




Comprender el algoritmo CURE: una exploración completa del clustering con representantes
 Representación visual del clustering
Representación visual del clustering
Figura 1: Representación visual del clustering
¿Cómo pueden las empresas navegar por un mercado en constante cambio y agrupar eficazmente a clientes con patrones similares? Los métodos tradicionales de clustering a menudo se quedan cortos al tratar con formas de datos irregulares y valores atípicos. La complejidad de los conjuntos de datos modernos exige soluciones más inteligentes y adaptables.
Aquí entra el algoritmo CURE (Clustering Using Representatives), un método eficaz que aborda las limitaciones de los enfoques de clustering estándar. CURE utiliza una selección de puntos representativos para diferenciarse de los métodos clásicos de clustering, mejorando así su inteligencia al discernir distribuciones de datos complejas. Estos puntos representativos se acercan a la media del clúster, lo que hace que el algoritmo sea más avanzado al permitirle tratar con clústeres de forma arbitraria.
CURE puede volverse computacionalmente intensivo cuando se aplica a grandes conjuntos de datos. A pesar de esto, su enfoque para manejar anomalías y clústeres complejos sigue siendo altamente eficaz. Analicemos las operaciones del algoritmo CURE explorando su enfoque central, ventajas y aplicaciones prácticas. También repasaremos los desafíos que puedes enfrentar al implementar CURE.
¿Qué es el algoritmo CURE?
El algoritmo CURE utiliza un enfoque de clustering jerárquico, que identifica formas de clúster intrincadas y maneja eficazmente los valores atípicos. ****A diferencia de los algoritmos basados en centroides como k-means, CURE representa los clústeres utilizando múltiples puntos representativos. Estos puntos se desplazan hacia las medias de los clústeres con un factor de contracción fijo para crear representaciones de clúster resilientes.
CURE demuestra una mayor flexibilidad que k-means porque su diseño le permite trabajar con varios tipos de conjuntos de datos irregulares. Su capacidad para superar las limitaciones de los algoritmos tradicionales con respecto a clústeres convexos o equidistantes conduce a la detección precisa de los límites y formas de los clústeres.
Cómo funciona
Los algoritmos CURE implican múltiples pasos para producir el resultado final. Descubramos cómo seleccionan datos para crear un clúster libre de valores atípicos.
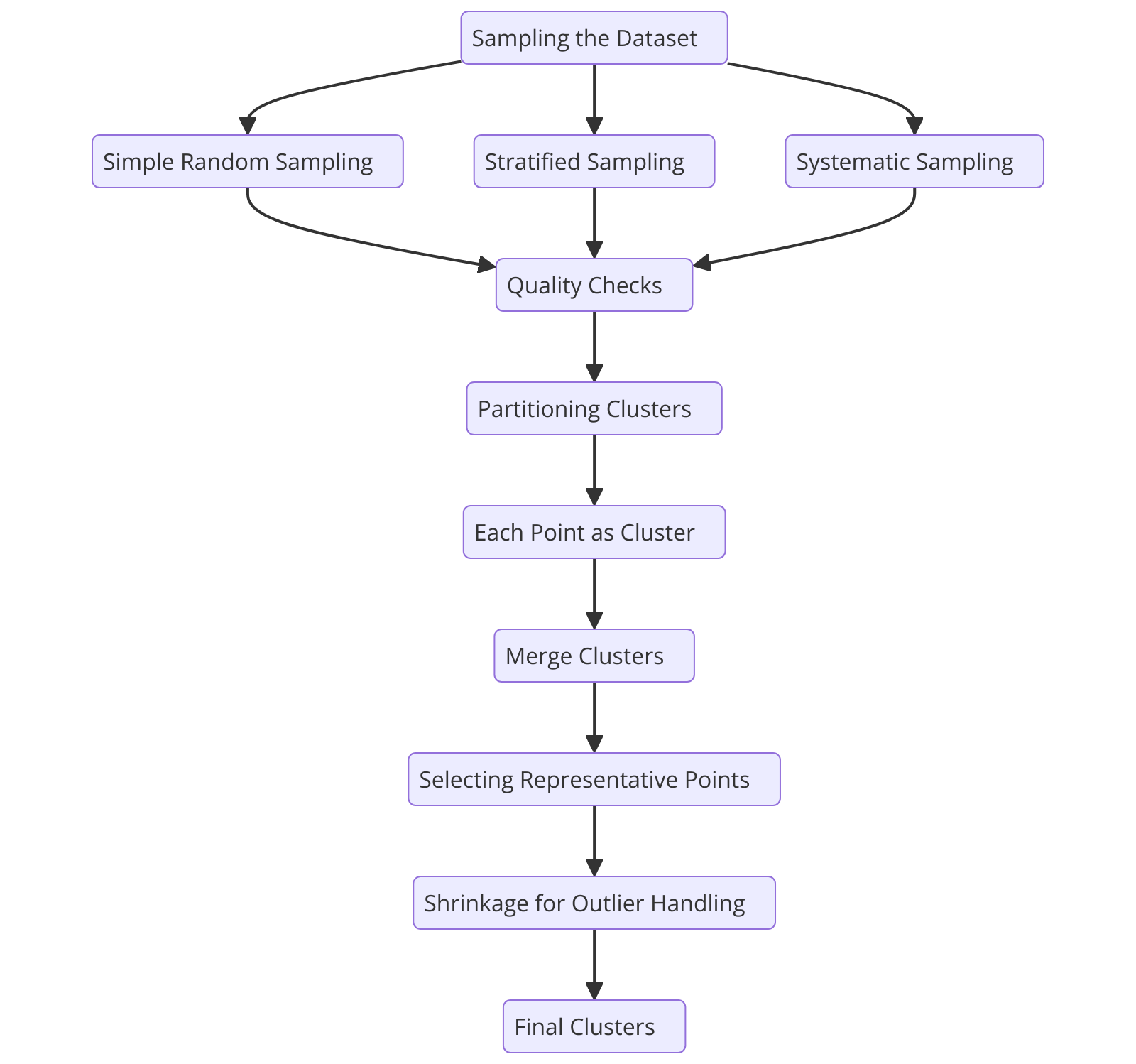 Flujo del proceso del algoritmo de clustering CURE
Flujo del proceso del algoritmo de clustering CURE
Figura 2: Flujo del proceso del algoritmo de clustering CURE
Flujo del proceso del algoritmo de clustering CURE
Para entender cómo funciona el algoritmo CURE, desglosamos su proceso paso a paso, empezando por el muestreo del conjunto de datos.
Muestreo del conjunto de datos
CURE comienza seleccionando una muestra aleatoria representativa del conjunto de datos. El proceso de muestreo reduce el número de puntos de datos, acelerando la velocidad de cálculo mientras mantiene la integridad del clúster.
El muestreo aleatorio simple ofrece una implementación rápida, pero no logra captar casos límite cruciales. Esto produce una representación inadecuada de grupos minoritarios en conjuntos de datos desequilibrados. El muestreo estratificado se vuelve necesario cuando se necesita mantener la distribución proporcional de las diferentes clases en los datos.
Este método garantiza que todos los subconjuntos pequeños significativos de datos sigan siendo visibles para el análisis. Otro método es el muestreo sistemático, que elige puntos de datos mediante un sistema de intervalos regulares. El muestreo sistemático destaca en series temporales y datos ordenados, ya que conserva la naturaleza temporal y el patrón de orden secuencial en los conjuntos de datos.
Las verificaciones de calidad comprueban la coherencia de la muestra con la distribución del conjunto de datos original después de la recopilación. Comparar valores medios, niveles de varianza y características de distribución ayuda a evaluar las similitudes entre la muestra obtenida y el conjunto de datos original completo. Las estrategias rigurosas de muestreo implementadas por CURE permiten que el clustering posterior represente con precisión la complejidad y diversidad de todo el conjunto de datos.
Partición de clústeres
Después de muestrear el conjunto de datos, CURE aplica un método jerárquico que divide los datos en subconjuntos manejables. En particular, utiliza una estrategia de fusión ascendente para la agrupación en clústeres. El algoritmo mide las similitudes de los puntos de datos mediante métricas de distancia que utilizan la distancia euclidiana o la distancia de Manhattan. Las métricas de cálculo de distancia son esenciales para determinar la proximidad de los puntos mientras se establece una base sólida para una fusión eficaz de clústeres.
Al comienzo del proceso, cada punto de datos funciona como su propio clúster para representar la naturaleza detallada de los datos. El algoritmo realiza fusiones sucesivas de clústeres utilizando estándares de proximidad para agrupar puntos similares. El algoritmo continúa con las operaciones de fusión de clústeres hasta que se alcanza un número definido de clústeres o se activa una condición alternativa de terminación.
El proceso de selección de grupos en CURE crea clústeres que se alinean con las categorías naturales presentes en los datos. Al usar partición jerárquica, CURE supera las limitaciones de los algoritmos tradicionales de agrupación en clústeres que requieren que los clústeres tengan formas convexas.
Selección de puntos representativos
CURE selecciona múltiples puntos representativos para representar cada clúster en lugar de depender de un único centroide. Estos puntos, cuidadosamente elegidos del clúster, capturan su rango espacial y estructura. CURE logra un mejor reconocimiento de los límites de los clústeres y una mejor comprensión de la estructura interna al usar múltiples puntos para representar cada clúster.
Después de seleccionar los puntos representativos, el algoritmo los mueve hacia la media del clúster con una cantidad de contracción especificada. El procedimiento de contracción hace que el algoritmo sea menos reactivo a los valores atípicos al mover puntos distantes hacia los puntos centrales del clúster.
El éxito del algoritmo depende en gran medida de cuántos puntos representativos se utilizan durante la ejecución. La selección adecuada de puntos representativos es crucial. Usar pocos puntos representativos puede no capturar la complejidad del clúster, mientras que usar demasiados puede aumentar los costos computacionales.
Fusión de clústeres
Después de identificar los puntos representativos, el algoritmo fusiona clústeres utilizando un enfoque iterativo sistemático. El procedimiento depende de medir la distancia entre los puntos representativos de diferentes clústeres. Se utilizan métricas predefinidas, como la distancia euclidiana, para medir distancias, eliminando así conflictos al encontrar los clústeres más cercanos.
El algoritmo identifica qué pares de clústeres tienen la menor distancia a partir de la separación de los puntos representativos durante cada paso de evaluación. El algoritmo toma decisiones precisas de fusión de clústeres mientras preserva las relaciones espaciales y los patrones de alineación natural de los datos dentro de los clústeres.
El proceso itera hasta que se logran algunos clústeres predeterminados o se cumple otro criterio de terminación. El criterio de terminación depende de factores como la distancia mínima entre clústeres o la similitud máxima permitida dentro de los clústeres. Esto asegura que los clústeres producidos correspondan a las agrupaciones naturales en los datos y sean lo suficientemente flexibles para capturar formas irregulares y complejas.
Manejo de valores atípicos
Cuando existen valores atípicos, los resultados se distorsionan porque causan formas incorrectas de los clústeres y una interpretación errónea de la estructura de los datos. El algoritmo CURE resuelve estas limitaciones utilizando múltiples puntos representativos, que identifican con precisión la forma y distribución reales de los clústeres.
El mecanismo de contracción representa otro avance fundamental en CURE, haciendo que el sistema sea más resiliente y aumentando su sofisticación. Este ajuste deliberado disminuye la sensibilidad del algoritmo a valores extremos, moviendo los puntos representativos hacia las posiciones centrales del clúster.
El factor de contracción es un parámetro de ajuste que permite a los usuarios personalizar su valor según las características del conjunto de datos. Esto permite una mitigación flexible de valores atípicos mientras se preservan los límites naturales de los clústeres.
Comparación con otros métodos de agrupación en clústeres
El enfoque innovador del algoritmo CURE lo distingue de otras técnicas populares de agrupamiento. Aquí tienes una comparación más profunda:
| Aspecto | CURE | k-means | DBSCAN |
| Representación | Múltiples puntos representativos | Centroide único | Basado en densidad |
| Manejo de valores atípicos | Excelente | Deficiente | Bueno |
| Flexibilidad de forma | Formas arbitrarias | Solo formas convexas | Formas arbitrarias |
| Escalabilidad | Alta (con muestreo) | Alta | Moderada |
| Complejidad | Mayor | Menor | Moderada |
Beneficios y desafíos
Cuando se aplica a escenarios del mundo real, CURE ofrece una combinación de ventajas y desafíos. Analicemos cómo CURE puede aportar valor y, al mismo tiempo, presentar ciertos obstáculos en aplicaciones prácticas.
Beneficios
Escalabilidad: CURE logra escalabilidad mediante su estrategia de muestreo de datos, que reduce las cargas de trabajo computacionales sin comprometer la precisión de los clústeres.
Robustez: CURE aumenta la robustez al usar múltiples puntos representativos para capturar la forma y estructura de un clúster. Así, el agrupamiento producirá resultados fiables y estables incluso cuando los datos sean ruidosos e inconsistentes.
Versatilidad: CURE captura clústeres de cualquier forma y maneja irregularidades o estructuras no convexas. Esto es particularmente útil en conjuntos de datos diversos, donde las técnicas tradicionales como k-means no logran representarlos con precisión.
Desafíos
Sensibilidad a los parámetros: El algoritmo requiere un ajuste preciso de los parámetros para el factor de contracción y el número de puntos representativos. Encontrar el equilibrio adecuado es crucial para un rendimiento óptimo, lo que requiere tanto experimentación como experiencia en el dominio.
Sesgo de muestreo: Las técnicas de muestreo insuficientes producen una formación de clústeres inexacta y resultados deficientes. Mantener muestras representativas sin sesgo es esencial para garantizar que las estructuras del conjunto de datos permanezcan intactas.
Demandas computacionales: Los desafíos de escalabilidad de CURE aumentan con conjuntos de datos grandes, de alta dimensionalidad o no estructurados debido a la necesidad de múltiples evaluaciones de distancia. Técnicas como PCA y la computación paralela pueden reducir la dimensionalidad, disminuyendo los costos computacionales mientras preservan las relaciones clave.
Casos de uso
Para ver el impacto práctico del algoritmo CURE, repasemos cómo puede resolver desafíos de agrupamiento del mundo real en varios dominios.
Detección de anomalías
CURE identifica eficazmente anomalías agrupando transacciones típicas y aislando las irregulares que pueden indicar fraude. Esto permite a las instituciones financieras detectar rápidamente actividades sospechosas y mejorar sus medidas de seguridad.
Segmentación de mercado
En marketing, CURE puede segmentar clientes en función de atributos como el comportamiento de compra, la demografía y las preferencias. Esto permite campañas de marketing dirigidas, mejora la retención de clientes y predice tendencias futuras. Por ejemplo, los clientes de alto valor pueden agruparse para ofertas exclusivas con el fin de aumentar la fidelidad.
Análisis de datos geoespaciales
Los urbanistas pueden implementar CURE para categorizar regiones con climas, densidades de población o desarrollos de infraestructura similares. Los científicos ambientales pueden usarlo para agrupar áreas según su biodiversidad y disponibilidad de recursos mientras estudian ecosistemas.
Agrupamiento de documentos
CURE demuestra una excelente eficacia en la minería de texto al agrupar extensos catálogos de documentos en función de sus temas y asuntos estándar. Los motores de búsqueda utilizan este método para crear categorías de resultados precisas que permiten a los usuarios encontrar contenido relevante rápidamente.
CURE permite a los sistemas de recomendación identificar artículos y trabajos de investigación con temas similares. Esto da como resultado recomendaciones personalizadas y significativas para los usuarios. CURE puede agrupar eficazmente diversas estructuras de texto para mantener resultados de agrupación precisos independientemente de la complejidad y el tamaño de los conjuntos de datos de alta dimensionalidad. El algoritmo se adapta bien a conjuntos de datos de texto multilingües y entradas de datos heterogéneas, lo que lo posiciona como una solución esencial para las plataformas contemporáneas de recuperación de información.
Conclusión
El algoritmo de agrupación CURE representa un gran avance en los métodos de agrupación. Ofrece una solución eficaz y escalable para los problemas de datos contemporáneos. El algoritmo utiliza puntos representativos junto con principios jerárquicos para superar las limitaciones de la agrupación tradicional, al tiempo que garantiza resultados flexibles y precisos. Aunque el algoritmo enfrenta desafíos relacionados con la optimización de parámetros y los requisitos computacionales, su capacidad para gestionar datos ruidosos y patrones complejos es esencial para múltiples sectores empresariales.
La creciente complejidad de los conjuntos de datos seguirá impulsando la necesidad de algoritmos de agrupación flexibles como CURE en el futuro. Los científicos de datos y los profesionales del aprendizaje automático que comprendan los principios de CURE podrán maximizar su potencial para generar información significativa a partir de conjuntos de datos complejos.
Preguntas frecuentes
- ¿Qué hace que CURE sea único en comparación con k-means?
CURE se distingue de k-means al utilizar múltiples puntos representativos en lugar de un único centroide de clúster. El método permite la detección de formas de clúster irregulares y patrones no lineales en conjuntos de datos complejos sin requerir supuestos de clústeres convexos.
- ¿Cómo maneja CURE conjuntos de datos grandes?
CURE gestiona conjuntos de datos grandes mediante técnicas de muestreo aleatorio que minimizan los requisitos de procesamiento computacional. La estrategia de muestreo permite al algoritmo procesar subconjuntos de datos reducidos, preservando la integridad de las relaciones entre clústeres.
- ¿Cuál es el papel del factor de contracción en CURE?
El factor de contracción de CURE controla la distancia a la que los puntos representativos se desplazan hacia la posición media de su clúster. Este factor permite a los usuarios lograr resultados óptimos entre precisión y robustez. El éxito de las implementaciones de CURE depende en gran medida de descubrir el factor de contracción correcto para cada conjunto de datos.
- ¿Puede CURE funcionar con datos de alta dimensionalidad?
El uso de algoritmos CURE en datos de alta dimensionalidad requiere un preprocesamiento previo mediante técnicas como PCA. El procesamiento de datos de alta dimensionalidad requiere una reducción de dimensiones eficiente para encontrar patrones esenciales incluso manteniendo la simplicidad de los datos.
- ¿Cuáles son las aplicaciones típicas de CURE?
Las aplicaciones típicas de CURE incluyen la detección de anomalías, la segmentación de mercado, el análisis geoespacial y el análisis de agrupación de documentos. Puede identificar patrones financieros inusuales para la detección de fraudes, agrupar clientes por comportamiento y analizar regiones en función de sus características.
Recursos relacionados
https://zilliz.com/ai-faq/how-are-embeddings-used-for-clustering
https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search
https://zilliz.com/ai-faq/how-does-swarm-intelligence-improve-data-clustering
https://zilliz.com/ai-faq/what-is-graph-clustering-in-knowledge-graphs
https://zilliz.com/ai-faq/what-are-the-most-common-algorithms-for-anomaly-detection
- Comprender el algoritmo CURE: una exploración completa del clustering con representantes
- ¿Qué es el algoritmo CURE?
- Cómo funciona
- Flujo del proceso del algoritmo de clustering CURE
- Comparación con otros métodos de agrupación en clústeres
- Beneficios y desafíos
- Casos de uso
- Conclusión
- Preguntas frecuentes
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis