




Tudo o que Você Precisa Saber sobre Llama 2

Tudo o que Você Precisa Saber sobre Llama 2
O que é o Llama 2?
O Llama 2, apresentado pela Meta AI em 2023, é um avanço significativo em modelos de linguagem grandes (LLMs). Esses modelos, Llama 2 e Llama 2-CHAT, escalam até 70 bilhões de parâmetros e estão disponíveis para fins de pesquisa e comerciais sem custo, representando um salto nas capacidades de processamento de linguagem natural (NLP), da geração de texto à interpretação de código de programação.
Com base em seu antecessor, LLaMa 1, que inicialmente era acessível apenas a instituições de pesquisa sob uma licença não comercial, o Llama 2 marca uma mudança importante rumo à democratização do acesso a tecnologias de IA de ponta. Ao contrário de seu antecessor, os modelos Llama 2 são “open-source” e, portanto, estão livremente disponíveis para pesquisa e aplicações comerciais, refletindo o compromisso da Meta em promover um ecossistema de IA generativa mais inclusivo e colaborativo.
O lançamento do Llama 2 oferece acesso a LLMs de última geração e aborda os desafios computacionais associados ao seu desenvolvimento. Ao otimizar o desempenho sem aumentar exponencialmente a contagem de parâmetros, o Llama 2 oferece modelos com tamanhos de parâmetros variados, que vão de 7 bilhões a 70 bilhões. Essa abordagem estratégica permite que organizações menores e comunidades de pesquisa aproveitem o poder dos LLMs sem recursos computacionais exorbitantes.
Além disso, a dedicação da Meta à transparência fica evidente em sua decisão de lançar tanto o código quanto os pesos do modelo do Llama 2, facilitando maior compreensão e colaboração dentro da comunidade de pesquisa em IA. Ao reduzir as barreiras de entrada e promover a acessibilidade, o Llama 2 abre caminho para um futuro mais inclusivo e inovador na pesquisa e no desenvolvimento de IA.
Llama 2
O Llama 2 é uma versão atualizada do Llama 1 treinada em uma nova combinação de dados públicos. O conjunto de dados pré-treinado foi aumentado em 40%, o comprimento do contexto foi duplicado, e a equipe da Meta adotou atenção grouped-query ao criar o Llama 2.
| Dados de Treinamento | Parâmetros | Comprimento do Contexto | Atenção grouped-query | Tokens | |
| Llama 1 | Veja Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Uma nova combinação de dados online disponíveis publicamente | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT é uma versão ajustada do Llama 2 que a equipe da Meta otimizou para casos de uso de linguagem natural. As variantes deste modelo estão disponíveis com 7B, 13B e 70B parâmetros. O Llama 2-Chat está sujeito às mesmas limitações bem reconhecidas de outros LLMs, incluindo a cessação de atualizações de conhecimento após o pré-treinamento, potencial para geração não factual, como conselhos não qualificados, e uma propensão a alucinações.
Código aberto do Llama 2
Embora a Meta tenha generosamente fornecido acesso ao código inicial e aos pesos do modelo para os modelos Llama 2 para fins de pesquisa e comerciais, surgiram discussões sobre a adequação de rotulá-lo como "código aberto" devido a certas restrições descritas em seu contrato de licenciamento.
O debate em torno da classificação dos termos de licenciamento do Llama 2 depende de nuances técnicas e semânticas. Embora "código aberto" seja comumente usado coloquialmente para denotar qualquer software com código-fonte livremente acessível, ele carrega um significado específico como uma designação formal supervisionada pela Open Source Initiative (OSI). Para se qualificar como "aprovado pela Open Source Initiative", uma licença de software deve aderir aos dez critérios descritos na Definição Oficial de Código Aberto (OSD).
Assim, a aplicabilidade do rótulo "código aberto" aos modelos Llama 2 depende de seus termos de licenciamento estarem alinhados com os critérios rigorosos estabelecidos pela OSI. Essa distinção destaca a importância da clareza e da precisão ao discutir a acessibilidade e a distribuição de recursos de software dentro da comunidade de desenvolvimento mais ampla.
No entanto, embora o Llama 2 não seja totalmente de código aberto, ele oferece aos desenvolvedores um modelo atraente com muito mais flexibilidade do que os modelos fechados criados pela OpenAI, Google e outros grandes participantes no campo da IA generativa.
Arquitetura do Llama 2
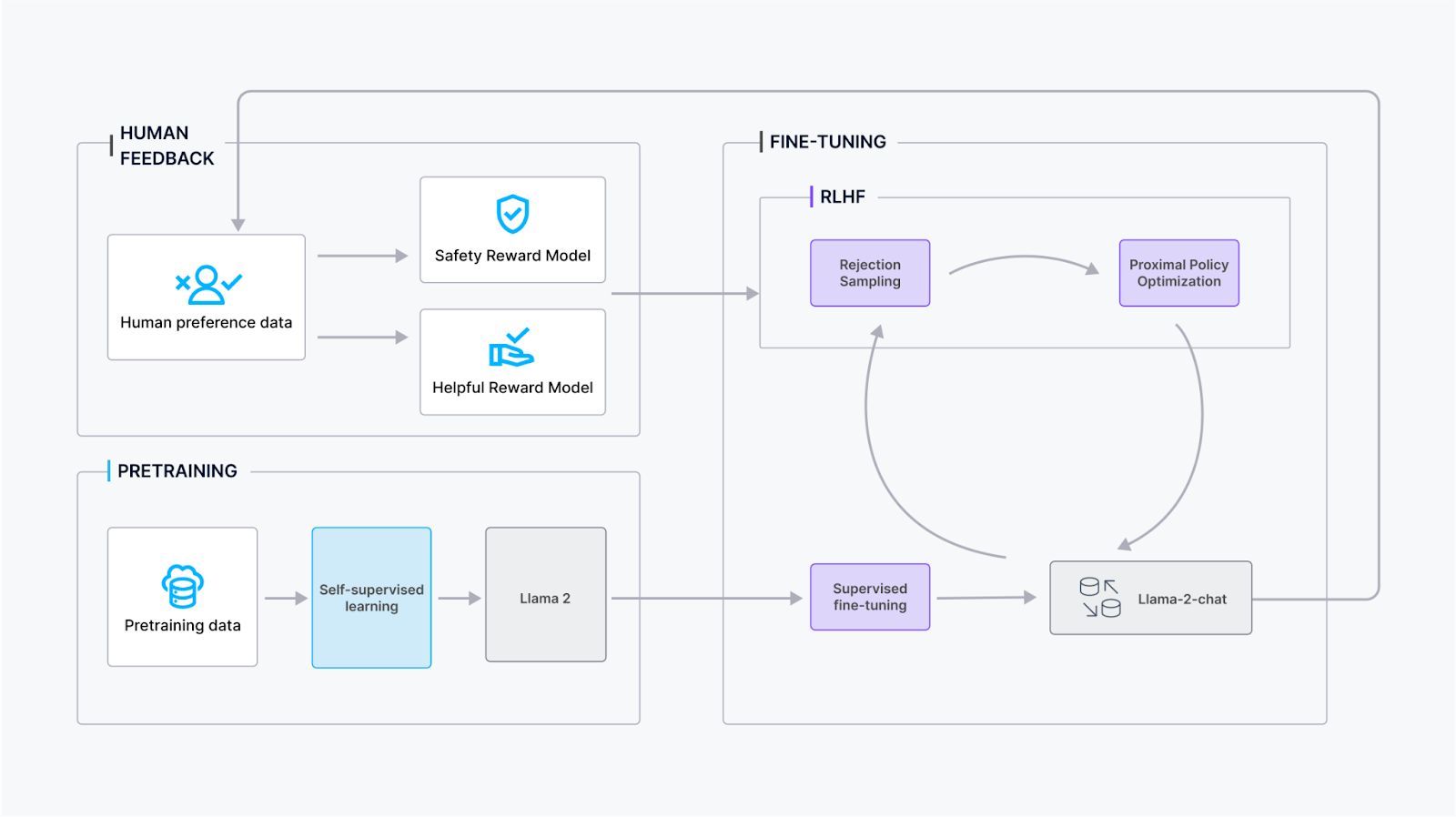
O processo de treinamento do Llama 2-Chat envolve várias etapas para garantir desempenho e refinamento ideais:
Pré-treinamento: O Llama 2 passa por pré-treinamento usando fontes online publicamente disponíveis para estabelecer conhecimento fundamental e compreensão linguística.
Ajuste fino supervisionado: A equipe da Meta criou uma versão inicial do Llama 2-Chat por meio de ajuste fino supervisionado, em que o modelo aprende a partir de dados rotulados para melhorar suas capacidades conversacionais.
Aprendizado por reforço com feedback humano (RLHF): O modelo passa por refinamento iterativo usando metodologias de RLHF, principalmente por meio de amostragem por rejeição e Proximal Policy Optimization (PPO). Esta etapa envolve interação contínua com feedback humano para melhorar a qualidade conversacional.
Modelagem iterativa de recompensas: Ao longo da etapa de RLHF, o acúmulo de dados de modelagem iterativa de recompensas ocorre em paralelo com os aprimoramentos do modelo. A modelagem iterativa de recompensas garante que os modelos de recompensa permaneçam dentro da distribuição, contribuindo para a melhoria consistente das capacidades conversacionais do modelo.
Ao incorporar essas etapas, o treinamento do Llama 2-Chat visa alcançar um desempenho conversacional robusto, ao mesmo tempo em que se adapta ao feedback do usuário e mantém o alinhamento com os modelos de recompensa.
O que é um Embedding em Machine Learning?
Em machine learning, um embedding refere-se a uma representação aprendida de objetos em um espaço vetorial contínuo, como palavras, imagens ou entidades. Esses embeddings capturam relações semânticas e semelhanças entre objetos, tornando-os mais adequados para tarefas computacionais. Em processamento de linguagem natural (NLP), embeddings de palavras, por exemplo, mapeiam palavras de um vocabulário para vetores densos em um espaço de alta dimensionalidade, onde palavras semelhantes ficam próximas umas das outras.
No Llama 2, embeddings desempenham um papel crucial na compreensão e geração de linguagem natural. O Llama 2 usa embeddings para representar palavras, frases ou sentenças inteiras em um espaço vetorial contínuo. O Llama 2 pode processar e gerar texto de forma eficaz ao incorporar entradas e saídas de linguagem enquanto captura relações semânticas e nuances.
Por exemplo, o Llama 2 aprende embeddings para palavras e frases a partir do vasto corpus de texto no qual é treinado durante o processo de treinamento. Esses embeddings codificam informações semânticas sobre a linguagem, permitindo que o Llama 2 compreenda e gere respostas coerentes a consultas ou prompts.
Embeddings em aprendizado de máquina, incluindo aqueles usados no Llama 2, facilitam a representação de linguagem e outros dados de uma forma estruturada e semanticamente significativa, possibilitando processamento, compreensão e geração eficazes de linguagem natural.
Como Usar o Llama 2?
Para usar o Llama 2 de forma eficaz, acesse o modelo por meio da interface ou API fornecida, garantindo que as permissões estejam em vigor. Prepare seus dados de entrada, sejam texto, imagens ou formatos compatíveis, e faça o pré-processamento conforme necessário. Especifique a tarefa para o Llama 2, como geração de texto ou sumarização. Insira os dados pré-processados no Llama 2, recupere a saída e avalie sua qualidade. Experimente diferentes formatos e configurações para otimizar os resultados. Monitore métricas de desempenho, como precisão e velocidade, ajustando estratégias com base no feedback. Mantenha-se atualizado sobre melhorias para maximizar a eficácia, desbloqueando novas possibilidades para projetos e aplicações. Você também pode usar o Llama 2 com ferramentas como LangChain, LlamaIndex e Semantic Kernel ao criar aplicações RAG.
Desempenho do Llama 2
O desempenho geral pode ser visto observando alguns benchmarks agregados populares. Aqui está uma tabela de resultados sobre o desempenho em comparação com modelos baseados em código aberto, conforme observado no artigo do LLama 2:
| Modelo | Tamanho | Código | Raciocínio de Senso Comum | Conhecimento Mundial | Compreensão de Leitura | Matemática | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Você pode ver que o Llama 2 supera o Llama 1 em várias categorias, como MMLU e BBH, e até mesmo tem um bom desempenho em comparação com o modelo Falcon.
Llama 2 vs GPT 4
O artigo do Llama 2 também cobre algumas comparações entre o Llama 2, o GPT 4 e alguns outros, como mostrado abaixo:
| Benchmark (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot): O modelo recebe 5 trechos ou exemplos para gerar uma resposta.
- TriviaQA (1-shot): Um conjunto de dados em que o modelo recebe um único contexto ou pergunta antes de gerar uma resposta.
- Natural Questions (1-shot): Outro conjunto de dados em que o modelo recebe uma pergunta como entrada.
- GSM8K (8-shot): Um conjunto de dados em que o modelo recebe 8 trechos ou exemplos para responder a perguntas ou realizar tarefas.
- HumanEval (0-shot): Um conjunto de dados ou configuração de avaliação em que o modelo é avaliado em tarefas ou perguntas nas quais não foi explicitamente treinado, daí "0-shot."
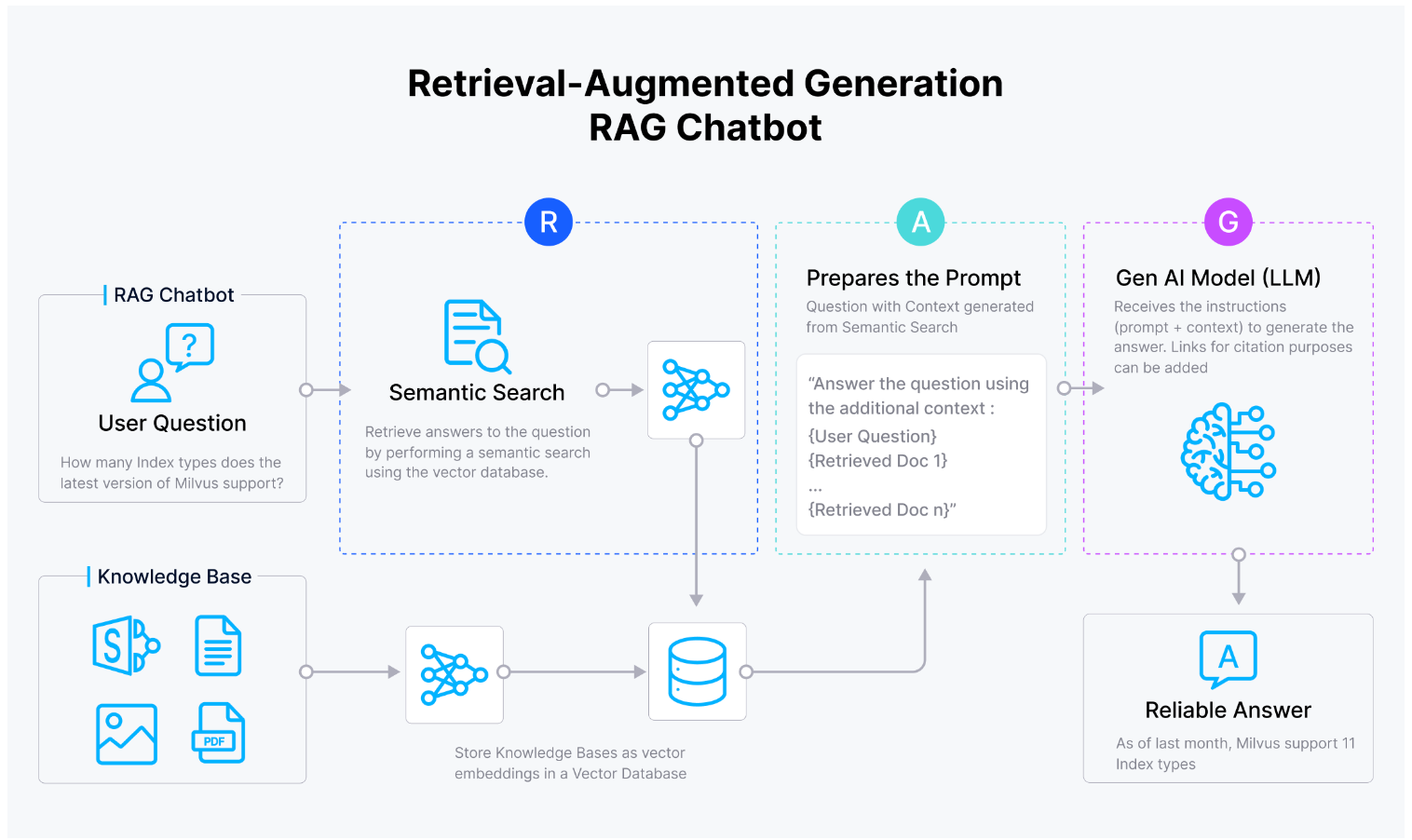
O Zilliz Funciona com o Llama 2?
O caso de uso mais comum do Zilliz Cloud em conjunto com o Llama 2 é o desenvolvimento de aplicações de Geração Aumentada por Recuperação (RAG). As aplicações RAG aproveitam os recursos de grandes modelos de linguagem (LLMs) como o Llama 2, que são treinados em vastos conjuntos de dados, mas operam inerentemente dentro dos limites de dados finitos. Por si só, o Llama 2 tem a propensão a "alucinar" respostas, gerando respostas mesmo quando pode não haver contexto suficiente ou informações precisas. RAG é uma forma de abordar essa alucinação.
A combinação do Zilliz Cloud e do Llama 2 permite que os usuários integrem perfeitamente recursos avançados de compreensão e geração de linguagem com sistemas de recuperação baseados em vetores eficientes e escaláveis fornecidos pelo Zilliz Cloud. Ao aproveitar os pontos fortes de ambas as plataformas, os desenvolvedores podem criar aplicações sofisticadas que se destacam em tarefas que exigem processamento abrangente de linguagem, recuperação de informações e funcionalidades de geração.
Recursos Principais
- O que é o Llama 2?
- Arquitetura do Llama 2
- O que é um Embedding em Machine Learning?
- Como Usar o Llama 2?
- Desempenho do Llama 2
- Llama 2 vs GPT 4
- O Zilliz Funciona com o Llama 2?
- Recursos Principais
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis