




LlamaIndex
LlamaIndex Integration | Build Retrieval-Augmented Generation applications with Zilliz Cloud and Milvus Vector Database
Use esta integração gratuitamenteIntegração do LlamaIndex, criar aplicações de recuperação-geração aumentada com o Zilliz Cloud
O LlamaIndex (anteriormente GPT Index) é uma estrutura de dados adaptada a aplicações de Modelos de Linguagem de Grande Porte (LLM), que facilita a ingestão, estruturação e acesso a dados privados ou de domínios específicos. Na sua essência, os LLM actuam como uma ponte entre a linguagem humana e os dados inferidos, tanto estruturados como não estruturados. Embora as LLM amplamente acessíveis cheguem pré-treinadas em extensos conjuntos de dados publicamente disponíveis, muitas vezes faltam-lhes dados críticos, o que resulta em alucinações ou respostas incorrectas geradas pelas LLM.
O LlamaIndex integra-se com bases de dados vectoriais:
- Uso do índice interno: O LlamaIndex pode funcionar como um índice usando um banco de dados vetorial. Semelhante aos índices tradicionais, este índice baseado no LlamaIndex pode armazenar documentos e responder eficazmente a consultas.
- Integração de dados externos: O LlamaIndex pode recuperar dados de armazéns vectoriais, funcionando como um conetor de dados convencional. Uma vez recuperados, estes dados podem ser integrados sem problemas nas estruturas de dados do LlamaIndex para posterior processamento e utilização. Este processo é frequentemente designado por Retrieval-Augmented Generated ou RAG.
Como funciona a integração do LlamaIndex com o Zilliz Cloud
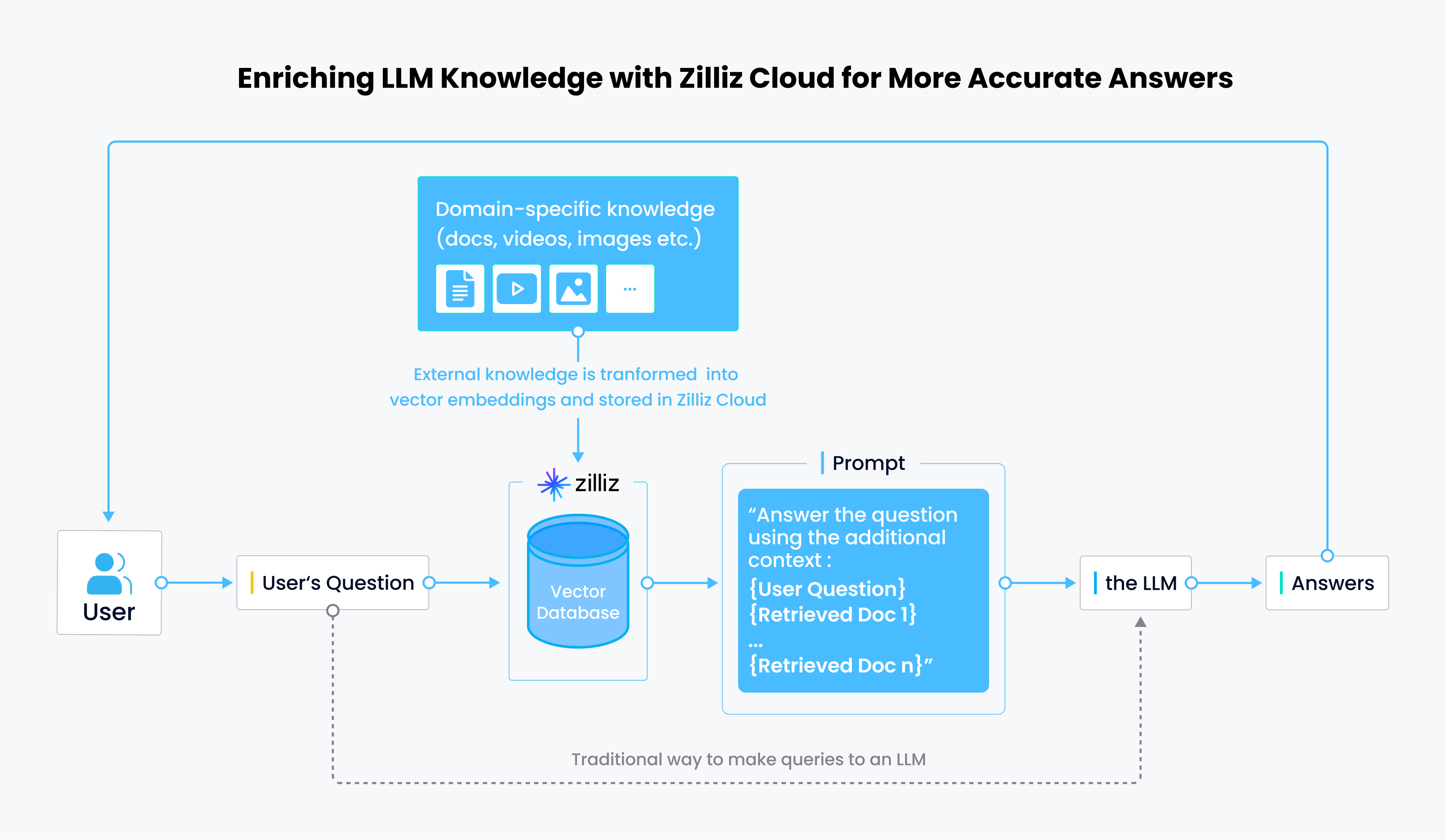
Saiba mais sobre como utilizar o Llama
- Tutorial | Introdução ao LlamaIndex
- Docs | Garantia de qualidade da documentação usando Zilliz Cloud e LlamaIndex
- Vídeo com Yujian Tang | Armazenamento vetorial persistente com LlamaIndex
- Vídeo com Jerry Liu, CEO da LlamaIndex | Impulsione o seu LLM com dados privados utilizando a LlamaIndex
- Construindo um Chatbot com Zilliz Cloud, LlamaIndex e LangChain Parte I
- Construindo aplicações LLM com respostas 100x mais rápidas e redução drástica de custos usando GPTCache