




Deja de crear infraestructura de datos de IA para la etapa equivocada
La mayoría de las decisiones de infraestructura de IA se toman en la primera semana y se lamentan al mirar atrás en el segundo año.
El problema casi nunca es el modelo, y rara vez la lógica de la aplicación. Siempre vuelve a lo mismo: la infraestructura de datos debe construirse para la etapa en la que se encuentra el equipo.
En cada etapa, el modo de fallo va en ambas direcciones. Sobredimensiona demasiado pronto y te ralentizas. Subestima, y reconstruyes bajo presión. Ambos crean el mismo resultado: una sobrecarga de iteración que se acumula.
Etapa 1: El prototipo — Simplemente haz que funcione
Al principio, la velocidad importa mucho más que la infraestructura de datos — o, en realidad, no hay necesidad de una supuesta "infraestructura de datos" en absoluto.
El objetivo no es la escalabilidad. El objetivo no es la gobernanza. El objetivo no es la optimización.
El objetivo es simplemente hacer que la aplicación funcione.
El error más común en esta etapa es confundir sofisticación con calidad. Los equipos añaden pipelines de ingesta en streaming antes de tener documentos que ingerir. Configuran replicación de nivel de producción antes de tener un solo usuario real. Se preocupan por la consistencia de datos entre múltiples sistemas antes de tener suficientes datos como para que la consistencia importe.
El resultado: semanas de trabajo de infraestructura que podrían haberse enviado como un simple cambio de idea.
En cuanto al tema candente "base de datos vectorial", apenas importa. Milvus, Elasticsearch, pgvector, o incluso una biblioteca de búsqueda ligera — cualquiera de ellas hará el trabajo. La brecha de calidad de recuperación entre opciones es insignificante comparada con la brecha entre tener un prototipo funcional y no tenerlo.

Lo que realmente necesitas en esta etapa:
- Tu sistema de archivos local
- Cualquier base de datos o biblioteca de búsqueda ligera
Etapa 2: Ajuste producto-mercado — Más bases de datos, peores problemas
Una vez que los usuarios reales empiezan a interactuar con el sistema, el foco pasa de construir una demo a mejorar continuamente el producto, pero aparece una trampa diferente.
La idea equivocada suena razonable: más tipos de bases de datos especializadas conducen a una mejor calidad de recuperación.
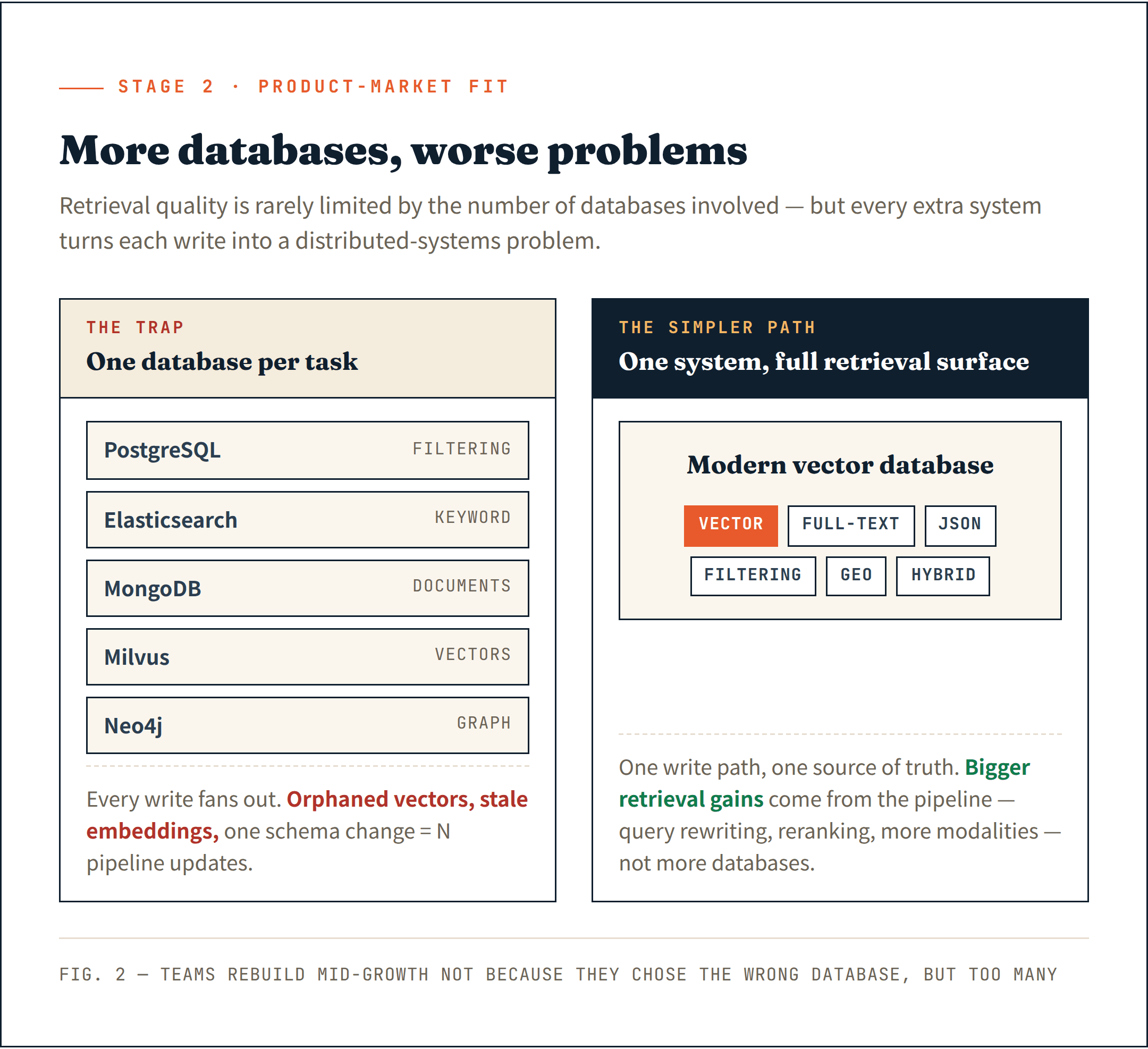
Algunos equipos empiezan a ensamblar un sistema por cada tarea de recuperación — PostgreSQL para filtrado, Elasticsearch para búsqueda por palabras clave, MongoDB para documentos, Milvus para vectores y Neo4j para relaciones de grafos. La pila de recuperación crece más rápido que el propio producto.
Entonces llega el problema de sincronización.
Los documentos viven en un sistema. Los embeddings en otro. Los metadatos en un tercero. Cada operación de escritura se convierte en un problema de sistemas distribuidos. Una eliminación fallida deja vectores huérfanos. Una inserción parcial crea embeddings obsoletos. Un cambio de esquema requiere actualizar múltiples pipelines a la vez.
La lección difícil: la calidad de recuperación rara vez está limitada por la cantidad de bases de datos involucradas.
Las mayores mejoras provienen del propio pipeline de recuperación — reescritura dinámica de consultas, búsqueda iterativa, divulgación progresiva, mejor reranking. En el lado de los datos, añadir otro campo de embedding u otra modalidad con frecuencia mejora la calidad de recuperación más que añadir otra base de datos especializada.
Las bases de datos vectoriales modernas se han expandido silenciosamente mucho más allá de los vectores. Búsqueda de texto completo, filtrado JSON, búsqueda geoespacial y recuperación híbrida — la mayoría de los sistemas maduros ahora admiten esto de forma nativa. La suposición de una base de datos especializada por tarea está cada vez más obsoleta.
Un único sistema que gestione toda la superficie de recuperación es más simple de operar y proporciona una base más limpia para lo que viene después.
He visto demasiados equipos obligados a reconstruir su infraestructura de datos en pleno crecimiento — no porque eligieran la base de datos equivocada, sino porque eligieron demasiadas.
Lo que realmente necesitas en esta etapa:
- Un servicio de base de datos administrado: deja que el proveedor se encargue de la fiabilidad mientras tú te concentras en el producto
- Un único sistema con amplio soporte semántico: vectorial, texto completo, JSON, filtrado, híbrido; no una base de datos por tarea
- Suficiente margen para crecer hasta el siguiente orden de magnitud sin reconstruir
Etapa 3: Crecimiento a escala — No todas las cargas de trabajo deberían compartir el mismo cómputo
Esta es la etapa en la que la presión de costes se vuelve innegable. La razón es simple: los datos siempre crecen más rápido que tus ingresos.
El error más común: suponer que la solución de base de datos tradicional que te trajo hasta aquí te llevará más lejos.
A diferencia de la Etapa 2, en este punto no hay margen fácil para reconstruir. Una migración de infraestructura a gran escala bajo presión de crecimiento es extremadamente cara, extremadamente arriesgada, o ambas cosas.
La decisión correcta es ponerlo todo en almacenamiento de objetos (como S3), no solo como almacén persistente, sino como la capa base de tu arquitectura de recuperación. Es la opción más barata, más duradera y más escalable que existe. Trátala como la base, no como algo secundario.
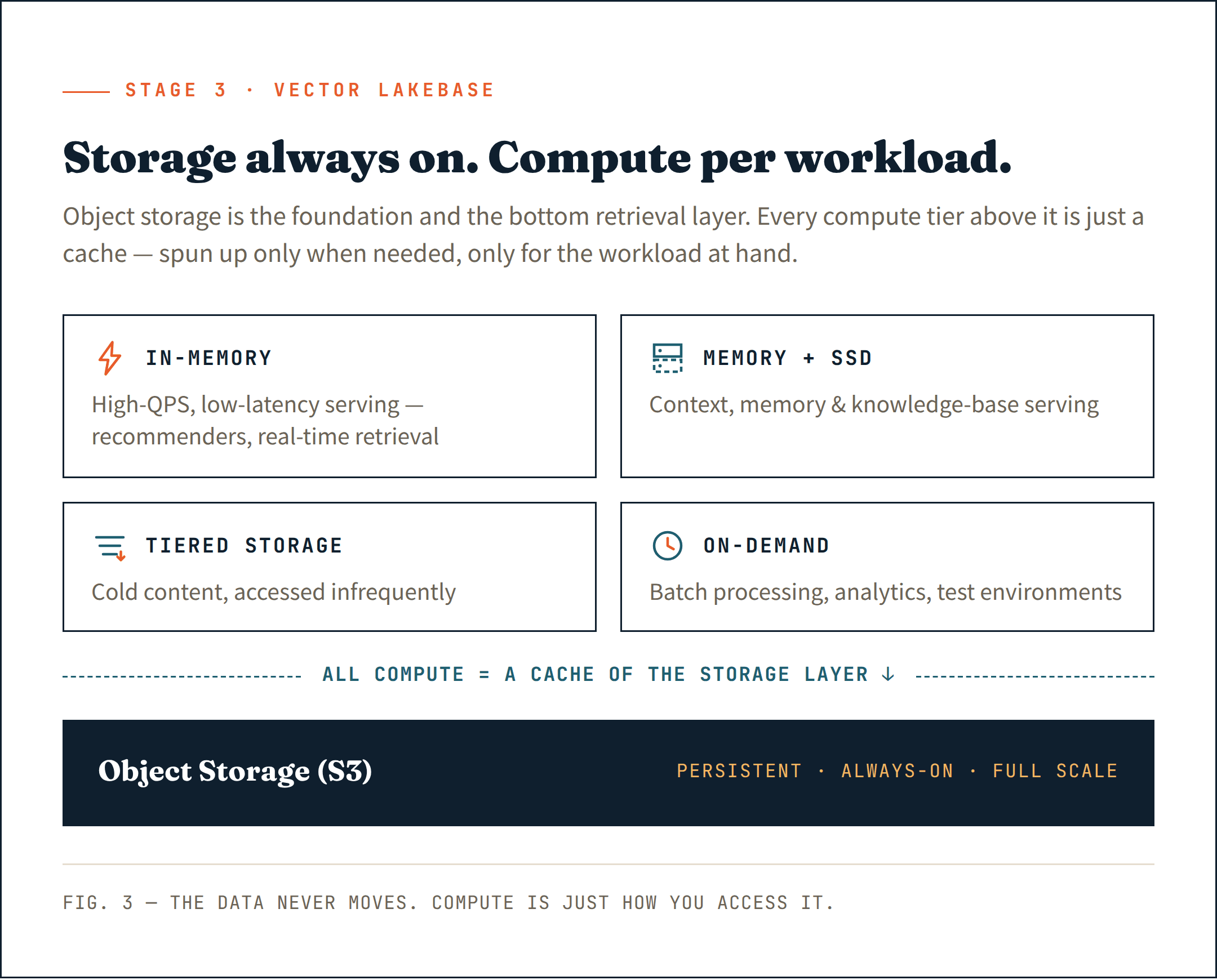
Por encima de esa capa, incorpora cómputo solo donde sea realmente necesario. Clústeres de larga duración para servir con sensibilidad a la latencia. Recursos de cómputo efímeros para ingesta e indexación. Cómputo bajo demanda para análisis y trabajos por lotes. Cada carga de trabajo recibe el cómputo que necesita, y nada más.
Esta es la esencia de una Vector Lakebase: almacenamiento que está siempre activo a escala completa, cómputo que no lo está: se pone en marcha solo cuando se necesita, solo para la carga de trabajo en cuestión.
Lo más importante es que todo el cómputo, ya sea de larga duración o bajo demanda, actúa como caché de la capa de almacenamiento de objetos. Los datos siempre viven en el almacenamiento. El cómputo es solo la forma en que accedes a ellos.
Ajusta cada carga de trabajo al nivel de cómputo adecuado:
- En memoria para cargas de trabajo de alto QPS y baja latencia: sistemas de recomendación de IA, recuperación en tiempo real
- Memoria + SSD para servir contexto, memoria y bases de conocimiento
- Almacenamiento por niveles para contenido frío al que se accede con poca frecuencia
- Cómputo bajo demanda para procesamiento por lotes, analítica interna y entornos de prueba
Hecho correctamente, este enfoque reduce los costes de infraestructura en un 50% o más en comparación con un diseño unificado, al tiempo que ofrece una calidad de servicio mucho mejor para cada carga de trabajo.
Las soluciones serverless a menudo se desmoronan en esta etapa, no técnicamente, sino económicamente. Una vez que tus datos alcanzan los terabytes, los costes de inserción y almacenamiento comienzan a dominar. La razón es estructural: las arquitecturas serverless agrupan la sobrecarga de pooling, la indexación y los costes de datos persistentes en recargos de escritura y almacenamiento. Ya no estás pagando por lo que usas. Estás pagando por la abstracción.
El primer principio para la infraestructura de datos en esta etapa es sencillo: tu base debe escalar con tus datos, no contra ellos. Una arquitectura obligada a servir a todas las cargas de trabajo igual de bien termina sin servir bien a ninguna, y el coste de ese compromiso se acumula con cada gigabyte que añades.
Lo que realmente necesitas en esta etapa:
- Almacenamiento de objetos (S3) como base y capa inferior de recuperación: persistente, siempre activo a escala completa, la capa desde la que lee todo el cómputo
- Una Vector Lakebase: datos que nunca se mueven, cómputo que se activa por carga de trabajo y nada más
- El nivel de cómputo adecuado por tipo de carga de trabajo
Etapa 4: Escala empresarial — La confianza se convierte en parte del producto
En esta etapa, la mayoría de los equipos creen que la parte difícil ha quedado atrás. No es así.
El error común: los equipos siguen pensando que el problema es técnico.
Han optimizado la infraestructura. Han controlado los costes. Suponen que escalar a nivel empresarial es cuestión de añadir capacidad y marcar una casilla de seguridad.
No lo es.
Las preguntas que bloquean acuerdos empresariales no tienen nada que ver con el rendimiento:
¿Cómo se aíslan nuestros datos de los de otros clientes?
¿Quién tiene acceso a qué, y pueden demostrarlo?
¿Pueden prestarnos servicio en nuestra región?
¿Podemos desplegar esto dentro de nuestra propia cuenta en la nube?
Pero los requisitos individuales de cada acuerdo son solo una parte del problema. En la Etapa 3, la falta de homogeneidad era técnica: diferentes cargas de trabajo, diferentes niveles de cómputo. En esta etapa, es estructural: tu base de clientes requiere infraestructura de datos a nivel de plataforma para gestionarla.
Tienes usuarios gratuitos que necesitan un servicio compartido rentable. Tienes clientes individuales de pago que esperan una mayor disponibilidad. Tienes clientes empresariales que requieren aislamiento completo de datos, cómputo dedicado y la capacidad de auditarlo todo. Servir a los tres desde la misma arquitectura significa que estás gastando de más en tu nivel gratuito, atendiendo insuficientemente a tus clientes empresariales, o ambas cosas.
La respuesta correcta es una infraestructura por niveles alineada con cada segmento de clientes:
- Clústeres compartidos para usuarios gratuitos e individuales: agrupados, optimizados en costes
- Clústeres aislados por cliente empresarial: cómputo dedicado, almacenamiento dedicado, controles de acceso dedicados
- BYOC para clientes que requieren despliegue dentro de su propia cuenta en la nube

El punto de BYOC es donde la mayoría de los equipos comete un error crítico. SaaS y BYOC parecen dos productos. Si se bifurcan a nivel de arquitectura, estás manteniendo dos bases de código, dos pipelines de despliegue y dos runbooks operativos, indefinidamente. Los equipos que acertaron trataron BYOC como un modelo de despliegue en lugar de como un producto separado. El mismo plano de datos, la misma interfaz de control, un objetivo de despliegue diferente.
La fiabilidad global es la otra pieza que se pospone durante demasiado tiempo. A escala empresarial, las múltiples regiones no son una característica premium: son una expectativa básica. Los clientes empresariales de distintas geografías no tolerarán un despliegue en una sola región, ni aceptarán tus compromisos de SLA. Sin una interfaz unificada de infraestructura de datos entre nubes y regiones, acabas operando diferentes capas de datos en diferentes entornos: la sincronización de datos en tiempo real se convierte en su propio problema de sistemas distribuidos, y la complejidad operativa se acumula con cada nueva región que añades.
Los equipos con los que hablé que habían alcanzado acuerdos empresariales importantes describieron el mismo descubrimiento doloroso: nada de esto se había diseñado desde el principio. Se había añadido después, bajo la presión de un ciclo de ventas en marcha. Un equipo pasó cuatro meses incorporando aislamiento a nivel de datos en una arquitectura que no se había construido para ello. Lo lanzaron. Pero sabían exactamente por qué era frágil.
La preparación para la empresa no es una lista de verificación. Es una consecuencia de decisiones arquitectónicas tomadas mucho antes.
Lo que realmente necesitas en esta etapa:
- Una interfaz unificada de infraestructura de datos: consistente entre nubes, consistente entre regiones
- Clústeres globales diseñados para alta fiabilidad y servicio multirregión
- Servicio por niveles: clústeres compartidos para usuarios gratuitos, clústeres aislados por cliente empresarial
- SaaS y BYOC sobre la misma arquitectura: un plano de datos, diferentes objetivos de despliegue
- Estándares abiertos y código abierto en la base: sin dependencia de un proveedor a escala empresarial
Lo que tienen en común los equipos que escalaron bien
El patrón es consistente.
Cada etapa introduce una clase de problema completamente diferente. La Etapa 1 es un problema de velocidad. La Etapa 2 es un problema de complejidad. La Etapa 3 es un problema de costes y arquitectura. La Etapa 4 es un problema de confianza y plataforma.

Los equipos que navegaron cada etapa sin una reconstrucción dolorosa entendieron esto pronto. Dejaron de preguntarse "¿qué base de datos necesito ahora mismo?" y empezaron a preguntarse "¿qué requerirá la siguiente etapa, y mi decisión actual cierra esa puerta?"
En la Etapa 1, una base de datos vectorial es exactamente la herramienta adecuada. Lo digo sin reservas.
En la Etapa 3 y más allá, lo que se vuelve necesario es algo de una naturaleza diferente: un Vector Lakebase. Almacenamiento siempre activo a escala completa. Cómputo adaptado a cada carga de trabajo. Una plataforma que pueda atender a un usuario gratuito, un cliente de pago y una cuenta empresarial desde la misma arquitectura, sin bifurcarse.
Los equipos que llegaron allí más rápido no eran más inteligentes ni contaban con más financiación.
Simplemente entendieron, antes, que la decisión de infraestructura no era una elección temporal.
Era la base sobre la que se construiría todo lo demás.
Zilliz Vector Lakebase está disponible en versión preliminar pública
Hemos lanzado la versión preliminar pública de Zilliz Vector Lakebase — una gran evolución de Zilliz Cloud, de una base de datos vectorial gestionada a una plataforma unificada de datos semánticos que combina la base de datos vectorial de producción con una base de datos compartida, nativa de lake.
Capacidades principales de Zilliz Vector Lakebase:
- Servicio por niveles optimizado para diferentes compensaciones entre rendimiento en tiempo real y coste
- Búsqueda bajo demanda para cargas de trabajo a gran escala o exploratorias sin cómputo siempre activo
- Búsqueda en data lakes externos: indexa y busca directamente sobre tus datos de lake existentes
- Búsqueda de espectro completo en vectores, texto, JSON y datos geoespaciales con recuperación híbrida y reordenamiento
- Almacenamiento unificado nativo de lake construido sobre Vortex, un formato abierto con lecturas aleatorias más rápidas y económicas que Lance o Parquet
Si tu stack actual divide el servicio y el descubrimiento en sistemas separados, podría valer la pena echar un vistazo a Vector Lakebase. Pruébalo en Zilliz Cloud — los nuevos registros con correo electrónico de trabajo reciben $100 en créditos gratis — o habla con nosotros sobre tu caso de uso.
Más información sobre Vector Lakebases
- De Vector Database a Vector Lakebase
- Pasamos 8 años haciendo que las bases de datos vectoriales fueran más rápidas. Luego nos detuvimos.
- Por qué creamos Vector Lakebase: repensando la arquitectura de datos no estructurados para la IA
- Vector Lakebase: acaba con el silo de datos de IA
- Zilliz Cloud On-Demand Compute: paga solo por lo que usas
- La búsqueda vectorial de Notion es excelente. Su próximo problema es más difícil.

Sigue leyendo

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.