraction standard et pipeline ColPali pour l'extraction de PDF](https://assets.zilliz.com/Co_Pali_image_2_50aa11b6d2.png)
L'image ci-dessus est tirée de l'article de ColPali (https://arxiv.org/abs/2407.01449), dans lequel les auteurs expliquent qu'un pipeline de recherche de PDF classique comprend généralement plusieurs étapes : l'extraction de texte à l'aide de l'OCR, la détection de la mise en page, le [regroupement] (https://zilliz.com/learn/guide-to-chunking-strategies-for-rag) et la génération de l'[incorporation] (https://zilliz.com/glossary/vector-embeddings). ColPali simplifie ce processus en utilisant un seul modèle de langage de vision (VLM) qui prend une capture d'écran de la page comme entrée.
ColPali intègre des outils qui vont au-delà des systèmes RAG traditionnels, il est donc important de comprendre d'abord certains de ces concepts. Avant d'aborder les détails de ColPali, nous allons apprendre les modèles de langage de vision et les modèles d'interaction tardive.
Que sont les modèles de langage de vision (VLM) ?
Les modèles de langage de vision (VLM) sont des [modèles multimodaux] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know) qui apprennent simultanément à partir d'images et de textes. Ils prennent des images et des textes en entrée et génèrent des textes en sortie. Ils font partie de la catégorie plus large des [modèles génératifs] (https://zilliz.com/glossary/foundation-models).
 Exemple de VLM
Exemple de VLM
ColPali s'appuie sur les VLM pour aligner les enchâssements d'éléments de texte et d'image acquis au cours de la mise au point multimodale. Plus précisément, il utilise une version étendue du modèle PaliGemma-3B pour produire des représentations multi-vectorielles ColBERT-style. Les auteurs ont choisi ce modèle parce qu'il dispose d'une variété de points de contrôle adaptés à différentes résolutions d'images et tâches, y compris l'OCR pour la lecture de texte à partir d'images.
ColPali est construit sur le modèle PaliGemma-3B de Google, qui a été publié avec des poids ouverts. Ce modèle a été entraîné à l'aide d'un ensemble de données diversifié - 63 % de données académiques et 37 % de données synthétiques provenant de pages PDF explorées sur le web, enrichies de pseudo-questions générées par le VLM.
Que sont les modèles d'interaction tardive ?
Les modèles [Late Interaction] (https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search#The-Late-Interaction-Mechanism) sont conçus pour les tâches de recherche. Ils se concentrent sur la similarité au niveau des jetons entre les documents plutôt que d'utiliser une représentation vectorielle unique. En représentant le texte comme une série d'encastrements de jetons, ces modèles offrent le détail et la précision des encodeurs croisés tout en bénéficiant de l'efficacité du stockage de documents hors ligne.
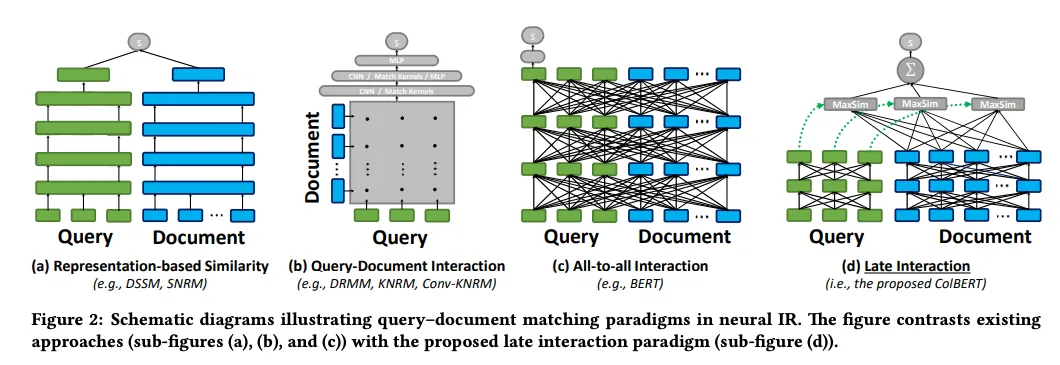 Figure 2 : Schémas illustrant les paradigmes de correspondance requête-document dans la RI neuronale
Figure 2 : Schémas illustrant les paradigmes de correspondance requête-document dans la RI neuronale
Figure 2 : Schémas illustrant les paradigmes d'appariement requête-document en RI neuronale. | Source](https://arxiv.org/pdf/2004.12832)_
Avec cette compréhension des modèles d'interaction tardive et des modèles de langage de vision, nous pouvons maintenant explorer comment ColPali combine ces éléments pour améliorer la recherche de documents.
Qu'est-ce que ColPali et comment fonctionne-t-il ?
ColPali est un modèle avancé de récupération de documents conçu pour indexer et récupérer des informations directement à partir des caractéristiques visuelles des documents, en particulier les PDF. Contrairement aux méthodes traditionnelles qui reposent sur la reconnaissance optique des caractères (OCR) et la segmentation du texte, ColPali capture des captures d'écran de chaque page et intègre des pages entières de documents dans un espace vectoriel unifié à l'aide de VLM. Cette approche permet à ColPali de contourner les processus d'extraction complexes, ce qui améliore la précision et l'efficacité de la recherche.
Vous trouverez ci-dessous les principales étapes de son flux de travail :
Traitement des documents
- Création d'images à partir de PDF:** Au lieu d'extraire le texte, de créer des morceaux, puis de les incorporer, ColPali incorpore directement la capture d'écran d'une page PDF dans une représentation vectorielle. Cette étape revient à prendre une photo de chaque page plutôt que d'essayer d'en extraire le contenu.
- Diviser les images en grilles** : Chaque page est ensuite divisée en une grille de morceaux uniformes appelés patchs. Par défaut, elle est divisée en une grille de 32x32, ce qui donne 1024 patchs par image. Chaque patch est représenté par un vecteur à 128 dimensions. On peut considérer qu'il s'agit d'une image avec 1024 "mots" décrivant ces patchs.
Génération d'intégration
- Traitement des patchs d'images : ColPali transforme ces patchs visuels en embeddings grâce à un Vision Transformer (ViT), qui traite chaque patch pour créer une représentation vectorielle détaillée.
- Alignement de l'intégration visuelle et de l'intégration textuelle** : Pour faire correspondre les informations visuelles à la requête, ColPali convertit le texte de la requête en encastrements dans le même espace vectoriel que les patchs de l'image. Cet alignement permet au modèle de comparer et de faire correspondre directement les contenus visuels et textuels.
- Traitement de la requête** : Le modèle génère des jetons dans la requête, en attribuant à chaque jeton un vecteur à 128 dimensions. Il utilise des invites telles que "Décrivez cette image
" pour s'assurer que le modèle se concentre sur les éléments visuels, ce qui permet une intégration transparente des données textuelles et visuelles.
Mécanisme de récupération
ColPali utilise un mécanisme de similarité d'interaction tardive pour comparer la requête et les enchâssements de documents au moment de la requête. Cette approche permet une interaction détaillée entre tous les vecteurs de cellules de la grille d'image et les vecteurs de jetons du texte de la requête, garantissant ainsi une comparaison complète.
La similarité est calculée en utilisant une approche de "somme des similarités maximales" :
- Calculer les scores de similarité entre chaque jeton de la requête et chaque jeton du patch dans l'image.
- Agréger ces scores pour générer un score de pertinence pour chaque document.
- Trier les documents par ordre décroissant de score, en utilisant le score comme mesure de pertinence.
Cette méthode permet à ColPali de faire correspondre efficacement les requêtes des utilisateurs avec les documents pertinents, en se concentrant sur les parties de l'image qui correspondent le mieux au texte de la requête. Cette méthode met en évidence les parties les plus pertinentes du document, en combinant le contenu textuel et visuel pour une recherche précise.
Processus de formation du modèle
ColPali est construit sur le modèle PaliGemma-3B, un modèle de langage de vision développé par Google. Dans son implémentation, ColPali maintient les poids du modèle gelés pendant l'entraînement afin de conserver les connaissances pré-entraînées du VLM tout en se concentrant sur l'optimisation pour les tâches de recherche de documents.
La clé de l'adaptation de ce VLM polyvalent à la recherche de documents réside dans un composant petit mais crucial : un adaptateur spécifique à la recherche de documents : **Cet adaptateur est superposé au modèle PaliGemma-3B et est entraîné à apprendre des représentations adaptées aux tâches de recherche.
Le processus d'apprentissage de cet adaptateur utilise une approche d'apprentissage par triplet :
- Une requête textuelle
- Une image d'une page correspondant à la requête
- Une image d'une page sans rapport avec la requête
Cette méthode permet au modèle d'apprendre à distinguer finement le contenu pertinent de celui qui ne l'est pas, ce qui améliore la précision de la recherche.
Avantages de ColPali
- Limitation du prétraitement complexe** : ColPali remplace le pipeline traditionnel d'extraction de texte, d'OCR, de détection de mise en page et de découpage par un seul VLM qui prend une capture d'écran de la page comme entrée.
- Capture des informations visuelles et textuelles** : En travaillant directement avec les images des pages, ColPali peut intégrer à la fois le contenu textuel et la mise en page visuelle dans sa compréhension des documents.
- Extraction efficace de documents visuellement riches** : Le mécanisme d'interaction tardive permet une correspondance fine entre les requêtes et le contenu du document, ce qui permet une récupération efficace des informations pertinentes dans des documents complexes et visuellement riches.
- Préservation du contexte** : En opérant sur des images de pages entières, ColPali conserve le contexte complet du document, qui peut être perdu dans les approches traditionnelles de découpage du texte.
Défis de ColPali
Comme tout système de recherche à grande échelle, ColPali est confronté à des défis importants en termes de complexité de calcul et d'exigences de stockage.
Complexité informatique : Les besoins en calcul de ColPali augmentent de façon quadratique avec le nombre de mots clés et de vecteurs de patch. Cela signifie qu'à mesure que la complexité des requêtes ou la résolution des images de documents augmente, la demande de calcul croît rapidement.
Exigences en matière de stockage : Le coût de stockage des approches de type ColBERT est de 10 à 100 fois supérieur à celui de l'intégration vectorielle dense, car il faut un vecteur pour chaque jeton. Les besoins en stockage du système augmentent linéairement en fonction de trois facteurs :
le nombre de documents
Le nombre de correctifs par document
[Dimensionnalité] (https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning) des représentations vectorielles.
Cette mise à l'échelle peut entraîner des besoins de stockage importants pour les grandes collections de documents.
Stratégie d'optimisation - Réduction de la précision
Pour résoudre ces problèmes de mise à l'échelle, nous suggérons d'utiliser la stratégie de réduction de la précision.
- Réduction de la précision : Le passage de représentations de haute précision (par exemple, les nombres flottants de 32 bits) à des formats de moindre précision (par exemple, les nombres entiers de 8 bits) peut réduire considérablement les besoins de stockage avec un impact souvent minime sur la qualité de l'extraction.
Résumé
ColPali a un potentiel significatif pour transformer la façon dont nous récupérons un contenu visuellement riche avec un contexte textuel dans les systèmes RAG. En s'appuyant sur les modèles de langage de la vision, il permet de récupérer des documents en se basant non seulement sur le texte mais aussi sur les éléments visuels.
Cependant, malgré ses résultats impressionnants, ColPali est confronté à des défis en raison de ses exigences élevées en matière de stockage et de sa complexité de calcul, ce qui pourrait entraver son adoption à grande échelle. Des optimisations futures pourraient remédier à ces limitations et le rendre plus pratique. Comme les méthodes RAG continuent à se développer, les méthodes de recherche comme ColPali, qui intègrent la compréhension visuelle et textuelle, sont susceptibles de jouer un rôle de plus en plus important dans la [recherche d'informations] (https://zilliz.com/learn/what-is-information-retrieval) à travers divers types de documents.
Nous aimerions savoir ce que vous en pensez !
Si vous avez aimé cet article de blog, nous vous serions reconnaissants de nous donner une étoile sur GitHub ! Vous pouvez également rejoindre notre communauté Milvus sur Discord pour partager vos expériences. Si vous souhaitez en savoir plus, consultez notre dépôt Bootcamp sur GitHub ou nos notebooks. Nous aimerions également savoir si vous prévoyez d'essayer ColPali à l'avenir !
Lectures complémentaires
- ColPali Paper : [2407.01449] ColPali : Efficient Document Retrieval with Vision Language Models
- ColPali GitHub : https://github.com/illuin-tech/colpali
- ColBERT : A Token-Level Embedding and Ranking Model (Modèle d'intégration et de classement au niveau du jeton)](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
- ColPali : Récupération de documents avec des modèles de langage de vision](https://antaripasaha.notion.site/ColPali-Document-Retrieval-with-Vision-Language-Models-10f5314a5639803d94d0d7ac191bb5b1)
- Qu'est-ce que RAG ?
- Qu'est-ce qu'une base de données vectorielles et comment fonctionne-t-elle ?](https://zilliz.com/learn/what-is-vector-database)

Continuer à lire

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.