




Da extração aos conhecimentos: Compreender o ETL

Da extração aos conhecimentos: Compreender o ETL
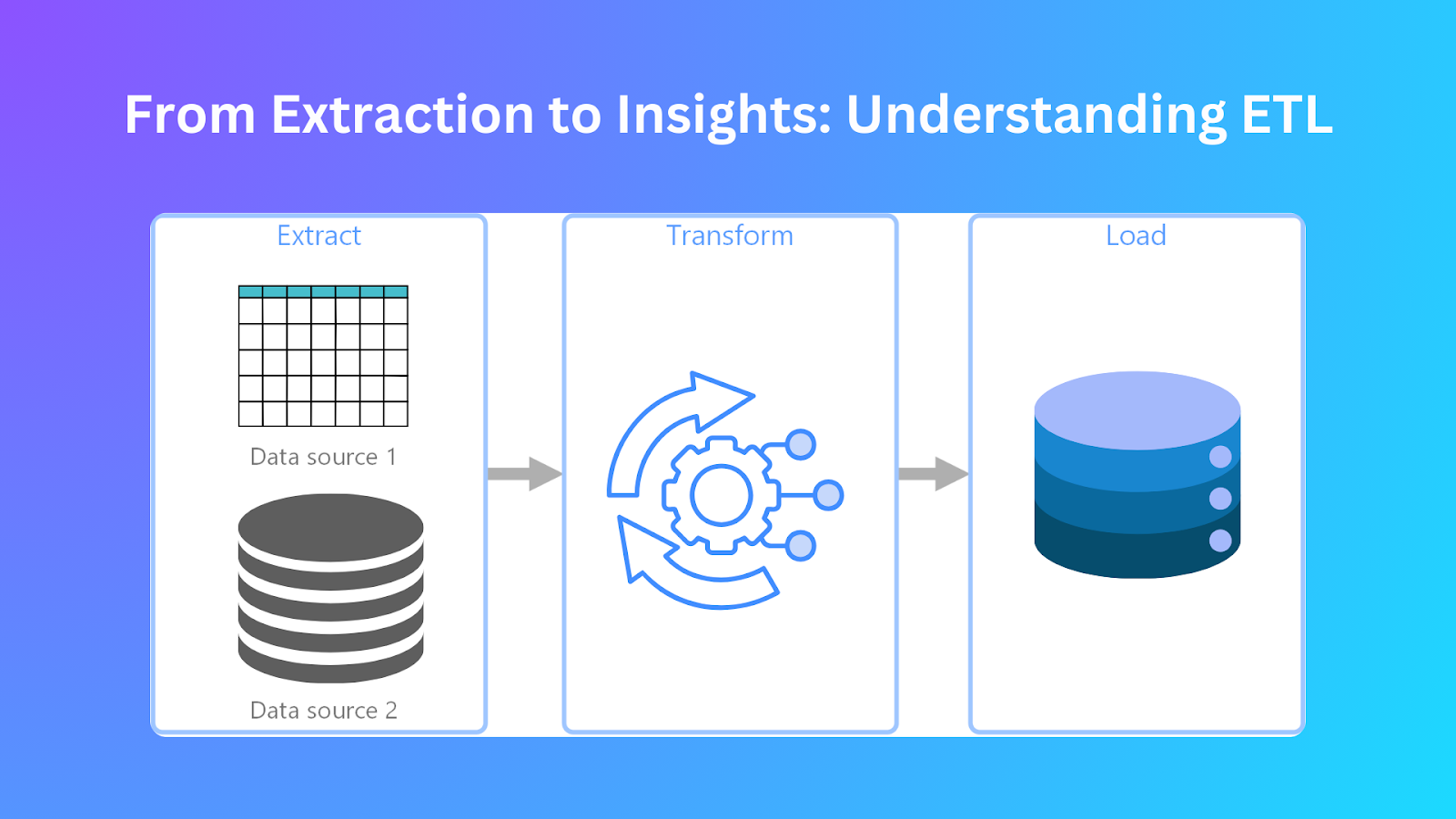 ETL Pipeline.png
ETL Pipeline.png
Como é que as empresas convertem enormes [conjuntos de dados] brutos (https://zilliz.com/learn/popular-datasets-for-natural-language-processing) em conhecimentos poderosos? Que passos é que as organizações dão para integrar e refinar os dados antes da análise? A resposta está em Extrair, Transformar e Carregar (ETL).
A ETL é a chave para a gestão de dados moderna. Permite às organizações recolher, processar e carregar dados para análise. O ETL extrai informações de vários recursos, modifica-as para eliminar erros e, em seguida, coloca-as numa base de dados centralizada. Este processo permite obter informações refinadas, exactas e organizadas, ajudando na tomada de decisões empresariais.
Os dados sem ETL são difíceis de analisar devido à sua natureza dispersa e distorcida. Dados ineficientes podem levar a erros, afectando vários aspectos como a relação com o cliente ou o desempenho operacional. O ETL resolve a má qualidade dos dados, automatizando os fluxos de trabalho e mantendo a integridade dos dados. Isto ajuda a empresa a simplificar a elaboração de relatórios, a melhorar a análise e a tomar melhores decisões.
Com as empresas a tornarem tudo orientado para os dados, torna-se crucial compreender o ETL. Quer esteja a trabalhar com [bases de dados] estruturadas (https://docs.zilliz.com/docs/database), sistemas em nuvem ou análises em tempo real, o ETL garante a integração e o processamento de dados de qualidade.
Este artigo abordará o funcionamento do ETL, o seu impacto e a forma como uma organização o pode utilizar na íntegra. Também revelaremos as principais ferramentas que podem ser utilizadas para facilitar o processo de ETL.
O que é ETL (Extract, Transform, and Load)?
ETL é o processo central de gestão e integração de dados. Começa por extrair dados de diferentes fontes antes de os transformar num formato adequado para serem carregados em destinos de destino, como armazéns de dados ou lagos de dados. As organizações conseguem a consolidação de dados unindo fontes de dados separadas num único repositório para apoiar a análise.
O ETL é a espinha dorsal para manter a consistência, a qualidade e a acessibilidade dos dados, independentemente das diferenças de sistema ou de plataforma. Esta abordagem serve vários sectores, incluindo finanças, cuidados de saúde e comércio eletrónico.
As empresas utilizam este método para organizar os seus dados e eliminar inconsistências, o que melhora as capacidades de tomada de decisões. As ferramentas ETL modernas podem processar eficazmente dados estruturados e não estruturados.
Um sistema de pipeline ETL bem concebido permite que as organizações analisem tendências e descubram informações. O fluxo de trabalho automatizado aumenta a eficiência operacional através da automatização do processamento de dados. As empresas utilizam o ETL para criar uma visão unificada que suporta relatórios precisos e actividades de planeamento estratégico.
Como funciona o ETL
O processamento de dados através de ETL segue um processo de três etapas que assegura a exatidão e a eficiência durante cada etapa. Estas etapas são:
Extração
O pipeline ETL começa com a extração de dados como fase inicial. Esta fase recolhe dados de diferentes fontes antes de os unir para efeitos de processamento. Através do processo de extração, as organizações adquirem conjuntos de dados completos dos seus diversos sistemas, que incluem bases de dados, ficheiros simples, armazenamento na nuvem e APIs. Eis alguns dos passos da fase de extração de dados:
Identificação da fonte de dados: O primeiro passo na extração determina onde residem os dados. Os dados podem ser provenientes de bases de dados relacionais MySQL e PostgreSQL, bases de dados NoSQL MongoDB e Cassandra, ficheiros APIs, CSV ou JSON de terceiros e plataformas de dados de fluxo contínuo. A construção de um pipeline ETL eficaz requer a identificação correta das fontes de dados adequadas.
Recuperação de dados**: Os métodos de recuperação de dados dependem dos requisitos da empresa e das funcionalidades do sistema disponíveis. Os dados podem ser recuperados de duas formas: completa ou incremental. A extração completa recolhe todos os dados das fontes, enquanto a extração incremental apenas recolhe as alterações desde a última extração. A extração incremental é preferível porque encurta a duração do processamento e diminui a pressão sobre os sistemas de origem.
Tratamento de discrepâncias de dados:** Os dados extraídos podem conter campos vazios, tipos de dados inconsistentes e formatos estruturais. As organizações devem efetuar verificações de pré-processamento para identificar e gerir inconsistências antes de iniciar a fase de transformação.
Transformação
Após a extração, os dados têm de ser transformados para garantir a compatibilidade com o esquema do sistema de destino e aplicar regras comerciais. Este processo de transformação conduz a uma melhor qualidade dos dados, a dados consistentes e a uma maior facilidade de utilização. Aqui estão algumas das formas de transformar os seus dados:
Limpeza de dados: É um dos procedimentos fundamentais de transformação. Requer a remoção de duplicados, a imputação de valores para dados em falta e a normalização das convenções de nomenclatura. Isto ajuda a produzir relatórios precisos e isentos de erros.
Integração de dados**: Os dados são originários de várias fontes que contêm estruturas de dados separadas. A integração de dados cria uma visão de dados única e coerente a partir de vários conjuntos de dados separados. O processo envolve o mapeamento de diferentes nomes de colunas, a reconciliação de diferenças de fuso horário e a garantia de integridade referencial.
Agregação de dados**: Ajuda a resumir os dados para uma análise eficiente. As empresas necessitam frequentemente de relatórios que contenham totais de vendas regionais, médias de despesas trimestrais dos clientes e padrões de receitas mensais. O processo de agregação permite consultas de dados mais rápidas e simplifica a interpretação dos dados.
Conversão de dados**: Vários tipos de dados devem ser convertidos para serem compatíveis com o sistema necessário. A normalização dos formatos de dados é crucial, enquanto a normalização dos campos de texto e a conversão de unidades para dados numéricos completam o processo. O processo de transformação de dados garante que todos os dados carregados correspondem exatamente às necessidades analíticas.
Aplicação de regras de negócio**: Normalmente, as organizações criam regras de negócio para os processos de transformação de dados. Uma instituição financeira utiliza limiares de transação para desenvolver categorias e as empresas de comércio eletrónico dividem os seus clientes em segmentos com base na sua atividade de compra. As regras definidas geram valor através da organização de dados não processados em categorias funcionais.
Carregamento
Os dados transformados requerem o carregamento num sistema de destino, que pode ser um armazém de dados, um lago de dados ou uma base de dados analítica. O processo de carregamento estabelece o nível em que os dados podem ser consultados e analisados de forma eficiente.
Carregamento no sistema de destino**: Durante os procedimentos de carregamento completo, o sistema de destino recebe todos os dados numa única operação. Este método é utilizado principalmente durante a primeira migração de dados ou para tratar conjuntos de dados mais pequenos. Outra forma é carregar apenas novos registos e actualizações do sistema de origem. Este método reduz a duração do processamento, tornando as operações mais eficientes.
Indexação e particionamento:** Os métodos de indexação de dados e as técnicas de particionamento aceleram o desempenho do sistema nas pesquisas de registos. As técnicas de particionamento dividem as colecções de dados em segmentos mais pequenos, melhorando o desempenho das consultas e tornando os dados mais fáceis de gerir.
As organizações estabelecem estratégias de cópia de segurança para proteger os seus dados contra a perda durante as falhas do sistema. Este método mantém a proteção dos dados e garante a sua disponibilidade permanente.
Comparação: ETL vs. ELT
A integração de dados baseia-se em ETL (Extrair, Transformar, Carregar) e ELT (Extrair, Carregar, Transformar) como os seus principais métodos para transferir dados de várias fontes para armazéns ou lagos de dados. Os dois métodos partilham o objetivo de uma transferência de dados eficiente, mas funcionam de forma diferente quando processam e se adaptam aos sistemas de dados contemporâneos. Eis a comparação entre eles:
| Aspeto | ETL | ELT |
| Sequência do processo** | Extrair -> Transformar -> Carregar | Extrair -> Carregar -> Transformar |
| Transformação** | A transformação ocorre antes do carregamento no sistema de destino | A transformação ocorre após o carregamento no sistema de destino |
| Armazenamento de dados** | Os dados são armazenados em uma área de preparação temporária durante a transformação | Os dados são armazenados no sistema de destino e a transformação ocorre no local |
| Processamento de dados** | Os dados são processados em lotes, e o processamento é normalmente feito de forma linear | Os dados são processados em tempo real ou quase em tempo real, e o processamento pode ser feito em paralelo |
| Escalabilidade** | Pode ser menos escalável devido à necessidade de uma área de preparação e processamento em lote | Mais escalável devido à capacidade de processar dados em tempo real e em paralelo |
| Custo** | Pode ser mais dispendioso devido à necessidade de uma área de preparação e de processamento em lote | Pode ser menos dispendioso devido à capacidade de processar dados em tempo real e em paralelo |
| Flexibilidade** | Menos flexível devido à ordem rígida do processo | Mais flexível devido à capacidade de realizar transformações a qualquer momento |
| Adequado para processamento em lote, armazenamento de dados e business intelligence | Adequado para análise em tempo real, integração de dados e processamento de big data |
RTL vs ELT | Fonte
Benefícios e desafios
Embora a ETL suporte a extração, transformação e carregamento de dados, também tem vantagens e desafios. Vamos dar uma olhadela neles:
Benefícios
Rastreamento da linhagem de dados:** Os processos ETL rastreiam o movimento de dados das fontes para os destinos. As suas principais funções incluem a identificação de erros, a manutenção da integridade e a garantia da conformidade da exatidão.
Preservação de dados históricos**: O processo ETL captura instantâneos de dados ao longo do seu percurso, permitindo que as organizações mantenham informações históricas necessárias para a análise de tendências e relatórios. As empresas podem seguir os dados enquanto efectuam comparações para ajudar no seu processo de tomada de decisões.
Transformação de dados complexos**: As ferramentas ETL são excelentes na execução de transformações de dados complexas, incluindo processos de agregação, conversões de tipos de dados e a implementação de lógica empresarial. As capacidades do sistema facilitam as operações de limpeza de dados, produzindo informações estruturadas e normalizadas antes de o sistema de destino as receber.
Enriquecimento de dados:** O processo de enriquecimento de dados do ETL permite que as empresas combinem informações de várias bases de dados externas, melhorando assim a qualidade e a integridade do conjunto de dados. A incorporação de informações contextuais através do enriquecimento aumenta o conhecimento analítico, acrescentando valor aos dados para efeitos de tomada de decisões.
Eficiência do processamento em lote**: Os fluxos de trabalho ETL atingem a máxima eficiência através do processamento em lote, que lida com grandes volumes de dados durante os ciclos programados fora de pico. O processo minimiza o impacto no desempenho do sistema durante as horas normais de expediente, ao mesmo tempo que gere eficazmente grandes conjuntos de dados.
Desafios
Limitações de integração em tempo real**: Os processos tradicionais de ETL integram dados em lotes programados, o que limita os requisitos de dados em tempo real. As organizações que exigem capacidades analíticas e de tomada de decisões instantâneas encontram desafios devido aos atrasos associados aos processos ETL tradicionais.
Operações com uso intensivo de recursos:** Os requisitos computacionais para cargas de trabalho ETL tornam-se particularmente exigentes quando ocorrem processos de transformação e carregamento de dados. A elevada utilização de CPU e de recursos de memória diminui a velocidade das operações do sistema, afectando assim os níveis de desempenho.
Complexidade do tratamento de erros**: A gestão de erros torna-se difícil porque os pipelines ETL têm de lidar com inúmeras fontes de dados e regras de transformação complexas. São necessárias ferramentas de monitorização robustas e sistemas de depuração para identificar inconsistências, tratar dados em falta e gerir a qualidade.
Limitações de escalabilidade**: O volume crescente de dados apresenta desafios de escalabilidade que exigem que os processos ETL garantam novos investimentos em infra-estruturas ou adoptem arquitecturas redesenhadas. Quando a otimização dos dados é insuficiente, o aumento do volume de dados pode levar a atrasos no processamento e a limitações no desempenho do sistema.
Gestão de dependências**: As várias fases dos fluxos de trabalho ETL dependem umas das outras, pelo que qualquer falha num passo pode criar um efeito de cascata em todo o pipeline. Para evitar interrupções operacionais, a gestão eficaz das dependências exige uma programação minuciosa, juntamente com sistemas de monitorização e planos de mecanismos de recuperação de erros.
Casos de uso e ferramentas
O processo ETL é um requisito operacional fundamental para vários sectores, ajudando a conseguir uma integração e análise de dados eficientes. Aqui estão alguns dos casos de utilização e ferramentas:
Casos de utilização
Retalho:** O processo ETL permite que as lojas de retalho recolham dados do sistema de checkout, que normalizam em relação aos registos de inventário antes de os armazenarem numa base de dados unificada. O sistema permite o acompanhamento de dados de vendas, gestão de stocks e uma melhor compreensão do cliente.
Finanças:** As instituições financeiras aplicam métodos ETL para fundir dados de transacções de vários sistemas antes de os transformarem e carregarem em sistemas integrados de armazenamento de dados. O processo de consolidação permite às organizações detetar eficazmente a fraude, gerir os riscos e produzir relatórios conformes.
Cuidados de saúde**: As organizações de cuidados de saúde aplicam processos ETL para unir dados de registos médicos electrónicos (EMRs), bases de dados clínicas e sistemas administrativos. A integração do sistema permite uma melhor gestão dos cuidados aos pacientes com melhorias na eficiência operacional, apoiando simultaneamente processos de tomada de decisões informados.
Ferramentas ETL populares
AWS Glue: Um serviço de integração de dados sem servidor que facilita a ligação a mais de 70 fontes de dados diferentes. Ele oferece um catálogo de dados centralizado, um ambiente sem servidor e scripts personalizáveis.
Apache NiFi: Trata-se de um sistema de código aberto que permite o processamento automatizado de fluxos de dados através da sua funcionalidade ETL. O sistema oferece acesso baseado na Web fácil de utilizar, capacidades de processamento instantâneo e opções de personalização extensivas que beneficiam operações complexas de encaminhamento de dados.
Matillion: Uma ferramenta ETL nativa da nuvem que opera perfeitamente nas principais plataformas de dados baseadas na nuvem. Oferece recursos como IA generativa, conectores pré-construídos e fluxos de trabalho colaborativos.
As ferramentas e as suas aplicações demonstram como os métodos ETL são essenciais para converter dados brutos em conhecimentos práticos em vários domínios empresariais.
FAQs
- Qual é o principal objetivo do ETL?
O ETL funciona para fundir dados de várias fontes num único repositório unificado. O fluxo de trabalho de processamento de dados inclui três fases: os dados são extraídos das fontes e depois transformados de acordo com as necessidades operacionais antes de serem carregados num sistema analítico.
- Qual é a diferença entre ETL e ELT?
O processo ETL começa com a extração de dados dos sistemas de origem antes de os transformar numa área de preparação para os carregar para o sistema de destino. Os dados são então carregados no sistema de destino e as transformações são efectuadas diretamente nesse sistema.
- Quais são alguns dos desafios comuns na implementação de processos ETL?
A implementação de procedimentos ETL enfrenta vários obstáculos porque requer uma gestão eficaz dos dados de diferentes origens, controlo de qualidade e tratamento eficiente de quantidades substanciais de dados. Os desafios criam problemas de desempenho que exigem um planeamento minucioso dos recursos para serem resolvidos eficazmente.
- Os processos ETL podem ser automatizados?
As ferramentas ETL fornecem capacidades de automatização através de funcionalidades de programação e gestão do fluxo de trabalho para executar processos de transferência de dados. A automatização permite operações eficientes através do processamento automático de dados que reduz o envolvimento humano, mantendo uma qualidade de dados consistente para manter os conjuntos de dados actualizados para análise.
- Porque é que a transformação de dados é importante no ETL?
A transformação de dados no âmbito das operações ETL é fundamental para limpar, normalizar e formatar os dados obtidos de diferentes fontes. O processo de transformação de dados garante que o sistema de destino recebe dados precisos e consistentes para análise e elaboração de relatórios, o que apoia decisões comerciais fiáveis.
Recursos relacionados
Qual é o papel do ETL no processamento de grandes volumes de dados?
Como é que se integram dados de várias fontes para análise?](https://zilliz.com/ai-faq/how-do-you-integrate-data-from-multiple-sources-for-analytics)
Como sincronizar dados entre bases de dados relacionais e NoSQL?](https://zilliz.com/ai-faq/how-do-you-synchronize-data-between-relational-and-nosql-databases)
- O que é ETL (Extract, Transform, and Load)?
- Como funciona o ETL
- Comparação: ETL vs. ELT
- Benefícios e desafios
- Casos de uso e ferramentas
- FAQs
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis