




Entendendo o Algoritmo CURE: Uma Exploração Abrangente de Clustering com Representantes
 Representação Visual de Clustering
Representação Visual de Clustering
Figura 1: Representação Visual de Clustering
Como as empresas podem navegar pelo mercado em constante mudança e agrupar efetivamente clientes com padrões semelhantes? Métodos tradicionais de clustering frequentemente ficam aquém ao lidar com formatos de dados irregulares e outliers. A complexidade dos datasets modernos exige soluções mais inteligentes e adaptáveis.
Entra em cena o algoritmo CURE (Clustering Using Representatives), um método eficaz que aborda as limitações das abordagens padrão de clustering. O CURE usa uma seleção de pontos representativos para se diferenciar dos métodos clássicos de clustering, melhorando assim sua inteligência ao discernir distribuições de dados complexas. Esses pontos representativos se aproximam da média do cluster, tornando o algoritmo mais avançado ao permitir que ele lide com clusters de formatos arbitrários.
O CURE pode se tornar computacionalmente intensivo quando aplicado a datasets grandes. Apesar disso, sua abordagem para lidar com anomalias e clusters complexos permanece altamente eficaz. Vamos discutir as operações do algoritmo CURE explorando sua abordagem central, vantagens e aplicações práticas. Também abordaremos os desafios que você pode enfrentar ao implementar o CURE.
O Que É o Algoritmo CURE?
O algoritmo CURE usa uma abordagem de clustering hierárquico, que identifica formatos intricados de clusters e lida efetivamente com outliers. ****Diferentemente de algoritmos baseados em centroides, como k-means, o CURE representa clusters usando múltiplos pontos representativos. Esses pontos se movem em direção às médias dos clusters com um fator de encolhimento fixo para criar representações de clusters resilientes.
O CURE demonstra melhor flexibilidade do que o k-means porque seu design permite que ele trabalhe com vários tipos de datasets irregulares. Sua capacidade de superar as restrições dos algoritmos tradicionais em relação a clusters convexos ou equidistantes leva à detecção precisa dos limites e formatos dos clusters.
Como Funciona
Os algoritmos CURE envolvem múltiplas etapas para produzir a saída final. Vamos descobrir como eles selecionam dados para criar um cluster livre de outliers.
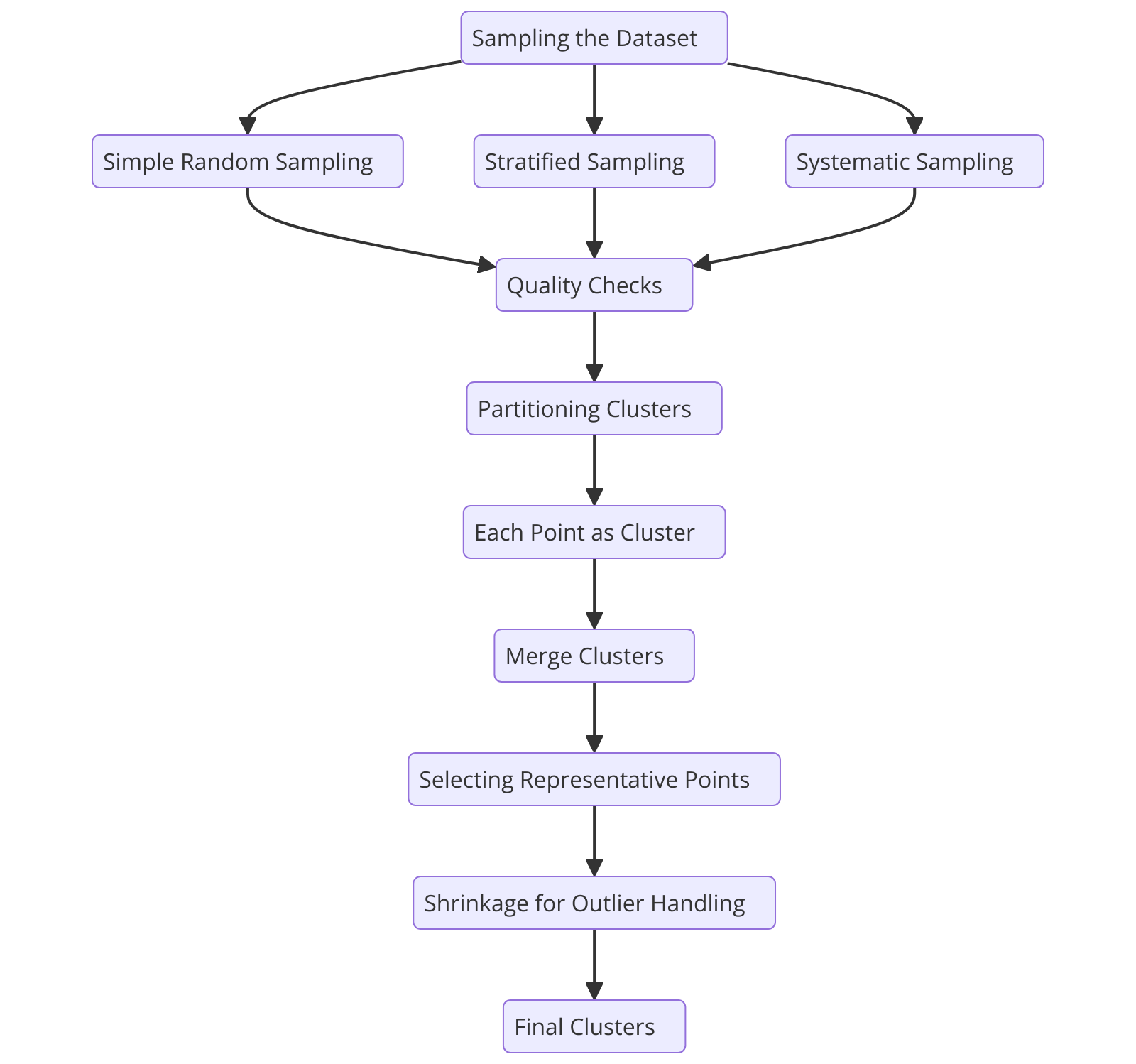 Fluxo do Processo do Algoritmo de Clustering CURE
Fluxo do Processo do Algoritmo de Clustering CURE
Figura 2: Fluxo do Processo do Algoritmo de Clustering CURE
Fluxo do Processo do Algoritmo de Clustering CURE
Para entender como o algoritmo CURE funciona, vamos detalhar seu processo passo a passo, começando pela amostragem do dataset.
Amostragem do Dataset
O CURE começa selecionando uma amostra aleatória representativa do dataset. O processo de amostragem reduz o número de pontos de dados, acelerando a velocidade de computação enquanto mantém a integridade do cluster.
A amostragem aleatória simples oferece implementação rápida, mas falha em capturar casos extremos cruciais. Isso produz uma representação inadequada de grupos minoritários em datasets desequilibrados. A amostragem estratificada se torna necessária quando a distribuição proporcional de diferentes classes nos dados precisa ser mantida.
Esse método garante que todos os pequenos subconjuntos significativos de dados permaneçam visíveis para análise. Outro método é a amostragem sistemática, que seleciona pontos de dados por meio de um sistema de intervalos regulares. A amostragem sistemática se destaca em séries temporais e dados ordenados, pois preserva a natureza temporal e o padrão de ordenação sequencial nos datasets.
Verificações de qualidade confirmam a consistência da amostra com a distribuição do dataset original após a coleta. Comparar valores médios, níveis de variância e características de distribuição ajuda a avaliar as semelhanças entre a amostra obtida e o dataset original completo. Estratégias rigorosas de amostragem implementadas pelo CURE permitem que o clustering subsequente represente com precisão a complexidade e a diversidade de todo o dataset.
Particionamento de Clusters
Após amostrar o conjunto de dados, o CURE aplica um método hierárquico que divide os dados em subconjuntos gerenciáveis. Notavelmente, ele usa uma estratégia de mesclagem de baixo para cima para clustering. O algoritmo mede as similaridades dos pontos de dados por meio de métricas de distância que usam distância euclidiana ou distância de Manhattan. As métricas de cálculo de distância são essenciais para determinar a proximidade dos pontos enquanto estabelecem uma base sólida para a mesclagem eficaz de clusters.
No início do processo, cada ponto de dados funciona como seu próprio cluster para representar a natureza refinada dos dados. O algoritmo realiza mesclagens sucessivas de clusters usando padrões de proximidade para agrupar pontos semelhantes. O algoritmo continua por meio de operações de mesclagem de clusters até que um número definido de clusters seja alcançado ou uma condição alternativa de término seja ativada.
O processo de seleção de grupos no CURE cria clusters que se alinham às categorias naturais presentes nos dados. Ao usar particionamento hierárquico, o CURE supera as limitações dos algoritmos tradicionais de clustering que exigem que os clusters tenham formas convexas.
Seleção de Pontos Representativos
O CURE seleciona múltiplos pontos representativos para representar cada cluster em vez de depender de um único centroide. Esses pontos, cuidadosamente escolhidos a partir do cluster, capturam sua extensão espacial e estrutura. O CURE alcança melhor reconhecimento dos limites dos clusters e compreensão da estrutura interna ao usar múltiplos pontos para representar cada cluster.
Após selecionar os pontos representativos, o algoritmo os move em direção à média do cluster com uma quantidade especificada de contração. O procedimento de contração torna o algoritmo menos reativo a outliers ao mover pontos distantes em direção aos pontos centrais do cluster.
O sucesso do algoritmo depende fortemente de quantos pontos representativos são usados durante a execução. A seleção apropriada de pontos representativos é crucial. Usar poucos pontos representativos pode não capturar a complexidade do cluster, enquanto usar muitos pode aumentar os custos computacionais.
Mesclagem de Clusters
Após identificar os pontos representativos, o algoritmo mescla clusters usando uma abordagem iterativa sistemática. O procedimento depende da medição da distância entre pontos representativos de diferentes clusters. Métricas predefinidas, como a distância euclidiana, são usadas para medir distâncias, eliminando assim conflitos na identificação dos clusters mais próximos.
O algoritmo identifica quais pares de clusters têm a menor distância a partir da separação dos pontos representativos durante cada etapa de avaliação. O algoritmo toma decisões precisas de mesclagem de clusters enquanto preserva as relações espaciais e os padrões naturais de alinhamento dos dados dentro dos clusters.
O processo itera até que alguns clusters predeterminados sejam alcançados ou outro critério de término seja atingido. O critério de término depende de fatores como a distância mínima entre clusters ou a similaridade máxima permitida dentro dos clusters. Isso garante que os clusters produzidos correspondam aos agrupamentos naturais nos dados e sejam flexíveis o suficiente para capturar formas irregulares e complexas.
Tratamento de Outliers
Quando existem outliers, os resultados se tornam distorcidos porque eles causam formas incorretas de clusters e interpretam erroneamente a estrutura dos dados. O algoritmo CURE resolve essas limitações usando múltiplos pontos representativos, que identificam com precisão a forma e a distribuição reais dos clusters.
O mecanismo de contração representa outro avanço fundamental no CURE, tornando o sistema mais resiliente e aumentando sua sofisticação. Esse ajuste deliberado diminui a sensibilidade do algoritmo a valores extremos, movendo os pontos representativos em direção às posições centrais do cluster.
O fator de contração é um parâmetro de ajuste que permite aos usuários personalizar seu valor de acordo com as características do conjunto de dados. Isso possibilita a mitigação flexível de outliers enquanto preserva os limites naturais dos clusters.
Comparação com Outros Métodos de Clustering
A abordagem inovadora do algoritmo CURE o distingue de outras técnicas populares de clustering. Aqui está uma comparação mais aprofundada:
| Aspecto | CURE | k-means | DBSCAN |
| Representação | Múltiplos pontos representativos | Centroide único | Baseado em densidade |
| Tratamento de Outliers | Excelente | Ruim | Bom |
| Flexibilidade de Forma | Formas arbitrárias | Apenas formas convexas | Formas arbitrárias |
| Escalabilidade | Alta (com amostragem) | Alta | Moderada |
| Complexidade | Maior | Menor | Moderada |
Benefícios e Desafios
Quando aplicado a cenários do mundo real, o CURE oferece uma combinação de vantagens e desafios. Vamos discutir como o CURE pode oferecer valor ao mesmo tempo em que apresenta certos obstáculos em aplicações práticas.
Benefícios
Escalabilidade: O CURE alcança escalabilidade por meio de sua estratégia de amostragem de dados, que reduz as cargas de trabalho computacionais sem comprometer a precisão dos clusters.
Robustez: O CURE aumenta a robustez ao usar múltiplos pontos representativos para capturar a forma e a estrutura de um cluster. Assim, o clustering produzirá resultados confiáveis e estáveis mesmo quando os dados forem ruidosos e inconsistentes.
Versatilidade: O CURE captura clusters de qualquer forma e lida com irregularidades ou estruturas não convexas. Isso é particularmente útil em conjuntos de dados diversos, nos quais técnicas tradicionais como k-means não conseguem representá-los com precisão.
Desafios
Sensibilidade a Parâmetros: O algoritmo exige ajuste preciso de parâmetros para o fator de encolhimento e o número de pontos representativos. Encontrar o equilíbrio certo é crucial para um desempenho ideal, exigindo tanto experimentação quanto conhecimento do domínio.
Viés de Amostragem: Técnicas de amostragem insuficientes produzem formação de clusters imprecisa e resultados ruins. Manter amostras representativas imparciais é essencial para garantir que as estruturas do conjunto de dados permaneçam intactas.
Demandas Computacionais: Os desafios de escalabilidade do CURE aumentam com conjuntos de dados grandes, de alta dimensionalidade ou não estruturados devido à necessidade de múltiplas avaliações de distância. Técnicas como PCA e computação paralela podem reduzir a dimensionalidade, diminuindo os custos computacionais enquanto preservam relações-chave.
Casos de Uso
Para ver o impacto prático do algoritmo CURE, vamos analisar como ele pode resolver desafios de clustering do mundo real em vários domínios.
Detecção de anomalias
O CURE identifica efetivamente anomalias ao agrupar transações típicas e isolar as irregulares que podem indicar fraude. Isso permite que instituições financeiras detectem atividades suspeitas rapidamente e aprimorem suas medidas de segurança.
Segmentação de mercado
Em marketing, o CURE pode segmentar clientes com base em atributos como comportamento de compra, dados demográficos e preferências. Isso permite campanhas de marketing direcionadas, melhorando a retenção de clientes e prevendo tendências futuras. Por exemplo, clientes de alto valor podem ser agrupados para ofertas exclusivas a fim de aumentar a fidelidade.
Análise de dados geoespaciais
Planejadores urbanos podem implementar o CURE para categorizar regiões com climas, densidades populacionais ou desenvolvimentos de infraestrutura semelhantes. Cientistas ambientais podem usá-lo para agrupar áreas de acordo com sua biodiversidade e disponibilidade de recursos enquanto estudam ecossistemas.
Clustering de documentos
O CURE demonstra excelente eficácia na mineração de texto ao agrupar extensos catálogos de documentos com base em seus temas e tópicos padrão. Mecanismos de busca usam esse método para criar categorias de resultados precisas que permitem aos usuários encontrar conteúdo relevante rapidamente.
O CURE permite que sistemas de recomendação identifiquem artigos e trabalhos de pesquisa com assuntos semelhantes. Isso resulta em recomendações personalizadas e significativas para os usuários. O CURE consegue agrupar efetivamente diversas estruturas de texto para manter resultados de agrupamento precisos, independentemente da complexidade e do tamanho de conjuntos de dados de alta dimensionalidade. O algoritmo se adapta bem a conjuntos de dados de texto multilíngues e entradas de dados heterogêneas, posicionando-o como uma solução essencial para plataformas contemporâneas de recuperação de informações.
Conclusão
O algoritmo de agrupamento CURE representa um grande avanço nos métodos de agrupamento. Ele oferece uma solução eficaz e escalável para problemas de dados contemporâneos. O algoritmo usa pontos representativos junto com princípios hierárquicos para superar limitações tradicionais de agrupamento, ao mesmo tempo em que garante resultados flexíveis e precisos. Embora o algoritmo enfrente desafios com a otimização de parâmetros e requisitos computacionais, sua capacidade de gerenciar dados ruidosos e padrões complexos é essencial para vários setores de negócios.
A crescente complexidade dos conjuntos de dados continuará a impulsionar a necessidade de algoritmos de agrupamento flexíveis como o CURE no futuro. Cientistas de dados e profissionais de machine learning que compreendem os princípios do CURE poderão maximizar seu potencial para gerar insights significativos a partir de conjuntos de dados complexos.
Perguntas frequentes
- O que torna o CURE único em comparação com o k-means?
O CURE se distingue do k-means ao utilizar múltiplos pontos representativos em vez de um único centroide de cluster. O método permite a detecção de formatos de cluster irregulares e padrões não lineares em conjuntos de dados complexos sem exigir pressupostos de clusters convexos.
- Como o CURE lida com grandes conjuntos de dados?
O CURE gerencia grandes conjuntos de dados por meio de técnicas de amostragem aleatória que minimizam os requisitos de processamento computacional. A estratégia de amostragem permite que o algoritmo processe subconjuntos de dados reduzidos, preservando a integridade das relações entre clusters.
- Qual é o papel do fator de encolhimento no CURE?
O fator de encolhimento do CURE controla a distância na qual os pontos representativos se movem em direção à posição média de seu cluster. Esse fator permite que os usuários alcancem resultados ideais entre precisão e robustez. O sucesso das implementações do CURE depende fortemente da descoberta do fator de encolhimento correto para cada conjunto de dados.
- O CURE pode funcionar com dados de alta dimensionalidade?
Usar algoritmos CURE em dados de alta dimensionalidade requer pré-processamento prévio por meio de técnicas como PCA. O processamento de dados de alta dimensionalidade exige redução eficiente de dimensões para encontrar padrões essenciais, mesmo ao manter a simplicidade dos dados.
- Quais são as aplicações típicas do CURE?
As aplicações típicas do CURE incluem detecção de anomalias, segmentação de mercado, análise geoespacial e análise de agrupamento de documentos. Ele pode identificar padrões financeiros incomuns para detecção de fraude, agrupar clientes por comportamento e analisar regiões com base em características.
Recursos relacionados
https://zilliz.com/ai-faq/how-are-embeddings-used-for-clustering
https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search
https://zilliz.com/ai-faq/how-does-swarm-intelligence-improve-data-clustering
https://zilliz.com/ai-faq/what-is-graph-clustering-in-knowledge-graphs
https://zilliz.com/ai-faq/what-are-the-most-common-algorithms-for-anomaly-detection
- Entendendo o Algoritmo CURE: Uma Exploração Abrangente de Clustering com Representantes
- O Que É o Algoritmo CURE?
- Como Funciona
- Fluxo do Processo do Algoritmo de Clustering CURE
- Comparação com Outros Métodos de Clustering
- Benefícios e Desafios
- Casos de Uso
- Conclusão
- Perguntas frequentes
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis