




Personalisierte Empfehlungssysteme mit Milvus und PaddlePaddle erstellen
Hintergrundeinführung
Mit der kontinuierlichen Entwicklung der Netzwerktechnologie und dem ständig wachsenden Umfang des E-Commerce nehmen Anzahl und Vielfalt der Waren rasant zu, und Nutzer müssen viel Zeit aufwenden, um die Waren zu finden, die sie kaufen möchten. Dies ist Informationsüberlastung. Um dieses Problem zu lösen, entstand das Empfehlungssystem.
Das Empfehlungssystem ist eine Teilmenge des Information Filtering System, das in einer Reihe von Bereichen wie Filmen, Musik, E-Commerce und Feed-Stream-Empfehlungen eingesetzt werden kann. Das Empfehlungssystem entdeckt die personalisierten Bedürfnisse und Interessen der Nutzer durch die Analyse und das Mining von Nutzerverhalten und empfiehlt Informationen oder Produkte, die für den Nutzer von Interesse sein könnten. Im Gegensatz zu Suchmaschinen verlangen Empfehlungssysteme von Nutzern nicht, ihre Bedürfnisse genau zu beschreiben, sondern modellieren ihr historisches Verhalten, um proaktiv Informationen bereitzustellen, die den Nutzerinteressen und -bedürfnissen entsprechen.
In diesem Artikel verwenden wir PaddlePaddle, eine Deep-Learning-Plattform von Baidu, um ein Modell zu erstellen, und kombinieren Milvus, eine Suchmaschine für Vektorähnlichkeit, um ein personalisiertes Empfehlungssystem aufzubauen, das Nutzern schnell und präzise interessante Informationen bereitstellen kann.
Datenvorbereitung
Wir nehmen den MovieLens Million Dataset (ml-1m) [1] als Beispiel. Der ml-1m-Datensatz enthält 1.000.000 Bewertungen von 4.000 Filmen durch 6.000 Nutzer, gesammelt vom GroupLens Research lab. Die Originaldaten umfassen Feature-Daten des Films, Nutzer-Features und Nutzerbewertungen des Films; Sie können sich auf ml-1m-README [2] beziehen.
Der ml-1m-Datensatz umfasst 3 .dat-Artikel: movies.dat、users.dat und ratings.dat.movies.dat enthält die Features des Films, siehe Beispiel unten:
MovieID::Title::Genres
1::ToyStory(1995)::Animation|Children's|Comedy
Das bedeutet, dass die Film-ID 1 ist und der Titel 《Toy Story》 lautet, der in drei Kategorien unterteilt ist. Diese drei Kategorien sind Animation, Kinder und Komödie.
users.dat enthält die Features des Nutzers, siehe Beispiel unten:
UserID::Gender::Age::Occupation::Zip-code
1::F::1::10::48067
Das bedeutet, dass die Nutzer-ID 1 ist, weiblich und jünger als 18 Jahre alt. Die Berufs-ID ist 10.
ratings.dat enthält das Feature der Filmbewertung, siehe Beispiel unten:
UserID::MovieID::Rating::Timestamp 1::1193::5::978300760
Das heißt, Nutzer 1 bewertet den Film 1193 mit 5 Punkten.
Fusion Recommendation Model
Im personalisierten Filmempfehlungssystem haben wir das Fusion Recommendation Model [3] verwendet, das PaddlePaddle implementiert hat. Dieses Modell stammt aus seiner industriellen Praxis.
Zunächst werden Nutzer-Features und Film-Features als Eingabe für das neuronale Netzwerk verwendet, wobei:
- Die Nutzer-Features vier Attributinformationen einbeziehen: Nutzer-ID, Geschlecht, Beruf und Alter.
- Das Film-Feature drei Attributinformationen einbezieht: Film-ID, Filmtyp-ID und Filmname.
Für das Nutzer-Feature wird die Nutzer-ID auf eine Vektordarstellung mit einer Dimensionsgröße von 256 abgebildet, in die vollständig verbundene Schicht eingegeben, und für die anderen drei Attribute wird eine ähnliche Verarbeitung durchgeführt. Anschließend werden die Feature-Darstellungen der vier Attribute jeweils vollständig verbunden und separat addiert.
Für Film-Features wird die Film-ID auf ähnliche Weise wie die Nutzer-ID verarbeitet. Die Filmtyp-ID wird direkt in Form eines Vektors in die vollständig verbundene Schicht eingegeben, und der Filmname wird mithilfe eines textbasierten konvolutionalen neuronalen Netzwerks durch einen Vektor fester Länge dargestellt. Die Feature-Darstellungen der drei Attribute werden anschließend jeweils vollständig verbunden und separat addiert.
Nachdem die Vektordarstellung des Nutzers und des Films erhalten wurde, wird deren Kosinusähnlichkeit als Punktzahl des personalisierten Empfehlungssystems berechnet. Schließlich wird das Quadrat der Differenz zwischen der Ähnlichkeitspunktzahl und der tatsächlichen Bewertung des Nutzers als Verlustfunktion des Regressionsmodells verwendet.
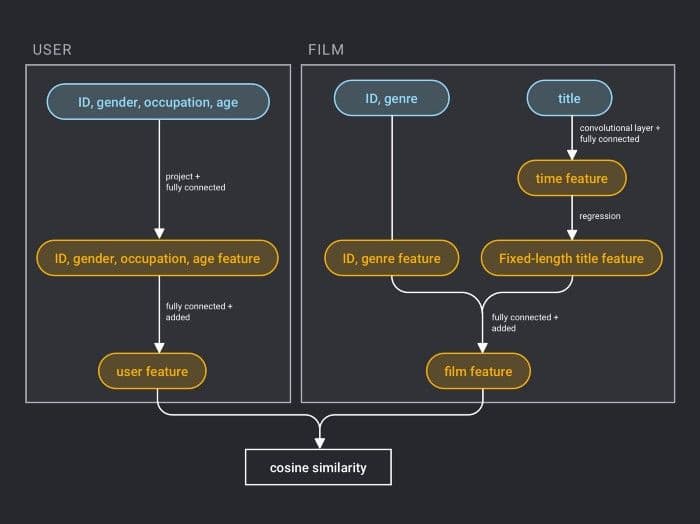 PaddlePaddles Fusion Recommendation Model.
PaddlePaddles Fusion Recommendation Model.
Systemübersicht
In Kombination mit dem Fusion-Recommendation-Modell von PaddlePaddle wird der vom Modell generierte Film-Feature-Vektor in der Milvus-Vektorähnlichkeitssuchmaschine gespeichert, und das Benutzer-Feature wird als zu suchender Zielvektor verwendet. In Milvus wird eine Ähnlichkeitssuche durchgeführt, um das Abfrageergebnis als die dem Benutzer empfohlenen Filme zu erhalten.
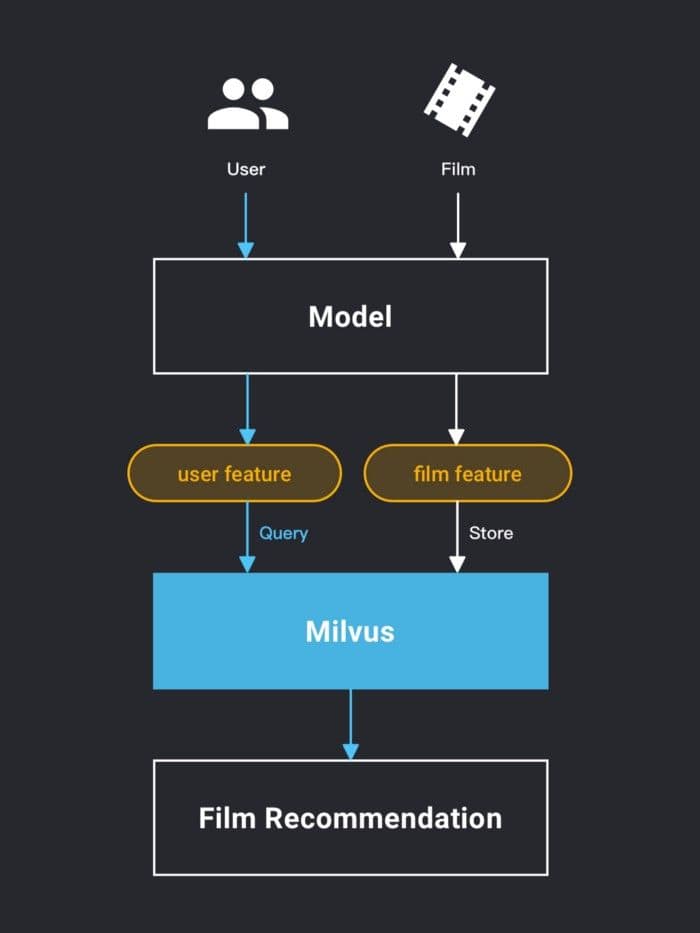 Fusion-Recommendation-Modell kombiniert mit Milvus.
Fusion-Recommendation-Modell kombiniert mit Milvus.
Die Inner-Product-(IP)-Methode wird in Milvus bereitgestellt, um den Vektorabstand zu berechnen. Nach der Normalisierung der Daten stimmt die Inner-Product-Ähnlichkeit mit dem Ergebnis der Kosinusähnlichkeit im Fusion-Recommendation-Modell überein.
Anwendung des persönlichen Empfehlungssystems
Es gibt drei Schritte beim Aufbau eines personalisierten Empfehlungssystems mit Milvus; Details zur Bedienung finden Sie im Mivus Bootcamp [4].
Schritt 1:Modelltraining
# run train.py
$ python train.py
Durch Ausführen dieses Befehls wird im Verzeichnis ein Modell recommender_system.inference.model generiert, das Filmdaten und Benutzerdaten in Feature-Vektoren umwandeln und Anwendungsdaten für Milvus zum Speichern und Abrufen erzeugen kann.
Schritt 2:Datenvorverarbeitung
# Data preprocessing, -f followed by the parameter raw movie data file name
$ python get_movies_data.py -f movies_origin.txt
Durch Ausführen dieses Befehls werden im Verzeichnis Testdaten movies_data.txt generiert, um die Vorverarbeitung der Filmdaten zu erreichen.
Schritt 3:Implementierung eines persönlichen Empfehlungssystems mit Milvus
# Implementing personal recommender system based on user conditions
$ python infer_milvus.py -a <age>-g <gender>-j <job>[-i]
Durch Ausführen dieses Befehls werden personalisierte Empfehlungen für angegebene Benutzer implementiert.
Der Hauptprozess ist:
- Über load_inference_model werden die Filmdaten vom Modell verarbeitet, um einen Film-Feature-Vektor zu generieren.
- Laden Sie den Film-Feature-Vektor über milvus.insert in Milvus.
- Entsprechend dem durch die Parameter angegebenen Alter / Geschlecht / Beruf des Benutzers wird er in einen Benutzer-Feature-Vektor umgewandelt, milvus.search_vectors wird für die Ähnlichkeitsabfrage verwendet, und das Ergebnis mit der höchsten Ähnlichkeit zwischen Benutzer und Film wird zurückgegeben.
Vorhersage der fünf Filme, an denen der Benutzer am meisten interessiert ist:
TopIdsTitleScore
03030Yojimbo2.9444923996925354
13871Shane2.8583481907844543
23467Hud2.849525213241577
31809Hana-bi2.826111316680908
43184Montana2.8119677305221558
Zusammenfassung
Durch die Eingabe von Benutzerinformationen und Filminformationen in das Fusion-Recommendation-Modell können wir Übereinstimmungswerte erhalten und dann die Werte aller Filme auf Grundlage des Benutzers sortieren, um Filme zu empfehlen, die für den Benutzer von Interesse sein könnten. Dieser Artikel kombiniert Milvus und PaddlePaddle, um ein personalisiertes Empfehlungssystem aufzubauen. Milvus, eine Vektorsuchmaschine, wird verwendet, um alle Film-Feature-Daten zu speichern, und anschließend wird eine Ähnlichkeitsabfrage für Benutzer-Features in Milvus durchgeführt. Das Suchergebnis ist die vom System dem Benutzer empfohlene Filmrangliste.
Die Milvus [5] Vektorähnlichkeitssuchmaschine ist mit verschiedenen Deep-Learning-Plattformen kompatibel und durchsucht Milliarden von Vektoren mit nur Millisekunden Reaktionszeit. Mit Milvus können Sie mühelos weitere Möglichkeiten von KI-Anwendungen erkunden!
Referenz
- MovieLens Million Dataset (ml-1m): http://files.grouplens.org/datasets/movielens/ml-1m.zip
- ml-1m-README: http://files.grouplens.org/datasets/movielens/ml-1m-README.txt
- Fusion Recommendation Model by PaddlePaddle: https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/basics/recommender_system/index.html#id7
- Bootcamp: https://github.com/milvus-io/bootcamp/tree/master/solutions/recommendation_system
- Milvus: https://milvus.io/en/
Weiterlesen

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.