




Read AI skaliert konversationelle Intelligenz mit Milvus für Millionen aktiver Nutzer

Unter 20-50ms
Abruflatenz für Millionen monatlicher Nutzer
5-fache Beschleunigung
in der agentischen Suche
Millionenmaßstab
Unterstützung für aktive Mandanten
Verbesserte Benutzererfahrung
indem eine Verlagerung von reaktiver zu proaktiver Suche vorangetrieben wird
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Zusammenfassung
Read AI benötigte eine leistungsstarke Vektordatenbank, um Retrieval im Unternehmensmaßstab aus unstrukturierten Kommunikationsquellen zu unterstützen, darunter Meetings, Chats, E-Mails und interne Wissensdatenbanken. Durch die Einführung von Milvus als Rückgrat seiner semantischen Suchinfrastruktur konnte Read AI narrative, reichhaltige Embeddings in großem Maßstab indexieren und abfragen und so schnelle, präzise Retrievals über Milliarden von Datensätzen hinweg ermöglichen.
Retrieval-Latenz von unter 20–50 ms für Millionen monatlicher Nutzer
Hochgradig skalierbar, um Millionen aktiver Mandanten zu bewältigen
Erhebliche Produktivitätsgewinne für Entwickler
„Wir haben Millionen monatlich aktive Nutzer und all die zugrunde liegenden Daten, wenn wir versuchen, verwandte Gespräche zu finden, Aktualisierungen zu einem Action Item zu finden, referenzierte Dokumente zu finden ... Milvus dient als zentrales Repository und treibt unser Information Retrieval über Milliarden von Datensätzen hinweg an.“--Rob Williams, Mitgründer und CTO bei Read AI
Über Read AI
Read AI ist ein führendes Produktivitäts-KI-Unternehmen, das Millionen von Menschen dabei hilft, mehr Zeit für die Arbeit aufzuwenden, die am wichtigsten ist. Ursprünglich darauf ausgerichtet, Meeting-Müdigkeit zu reduzieren, hat sich das Unternehmen zu einer Full-Stack-Intelligence-Plattform entwickelt, die außerdem prädiktive nächste Schritte, Unternehmenssuche und Echtzeit-Coaching bietet und sich nahtlos in Tools über Kalender (Google Calendar, Outlook 365, Zoom Calendar), CRMs (Salesforce, HubSpot), Kollaborationsplattformen (Jira, Confluence, Notion), Messaging-Apps (Slack, Microsoft Teams), Notiztools (Google Docs, OneNote), E-Mail (Gmail, Outlook) und Videokonferenzen (Zoom, Google Meet, Microsoft Teams) hinweg integriert. Sie erfasst und kontextualisiert Daten aus diesen Quellen und verwandelt passive Interaktionen in strukturierte, abfragbare und handlungsorientierte Narrative.
Mit einer Consumer-first-Denkweise entwickelt, unterstützt Read AI Millionen von Nutzern über ein Self-Service-Modell und arbeitet in echtem Internetmaßstab mit Milliarden von Gesprächsereignissen, die über zahllose Unternehmen hinweg verarbeitet werden.
Die technische Herausforderung
Aufgrund seines rasanten Wachstums stand Read AI vor einer grundlegenden Herausforderung bei der Organisation und dem Abruf unstrukturierter Kommunikationsdaten aus einer breiten Palette von Quellen – von Meetings und Chats bis hin zu CRM-Updates, Kalendern, E-Mail-Threads und Support-Tickets. Jede Quelle enthält wertvolle Signale, existiert jedoch in Silos, weist keine einheitliche Struktur auf und lässt sich nur schwer effektiv durchsuchen. Die Erwartung: intelligente, kontextbezogene Ergebnisse innerhalb von 20 Minuten nach jeder Interaktion liefern.
Dies erforderte eine nahezu echtzeitfähige Datenerfassung, -transformation und -indexierung über unterschiedliche Formate hinweg. Von gut strukturierten internen Meetings bis hin zu spärlichen Drittanbieterplattformen wie Slack, Gmail und HubSpot. Mit zunehmender Nutzung musste Read AI Milliarden von Datensätzen über Millionen von Mandanten hinweg, Tausende von Abfragen pro Sekunde und eine Latenz von unter 20–50 ms unterstützen. Frühere Lösungen, darunter intern entwickelte Stores und andere Vektordatenbanken wie Pinecone und Faiss, konnten diese Anforderungen aufgrund schlechter Unterstützung für Multi-Tenancy, begrenzter Filterfunktionen oder mangelnder Reaktionsfähigkeit der Community nicht erfüllen.
Die Lösungsarchitektur mit Milvus
Die neue Architektur von Read AI ist darauf ausgelegt, High-Throughput-Retrieval mit niedriger Latenz über unterschiedliche Kommunikationsquellen wie Slack, Zoom, E-Mail und Salesforce hinweg zu bewältigen. Diese Eingaben durchlaufen eine Embedding- und Narrationsebene, die Rohdaten in strukturierte Narrative und stimmungsbewusste Repräsentationen umwandelt. Alles wird in der Vektordatenbank Milvus gespeichert, die effektiv als zentrales Repository für die Informationen dient.
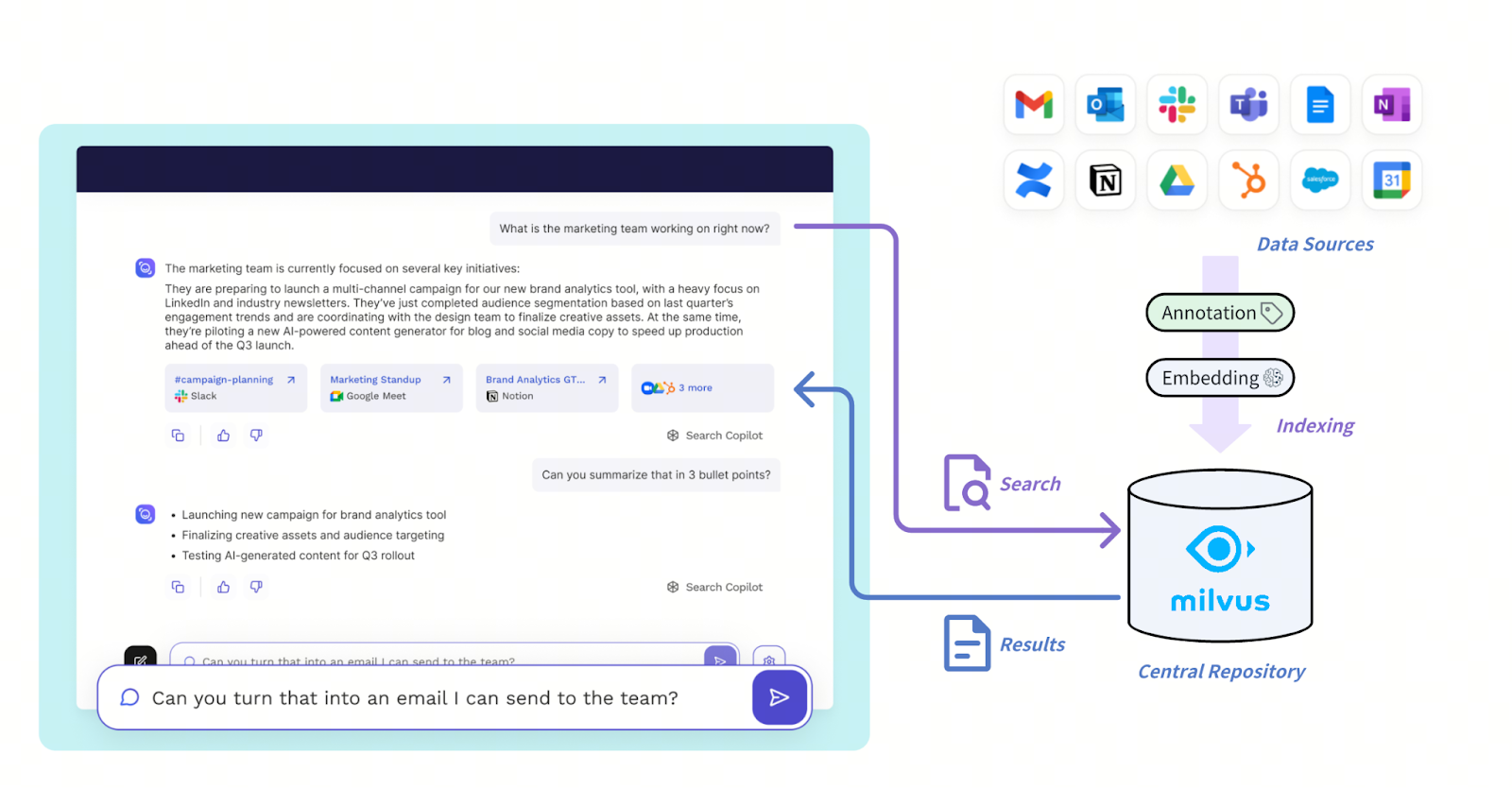 Die Lösungsarchitektur mit Milvus
Die Lösungsarchitektur mit Milvus
Abbildung: Wie Mivus das Read AI-System unterstützt
Read AI verwendet eine gefilterte Vektorsuche, die Vektorähnlichkeit mit Filterung auf Basis strukturierter Metadaten kombiniert, zum Beispiel durch die Eingrenzung von Abfragen auf Einzelgespräche, bestimmte Mitarbeitende oder Zeitfenster, und ermöglicht so eine nuancierte Abfrage wie „am wenigsten engagierte Vertriebsgespräche“ oder „positives Feedback in Einzelgesprächen“. Die optimierte Metadatenfilterung von Milvus ist entscheidend, um in diesem Maßstab eine Latenz von unter 20–50 ms zu erreichen.
„Milvus gibt uns eine narrativ-bewusste Speicherschicht — nicht nur Text-Embeddings, sondern eine vollständig kontextbewusste Suche.“ — Rob Williams, Co-Founder and CTO at Read AI
Dank der nativen Multi-Tenancy-Unterstützung in Milvus setzt Read AI einen einzigen Milvus-Cluster ein, um Millionen von Mandanten effizient zu bedienen. Abfragen werden über interne Agenten-Frameworks orchestriert, die die Suchintention analysieren und Anfragen an Milvus weiterleiten, um die Ergebnisse anschließend für die Bereitstellung über Chat-Oberflächen, Zusammenfassungen oder Benachrichtigungen nachzuverarbeiten. Diese Architektur gibt Read AI die Skalierbarkeit und Flexibilität, unterschiedliche Inhaltstypen zu vereinheitlichen und gleichzeitig Geschwindigkeit und Präzision aufrechtzuerhalten, die für Echtzeit-Abruf und retrospektive Analyse entscheidend sind.
Technische Bewertung & Entscheidungsprozess
Vor der Einführung von Milvus evaluierte das Read AI-Team mehrere Alternativen. FAISS wurde aufgrund fehlender integrierter Multi-Tenancy und begrenzter Filterfunktionen ausgeschlossen. Pinecone bot nicht die Flexibilität, die erforderlich war, um das Suchmuster und die Skalierung von Read AI zu unterstützen. Eine vollständig selbst gehostete, intern entwickelte Lösung wurde ebenfalls in Betracht gezogen, konnte jedoch die Skalierbarkeits- und Reifeanforderungen ihres Anwendungsfalls nicht erfüllen. Milvus stach aufgrund mehrerer Schlüsselfaktoren hervor:
Die Fähigkeit, auf Millionen von Nutzern und Milliarden von Datensätzen zu skalieren
Konstante Latenz von unter 20–50 ms bei großen Vektorsammlungen
Unterstützung für hybride Such-Workflows
Isolation auf Mandantenebene
Die Developer Experience war ein weiterer entscheidender Faktor, mit klarer Dokumentation, reaktionsschnellen Maintainern und praktischer Engineering-Unterstützung, insbesondere während ihres Proof-of-Concept. Die PoC-Phase zeigte eine schnelle Bearbeitung von Test-Workloads und bot Echtzeit-Debugging-Unterstützung durch das Milvus-Team, was Read AI das Vertrauen gab, in die Produktion überzugehen.
Ergebnisse und Vorteile der Wahl von Milvus
Seit der Bereitstellung von Milvus und parallel zur Einführung des Enterprise-Search-Tools Search Copilot durch das Unternehmen hat Read AI eine 5-fache Beschleunigung der agentischen Suche über verschiedene Datenquellen hinweg erreicht, bei gleichbleibender Abruflatenz von etwa 20–50 ms, selbst bei der Verarbeitung von Abfragen mit komplexen Filtern. Die Plattform nahm Millionen einzelner Nutzerkonten reibungslos in einen riesigen Cluster auf, ohne Unterbrechungen, und demonstrierte damit die Robustheit der verteilten Architektur und der Multi-Tenancy-Fähigkeit von Milvus.
Milvus betreibt eine einheitliche Suchschicht über alle Kommunikationskanäle hinweg—Meetings, Chat, E-Mail und CRM. Elastische Skalierung vereinfacht den Betrieb, um Enterprise-Kohorten oder Traffic-Spitzen zu bewältigen. Funktionen wie Bulk Import sorgen für eine reibungslose Erfahrung beim Onboarding großer Mengen historischer Daten, wenn sich neue Unternehmen für den Dienst anmelden.
Noch wichtiger ist, dass Milvus den Wandel von reaktiver zu proaktiver Suche ermöglicht: relevante Erkenntnisse, Aufgaben und Risiken werden angezeigt, bevor Nutzer überhaupt danach fragen, dank Vektorsuche mit niedriger Latenz über dynamische, multimodale Kontexte hinweg. Diese Fähigkeit verbessert nicht nur die Nutzererfahrung, sondern erschließt auch neue Geschäftsmöglichkeiten, während Read AI die Plattform weiterhin mit kontinuierlichen Fortschritten bei prädiktiven Empfehlungen und nächsten Schritten ausbaut.
„Was wir wollten, war, den Nutzern Intelligenz bereitzustellen, bevor sie überhaupt gefragt haben. Milvus hat das erst möglich gemacht.“ —Rob Williams, Co-Founder and CTO at Read AI
Diese technischen Erfolge führen direkt zu geschäftlichem Mehrwert: Nutzer der kostenlosen Version erhalten innerhalb weniger Minuten aussagekräftige Erkenntnisse, was die Kundenbindung stärkt, während Unternehmenskunden von tiefergehendem Wissensabruf und langfristigem Kontext profitieren, was das Vertrauen der Nutzer erhöht und Premium-Upsell-Möglichkeiten unterstützt.
Einblicke für Entwickler & Engineering
Erkenntnisse aus der Implementierung:
Strukturierte Annotationen können umfassendere nachgelagerte LLM-Ausgaben ermöglichen
Vektorsuche muss ihre Geschwindigkeit beibehalten, selbst mit strukturierter Metadatenfilterung, um mit der Sucherfahrung der Nutzer Schritt zu halten
Mandantenfähige Isolation und dynamische Skalierung sind im Consumer-Maßstab unverzichtbar
Das Team führt laufend Experimente durch und verfolgt Abfrageleistung, Nutzerzufriedenheit und Verhaltensmetriken, um kontinuierlich zu verfeinern, wie Agenten Ergebnisse suchen, filtern und ranken.
Read AI verarbeitet Konversationsdaten nicht nur mit Embedding-Modellen, sondern auch mit einer einzigartigen Narrationsebene. Diese semantische Abstraktion geht über Transkripte hinaus, um Tonfall, Absicht und wichtige Ereignisse wie Deal-Fortschritt oder nachlassendes Engagement zu erfassen. Dadurch können Nutzer natürlichsprachliche Narrative durchsuchen, etwa "wer während der Demo unbeteiligt war", anstatt nur Schlüsselwörter abzugleichen.
Roadmap
Mit Blick nach vorn konzentriert sich Read AI darauf, die Balance zwischen Echtzeit- und Offline-Workloads zu verbessern, mit Plänen, eine dynamischere Orchestrierung zwischen Live-Streaming-Daten und längerfristiger Speicherung aufzubauen. Sie untersuchen den Einsatz von Milvus’s kommendem Vector Lake, um Suchkosten zu senken, indem Offline-Abfragen mit weniger strengen Latenzerwartungen auf eine Warehouse-artige Ebene verlagert werden, die durch Objektspeicher unterstützt wird.
Ein weiterer zentraler Entwicklungsbereich ist die automatisierte Erkennung von Wissenslücken — also zu identifizieren, wenn kritische Informationen fehlen oder nicht verbunden sind — und Nutzern proaktiv Erkenntnisse bereitzustellen, bevor sie danach fragen. All diese Verbesserungen unterstützen die langfristige Vision von Read AI: eine “Action Engine” für das Unternehmen aufzubauen — eine kontextbewusste, stets aktive, KI-gestützte Plattform, die Wissensarbeiter über alle Kommunikationskanäle hinweg intelligent unterstützt.
Durch die Speicherung von Konversationskontext und historischen Erkenntnissen in Milvus erweitert Read AI die Verfügbarkeit institutionellen Wissens und stellt kritische Informationen bereit, selbst wenn der ursprüngliche Teilnehmer offline ist oder nicht mehr im Unternehmen arbeitet.
Fazit
Read AI’s Weg von einem Meeting-Analytics-Tool zu einer umfassenden Intelligence-Plattform für die breite Masse erforderte eine Infrastruktur, die massive Skalierung, heterogene Daten und komplexe Echtzeit-Abfrageanforderungen bewältigen kann. Milvus erwies sich als die richtige Wahl — nicht nur wegen seiner reinen Performance und Skalierbarkeit, sondern auch wegen seiner Flexibilität bei der Unterstützung annotierter Embeddings, Metadatenfilterung und mandantenfähiger Isolation.
Mit Milvus als Grundlage seiner Vektorsuchinfrastruktur liefert Read AI schnelle, zuverlässige und tief kontextbezogene Ergebnisse und Empfehlungen für Millionen von Nutzern. Während sie sich darauf zubewegen, eine stets aktive, intelligente Action Engine für das Unternehmen aufzubauen, unterstützt Milvus weiterhin ihren Bedarf an Kosteneffizienz, architektonischer Flexibilität und zukunftssicherer Skalierung und beweist damit, dass eine gut konzipierte Vektordatenbank mehr ist als nur Speicher; sie ist das Rückgrat modernen Informationsverständnisses.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams