




Todo lo que necesitas saber sobre Llama 2

Todo lo que necesitas saber sobre Llama 2
¿Qué es Llama 2?
Llama 2, presentado por Meta AI en 2023, es un avance significativo en los modelos de lenguaje grandes (LLMs). Estos modelos, Llama 2 y Llama 2-CHAT, escalan hasta 70 mil millones de parámetros y están disponibles para fines de investigación y comerciales sin costo, lo que representa un salto adelante en las capacidades de procesamiento del lenguaje natural (NLP), desde la generación de texto hasta la interpretación de código de programación.
Basándose en su predecesor, LLaMa 1, que inicialmente era accesible solo para instituciones de investigación bajo una licencia no comercial, Llama 2 marca un cambio importante hacia la democratización del acceso a tecnologías de IA de vanguardia. A diferencia de su predecesor, los modelos Llama 2 son “open-source” y, por lo tanto, están disponibles libremente para aplicaciones de investigación y comerciales, reflejando el compromiso de Meta de fomentar un ecosistema de IA generativa más inclusivo y colaborativo.
El lanzamiento de Llama 2 proporciona acceso a LLMs de última generación y aborda los desafíos computacionales asociados con su desarrollo. Al optimizar el rendimiento sin aumentar exponencialmente el número de parámetros, Llama 2 ofrece modelos con distintos tamaños de parámetros, que van desde 7 mil millones hasta 70 mil millones. Este enfoque estratégico permite a organizaciones más pequeñas y comunidades de investigación aprovechar el poder de los LLMs sin recursos computacionales exorbitantes.
Además, la dedicación de Meta a la transparencia es evidente en su decisión de publicar tanto el código como los pesos del modelo de Llama 2, lo que facilita una mayor comprensión y colaboración dentro de la comunidad de investigación en IA. Al reducir las barreras de entrada y promover la accesibilidad, Llama 2 allana el camino para un futuro más inclusivo e innovador en la investigación y el desarrollo de la IA.
Llama 2
Llama 2 es una versión actualizada de Llama 1 entrenada con una nueva mezcla de datos públicos. El conjunto de datos preentrenado se incrementó en un 40%, la longitud de contexto se duplicó y el equipo de Meta adoptó la atención de consulta agrupada al construir Llama 2.
| Datos de entrenamiento | Parámetros | Longitud de contexto | Atención de consulta agrupada | Tokens | |
| Llama 1 | Véase Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Una nueva mezcla de datos en línea públicamente disponibles | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT es una versión ajustada de Llama 2 que el equipo de Meta optimizó para casos de uso de lenguaje natural. Las variantes de este modelo están disponibles con 7B, 13B y 70B parámetros. Llama 2-Chat está sujeto a las mismas limitaciones bien reconocidas de otros LLMs, incluida la interrupción de las actualizaciones de conocimiento después del preentrenamiento, el potencial de generación no factual, como consejos no cualificados, y una propensión a las alucinaciones.
Código abierto de Llama 2
Si bien Meta ha proporcionado generosamente acceso al código inicial y a los pesos del modelo para los modelos Llama 2 con fines de investigación y comerciales, han surgido debates sobre la idoneidad de etiquetarlo como "código abierto" debido a ciertas restricciones descritas en su acuerdo de licencia.
El debate en torno a la clasificación de los términos de licencia de Llama 2 depende de matices técnicos y semánticos. Si bien "código abierto" se usa comúnmente de manera coloquial para denotar cualquier software con código fuente libremente accesible, tiene un significado específico como designación formal supervisada por la Open Source Initiative (OSI). Para calificar como "aprobado por la Open Source Initiative", una licencia de software debe adherirse a los diez criterios descritos en la Definición Oficial de Código Abierto (OSD).
Como tal, la aplicabilidad de la etiqueta "código abierto" a los modelos Llama 2 depende de si sus términos de licencia se alinean con los criterios estrictos establecidos por la OSI. Esta distinción subraya la importancia de la claridad y la precisión al hablar sobre la accesibilidad y distribución de recursos de software dentro de la comunidad de desarrollo más amplia.
Sin embargo, aunque Llama 2 no es completamente de código abierto, ofrece a los desarrolladores un modelo atractivo con mucha más flexibilidad que los modelos cerrados creados por OpenAI, Google y otros actores importantes en el campo de la IA generativa.
Arquitectura de Llama 2
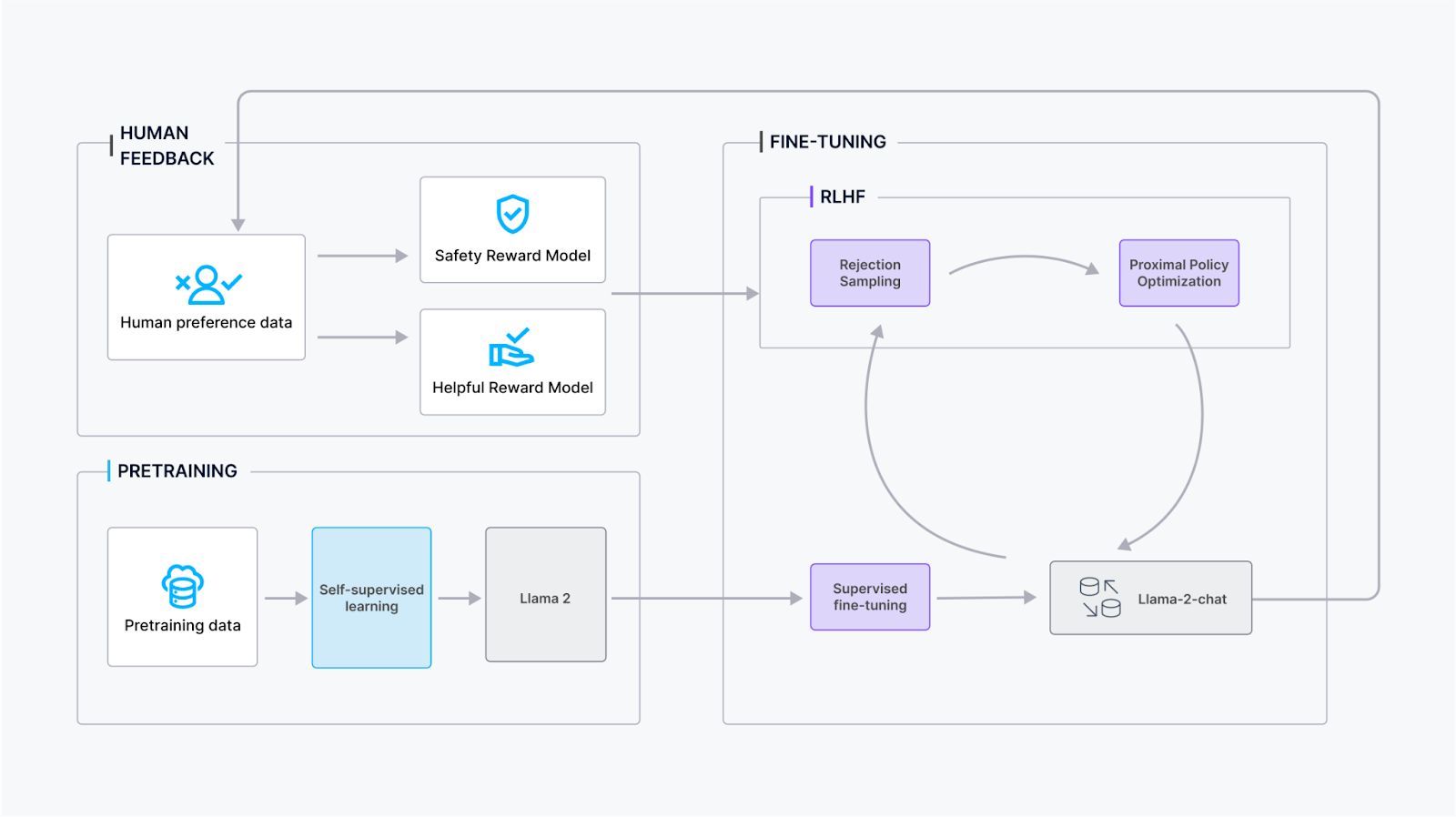
El proceso de entrenamiento de Llama 2-Chat implica varias etapas para garantizar un rendimiento y refinamiento óptimos:
Preentrenamiento: Llama 2 se somete a preentrenamiento utilizando fuentes en línea disponibles públicamente para establecer conocimientos fundamentales y comprensión del lenguaje.
Ajuste fino supervisado: El equipo de Meta creó una versión inicial de Llama 2-Chat mediante ajuste fino supervisado, donde el modelo aprende de datos etiquetados para mejorar sus capacidades conversacionales.
Aprendizaje por refuerzo con retroalimentación humana (RLHF): El modelo se somete a un refinamiento iterativo utilizando metodologías de RLHF, principalmente mediante muestreo por rechazo y Optimización de Política Proximal (PPO). Esta etapa implica una interacción continua con la retroalimentación humana para mejorar la calidad conversacional.
Modelado iterativo de recompensas: A lo largo de la etapa de RLHF, la acumulación de datos de modelado iterativo de recompensas ocurre en paralelo con las mejoras del modelo. El modelado iterativo de recompensas garantiza que los modelos de recompensa permanezcan dentro de la distribución, contribuyendo a mejorar de manera constante las capacidades conversacionales del modelo.
Al incorporar estos pasos, el entrenamiento de Llama 2-Chat tiene como objetivo lograr un rendimiento conversacional sólido mientras se adapta a la retroalimentación de los usuarios y mantiene la alineación con los modelos de recompensa.
¿Qué es un Embedding en Machine Learning?
En machine learning, un embedding se refiere a una representación aprendida de objetos en un espacio vectorial continuo, como palabras, imágenes o entidades. Estos embeddings capturan relaciones semánticas y similitudes entre objetos, haciéndolos más adecuados para tareas computacionales. En procesamiento del lenguaje natural (NLP), los embeddings de palabras, por ejemplo, asignan palabras de un vocabulario a vectores densos en un espacio de alta dimensión, donde las palabras similares están cerca unas de otras.
En Llama 2, los embeddings desempeñan un papel crucial en la comprensión y generación de lenguaje natural. Llama 2 utiliza embeddings para representar palabras, frases u oraciones completas en un espacio vectorial continuo. Llama 2 puede procesar y generar texto de manera eficaz al incrustar entradas y salidas de lenguaje mientras captura relaciones semánticas y matices.
Por ejemplo, Llama 2 aprende embeddings para palabras y frases a partir del vasto corpus de texto con el que se entrena durante el proceso de entrenamiento. Estos embeddings codifican información semántica sobre el lenguaje, lo que permite a Llama 2 comprender y generar respuestas coherentes a consultas o prompts.
Los embeddings en aprendizaje automático, incluidos los utilizados en Llama 2, facilitan la representación del lenguaje y otros datos de una manera estructurada y semánticamente significativa, lo que permite el procesamiento, la comprensión y la generación eficaces de lenguaje natural.
¿Cómo usar Llama 2?
Para usar Llama 2 de manera eficaz, accede al modelo a través de la interfaz o API proporcionada, asegurándote de que los permisos estén establecidos. Prepara tus datos de entrada, ya sean texto, imágenes o formatos compatibles, y preprocésalos según sea necesario. Especifica la tarea para Llama 2, como generación de texto o resumen. Introduce los datos preprocesados en Llama 2, recupera la salida y evalúa su calidad. Experimenta con diferentes formatos y configuraciones para optimizar los resultados. Supervisa métricas de rendimiento como precisión y velocidad, ajustando las estrategias según los comentarios. Mantente al día sobre las mejoras para maximizar la eficacia, desbloqueando nuevas posibilidades para proyectos y aplicaciones. También puedes usar Llama 2 con herramientas como LangChain, LlamaIndex y Semantic Kernel al crear aplicaciones RAG.
Rendimiento de Llama 2
El rendimiento general puede verse observando algunos benchmarks agregados populares. Aquí hay una tabla de resultados sobre el rendimiento en comparación con modelos basados en código abierto, tal como se señala en el artículo de LLama 2:
| Modelo | Tamaño | Código | Razonamiento de sentido común | Conocimiento del mundo | Comprensión lectora | Matemáticas | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Puedes ver que Llama 2 supera a Llama 1 en varias categorías como MMLU y BBH, e incluso obtiene buenos resultados frente al modelo Falcon.
Llama 2 vs GPT 4
El artículo de Llama 2 también cubre algunas comparaciones con Llama 2 y GPT 4 y algunos otros, como se muestra a continuación:
| Benchmark (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot): Al modelo se le dan 5 pasajes o ejemplos para generar una respuesta.
- TriviaQA (1-shot): Un conjunto de datos en el que se proporciona al modelo un único contexto o pregunta antes de generar una respuesta.
- Natural Questions (1-shot): Otro conjunto de datos en el que se da al modelo una pregunta como entrada.
- GSM8K (8-shot): Un conjunto de datos en el que se dan al modelo 8 pasajes o ejemplos para responder preguntas o realizar tareas.
- HumanEval (0-shot): Un conjunto de datos o configuración de evaluación en la que el modelo se evalúa en tareas o preguntas en las que no ha sido entrenado explícitamente, de ahí "0-shot."
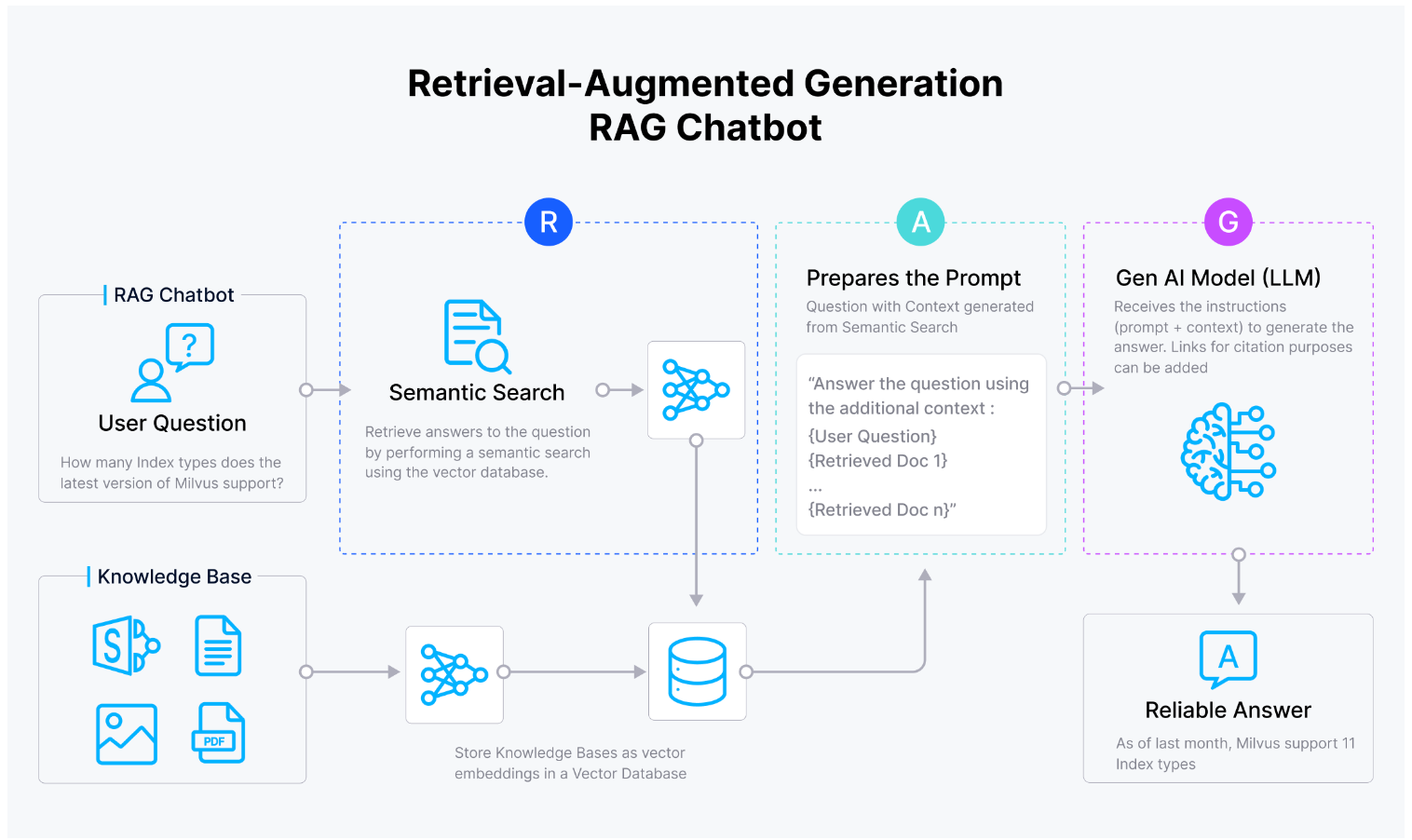
¿Funciona Zilliz con Llama 2?
El caso de uso más común de Zilliz Cloud junto con Llama 2 es el desarrollo de aplicaciones de Retrieval Augmented Generation (RAG). Las aplicaciones RAG aprovechan las capacidades de los large language models (LLMs) como Llama 2, que se entrenan con enormes conjuntos de datos pero que, por naturaleza, operan dentro de los límites de datos finitos. Por sí solo, Llama 2 tiende a "alucinar" respuestas, generando respuestas incluso cuando puede no haber suficiente contexto o información precisa. RAG es una forma de abordar esta alucinación.
La combinación de Zilliz Cloud y Llama 2 permite a los usuarios integrar sin problemas capacidades avanzadas de comprensión y generación de lenguaje con sistemas de recuperación basados en vectores eficientes y escalables proporcionados por Zilliz Cloud. Al aprovechar las fortalezas de ambas plataformas, los desarrolladores pueden crear aplicaciones sofisticadas que destacan en tareas que requieren procesamiento integral del lenguaje, recuperación de información y funcionalidades de generación.
Recursos clave
- ¿Qué es Llama 2?
- Arquitectura de Llama 2
- ¿Qué es un Embedding en Machine Learning?
- ¿Cómo usar Llama 2?
- Rendimiento de Llama 2
- Llama 2 vs GPT 4
- ¿Funciona Zilliz con Llama 2?
- Recursos clave
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis