




Kompilierung um das 2,5-Fache beschleunigen mit Abhängigkeitsentkopplung und Test-Containerisierung
Die Kompilierungszeit kann durch komplexe interne und externe Abhängigkeiten verlängert werden, die sich während des gesamten Entwicklungsprozesses weiterentwickeln, sowie durch Änderungen in Kompilierungsumgebungen wie dem Betriebssystem oder Hardwarearchitekturen. Im Folgenden sind häufige Probleme aufgeführt, auf die man bei der Arbeit an groß angelegten AI- oder MLOps-Projekten stoßen kann:
Unverhältnismäßig lange Kompilierung - Code-Integration wird hunderte Male pro Tag durchgeführt. Bei Hunderttausenden von Codezeilen kann selbst eine kleine Änderung zu einer vollständigen Kompilierung führen, die typischerweise eine oder mehrere Stunden dauert.
Komplexe Kompilierungsumgebung - Der Projektcode muss unter verschiedenen Umgebungen kompiliert werden, die unterschiedliche Betriebssysteme wie CentOS und Ubuntu, zugrunde liegende Abhängigkeiten wie GCC, LLVM und CUDA sowie Hardwarearchitekturen umfassen. Und eine Kompilierung unter einer bestimmten Umgebung funktioniert normalerweise möglicherweise nicht unter einer anderen Umgebung.
Komplexe Abhängigkeiten - Die Projektkompilierung umfasst mehr als 30 Abhängigkeiten zwischen Komponenten und von Drittanbietern. Die Projektentwicklung führt oft zu Änderungen an Abhängigkeiten, was unvermeidlich Abhängigkeitskonflikte verursacht. Die Versionskontrolle zwischen Abhängigkeiten ist so komplex, dass das Aktualisieren der Version von Abhängigkeiten leicht andere Komponenten beeinflusst.
Download von Drittanbieter-Abhängigkeiten ist langsam oder schlägt fehl - Netzwerkverzögerungen oder instabile Drittanbieter-Abhängigkeitsbibliotheken verursachen langsame Ressourcendownloads oder Zugriffsfehler, was die Code-Integration erheblich beeinträchtigt.
Durch das Entkoppeln von Abhängigkeiten und die Implementierung von Test-Containerisierung konnten wir die durchschnittliche Kompilierungszeit bei der Arbeit am Open-Source-Projekt für Embeddings-Ähnlichkeitssuche Milvus um 60 % reduzieren.
Die Abhängigkeiten des Projekts entkoppeln
Die Projektkompilierung umfasst normalerweise eine große Anzahl interner und externer Komponentenabhängigkeiten. Je mehr Abhängigkeiten ein Projekt hat, desto komplexer wird deren Verwaltung. Wenn Software wächst, wird es schwieriger und kostspieliger, Abhängigkeiten zu ändern oder zu entfernen sowie die Auswirkungen davon zu identifizieren. Während des gesamten Entwicklungsprozesses ist regelmäßige Wartung erforderlich, um sicherzustellen, dass die Abhängigkeiten ordnungsgemäß funktionieren. Schlechte Wartung, komplexe Abhängigkeiten oder fehlerhafte Abhängigkeiten können Konflikte verursachen, die die Entwicklung verlangsamen oder zum Stillstand bringen. In der Praxis kann dies verzögerte Ressourcendownloads, Zugriffsfehler, die sich negativ auf die Code-Integration auswirken, und mehr bedeuten. Das Entkoppeln von Projektabhängigkeiten kann Fehler mindern und die Kompilierungszeit reduzieren, wodurch Systemtests beschleunigt und unnötige Belastungen der Softwareentwicklung vermieden werden.
Daher empfehlen wir, die Abhängigkeiten Ihres Projekts zu entkoppeln:
- Komponenten mit komplexen Abhängigkeiten aufteilen
- Unterschiedliche Repositories für das Versionsmanagement verwenden.
- Konfigurationsdateien verwenden, um Versionsinformationen, Kompilierungsoptionen, Abhängigkeiten usw. zu verwalten.
- Die Konfigurationsdateien zu den Komponentenbibliotheken hinzufügen, damit sie bei der Iteration des Projekts aktualisiert werden.
Kompilierungsoptimierung zwischen Komponenten — Ziehen und kompilieren Sie die relevante Komponente entsprechend den Abhängigkeiten und den in den Konfigurationsdateien aufgezeichneten Kompilierungsoptionen. Markieren und paketieren Sie die binären Kompilierungsergebnisse und die entsprechenden Manifestdateien und laden Sie sie anschließend in Ihr privates Repository hoch. Wenn an einer Komponente oder den Komponenten, von denen sie abhängt, keine Änderung vorgenommen wird, spielen Sie ihre Kompilierungsergebnisse gemäß den Manifestdateien wieder ab. Bei Problemen wie Netzwerkverzögerungen oder instabilen Drittanbieter-Abhängigkeitsbibliotheken sollten Sie versuchen, ein internes Repository einzurichten oder gespiegelte Repositories zu verwenden.
So optimieren Sie die Kompilierung zwischen Komponenten:
1.Abhängigkeitsbeziehungsdiagramm erstellen — Verwenden Sie die Konfigurationsdateien in den Komponentenbibliotheken, um ein Abhängigkeitsbeziehungsdiagramm zu erstellen. Verwenden Sie die Abhängigkeitsbeziehung, um die Versionsinformationen (Git Branch, Tag und Git commit ID) sowie Kompilierungsoptionen und mehr sowohl der upstream- als auch der downstream-abhängigen Komponenten abzurufen.
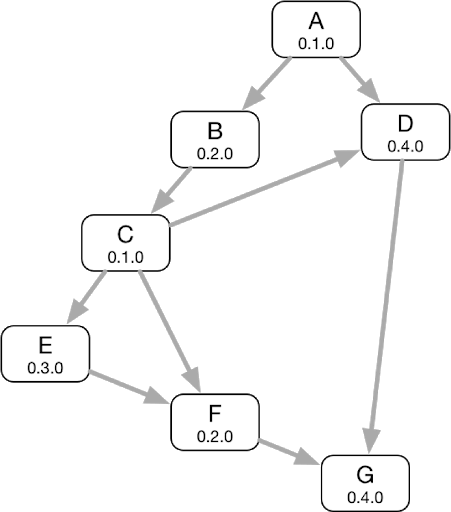 Abbildung 1.
Abbildung 1.
2.Auf Abhängigkeiten prüfen — Generieren Sie Warnungen für zirkuläre Abhängigkeiten, Versionskonflikte und andere Probleme, die zwischen Komponenten auftreten.
3.Abhängigkeiten flachlegen — Sortieren Sie Abhängigkeiten per Tiefensuche (Depth First Search, DFS) und führen Sie Komponenten mit doppelten Abhängigkeiten vorne zusammen, um einen Abhängigkeitsgraphen zu bilden.
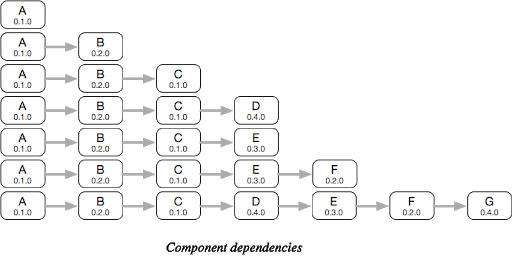 Abbildung 2.
Abbildung 2.
4.Verwenden Sie den MerkleTree-Algorithmus, um basierend auf Versionsinformationen, Kompilierungsoptionen und mehr einen Hash (Root Hash) zu generieren, der die Abhängigkeiten jeder Komponente enthält. Zusammen mit Informationen wie dem Komponentennamen bildet der Algorithmus ein eindeutiges Tag für jede Komponente.
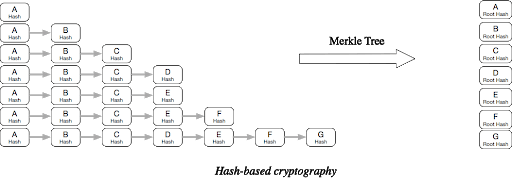 Abbildung 3.
Abbildung 3.
5.Prüfen Sie anhand der eindeutigen Tag-Informationen der Komponente, ob ein entsprechendes Kompilierungsarchiv im privaten Repo existiert. Wenn ein Kompilierungsarchiv abgerufen wird, entpacken Sie es, um die Manifestdatei für die Wiedergabe zu erhalten; falls nicht, kompilieren Sie die Komponente, markieren Sie die generierten Kompilierungsobjektdateien und die Manifestdatei und laden Sie sie in das private Repo hoch.
Kompilierungsoptimierungen innerhalb von Komponenten implementieren — Wählen Sie ein sprachspezifisches Kompilierungs-Cache-Tool, um die kompilierten Objektdateien zwischenzuspeichern, und laden Sie sie in Ihr privates Repository hoch und speichern Sie sie dort. Für die C/C++-Kompilierung wählen Sie ein Kompilierungs-Cache-Tool wie CCache, um die C/C++-Kompilierungs-Zwischendateien zwischenzuspeichern, und archivieren Sie anschließend den lokalen CCache-Cache nach der Kompilierung. Solche Compile-Cache-Tools speichern die geänderten Codedateien nach der Kompilierung einfach einzeln zwischen und kopieren die kompilierten Komponenten der unveränderten Codedatei, sodass sie direkt in die endgültige Kompilierung einbezogen werden können. Die Optimierung der Kompilierung innerhalb von Komponenten umfasst die folgenden Schritte:
- Fügen Sie die notwendigen Kompilierungsabhängigkeiten zum Dockerfile hinzu. Verwenden Sie Hadolint, um Konformitätsprüfungen am Dockerfile durchzuführen und sicherzustellen, dass das Image den Best Practices von Docker entspricht.
- Spiegeln Sie die Kompilierungsumgebung gemäß der Projekt-Sprint-Version (Version + Build), dem Betriebssystem und weiteren Informationen.
- Führen Sie den Container der gespiegelten Kompilierungsumgebung aus und übergeben Sie die Image-ID als Umgebungsvariable an den Container. Hier ist ein Beispielbefehl zum Abrufen der Image-ID: “docker inspect ‘ — type=image’ — format ‘{{.ID}}’ repository/build-env:v0.1-centos7”.
- Wählen Sie das geeignete Compile-Cache-Tool: Betreten Sie Ihren Container, um Ihre Codes zu integrieren und zu kompilieren, und prüfen Sie in Ihrem privaten Repository, ob ein geeigneter Compile-Cache existiert. Falls ja, laden Sie ihn herunter und extrahieren Sie ihn in das angegebene Verzeichnis. Nachdem alle Komponenten kompiliert wurden, wird der vom Compile-Cache-Tool generierte Cache basierend auf der Projektversion und der Image-ID paketiert und in Ihr privates Repository hochgeladen.
Weitere Kompilierungsoptimierung
Unser ursprünglich erstelltes Image belegt zu viel Speicherplatz und Netzwerkbandbreite und die Bereitstellung dauert lange; daher haben wir die folgenden Maßnahmen ergriffen:
- Wählen Sie das schlankste Basis-Image, um die Image-Größe zu reduzieren, z. B. alpine, busybox usw.
- Reduzieren Sie die Anzahl der Image-Layer. Verwenden Sie Abhängigkeiten so weit wie möglich wieder. Fassen Sie mehrere Befehle mit “&&” zusammen.
- Bereinigen Sie die Zwischenprodukte während des Image-Builds.
- Verwenden Sie beim Erstellen des Images so weit wie möglich den Image-Cache.
Da unser Projekt weiter voranschreitet, begannen die Festplattennutzung und die Netzwerkressourcen mit zunehmendem Kompilierungs-Cache stark anzusteigen, während einige der Kompilierungs-Caches kaum genutzt werden. Wir nahmen daraufhin die folgenden Anpassungen vor:
Cache-Dateien regelmäßig bereinigen — Prüfen Sie regelmäßig das private Repository (zum Beispiel mithilfe von Skripten) und bereinigen Sie Cache-Dateien, die sich seit einer Weile nicht geändert haben oder kaum heruntergeladen wurden.
Selektives Compile-Caching — Cachen Sie nur ressourcenintensive Kompilierungen und überspringen Sie das Caching von Kompilierungen, die nicht viele Ressourcen erfordern.
Containerisiertes Testen nutzen, um Fehler zu reduzieren sowie Stabilität und Zuverlässigkeit zu verbessern
Codes müssen in verschiedenen Umgebungen kompiliert werden, die eine Vielzahl von Betriebssystemen (z. B. CentOS und Ubuntu), zugrunde liegenden Abhängigkeiten (z. B. GCC, LLVM und CUDA) und spezifischen Hardwarearchitekturen umfassen. Code, der in einer bestimmten Umgebung erfolgreich kompiliert wird, kann in einer anderen Umgebung fehlschlagen. Durch das Ausführen von Tests in Containern wird der Testprozess schneller und genauer.
Containerisierung stellt sicher, dass die Testumgebung konsistent ist und dass eine Anwendung wie erwartet funktioniert. Der containerisierte Testansatz verpackt Tests als Image-Container und erstellt eine wirklich isolierte Testumgebung. Unsere Tester fanden diesen Ansatz ziemlich nützlich, was letztendlich die Kompilierzeiten um bis zu 60 % reduzierte.
Eine konsistente Kompilierumgebung sicherstellen — Da die kompilierten Produkte empfindlich auf Änderungen in der Systemumgebung reagieren, können in verschiedenen Betriebssystemen unbekannte Fehler auftreten. Wir müssen den Cache der kompilierten Produkte entsprechend den Änderungen in der Kompilierumgebung kennzeichnen und archivieren, aber sie sind schwer zu kategorisieren. Daher haben wir Containerisierungstechnologie eingeführt, um die Kompilierumgebung zu vereinheitlichen und solche Probleme zu lösen.
Fazit
Durch die Analyse von Projektabhängigkeiten stellt dieser Artikel verschiedene Methoden zur Kompilierungsoptimierung zwischen und innerhalb von Komponenten vor und bietet Ideen und Best Practices für den Aufbau einer stabilen und effizienten kontinuierlichen Code-Integration. Diese Methoden halfen dabei, langsame Code-Integration, die durch komplexe Abhängigkeiten verursacht wird, zu lösen, Abläufe innerhalb des Containers zu vereinheitlichen, um die Konsistenz der Umgebung sicherzustellen, und die Kompilierungseffizienz durch die Wiedergabe der Kompilierungsergebnisse und die Verwendung von Kompilierungscache-Tools zum Zwischenspeichern der Zwischenkompilierungsergebnisse zu verbessern.
Diese oben genannten Praktiken haben die Kompilierzeit des Projekts im Durchschnitt um 60 % reduziert und die Gesamteffizienz der Code-Integration erheblich verbessert. In Zukunft werden wir die Kompilierung zwischen und innerhalb von Komponenten weiter parallelisieren, um die Kompilierzeiten weiter zu reduzieren.
Die folgenden Quellen wurden für diesen Artikel verwendet:
- “Decoupling Source Trees into Build-Level Components”
- “Factors to consider when adding third party dependencies to a project”
- “Surviving Software Dependencies”
- “Understanding Dependencies: A Study of the Coordination Challenges in Software Development”
Über den Autor
Zhifeng Zhang ist Senior DevOps Engineer bei Zilliz.com und arbeitet an Milvus, einer Open-Source-Vektordatenbank, sowie autorisierter Dozent der LF Open-Source-Software-Universität in China. Er erhielt seinen Bachelor-Abschluss in Internet of Things (IOT) vom Software Engineering Institute of Guangzhou. Er verbringt seine Karriere damit, an Projekten in den Bereichen CI/CD, DevOps, IT-Infrastrukturmanagement, Cloud-Native-Toolkit, Containerisierung und Optimierung des Kompilierungsprozesses mitzuwirken und diese zu leiten.
Weiterlesen

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.