




Wie VIPSHOP seinen E-Commerce-Recommender mit Milvus 10-mal schneller machte
Empfehlungssysteme sind für den Erfolg im E-Commerce unverzichtbar geworden und fungieren als strategischer Katalysator, um die Benutzererfahrung zu verbessern, die Kundenbindung zu fördern und den Unternehmensumsatz zu steigern. VIPSHOP, der wegweisende Online-Händler in China, stand an einem kritischen Wendepunkt. Mit einem schnell wachsenden Kundenstamm von über 52 Millionen und einem jährlichen Anstieg auf 270 Millionen Bestellungen erwies sich sein altes, auf Elasticsearch basierendes Empfehlungssystem als träge und unzureichend. Der Ruf nach einer schnelleren, personalisierten Lösung bei VIPSHOP wurde immer dringlicher. In diesem Beitrag gehen wir auf die Herausforderungen ein, mit denen VIPSHOP konfrontiert war, und darauf, wie die Einführung von Milvus sein Empfehlungssystem verbesserte.
Die Suche nach einer effizienten Vektorsuchmaschine
Das Fundament eines agilen Empfehlungssystems liegt in seiner Fähigkeit zur Vektorsuche, die entscheidend dafür ist, semantisch ähnliche Ergebnisse zeitnah zu liefern. VIPSHOP setzte zunächst auf Elasticsearch für die Vektorsuche, stieß jedoch bald auf Herausforderungen, als sein Produktsortiment wuchs. Das Altsystem stieß auf zwei große Stolpersteine—lange Antwortzeiten und stark steigende Wartungskosten.
Die Verlangsamung wurde auf die hohe Latenz von Elasticsearch beim Abrufen von Top-K-Ergebnissen zurückgeführt, die im Durchschnitt 300 ms betrug. Die endgültige Antwortzeit betrug mehrere Sekunden, was sich in Kombination mit nachfolgenden Verarbeitungsschritten negativ auf die Benutzererfahrung auswirkte. Darüber hinaus verwandelten sich die gemeinsam genutzten Indizes in ein komplexes Labyrinth, wodurch die Erstellungs- und Wartungskosten stiegen. Trotz Versuchen, Elasticsearch mit einem Hashing-Plugin neu zu beleben, blieben die Ergebnisse hinter den Erwartungen zurück. Die Suche nach einem neuen Vektorsuch-Stack wurde zur Zugabe des Teams für ein reaktionsschnelles Empfehlungssystem.
VIPSHOP entschied sich für Milvus, um sein Empfehlungssystem zu modernisieren
Milvus ist eine Open-Source-Vektordatenbank, die Geschwindigkeit und eine Symphonie von Funktionen verspricht, die Milliarden von Vektoreinbettungen verarbeiten können. Sie bot außerdem den Reiz verteilter Bereitstellung, mehrsprachiger SDKs und Lese-/Schreibtrennung—eine Komposition, die Elasticsearch und andere Vektorsuchtechnologien übertraf. Nach sorgfältiger Prüfung und Bewertung entschied sich VIPSHOP für Milvus, um sein Empfehlungssystem neu aufzubauen.
Wie Milvus im Empfehlungssystem von VIPSHOP funktioniert
Das Diagramm gibt einen Einblick in die Architektur des von Milvus betriebenen Empfehlungssystems von VIPSHOP.
