




VIPSHOP constrói um sistema de recomendação personalizado 10x mais rápido usando Milvus

Velocidade de consulta 10x mais rápida
do que a solução anterior do Elasticsearch
Tempo de resposta <30ms
para pesquisar em milhões de vetores
Experiência do Usuário Otimizada
com recomendações mais precisas com base nos comportamentos de compra dos usuários
Milvus-powered vector search has been running steadily in our recommendation systems, providing high performance and allowing us more flexibility in selecting models and algorithms.
VIPSHOP Search Service Team
Sobre a VIPSHOP
A VIPSHOP é uma renomada varejista online listada na NYSE, com sede na China, especializada em fornecer produtos de marcas populares aos consumidores com descontos significativos. Sua diversificada gama de produtos inclui moda, vestuário, acessórios, produtos de beleza, artigos para o lar e eletrônicos. Com uma impressionante base de clientes de mais de 52 milhões e facilitando quase 270 milhões de pedidos anualmente, a VIPSHOP conquistou seu lugar como a 115ª entrada na prestigiosa lista China 500 da Fortune.
Desafios: Alta latência e custos de manutenção crescentes usando Elasticsearch
Com o rápido crescimento de seus negócios, a VIPSHOP enfrentou um dilema comum: à medida que seu portfólio de produtos se expandia, também aumentava a complexidade de ajudar os usuários a descobrir o que estavam procurando. Para resolver esse problema, a VIPSHOP criou um sistema de recomendação personalizado baseado em palavras-chave de consulta dos usuários e nos comportamentos de compra dos usuários.
Anteriormente, a equipe da VIPSHOP utilizava os recursos de Similaridade de Cosseno(7.x) do Elasticsearch para impulsionar o sistema de recomendação. No entanto, essa abordagem era ineficiente por dois motivos:
Alta latência na busca vetorial: Média de cerca de 300 ms para recuperar resultados Top-K de milhões de vetores, resultando em segundos para o tempo de resposta geral do sistema.
Altos custos de manutenção dos índices do Elasticsearch: Vetores derivados de produtos, comportamentos de compra dos consumidores e todos os outros dados compartilhavam o mesmo conjunto de índices, tornando a construção, operação e manutenção dos índices muito mais complicadas.
A VIPSHOP tentou melhorar o desempenho do Elasticsearch desenvolvendo um plugin de hash sensível à localidade. No entanto, ele apenas melhorou a taxa de transferência e não conseguiu reduzir o tempo de busca vetorial para menos de 100 ms. Portanto, a equipe ainda precisava urgentemente de uma nova pilha de busca vetorial para melhorar o desempenho do sistema.
A solução Milvus
Após extensa pesquisa, a equipe da VIPSHOP optou pelo Milvus, um banco de dados vetorial de código aberto capaz de lidar com bilhões de embeddings vetoriais e entregar respostas extremamente rápidas. O Milvus também oferece recursos avançados, como implantação distribuída, SDKs multilíngues e separação de leitura/gravação, tornando-o uma escolha superior ao Elasticsearch e a muitas outras soluções de busca vetorial, como FAISS.
A arquitetura do sistema de recomendação da VIPSHOP usando Milvus
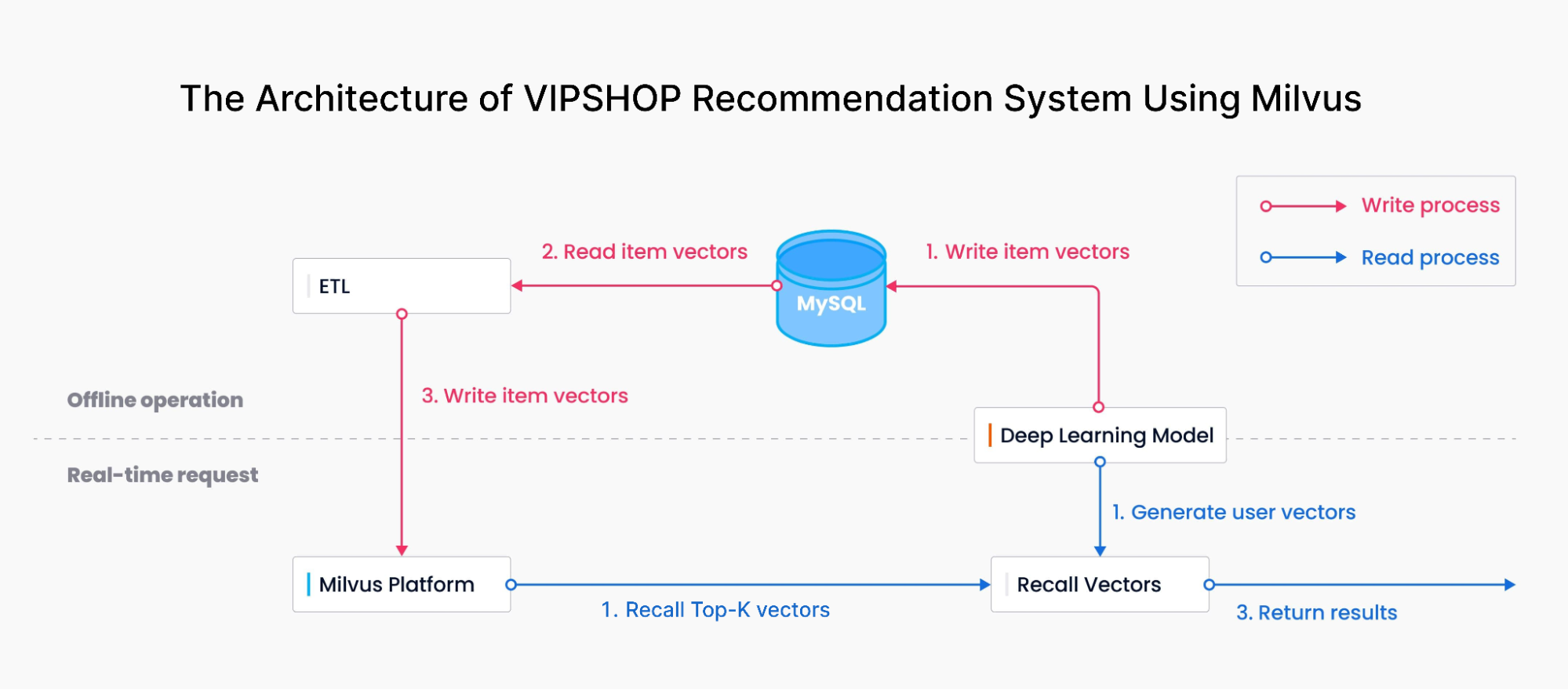
O diagrama acima demonstra a arquitetura do sistema de recomendação da VIPSHOP com Milvus. Ele consiste em duas partes principais:
Processo de gravação: a equipe da VIPSHOP usou um modelo de deep learning para transformar as características de cada produto em embeddings vetoriais e, em seguida, importou-os para o Milvus por meio do MySQL e de uma ferramenta ETL.
Processo de leitura: a equipe usou o modelo de deep learning para transformar as consultas e os comportamentos de compra dos consumidores em vetores e, em seguida, recuperou resultados semelhantes no Milvus. O Milvus realizou uma busca por similaridade e retornou os resultados Top-K mais relevantes aos consumidores.
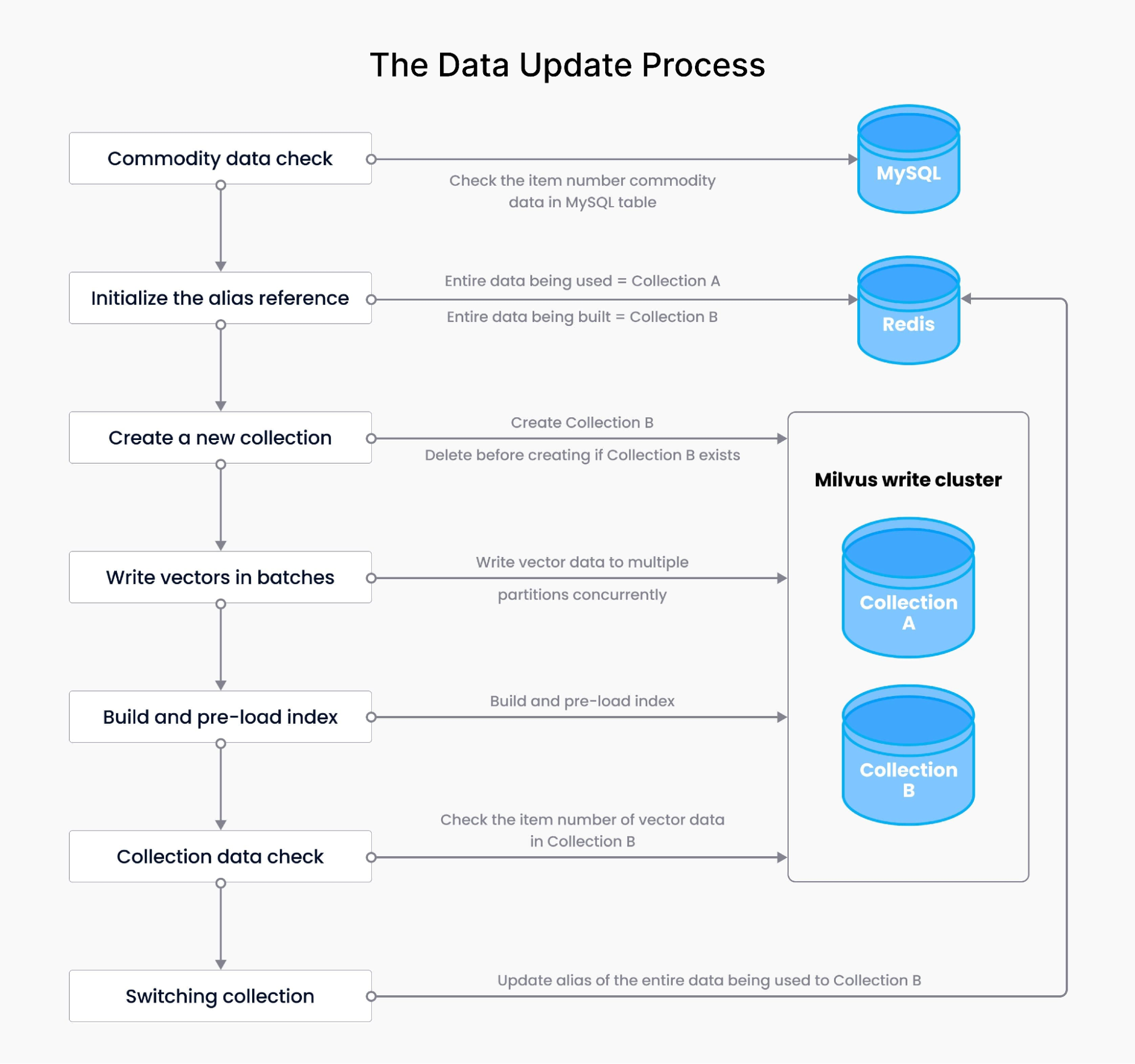
Detalhes da implementação do Milvus: atualização e recuperação de dados
A atualização e a recuperação de dados são os processos mais essenciais para o sistema de recomendação impulsionado pelo Milvus.
O procedimento de atualização de dados garante a sincronização dos dados, abrangendo tarefas como gravação de dados vetoriais, detecção de volumes de dados vetoriais, construção de índices, pré-carregamento de índices e gerenciamento de aliases. Ele começa com verificações de dados de mercadorias, garantindo que a quantidade no MySQL esteja alinhada com os dados existentes. Todo o processo de construção de dados segue, incluindo a inicialização de aliases no Redis, a criação de novas coleções, a gravação de vetores em lotes e o pré-carregamento do índice no Milvus. Após verificar os dados da nova coleção, o sistema alterna perfeitamente os aliases entre várias coleções de dados.
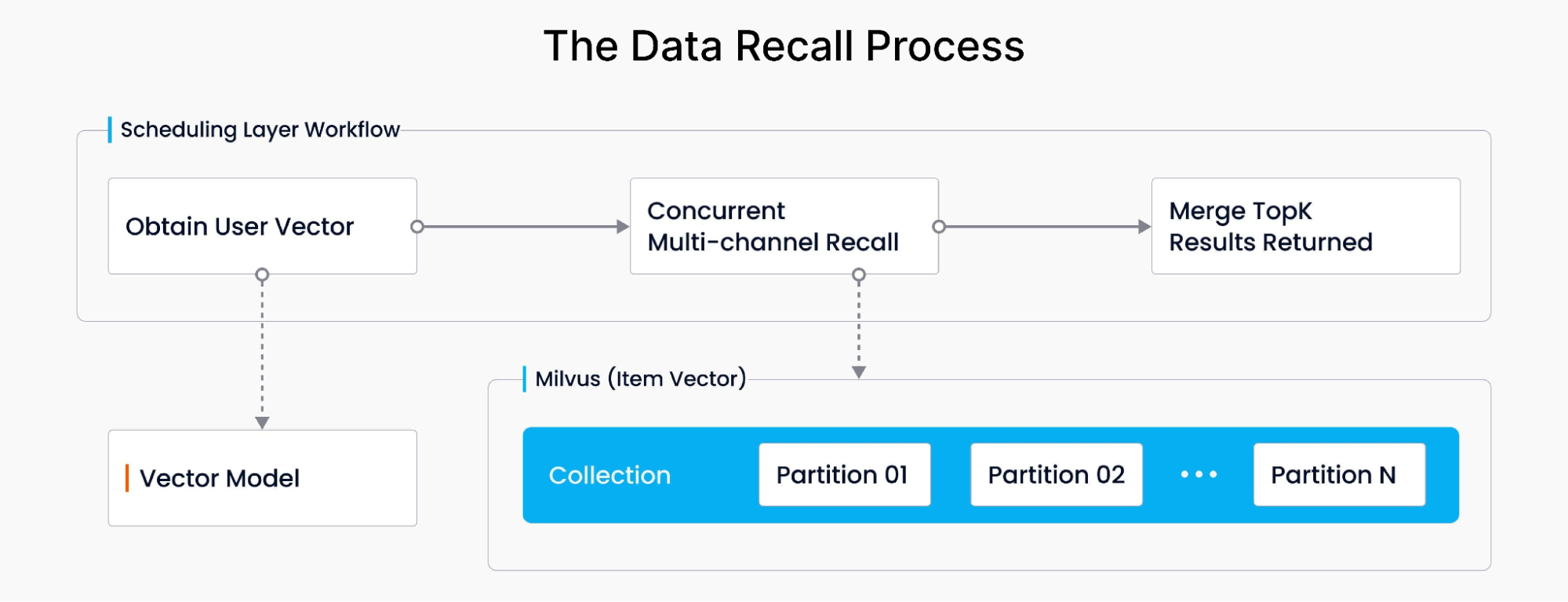
O processo de recall, crucial para recomendar produtos, envolve adquirir vetores relacionados às consultas e aos comportamentos de compra dos consumidores, calcular sua distância e mesclar os resultados. Utilizando o Milvus, o sistema recupera dados de forma concorrente e assíncrona em diferentes partições do Milvus, calcula similaridades vetoriais e classifica os principais resultados com base na distância de similaridade. Então, após múltiplas chamadas aos dados das partições do Milvus, ele apresenta os resultados finais de recomendação aos usuários. O fluxo de trabalho geral é o seguinte:
A tabela a seguir mostra o desempenho de três serviços principais do Milvus. Como mostrado na tabela, a latência média para recuperar resultados Top-K é de cerca de 10 ms.
| Serviço | Função | Parâmetros de entrada | Parâmetros de saída | Latência de resposta |
|---|---|---|---|---|
| Aquisição de vetores de usuário | Obter vetor do usuário | informações do usuário + consulta | vetor do usuário | 10 ms |
| Milvus Search | Calcular a similaridade vetorial e retornar resultados Top-K | vetor do usuário | vetor do item | 10 ms |
| Lógica de agendamento | Recall e mesclagem de resultados concorrentes | Vetores de itens recuperados de múltiplos canais e a pontuação de similaridade | itens Top-K | 10 ms |
Resultados: Melhor desempenho do sistema e experiência ideal do usuário
A adoção do Milvus no sistema de recomendação da VIPSHOP melhorou significativamente o desempenho geral do sistema, incluindo:
Velocidade de consulta 10x mais rápida
Usando o Milvus, o tempo de consulta e resposta do sistema foi reduzido para menos de 30 ms, 10x mais rápido do que a solução anterior com Elasticsearch.
Escalabilidade do sistema aprimorada
A implantação distribuída do Milvus e o suporte à escalabilidade horizontal permitem que o sistema de recomendação lide facilmente com volumes de dados e consultas de usuários em rápido crescimento sem comprometer o desempenho.
Experiência do usuário aprimorada
O Milvus otimiza o processo de recomendação para fornecer sugestões de produtos personalizadas com base nas preferências e na intenção de busca dos usuários, melhorando a satisfação e o engajamento dos usuários.
Custos de manutenção reduzidos
O Milvus lida de forma eficiente com dados vetoriais e simplifica os mecanismos de consulta, reduzindo os custos gerais de manutenção do sistema de recomendação.
Lições aprendidas e práticas recomendadas
Em sua jornada com o Milvus, a equipe da VIPSHOP aprendeu algumas lições e obteve vários insights cruciais para o desempenho ideal do sistema e a experiência do usuário:
Em situações em que as operações de leitura têm precedência, adotar uma estratégia de implantação com separação entre leitura e escrita pode melhorar o desempenho geral do sistema.
O cliente Java do Milvus não possui um mecanismo de reconexão integrado devido à sua residência em memória no serviço de recall. A equipe da VIPSHOP criou seu próprio pool de conexões para garantir conectividade consistente entre o cliente Java e o servidor por meio de um teste de heartbeat.
Consultas lentas ocorrem ocasionalmente no Milvus devido ao aquecimento insuficiente de novas coleções. Para resolver esse problema, a equipe da VIPSHOP simulou consultas na nova coleção.
Para alcançar o equilíbrio certo entre desempenho de recuperação e precisão, a equipe da VIPSHOP recomenda conduzir experimentos rigorosos de teste de pressão adaptados ao seu cenário de negócios específico e definir um valor de limiar razoável para otimizar esses parâmetros.
Em cenários envolvendo dados estáticos, é mais eficiente importar todos os dados para a coleção primeiro e construir índices posteriormente.