




DiskANN: Eine festplattenbasierte ANNS-Lösung mit hohem Recall und hoher QPS auf einem Datensatz im Milliardenmaßstab
„DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node“ ist ein Paper, das 2019 auf der NeurIPS veröffentlicht wurde. Das Paper stellt eine State-of-the-Art-Methode vor, um Indexaufbau und Suche auf einem Datensatz im Milliardenmaßstab mit einer einzelnen Maschine mit nur 64GB RAM und einer ausreichend großen SSD durchzuführen. Darüber hinaus erfüllt sie die drei Anforderungen von ANNS (Approximate Nearest Neighbor Search) auf dem großskaligen Datensatz: hoher Recall, niedrige Latenz und hohe Dichte (Anzahl der Knoten in einer einzelnen Maschine). Diese Methode erstellt einen graphbasierten Index auf einem Datensatz im Milliardenmaßstab SIFT-1B mit einer einzelnen Maschine mit 64GB RAM und einer 16-Kern-CPU, erreicht 5000 QPS (queries per second) bei über 95 % recall@1 und eine durchschnittliche Latenz von weniger als 3ms.
Autoren
Suhas Jayaram Subramanya: Ehemaliger Mitarbeiter des Microsoft India Research Institute, Doktorand an der CMU. Die wichtigsten Forschungsinteressen sind Hochleistungsrechnen und Machine-Learning-Algorithmen für großskalige Daten.
Devvrit: Graduate Research Assistant an der The University of Texas at Austin. Seine Forschungsinteressen sind theoretische Informatik, Machine Learning und Deep Learning.
Rohan Kadekodi: Ein Doktorand an der University of Texas. Seine Forschungsrichtung ist System und Storage, hauptsächlich einschließlich persistenter Speicherung, Dateisystem und kV-Speicher.
Ravishankar Krishaswamy: Principal Researcher am Microsoft Indian Research Institute. Doktor der CMU. Die Forschungsrichtung ist der Approximationsalgorithmus auf Basis von Graphen und Clustering.
Harsha Vardhan Simhadri: Principal Researcher am Microsoft Indian Research Institute. Doktor der CMU. In der Vergangenheit untersuchte er parallele Algorithmen und Laufzeitsysteme. Jetzt besteht seine Hauptarbeit darin, neue Algorithmen zu entwickeln und Programmiermodelle zu schreiben.
Motivationen
Die meisten der gängigen ANNS-Algorithmen gehen einige Kompromisse zwischen Indexaufbauleistung, Suchleistung und Recall ein. Graphbasierte Algorithmen wie HNSW und NSG sind derzeit State-of-the-Art-Methoden in Bezug auf Suchleistung und Recall. Da die speicherresidente graphbasierte Indexierungsmethode zu viel Speicher belegt, ist es relativ schwierig, einen großskaligen Datensatz mit einer einzelnen Maschine mit begrenzten Speicherressourcen zu indexieren und zu durchsuchen.
Viele Anwendungen erfordern schnelle Antworten von auf euklidischer Distanz basierendem ANNS auf einem Datensatz im Milliardenmaßstab. Nachfolgend sind zwei Hauptlösungen aufgeführt:
Invertierter Index + Quantisierung: den Datensatz in M Partitionen zu clustern und den Datensatz mit Quantisierungsschemata wie PQ (Product Quantization) zu komprimieren. Diese Lösung erzeugt einen niedrigen Recall aufgrund eines Präzisionsverlusts, der durch Datenkompression verursacht wird. Eine Erhöhung von topk hilft, den Recall zu verbessern, während die QPS entsprechend sinken würde.
Aufteilen und indexieren: den Datensatz in mehrere disjunkte Shards aufzuteilen und für jeden Shard einen In-Memory-Index zu erstellen. Wenn Query-Anfragen eintreffen, wird die Suche auf den Indizes jedes Shards durchgeführt und die Ergebnisse werden nach dem Zusammenführen zurückgegeben. Diese Lösung verursacht eine Überexpansion des Datensatzumfangs, und daher werden aufgrund der Einschränkung der Speicherressourcen in einer einzelnen Maschine mehr Maschinen benötigt, was zu niedrigen QPS führt.
Beide oben genannten Lösungen sind durch die Speichereinschränkung einer einzelnen Maschine begrenzt. Dieses Paper schlägt das Design eines SSD-residenten Indexierungsmechanismus vor, um dieses Problem zu lösen. Die Herausforderung der SSD-residenten Indexierung besteht darin, die Anzahl zufälliger Festplattenzugriffe und die Anzahl der Anforderungen für Festplattenzugriffe zu reduzieren.
Beiträge
Dieses Paper präsentiert ein SSD-residentes ANNS-Schema namens DiskANN, das die Suche auf großskaligen Datensätzen effektiv unterstützen kann. Dieses Schema basiert auf einem graphbasierten Algorithmus, der in diesem Paper vorgestellt wird: Vamana. Zu den Beiträgen dieses Papers gehören:
DiskANN kann einen Datensatz im Milliardenmaßstab mit über 100 Dimensionen auf einer einzelnen Maschine mit 64GB RAM indexieren und durchsuchen und dabei über 95% recall@1 mit Latenzen unter 5 Millisekunden bereitstellen.
Ein neuer graphbasierter Algorithmus namens Vamana mit einem kleineren Suchradius als NSG und HNSW wurde vorgeschlagen, um die Anzahl der Festplattenzugriffe zu minimieren.
Vamana kann im Speicher arbeiten und seine Leistung ist nicht langsamer als die von NSG und HNSW.
Kleinere Vamana-Indizes, die auf überlappenden Partitionen des großen Datensatzes aufgebaut sind, können zu einem Graphen zusammengeführt werden, ohne die Konnektivität zu verlieren.
Vamana kann mit Quantisierungsschemata wie PQ kombiniert werden. Die Graphstruktur und die Originaldaten werden auf der Festplatte gespeichert, während komprimierte Daten im Speicher gehalten werden.
Vamana
Dieser Algorithmus ähnelt der Idee von NSG[2][4] (für diejenigen, die NSG nicht verstehen, siehe bitte Referenz [2], und wenn Sie keine Paper lesen möchten, können Sie Referenz [4] heranziehen). Ihr Hauptunterschied liegt in der Trimmstrategie. Genauer gesagt wurde der Trimmstrategie von NSG ein Schalter alpha hinzugefügt. Die Hauptidee der NSG-Trimmstrategie besteht darin, dass die Auswahl der Nachbarn des Zielpunkts so vielfältig wie möglich ist. Wenn der neue Nachbar näher an einem Nachbarn des Zielpunkts liegt als der Zielpunkt, müssen wir diesen Punkt nicht zur Nachbarpunktmenge hinzufügen. Mit anderen Worten: Für jeden Nachbarn des Zielpunkts darf es innerhalb des umgebenden Radius dist (Zielpunkt, Nachbarpunkt) keine anderen Nachbarpunkte geben. Diese Trimmstrategie kontrolliert effektiv den Ausgrad des Graphen und ist relativ radikal. Sie reduziert den Speicherbedarf des Index, verbessert die Suchgeschwindigkeit, verringert aber auch die Suchgenauigkeit. Vamanas Trimmstrategie besteht darin, den Umfang des Trimmens über den Parameter alpha frei zu steuern. Das Funktionsprinzip besteht darin, die dist (ein Nachbarpunkt, Kandidatenpunkt) in der Trimmbedingung mit einem Parameter alpha (nicht kleiner als 1) zu multiplizieren. Nur wenn die dist (Zielpunkt, ein bestimmter Kandidatenpunkt) größer als die vergrößerte Referenzdistanz ist, wird die Trimmstrategie angewendet, wodurch die Toleranz der gegenseitigen Ausschließung zwischen Nachbarn des Zielpunkts erhöht wird.
Vamanas Indizierungsprozess ist relativ einfach:
Initialisieren Sie einen Zufallsgraphen;
Berechnen Sie den Startpunkt, der dem Navigationspunkt von NSG ähnelt. Finden Sie zunächst den globalen Schwerpunkt und anschließend den Punkt, der dem globalen Schwerpunkt am nächsten liegt, als Navigationspunkt. Der Unterschied zwischen Vamana und NSG besteht darin, dass die Eingabe von NSG bereits ein Nächste-Nachbarn-Graph ist, sodass Benutzer einfach eine approximative Nächste-Nachbarn-Suche auf dem Schwerpunktpunkt direkt auf dem anfänglichen Nachbargraphen durchführen können. Vamana initialisiert jedoch einen zufälligen Nächste-Nachbarn-Graphen, sodass Benutzer keine approximative Suche direkt auf dem Zufallsgraphen durchführen können. Sie müssen einen globalen Vergleich durchführen, um einen Navigationspunkt als Startpunkt der nachfolgenden Iterationen zu erhalten. Der Zweck dieses Punktes besteht darin, den durchschnittlichen Suchradius zu minimieren;
Führen Sie eine Approximate Nearest Neighbor Search für jeden Punkt basierend auf dem initialisierten zufälligen Nachbargraphen und dem in Schritt 2 bestimmten Suchstartpunkt durch, machen Sie alle Punkte auf dem Suchpfad zu den Kandidaten-Nachbarmengen und führen Sie die Kantentrimmstrategie mit alpha = 1 aus. Ähnlich wie bei NSG wird die Auswahl der Punktmenge auf dem Suchpfad, der vom Navigationspunkt ausgeht, als Kandidaten-Nachbarmenge einige lange Kanten hinzufügen und den Suchradius effektiv reduzieren.
Passen Sie alpha > 1 an (das Paper empfiehlt 1.2) und wiederholen Sie Schritt 3. Während Schritt 3 auf einem zufälligen Nächste-Nachbarn-Graphen basiert, ist der Graph nach der ersten Iteration von geringer Qualität. Daher ist eine weitere Iteration erforderlich, um die Graphqualität zu verbessern, was für die Recall-Rate sehr wichtig ist.
Dieses Paper vergleicht die drei Graphindizes, d. h. Vamana, NSG und HNSW. In Bezug auf Indizierungs- und Abfrageleistung liegen Vamana und NSG relativ nahe beieinander, und beide übertreffen HNSW geringfügig. Die Daten finden Sie im Abschnitt Experiment unten.
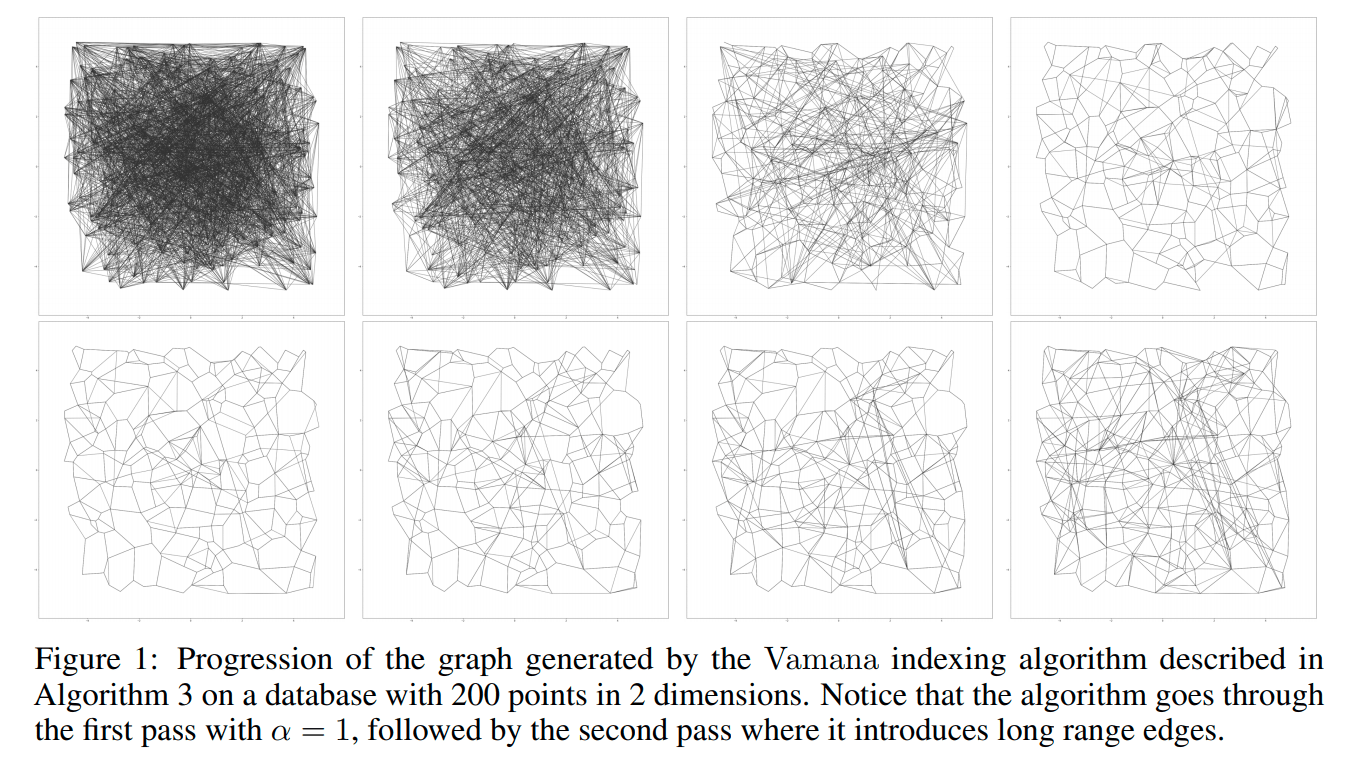 Figure 1.
Figure 1.
Um den Aufbauprozess des Vamana-Index zu veranschaulichen, stellt das Paper einen Graphen bereit, in dem 200 zweidimensionale Punkte verwendet werden, um zwei Iterationsrunden zu simulieren. Die erste Zeile verwendet alpha = 1, um die Kanten zu beschneiden. Es ist zu sehen, dass die Beschneidungsstrategie relativ radikal ist und eine große Anzahl von Kanten beschnitten wird. Nach der Erhöhung des Werts alpha und der Lockerung der Beschneidungsbedingungen werden offensichtlich viele Kanten wieder hinzugefügt. Im finalen Graphen werden ziemlich viele lange Kanten hinzugefügt. Dadurch kann der Suchradius effektiv reduziert werden.
DiskANN
Ein Personal Computer mit nur 64GB Speicher könnte nicht einmal eine Milliarde Rohdatenstücke halten, geschweige denn den darauf aufgebauten Index. Es gibt zwei Herausforderungen: 1. Wie kann ein Datensatz in solch großem Maßstab mit begrenzten Speicherressourcen indexiert werden? 2. Wie kann die Distanz bei der Suche berechnet werden, wenn die Originaldaten nicht in den Speicher geladen werden können?
Das Paper schlug die folgenden Lösungen vor:
Für die erste Herausforderung: Zunächst die Daten mit k-means in k Cluster aufteilen und dann jeden Punkt den nächsten i Clustern zuweisen. Im Allgemeinen reicht 2 für die Anzahl i aus. Für jeden Cluster einen speicherbasierten Vamana-Index erstellen und schließlich k Vamana-Indizes zu einem zusammenführen.
Für die zweite Herausforderung: Den Index auf den Originalvektoren aufbauen und komprimierte Vektoren abfragen. Der Aufbau von Indizes auf dem Originalvektor gewährleistet die Qualität des Graphen, während der komprimierte Vektor für eine grobgranulare Suche in den Speicher geladen werden kann. Obwohl die Suche mit den komprimierten Vektoren zu einem Genauigkeitsverlust führen kann, wird die allgemeine Richtung korrekt sein, solange die Qualität des Graphen hoch genug ist. Das endgültige Distanzergebnis wird mithilfe des Originalvektors berechnet.
Das Indexlayout von DiskANN ähnelt dem der allgemeinen Graphindizes. Die Nachbarmenge jedes Punkts und die Originalvektordaten werden zusammen gespeichert. Dies nutzt die Lokalität der Daten besser aus.
Wie bereits erwähnt, müssen, wenn die Indexdaten auf der SSD gespeichert werden, die Anzahl der Festplattenzugriffe sowie die Lese- und Schreibanforderungen an die Festplatte so weit wie möglich reduziert werden, um eine geringe Suchverzögerung zu gewährleisten. Daher schlägt DiskANN zwei Optimierungsstrategien vor:
Hotspot zwischenspeichern: Alle Punkte innerhalb von C Sprüngen vom Startpunkt im Speicher zwischenspeichern. Der Wert von C sollte besser innerhalb von 3 bis 4 gesetzt werden.
Beam Search: Einfach ausgedrückt, es geht darum, die Nachbarinformationen vorab zu laden. Bei der Suche nach Punkt p muss der Nachbarpunkt von p von der Festplatte geladen werden, wenn er sich nicht im Speicher befindet. Da eine kleine Anzahl zufälliger SSD-Zugriffsoperationen ungefähr genauso lange dauert wie eine SSD-Einzelsektorzugriffsoperation, können die Nachbarinformationen von W nicht besuchten Punkten auf einmal geladen werden. W darf nicht zu groß oder zu klein gesetzt werden. Ein großes W verschwendet Rechenressourcen und SSD-Bandbreite, während ein kleines die Suchverzögerung erhöht.
Experiment
Das Experiment besteht aus drei Gruppen:
Vergleich zwischen speicherbasierten Indizes: Vamana VS. NSG VS. HNSW
Datensätze: SIFT1M (128 Dimensionen), GIST1M (960 Dimensionen), DEEP1M (96 Dimensionen) und ein 1M-Datensatz, der zufällig aus DEEP1B gesampelt wurde.
Indexparameter (alle Datensätze verwenden denselben Parametersatz):
HNSW:M = 128, efc = 512.
Vamana: R = 70, L = 75, alpha = 1.2.
NSG: R = 60, L = 70, C= 500.
Die Suchparameter werden im Paper nicht angegeben, was möglicherweise mit den Indexierungsparametern übereinstimmt. Bei der Parameterauswahl basieren die im Artikel erwähnten Parameter von NSG auf den im GitHub-Repository von NSG aufgeführten Parametern, um die Gruppe mit besserer Leistung auszuwählen. Vamana und NSG liegen relativ nahe beieinander, daher werden die Parameter ebenfalls ähnlich gesetzt. Der Grund für die Auswahl der HNSW-Parameter wird jedoch nicht angegeben. Wir glauben, dass der Parameter M von HNSW relativ groß gesetzt ist. Dies könnte zu einem weniger überzeugenden Vergleich zwischen graphbasierten Indizes führen, wenn ihre Ausgrade nicht auf demselben Niveau festgelegt werden.