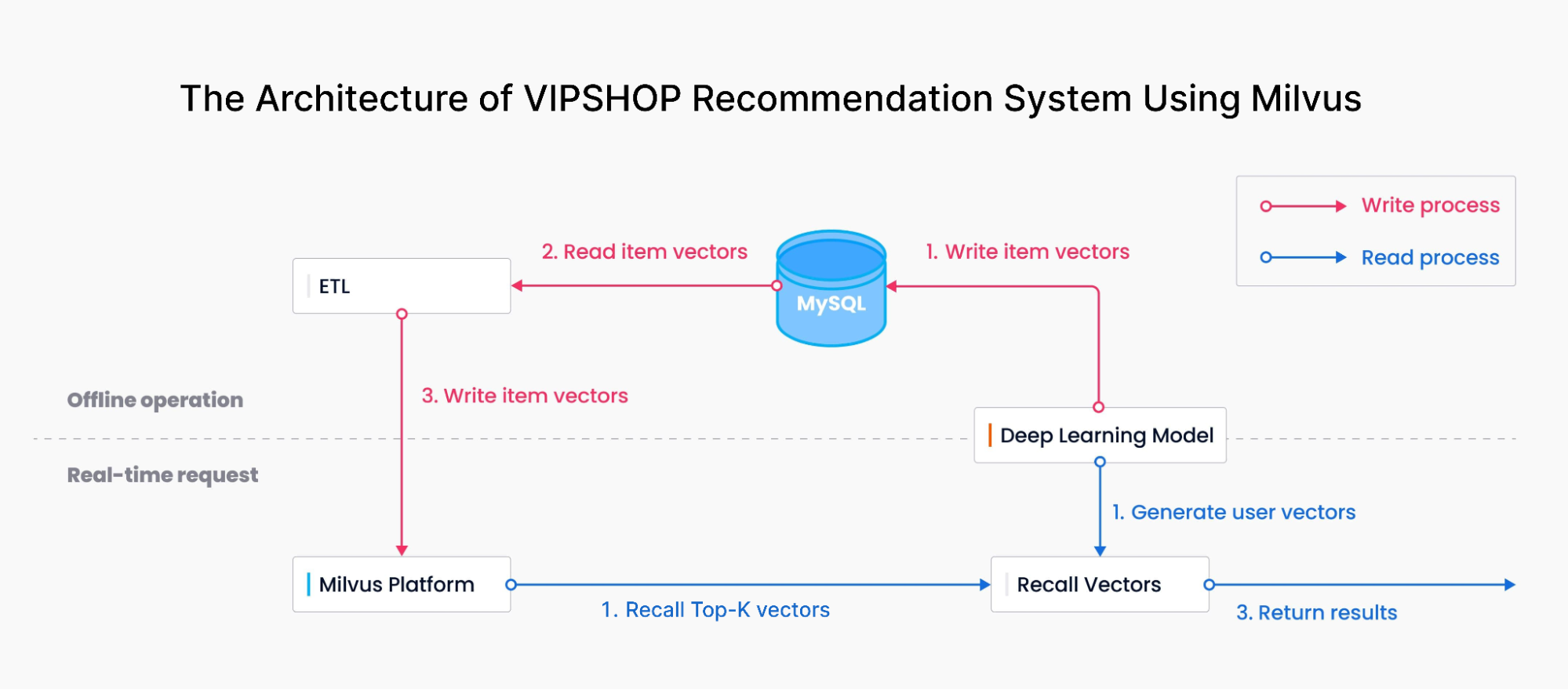
Ein Deep-Learning-Modell wandelt Produktmerkmale in Vektoreinbettungen um. Diese Einbettungen werden anschließend mithilfe von MySQL und einem ETL-Tool zur Speicherung und zum Abruf in Milvus aufgenommen.
Gleichzeitig werden Suchanfragen und Kaufpräferenzen der Verbraucher in ähnlicher Weise in Vektoreinbettungen umgewandelt, wodurch eine Ähnlichkeitssuche in Milvus ausgelöst wird. Hier führt Milvus eine Approximate-Nearest-Neighbors-(ANN)-Suche durch, indem es räumliche Abstände zwischen Verbraucher- und Produktvektoren bewertet und die Top-K der relevantesten Ergebnisse liefert. Schließlich wird dieses Ergebnis den Verbrauchern präsentiert.
Milvus zeigte bemerkenswerte Effizienz sowohl bei Datenaktualisierungs- als auch bei Recall-Prozessen.
Datenaktualisierung und Recall sind entscheidend für eine schnelle Vektorsuche und personalisierte Empfehlungen innerhalb dieser komplexen Orchestrierung. Das Verfahren zur Datenaktualisierung gewährleistet eine nahtlose Synchronisierung und umfasst Aufgaben wie das Schreiben von Vektordaten, das Erkennen von Datenvolumina, die Indexerstellung, das Vorladen von Indizes und das Alias-Management. Andererseits umfasst der Recall-Prozess, der ein integraler Bestandteil von Produktempfehlungen ist, das Abrufen von Vektoren im Zusammenhang mit Verbraucheranfragen und Kaufverhalten, das Berechnen ihrer Abstände und das Zusammenführen von Ergebnissen.
Milvus zeigte sowohl bei Datenaktualisierungs- als auch bei Abrufprozessen bemerkenswerte Effizienz und Agilität und erreichte eine durchschnittliche Latenz von nur 10 ms. Die folgende Tabelle veranschaulicht die Leistungsmetriken von drei primären Milvus-Diensten im Zusammenhang mit Datenaktualisierung und Abruf.
| Dienst | Rolle | Eingabeparameter | Ausgabeparameter | Antwortlatenz |
|---|---|---|---|---|
| Nutzervektorerfassung | Nutzervektor abrufen | Nutzerinformationen + Abfrage | Nutzervektor | 10 ms |
| Milvus Search | Vektorähnlichkeit berechnen und Top-K-Ergebnisse zurückgeben | Nutzervektor | Artikelvektor | 10 ms |
| Planungslogik | Gleichzeitiger Ergebnisabruf und Zusammenführung | Über mehrere Kanäle abgerufene Artikelvektoren und der Ähnlichkeitswert | Top-K-Artikel | 10 ms |
Verbesserung der Nutzererlebnisse durch 10x schnellere Empfehlungen und erhebliche Kostensenkung
Die Integration von Milvus in das Empfehlungssystem von VIPSHOP hat die Landschaft neu gestaltet und eine neue Ära der Nutzererlebnisse eingeläutet.
10x schnellere Gesamtantworten: Milvus senkte die gesamten Vektorabfragezeiten auf unter 30 ms. Diese außergewöhnliche Geschwindigkeit entspricht einer Verzehnfachung gegenüber der vorherigen Elasticsearch-Lösung und stellt sicher, dass Nutzer blitzschnelle Empfehlungen erhalten.
Erweiterte Fähigkeit zur Bewältigung eines Anstiegs von Geschäftsdaten: Die verteilte Bereitstellung und die horizontalen Skalierungsfähigkeiten von Milvus ermöglichten es dem Empfehlungssystem von VIPSHOP, wachsende Datenmengen und Nutzeranfragen mühelos zu bewältigen. Die Möglichkeit, Rechenleistung und Speicher unabhängig zu skalieren, passt nahtlos zu den sich wandelnden Anforderungen von VIPSHOP und bietet beispiellose Flexibilität.
Reduzierte Wartungskosten: Milvus half VIPSHOP mit seinen optimierten Abfragemechanismen, die Wartungskosten für das Empfehlungssystem zu senken. Diese Reduzierung verbessert die betriebliche Effizienz und trägt zur allgemeinen Kosteneffektivität der Plattform bei.
Herausforderungen mit Milvus und gewonnene Erkenntnisse
Auf ihrem Weg mit Milvus stieß das Team von VIPSHOP auch auf einige Herausforderungen, die es mit Unterstützung des technischen Supportteams von Zilliz löste. In diesem Abschnitt teilten sie die gewonnenen Erkenntnisse und Einsichten zur Optimierung der Systemleistung. * Die Einführung einer Bereitstellungsstrategie mit Lese-Schreib-Trennung kann die Gesamtleistung des Systems verbessern, wenn Leseoperationen Vorrang haben.
Dem Milvus Java-Client fehlt ein inhärenter Wiederverbindungsmechanismus, da er sich im Arbeitsspeicher innerhalb des Abrufdienstes befindet. Das VIPSHOP-Team entwickelte einen dedizierten Verbindungspool, um eine konsistente Konnektivität sicherzustellen, und implementierte einen Heartbeat-Test zwischen dem Java-Client und dem Server.
Gelegentliche langsame Abfragen in Milvus werden auf ein unzureichendes Aufwärmen neuer Collections zurückgeführt. Um diese Herausforderung zu bewältigen, implementierte das VIPSHOP-Team eine Strategie zur Simulation von Abfragen auf der neu erstellten Collection.
Das richtige Gleichgewicht zwischen Abrufleistung und Genauigkeit zu erreichen, ist entscheidend. Das VIPSHOP-Team empfiehlt, sorgfältige Lasttest-Experimente durchzuführen, die auf das jeweilige Geschäftsszenario zugeschnitten sind. Die Festlegung eines angemessenen Schwellenwerts ist entscheidend, um diese Parameter effektiv zu optimieren.
In Szenarien mit statischen Daten besteht ein effizienter Ansatz darin, zunächst alle Daten in die Collection zu importieren und den Indexaufbau auf einen späteren Zeitpunkt zu verschieben.

Weiterlesen

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.