




Beschleunigung der Ähnlichkeitssuche in wirklich großen Datenmengen mit Vektorindizierung
Von Computer Vision bis hin zur Entdeckung neuer Medikamente treiben Vektor-Ähnlichkeitssuchmaschinen viele beliebte Anwendungen der künstlichen Intelligenz (KI) an. Ein enormer Bestandteil dessen, was es ermöglicht, die Millionen-, Milliarden- oder sogar Billionen-Vektor-Datensätze, auf die Ähnlichkeitssuchmaschinen angewiesen sind, effizient abzufragen, ist die Indexierung, ein Prozess zur Organisation von Daten, der die Suche in Big Data drastisch beschleunigt. Dieser Artikel behandelt die Rolle, die die Indexierung dabei spielt, die Vektor-Ähnlichkeitssuche effizient zu machen, verschiedene Typen von Vector-Inverted-File-(IVF-)Indizes sowie Empfehlungen dazu, welcher Index in unterschiedlichen Szenarien verwendet werden sollte.
Springen zu:
- Wie beschleunigt die Vektorindexierung die Ähnlichkeitssuche und Machine Learning?
- Welche verschiedenen Arten von IVF-Indizes gibt es und für welche Szenarien sind sie am besten geeignet?
- FLAT: Gut geeignet für die Suche in relativ kleinen Datensätzen (im Millionenbereich), wenn 100 % Recall erforderlich ist.
- IVF_FLAT: Verbessert die Geschwindigkeit auf Kosten der Genauigkeit (und umgekehrt).
- IVF_SQ8: Schneller und ressourcenschonender als IVF_FLAT, aber auch weniger genau.
- IVF_SQ8H: Neuer hybrider GPU/CPU-Ansatz, der noch schneller ist als IVF_SQ8.
- Erfahren Sie mehr über Milvus, eine Vektordatenmanagement-Plattform im massiven Maßstab.
Wie beschleunigt die Vektorindexierung die Ähnlichkeitssuche und Machine Learning?
Ähnlichkeitssuchmaschinen funktionieren, indem sie eine Eingabe mit einer Datenbank vergleichen, um Objekte zu finden, die der Eingabe am ähnlichsten sind. Indexierung ist der Prozess der effizienten Organisation von Daten, und sie spielt eine wichtige Rolle dabei, die Ähnlichkeitssuche nützlich zu machen, indem sie zeitaufwendige Abfragen auf großen Datensätzen drastisch beschleunigt. Nachdem ein massiver Vektordatensatz indexiert wurde, können Abfragen an Cluster oder Teilmengen von Daten weitergeleitet werden, die am wahrscheinlichsten Vektoren enthalten, die einer Eingabeabfrage ähnlich sind. In der Praxis bedeutet dies, dass ein gewisser Grad an Genauigkeit geopfert wird, um Abfragen auf wirklich großen Vektordaten zu beschleunigen.
Eine Analogie lässt sich zu einem Wörterbuch ziehen, in dem Wörter alphabetisch sortiert sind. Wenn man ein Wort nachschlägt, ist es möglich, schnell zu einem Abschnitt zu navigieren, der nur Wörter mit demselben Anfangsbuchstaben enthält — was die Suche nach der Definition des Eingabeworts drastisch beschleunigt.
Welche verschiedenen Arten von IVF-Indizes gibt es und für welche Szenarien sind sie am besten geeignet?
Es gibt zahlreiche Indizes, die für die hochdimensionale Vektor-Ähnlichkeitssuche entwickelt wurden, und jeder bringt Kompromisse bei Leistung, Genauigkeit und Speicheranforderungen mit sich. Dieser Artikel behandelt mehrere gängige IVF-Indextypen, ihre Stärken und Schwächen sowie Leistungstestergebnisse für jeden Indextyp. Leistungstests quantifizieren die Abfragezeit und Recall-Raten für jeden Indextyp in Milvus, einer Open-Source-Plattform für Vektordatenmanagement. Weitere Informationen zur Testumgebung finden Sie im Abschnitt zur Methodik am Ende dieses Artikels.
FLAT: Gut geeignet für die Suche in relativ kleinen Datensätzen (im Millionenbereich), wenn 100 % Recall erforderlich ist.
Für Anwendungen der Vektor-Ähnlichkeitssuche, die perfekte Genauigkeit erfordern und auf relativ kleinen Datensätzen (im Millionenbereich) basieren, ist der FLAT-Index eine gute Wahl. FLAT komprimiert Vektoren nicht und ist der einzige Index, der exakte Suchergebnisse garantieren kann. Ergebnisse von FLAT können außerdem als Vergleichspunkt für Ergebnisse verwendet werden, die von anderen Indizes erzeugt werden, die weniger als 100 % Recall haben.
FLAT ist genau, weil es einen erschöpfenden Suchansatz verfolgt, was bedeutet, dass für jede Abfrage die Zieleingabe mit jedem Vektor in einem Datensatz verglichen wird. Dadurch ist FLAT der langsamste Index auf unserer Liste und für Abfragen massiver Vektordaten schlecht geeignet. Für den FLAT-Index in Milvus gibt es keine Parameter, und seine Verwendung erfordert weder Datentraining noch zusätzlichen Speicher.
FLAT-Leistungstestergebnisse:
Die Leistungstests der FLAT-Abfragezeit wurden in Milvus mit einem Datensatz durchgeführt, der aus 2 Millionen 128-dimensionalen Vektoren bestand.
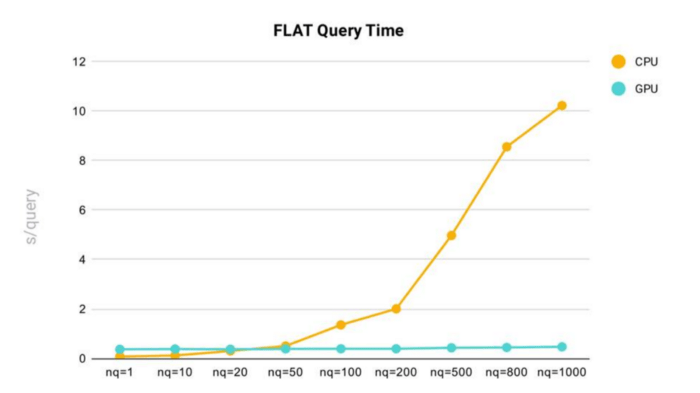 Testergebnisse der Abfragezeit für den FLAT-Index in Milvus.
Testergebnisse der Abfragezeit für den FLAT-Index in Milvus.
Wichtigste Erkenntnisse:
- Wenn nq (die Anzahl der Zielvektoren für eine Abfrage) zunimmt, steigt die Abfragezeit.
- Bei Verwendung des FLAT-Index in Milvus sehen wir, dass die Abfragezeit stark ansteigt, sobald nq 200 überschreitet.
- Im Allgemeinen ist der FLAT-Index schneller und konsistenter, wenn Milvus auf GPU statt auf CPU ausgeführt wird. FLAT-Abfragen auf CPU sind jedoch schneller, wenn nq unter 20 liegt.
IVF_FLAT: Verbessert die Geschwindigkeit auf Kosten der Genauigkeit (und umgekehrt).
Eine gängige Methode, den Ähnlichkeitssuchprozess auf Kosten der Genauigkeit zu beschleunigen, besteht darin, eine Approximate-Nearest-Neighbor-Suche (ANN) durchzuführen. ANN-Algorithmen reduzieren Speicheranforderungen und Rechenlast, indem sie ähnliche Vektoren zusammen clustern, was zu einer schnelleren Vektorsuche führt. IVF_FLAT ist der grundlegendste Typ eines invertierten Dateiindex und stützt sich auf eine Form der ANN-Suche.
IVF_FLAT unterteilt Vektordaten in eine Anzahl von Clustereinheiten (nlist) und vergleicht dann die Abstände zwischen dem Zieleingabevektor und dem Zentrum jedes Clusters. Abhängig von der Anzahl der Cluster, die das System abfragen soll (nprobe), werden Ähnlichkeitssuchergebnisse ausschließlich auf Grundlage von Vergleichen zwischen der Zieleingabe und den Vektoren in den ähnlichsten Clustern zurückgegeben — wodurch die Abfragezeit drastisch reduziert wird.
Durch Anpassung von nprobe kann für ein bestimmtes Szenario ein ideales Gleichgewicht zwischen Genauigkeit und Geschwindigkeit gefunden werden. Ergebnisse unseres IVF_FLAT-Leistungstests zeigen, dass die Abfragezeit stark ansteigt, wenn sowohl die Anzahl der Zieleingabevektoren (nq) als auch die Anzahl der zu durchsuchenden Cluster (nprobe) zunehmen. IVF_FLAT komprimiert Vektordaten jedoch nicht; Indexdateien enthalten Metadaten, die die Speicheranforderungen im Vergleich zum rohen, nicht indexierten Vektordatensatz geringfügig erhöhen.
IVF_FLAT-Leistungstestergebnisse:
Die Leistungstests der IVF_FLAT-Abfragezeit wurden in Milvus mit dem öffentlichen 1B SIFT-Datensatz durchgeführt, der 1 Milliarde 128-dimensionale Vektoren enthält.
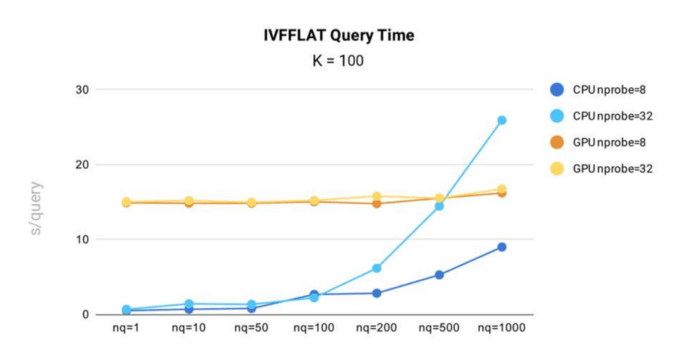 Testergebnisse der Abfragezeit für den IVF_FLAT-Index in Milvus.
Testergebnisse der Abfragezeit für den IVF_FLAT-Index in Milvus.
Wichtigste Erkenntnisse:
- Bei Ausführung auf CPU steigt die Abfragezeit für den IVF_FLAT-Index in Milvus sowohl mit nprobe als auch mit nq. Das bedeutet: Je mehr Eingabevektoren eine Abfrage enthält oder je mehr Cluster eine Abfrage durchsucht, desto länger wird die Abfragezeit sein.
- Auf GPU zeigt der Index geringere Zeitvarianz gegenüber Änderungen in nq und nprobe. Das liegt daran, dass die Indexdaten groß sind und das Kopieren von Daten aus dem CPU-Speicher in den GPU-Speicher den Großteil der gesamten Abfragezeit ausmacht.
- In allen Szenarien, außer wenn nq = 1,000 und nprobe = 32, ist der IVF_FLAT-Index effizienter, wenn er auf CPU ausgeführt wird.
Die Leistungstests des IVF_FLAT-Recalls wurden in Milvus sowohl mit dem öffentlichen 1M SIFT-Datensatz, der 1 Million 128-dimensionale Vektoren enthält, als auch mit dem glove-200-angular-Datensatz, der über 1 Million 200-dimensionale Vektoren enthält, für den Indexaufbau durchgeführt (nlist = 16,384).
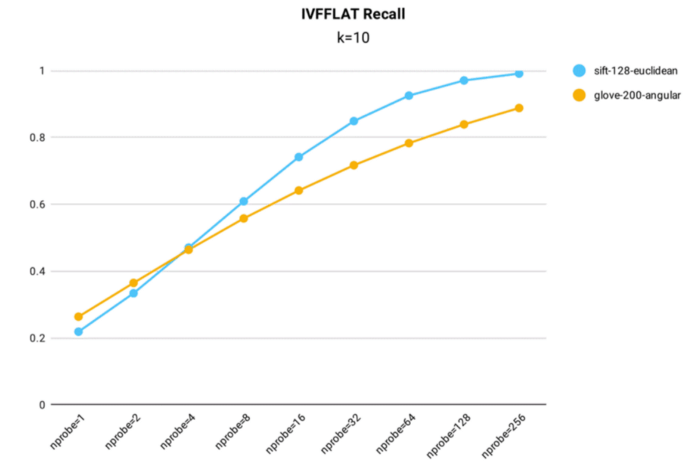 Testergebnisse der Recall-Rate für den IVF_FLAT-Index in Milvus.
Testergebnisse der Recall-Rate für den IVF_FLAT-Index in Milvus.
Wichtigste Erkenntnisse:
- Der IVF_FLAT-Index kann auf Genauigkeit optimiert werden und erreicht eine Recall-Rate von über 0,99 auf dem 1M SIFT-Datensatz, wenn nprobe = 256.
IVF_SQ8: Schneller und ressourcenschonender als IVF_FLAT, aber auch weniger genau.
IVF_FLAT führt keine Komprimierung durch, daher sind die von ihm erzeugten Indexdateien ungefähr so groß wie die ursprünglichen, rohen, nicht indizierten Vektordaten. Wenn beispielsweise der ursprüngliche 1B SIFT-Datensatz 476 GB groß ist, werden seine IVF_FLAT-Indexdateien etwas größer sein (~470 GB). Das Laden aller Indexdateien in den Speicher verbraucht 470 GB Speicherplatz.
Wenn Festplatten-, CPU- oder GPU-Speicherressourcen begrenzt sind, ist IVF_SQ8 eine bessere Option als IVF_FLAT. Dieser Indextyp kann durch skalare Quantisierung jeden FLOAT (4 Byte) in UINT8 (1 Byte) umwandeln. Dadurch wird der Speicherverbrauch auf Festplatte, CPU und GPU um 70–75% reduziert. Für den 1B SIFT-Datensatz benötigen die IVF_SQ8-Indexdateien nur 140 GB Speicherplatz.
IVF_SQ8-Leistungstestergebnisse:
Die Testung der IVF_SQ8-Abfragezeit wurde in Milvus unter Verwendung des öffentlichen 1B SIFT-Datensatzes durchgeführt, der 1 Milliarde 128-dimensionale Vektoren enthält, für den Indexaufbau.
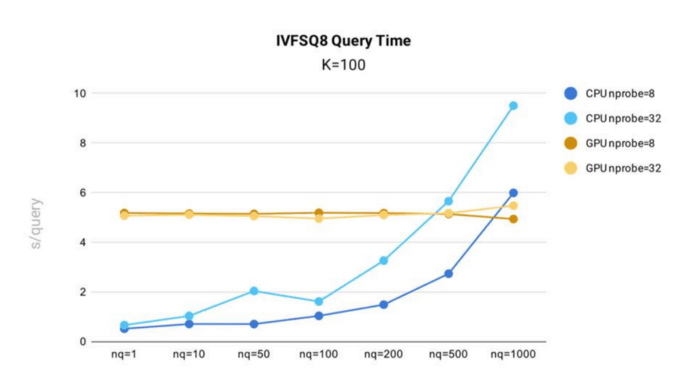 Testergebnisse der Abfragezeit für den IVF_SQ8-Index in Milvus.
Testergebnisse der Abfragezeit für den IVF_SQ8-Index in Milvus.
Wichtigste Erkenntnisse:
- Durch die Reduzierung der Größe der Indexdateien bietet IVF_SQ8 deutliche Leistungsverbesserungen gegenüber IVF_FLAT. IVF_SQ8 folgt einer ähnlichen Leistungskurve wie IVF_FLAT, wobei die Abfragezeit mit nq und nprobe steigt.
- Ähnlich wie IVF_FLAT zeigt IVF_SQ8 eine schnellere Leistung, wenn es auf der CPU ausgeführt wird und wenn nq und nprobe kleiner sind.
Die Testung der Recall-Leistung von IVF_SQ8 wurde in Milvus unter Verwendung sowohl des öffentlichen 1M SIFT-Datensatzes, der 1 Million 128-dimensionale Vektoren enthält, als auch des glove-200-angular-Datensatzes, der über 1 Million 200-dimensionale Vektoren enthält, für den Indexaufbau durchgeführt (nlist = 16,384).
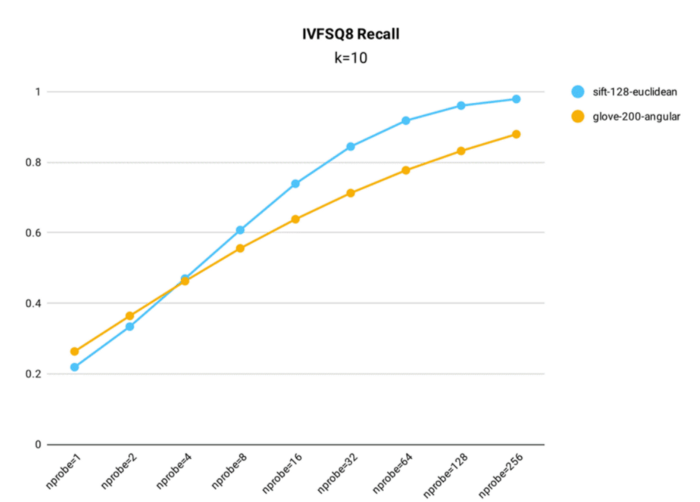 Testergebnisse der Recall-Rate für den IVF_SQ8-Index in Milvus.
Testergebnisse der Recall-Rate für den IVF_SQ8-Index in Milvus.
Wichtigste Erkenntnisse:
- Trotz der Komprimierung der ursprünglichen Daten zeigt IVF_SQ8 keinen signifikanten Rückgang der Abfragegenauigkeit. Über verschiedene nprobe-Einstellungen hinweg hat IVF_SQ8 höchstens eine um 1% niedrigere Recall-Rate als IVF_FLAT.
IVF_SQ8H: Neuer hybrider GPU/CPU-Ansatz, der noch schneller ist als IVF_SQ8.
IVF_SQ8H ist ein neuer Indextyp, der die Abfrageleistung im Vergleich zu IVF_SQ8 verbessert. Wenn ein auf der CPU ausgeführter IVF_SQ8-Index abgefragt wird, wird der Großteil der gesamten Abfragezeit dafür aufgewendet, nprobe-Cluster zu finden, die dem Ziel-Eingabevektor am nächsten liegen. Um die Abfragezeit zu reduzieren, kopiert IVF_SQ8 die Daten für Coarse-Quantizer-Operationen, die kleiner als die Indexdateien sind, in den GPU-Speicher — wodurch Coarse-Quantizer-Operationen stark beschleunigt werden. Anschließend bestimmt gpu_search_threshold, welches Gerät die Abfrage ausführt. Wenn nq >= gpu_search_threshold, führt die GPU die Abfrage aus; andernfalls führt die CPU die Abfrage aus.
IVF_SQ8H ist ein hybrider Indextyp, bei dem CPU und GPU zusammenarbeiten müssen. Er kann nur mit GPU-fähigem Milvus verwendet werden.
IVF_SQ8H-Leistungstestergebnisse:
Die Testung der IVF_SQ8H-Abfragezeitleistung wurde in Milvus unter Verwendung des öffentlichen 1B SIFT-Datensatzes durchgeführt, der 1 Milliarde 128-dimensionale Vektoren enthält, für den Indexaufbau.
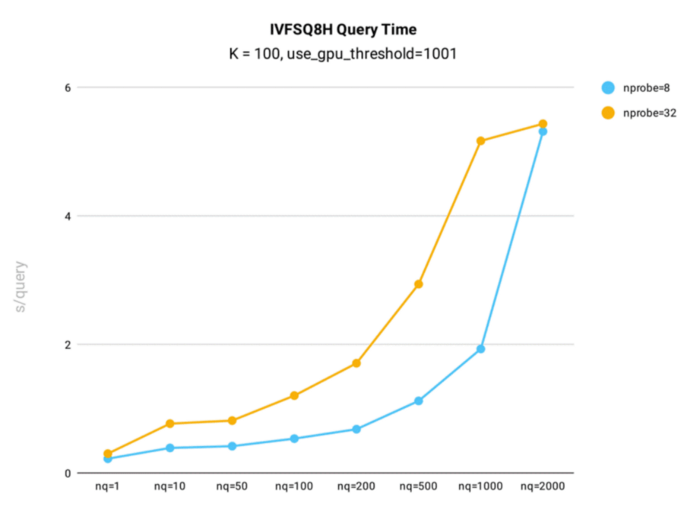 Testergebnisse der Abfragezeit für den IVF_SQ8H-Index in Milvus.
Testergebnisse der Abfragezeit für den IVF_SQ8H-Index in Milvus.
Wichtigste Erkenntnisse:
- Wenn nq kleiner oder gleich 1.000 ist, erreicht IVF_SQ8H Abfragezeiten, die nahezu doppelt so schnell sind wie IVFSQ8.
- Wenn nq = 2000, sind die Abfragezeiten für IVFSQ8H und IVF_SQ8 gleich. Wenn der Parameter gpu_search_threshold jedoch niedriger als 2000 ist, wird IVF_SQ8H IVF_SQ8 übertreffen.
- Die Abfrage-Recall-Rate von IVF_SQ8H ist identisch mit der von IVF_SQ8, was bedeutet, dass eine kürzere Abfragezeit ohne Verlust der Suchgenauigkeit erreicht wird.
Erfahren Sie mehr über Milvus, eine Vektordatenmanagement-Plattform für massive Skalierung.
Milvus ist eine Plattform zur Verwaltung von Vektordaten, die Anwendungen für die Ähnlichkeitssuche in Bereichen wie künstlicher Intelligenz, Deep Learning, traditionellen Vektorberechnungen und mehr ermöglichen kann. Weitere Informationen zu Milvus finden Sie in den folgenden Ressourcen:
- Milvus ist unter einer Open-Source-Lizenz auf GitHub verfügbar.
- Zusätzliche Indextypen, einschließlich graph- und baumbasierter Indizes, werden in Milvus unterstützt. Eine umfassende Liste der unterstützten Indextypen finden Sie in der Dokumentation zu Vektorindizes in Milvus.
- Um mehr über das Unternehmen zu erfahren, das Milvus ins Leben gerufen hat, besuchen Sie Zilliz.com.
- Chatten Sie mit der Milvus-Community oder erhalten Sie Hilfe bei einem Problem auf Slack.
Methodik
Umgebung für Leistungstests
Die Serverkonfiguration, die in den in diesem Artikel genannten Leistungstests verwendet wurde, lautet wie folgt:
- Intel (R) Xeon (R) Platinum 8163 @ 2.50GHz, 24 Kerne
- GeForce GTX 2080Ti x 4
- 768 GB Arbeitsspeicher
Relevante technische Konzepte
Obwohl sie für das Verständnis dieses Artikels nicht erforderlich sind, finden Sie hier einige technische Konzepte, die bei der Interpretation der Ergebnisse unserer Index-Leistungstests hilfreich sind:
 Blog_Accelerating Similarity Search on Really Big Data with Vector Indexing_8.png
Blog_Accelerating Similarity Search on Really Big Data with Vector Indexing_8.png
Ressourcen
Die folgenden Quellen wurden für diesen Artikel verwendet:
- „Encyclopedia of database systems,“ Ling Liu und M. Tamer Özsu.
Was kommt als Nächstes
Lesen Sie weiter: Accelerating Similarity Search on Really Big Data with Vector Indexing: Part II.
Weiterlesen

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.