Unter den oben genannten Indexierungsparametern betragen die Indexierungszeiten von Vamana, HNSW und NSG jeweils 129 s, 219 s und 480 s. Die NSG-Indexierungszeit umfasst die Zeit zur Konstruktion des initialen Nachbarschaftsgraphen mit EFANN [3].
Recall-QPS-Kurve:
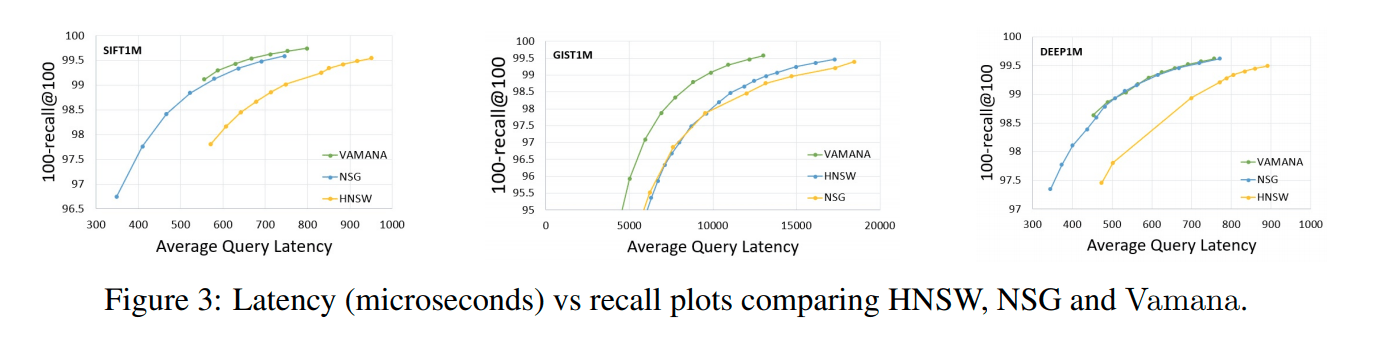 Figure 2.
Figure 2.
Aus Abbildung 3 ist ersichtlich, dass Vamana auf den drei Datensätzen eine ausgezeichnete Performance aufweist, ähnlich wie NSG und etwas besser als HNSW.
Vergleich des Suchradius:
Aus Abbildung 2.c können wir erkennen, dass Vamana bei gleicher Recall-Rate im Vergleich zu NSG und HNSW den kürzesten durchschnittlichen Suchpfad hat.
Vergleich zwischen einem einmalig erstellten Index und einem großen zusammengeführten Index
Datensatz: SIFT1B
Die Parameter des einmalig erstellten Index: L = 50, R = 128, alpha = 1.2. Nach einer Laufzeit von 2 Tagen auf einer 1800G-DDR3-Maschine beträgt der Spitzenwert des Speichers etwa 1100 G, und der durchschnittliche Out-Degree beträgt 113.9.
Indexierungsverfahren auf Basis des Zusammenführens:
40 Cluster auf dem Datensatz mit kmeans trainieren;
Jeder Punkt wird den nächstgelegenen 2 Clustern zugewiesen;
Einen Vamana-Index mit L = 50, R = 64 und alpha = 1.2 für jeden Cluster erstellen;
Die Indizes jedes Clusters zusammenführen.
Dieser Index erzeugte einen 384GB-Index mit einem durchschnittlichen Out-Degree von 92.1. Dieser Index lief 5 Tage lang auf einer 64GB-DDR4-Maschine.
Die Vergleichsergebnisse sind wie folgt (Abbildung 2a):
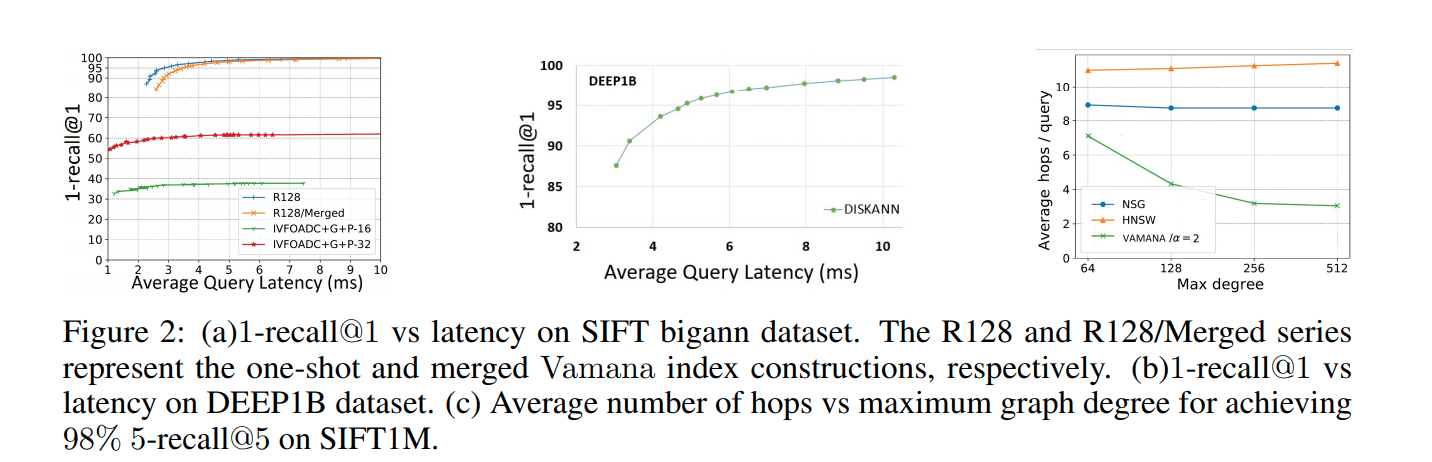 Figure 3.
Figure 3.
Zusammenfassend:
Der einmalig erstellte Index ist deutlich besser als der auf Zusammenführung basierende Index;
Der auf Zusammenführung basierende Index ist ebenfalls ausgezeichnet;
Das auf Zusammenführung basierende Indexierungsschema ist auch auf den DEEP1B-Datensatz anwendbar (Abbildung 2b).
Festplattenbasierter Index: DiskANN VS. FAISS VS. IVF-OADC+G+P
IVFOADC+G+P ist ein in Referenz [5] vorgeschlagener Algorithmus.
Dieses Paper vergleicht DiskANN nur mit IVFOADC+G+P, da Referenz [5] gezeigt hat, dass IVFOADC+G+P besser ist als FAISS. Darüber hinaus benötigt FAISS GPU-Ressourcen, die nicht von allen Plattformen unterstützt werden.
IVF-OADC+G+P scheint eine Kombination aus HNSW und IVF-PQ zu sein. Es bestimmt Cluster mithilfe von HNSW und führt die Suche durch, indem einige Pruning-Strategien zum Zielcluster hinzugefügt werden.
Das Ergebnis ist in Abbildung 2a dargestellt. Die 16 und 32 in der Abbildung sind die Codebook-Größe. Der Datensatz ist SIFT1B, quantifiziert durch OPQ.
Details zur Code-Implementierung
Der Quellcode von DiskANN ist als Open Source unter https://github.com/microsoft/DiskANN verfügbar.
Im Januar 2021 wurde der Quellcode der Disk-Lösung als Open Source veröffentlicht.
Im Folgenden werden hauptsächlich der Indexierungsprozess und der Suchprozess vorgestellt.
Index-Erstellung
Es gibt 8 Parameter für die Index-Erstellung:
data_type: Optionen umfassen float/int8/uint8.
data_file.bin: Die ursprüngliche binäre Datendatei. Die ersten beiden Integer in der Datei repräsentieren jeweils die Gesamtzahl n der Datensatzvektoren und die Vektordimension dim. Die letzten n * dim * sizeof(data_type) Bytes sind kontinuierliche Vektordaten.
index_prefix_path: Das Pfadpräfix der Ausgabedatei. Nachdem der Index erstellt wurde, werden mehrere indexbezogene Dateien generiert. Dieser Parameter ist das gemeinsame Präfix des Verzeichnisses, in dem sie gespeichert werden.
R: Der maximale Out-Degree des globalen Index.
L: Der Parameter L des Vamana-Index, die obere Grenze der Größe der Kandidatenmenge.
B: Der Speicherschwellenwert beim Abfragen. Er steuert die PQ-Codebook-Größe, in GB.
M: Der Speicherschwellenwert beim Erstellen eines Index. Er bestimmt die Größe des Fragments, in GB.
T: Die Anzahl der Threads.
Indexierungsprozess (Einstiegsfunktion: aux_utils.cpp::build_disk_index):
Verschiedene Ausgabedateinamen gemäß index_prefix_path generieren.
Parameterprüfung.
Die Metadaten von data_file.bin lesen, um n und dim zu erhalten. Die Codebook-Subraumanzahl m von PQ gemäß B und n bestimmen.
generate_pq_pivots: Den Mittelpunkt des PQ-Trainingssets mithilfe der Sampling-Rate von p = 1500000/n gleichmäßig sampeln, um PQ global zu trainieren.
generate_pq_data_from_pivots: Globales PQ-Codebook generieren und den Mittelpunkt und das Codebook separat speichern.
build_merged_vamana_index: den ursprünglichen Datensatz aufteilen, Vamana-Indizes in Segmenten erstellen und die Indizes schließlich zu einem zusammenführen.
partition_with_ram_budget: Bestimme die Anzahl der Fragmente k gemäß dem Parameter M. Stichprobenziehung aus dem Datensatz mittels kmeans, wobei jeder Punkt den zwei nächstgelegenen Clustern zugeordnet wird. Fragmentiere den Datensatz, und jedes Fragment erzeugt zwei Dateien: eine Datendatei und eine ID-Datei. Die ID-Datei und die Datendatei entsprechen einander, und jede ID in der ID-Datei entspricht einem Vektor in der Datendatei. Die IDs werden durch Nummerierung jedes Vektors der ursprünglichen Daten von 0 bis n-1 erhalten. Die ID ist relativ wichtig und steht im Zusammenhang mit dem Merge.
Ziehe global gleichmäßig Stichproben aus dem Trainingssatz mit einer Sampling-Rate von 1500000 / n;
Initialisiere num_parts = 3. Iteriere ab 3:
- Führe num_parts-means++ auf dem Trainingssatz in Schritt i aus;
- Verwende eine Sampling-Rate von 0.01, um global gleichmäßig einen Testsatz zu sampeln, und teile den Testsatz in die nächstgelegenen 2 Cluster auf;
- Zähle die Anzahl der Punkte in jedem Cluster und dividiere sie durch die Sampling-Rate, um die Anzahl der Punkte in jedem Cluster zu schätzen;
- Schätze den vom größten Cluster in Schritt 3 benötigten Speicher gemäß der Vamana-Indexgröße; wenn er den Parameter M nicht überschreitet, fahre mit Schritt iii fort, andernfalls num_parts ++ und zurück zu Schritt 2;
Teile den ursprünglichen Datensatz in num_parts Gruppendateien auf; jede Dateigruppe umfasst fragmentierte Datendateien und ID-Dateien, die den fragmentierten Daten entsprechen.
Erstelle Vamana-Indizes separat für alle Slices in Schritt a und speichere sie auf der Festplatte;
merge_shards: num_parts Shard-Vamana zu einem globalen Index zusammenführen:
Lies die ID-Datei der num_parts Fragmente in idmap ein. Diese idmap entspricht der Erstellung einer Vorwärtsabbildung von Fragment->id;
Erstelle eine Rückwärtsabbildung von id-> fragments gemäß idmap und wisse, in welchen zwei Fragmenten sich jeder Vektor befindet;
Verwende einen Reader mit 1GB Cache, um num_parts Slice-Vamana-Indizes zu öffnen, und verwende einen Writer mit 1GB Cache, um die Ausgabedatei zu öffnen, bereit zum Zusammenführen;
Lege num_parts Navigationspunkte des Vamana-Index in der Mittelpunktdatei ab, die bei der Suche verwendet wird;
Beginne das Zusammenführen gemäß der ID von klein nach groß, lies der Reihe nach entsprechend der Rückwärtsabbildung die Nachbarpunktmenge jedes ursprünglichen Vektors in jedem Fragment, dedupliziere, mische, kürze und schreibe in die Ausgabedatei. Da das Slicing ursprünglich global geordnet war und das Zusammenführen nun ebenfalls der Reihenfolge nach erfolgt, stehen die ID im endgültig geflushten Index und die ID der ursprünglichen Daten in einer Eins-zu-eins-Entsprechung.
Lösche temporäre Dateien, einschließlich Fragmentdateien, Fragmentindizes und Fragment-ID-Dateien.
7.create_disk_layout: Der in Schritt 6 erzeugte globale Index hat nur eine kompakte Adjazenz-Tabelle. Dieser Schritt dient dazu, den Index auszurichten. Die Adjazenz-Tabelle und die ursprünglichen Daten werden zusammen gespeichert. Bei der Suche wird die Adjazenz-Tabelle geladen und der ursprüngliche Vektor zur genauen Distanzberechnung mitgelesen. Es gibt außerdem das Konzept von SECTOR, wobei die Standardgröße 4096 beträgt. Jeder SECTOR enthält nur 4096 / node_size Stück Vektorinformationen. node_size = einzelne Vektorgröße + Größe der Adjazenz-Tabelle eines einzelnen Knotens.
8.Schließlich wird ein globales gleichmäßiges Sampling von 150000 / n durchgeführt, gespeichert und beim Suchen für den Warmup verwendet.
Suche
Es gibt 10 Suchparameter:
index_type: Optionen umfassen Float/int8/uint8, ähnlich dem ersten Parameter data_type beim Erstellen eines Index.
index_prefix_path: Siehe Indexparameter index_prefix_path.
num_nodes_to_cache: Anzahl der Cache-Hotspots.
num_threads: Anzahl der Such-Threads.
beamwidth: Obergrenze der Anzahl der Preload-Punkte. Das System bestimmt sie, wenn sie auf 0 gesetzt ist.
query_file.bin: Query-Set-Datei.
truthset.bin: Result-Set-Datei, "null" bedeutet, dass das Result-Set nicht bereitgestellt wird; das Programm berechnet es selbst;
K: topk;
result_output_prefix: Pfad zum Speichern der Suchergebnisse;
L*: Suchparameterliste. Es können mehrere Werte hinzugefügt werden. Für jedes L werden beim Suchen mit unterschiedlichen L statistische Informationen ausgegeben.
Suchprozess:
Zugehörige Daten laden: Abfragesatz, PQ-Zentrumspunktdaten, Codebook-Daten, Suchstartpunkt und andere Daten laden sowie Index-Metadaten lesen.
Den während der Indexierung gesampelten Datensatz verwenden, um cached_beam_search durchzuführen, die Zugriffshäufigkeit jedes Punkts zählen und num_nodes_to_cache Punkte mit der höchsten Zugriffshäufigkeit in den Cache laden.
Standardmäßig gibt es eine WARMUP-Operation. Wie in Schritt 2 wird auch dieser Beispieldatensatz verwendet, um cached_beam_search durchzuführen.
Entsprechend der Anzahl der angegebenen Parameter L wird jedes L erneut mit cached_beam_search mit dem Abfragesatz ausgeführt, und Statistiken wie Recall-Rate und QPS werden ausgegeben. Der Prozess des Warmups und der statistischen Hotspot-Daten wird nicht in die Abfragezeit eingerechnet.
Über cached_beam_search:
Den Kandidaten, der dem Abfragepunkt am nächsten ist, vom Kandidatenstartpunkt aus finden. Hier wird die PQ-Distanz verwendet, und der Startpunkt wird der Suchwarteschlange hinzugefügt.
Suche starten:
Aus der Suchwarteschlange gibt es nicht mehr als beam_width + 2 unbesuchte Punkte. Wenn diese Punkte im Cache sind, werden sie der Cache-Hit-Warteschlange hinzugefügt. Wenn sie nicht getroffen werden, werden sie der Miss-Warteschlange hinzugefügt. Sicherstellen, dass die Größe der Miss-Warteschlange beam_width nicht überschreitet.
Asynchrone Festplattenzugriffsanfragen an Punkte in der Miss-Warteschlange senden.
Für die vom Cache getroffenen Punkte die Originaldaten und die Abfragedaten verwenden, um die exakte Distanz zu berechnen, sie der Ergebniswarteschlange hinzufügen und anschließend PQ verwenden, um die Distanz zu den Nachbarpunkten zu berechnen, die noch nicht besucht wurden, bevor sie der Suchwarteschlange hinzugefügt werden. Die Länge der Suchwarteschlange wird durch Parameter begrenzt.
Die gecachten Miss-Punkte aus Schritt a verarbeiten, ähnlich wie in Schritt c.
Wenn die Suchwarteschlange leer ist, endet die Suche, und die topk der Ergebniswarteschlange werden zurückgegeben.
Zusammenfassung
Obwohl dies eine relativ umfangreiche Arbeit ist, ist sie insgesamt ausgezeichnet. Die Ideen von Paper und Code sind klar: eine Anzahl überlappender Buckets mittels k-means aufteilen, dann die Buckets aufteilen, um einen Map-Index zu erstellen, und schließlich die Indizes zusammenführen, was eine relativ neue Idee ist. Was den speicherbasierten Graphindex Vamana betrifft, ist er im Wesentlichen eine zufällig initialisierte Version von NSG, die die Trimming-Granularität steuern kann. Bei der Abfrage nutzt er Cache + Pipeline vollständig aus, verdeckt einen Teil der IO-Zeit und verbessert QPS. Laut Paper dauert die Trainingszeit jedoch selbst dann bis zu 5 Tage, wenn die Maschinenbedingungen nicht außergewöhnlich sind, und die Nutzbarkeit ist relativ gering. Optimierungen am Training sind in Zukunft definitiv notwendig. Aus Code-Perspektive ist die Qualität relativ hoch und kann direkt in der Produktionsumgebung eingesetzt werden.
Referenzen
[Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. Schnelle approximative Nearest-Neighbor-Suche mit navigierenden Spreading-out-Graphen. PVLDB, 12(5):461 – 474, 2019. doi: 10.14778/3303753.3303754.] (http://www.vldb.org/pvldb/vol12/p461-fu.pdf)
Cong Fu and Deng Cai. GitHub - ZJULearning/efanna: schnelle Bibliothek für ANN-Suche und KNN-Graphkonstruktion.
Weiterlesen

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.