




Como a Airtable construiu e escalou a infraestrutura vetorial com o Milvus

Consultas de baixa latência
desempenho previsível é fundamental para a confiança do usuário
Gravações de alta taxa de transferência
bases mudam constantemente, e os embeddings devem permanecer sincronizados
Escalabilidade horizontal
o sistema deve suportar milhões de bases independentes
Este post foi originalmente publicado no canal the Airtable Medium e é republicado aqui com permissão.
À medida que a busca semântica na Airtable evoluiu de um conceito para um recurso central do produto, a equipe de Infraestrutura de Dados enfrentou o desafio de escalá-la. Conforme detalhado em nosso post anterior sobre a Construção do Sistema de Embeddings, já havíamos projetado uma camada de aplicação robusta, eventualmente consistente, para lidar com o ciclo de vida dos embeddings. Mas uma peça crítica ainda faltava em nosso diagrama de arquitetura: o próprio banco de dados vetorial.
Precisávamos de um mecanismo de armazenamento capaz de indexar e servir bilhões de embeddings, oferecer suporte a uma enorme multilocação e manter metas de desempenho e disponibilidade em um ambiente de nuvem distribuído. Esta é a história de como arquitetamos, fortalecemos e evoluímos nossa plataforma de busca vetorial para se tornar um pilar central da stack de infraestrutura da Airtable.
Contexto
Na Airtable, nosso objetivo é ajudar os clientes a trabalhar com seus dados de maneiras poderosas e intuitivas. Com o surgimento de LLMs cada vez mais poderosos e precisos, recursos que aproveitam o significado semântico dos seus dados tornaram-se centrais para o nosso produto.
Como Usamos a Busca Semântica
Omni (o Chat de IA da Airtable) respondendo a perguntas reais de grandes conjuntos de dados
Imagine fazer uma pergunta em linguagem natural sobre sua base (banco de dados) com meio milhão de linhas e obter uma resposta correta, rica em contexto. Por exemplo:
“O que os clientes têm dito sobre a duração da bateria ultimamente?”
Em conjuntos de dados pequenos, é possível enviar todas as linhas diretamente para um LLM. Em escala, isso rapidamente se torna inviável. Em vez disso, precisávamos de um sistema capaz de:
- Compreender a intenção semântica de uma consulta
- Recuperar as linhas mais relevantes por meio de busca por similaridade vetorial
- Fornecer essas linhas como contexto para um LLM
Esse requisito moldou praticamente todas as decisões de design que se seguiram: o Omni precisava parecer instantâneo e inteligente, mesmo em bases muito grandes.
Recomendações de registros vinculados: significado em vez de correspondências exatas
A busca semântica também aprimora um recurso central da Airtable: registros vinculados. Os usuários precisam de sugestões de relacionamento baseadas em contexto, em vez de correspondências exatas de texto. Por exemplo, uma descrição de projeto pode implicar uma relação com “Team Infrastructure” sem nunca usar essa frase específica.
Entregar essas sugestões sob demanda exige recuperação semântica de alta qualidade com latência consistente e previsível.
Nossas Prioridades de Design
Para oferecer suporte a esses recursos e outros, ancoramos o sistema em 4 objetivos:
- Consultas de baixa latência (500ms p99): desempenho previsível é fundamental para a confiança do usuário
- Escritas de alta vazão: as bases mudam constantemente, e os embeddings devem permanecer sincronizados
- Escalabilidade horizontal: o sistema deve oferecer suporte a milhões de bases independentes
- Auto-hospedagem: todos os dados dos clientes devem permanecer dentro da infraestrutura controlada pela Airtable
Esses objetivos moldaram todas as decisões arquiteturais que se seguiram.
Avaliação de Fornecedores de Banco de Dados Vetorial
No fim de 2024, avaliamos várias opções de banco de dados vetorial e, no fim, selecionamos Milvus com base em três requisitos principais.
- Primeiro, priorizamos uma solução auto-hospedada para garantir a privacidade dos dados e manter controle refinado sobre nossa infraestrutura.
- Segundo, nossa carga de trabalho intensiva em escritas e padrões de consulta em rajadas exigiam um sistema que pudesse escalar elasticamente mantendo latência baixa e previsível.
- Por fim, nossa arquitetura exigia forte isolamento entre milhões de locatários de clientes.
Milvus surgiu como a melhor opção: sua natureza distribuída oferece suporte à multilocação em massa e nos permite escalar ingestão, indexação e execução de consultas de forma independente, entregando desempenho enquanto mantém os custos previsíveis.
Design da Arquitetura
Depois de escolher uma tecnologia, tivemos então que determinar uma arquitetura para representar o formato de dados único do Airtable: milhões de “bases” distintas pertencentes a diferentes clientes.
O Desafio de Particionamento
Avaliamos duas estratégias principais de particionamento de dados:
Opção 1: Partições Compartilhadas
Várias bases compartilham uma partição, e as consultas são delimitadas por meio de filtragem em um id de base. Isso melhora a utilização de recursos, mas introduz uma sobrecarga adicional de filtragem e torna a exclusão de bases mais complexa.
Opção 2: Uma Base por Partição
Cada base do Airtable é mapeada para sua própria partição física no Milvus. Isso proporciona forte isolamento, permite uma exclusão de base rápida e simples, e evita o impacto de desempenho da filtragem pós-consulta.
Estratégia Final
Escolhemos a opção 2 por sua simplicidade e forte isolamento. No entanto, testes iniciais mostraram que criar 100k partições em uma única coleção do Milvus causava degradação significativa de desempenho:
- A latência de criação de partições aumentou de ~20 ms para ~250 ms
- Os tempos de carregamento de partições excederam 30 segundos
Para resolver isso, limitamos o número de partições por coleção. Para cada cluster Milvus, criamos 400 coleções, cada uma com no máximo 1.000 partições. Isso limita o número total de bases por cluster a 400k, e novos clusters são provisionados à medida que clientes adicionais são integrados.
Indexação & Recall
A escolha do índice acabou sendo uma das decisões de trade-off mais importantes em nosso sistema. Quando uma partição é carregada, seu índice é armazenado em cache na memória ou em disco. Para encontrar um equilíbrio entre taxa de recall, tamanho do índice e desempenho, testamos vários tipos de índice.
- IVF-SQ8: Ofereceu uma pequena pegada de memória, mas recall menor.
- HNSW: Entrega o melhor recall (99%-100%), mas consome muita memória.
- DiskANN: Oferece um recall semelhante ao HNSW, mas com maior latência de consulta
No fim, selecionamos HNSW por seu recall superior e suas características de desempenho.
A camada de Aplicação
Em alto nível, o pipeline de busca semântica do Airtable envolve dois fluxos principais:
- Fluxo de ingestão: Converter linhas do Airtable em embeddings e armazená-las no Milvus
- Fluxo de consulta: Incorporar consultas de usuários, recuperar IDs de linhas relevantes e fornecer contexto ao LLM
Ambos os fluxos devem operar continuamente e de forma confiável em escala, e abordamos cada um abaixo. Abordamos cada um abaixo.
Fluxo de Ingestão: Mantendo o Milvus em Sincronia com o Airtable
Quando um usuário abre o Omni, o Airtable começa a sincronizar sua base com o Milvus. Criamos uma partição e, em seguida, processamos as linhas em blocos, gerando embeddings e fazendo upsert no Milvus. A partir daí, capturamos quaisquer alterações feitas na base, e re-embedamos e fazemos upsert dessas linhas para manter os dados consistentes.
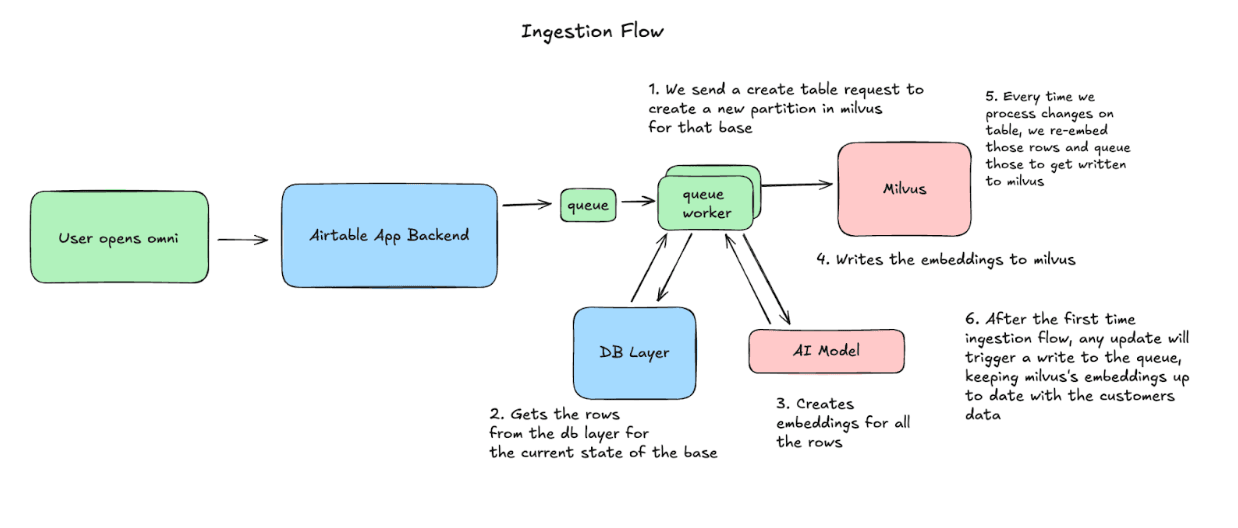
Fluxo de Consulta: Como usamos os Dados
No lado da consulta, incorporamos a solicitação do usuário e a enviamos ao Milvus para recuperar os IDs de linhas mais relevantes. Em seguida, buscamos as versões mais recentes dessas linhas e as incluímos como contexto na solicitação ao LLM.
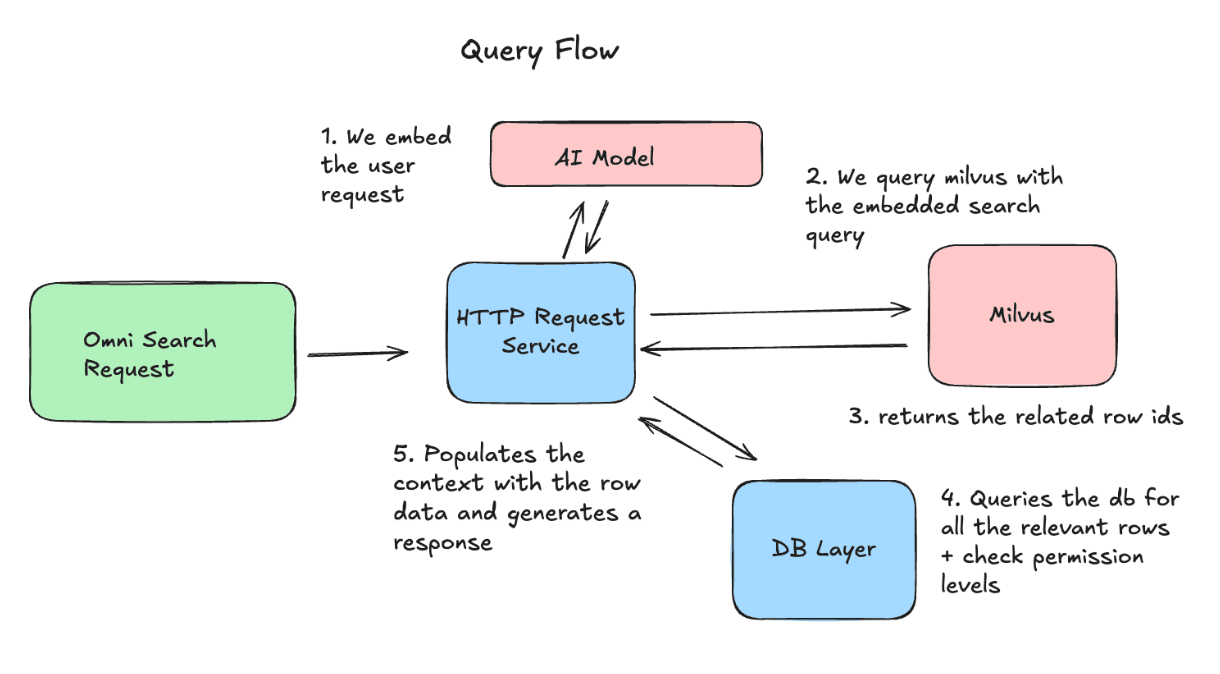
Desafios Operacionais & Como os Resolvemos
Construir uma arquitetura de busca semântica é um desafio; executá-la de forma confiável para centenas de milhares de bases é outro. Abaixo estão algumas lições operacionais importantes que aprendemos ao longo do caminho.
Implantação
Implantamos o Milvus por meio de seu CRD do Kubernetes com o Milvus operator, permitindo-nos definir e gerenciar clusters de forma declarativa. Toda mudança, seja uma atualização de configuração, melhoria de cliente ou upgrade do Milvus, passa por testes unitários e um teste de carga sob demanda que simula o tráfego de produção antes de ser disponibilizada aos usuários.
Na versão 2.5, o cluster Milvus é composto por estes componentes principais:
- Nós de Consulta mantêm os índices vetoriais em memória e executam buscas vetoriais
- Nós de Dados lidam com ingestão e compactação, e persistem novos dados no armazenamento
- Nós de Índice constroem e mantêm índices vetoriais para manter a busca rápida à medida que os dados crescem
- O Nó Coordenador orquestra toda a atividade do cluster e a atribuição de shards
- Nós Proxy roteiam o tráfego da API e equilibram a carga entre os nós
- Kafka fornece a espinha dorsal de log/streaming para mensagens internas e fluxo de dados
- Etcd armazena metadados do cluster e estado de coordenação
Com automação orientada por CRD e um pipeline de testes rigoroso, podemos lançar atualizações de forma rápida e segura.
Observabilidade: Entendendo a Saúde do Sistema de Ponta a Ponta
Monitoramos o sistema em dois níveis para garantir que a busca semântica permaneça rápida e previsível.
No nível de infraestrutura, acompanhamos CPU, uso de memória e a saúde dos pods em todos os componentes do Milvus. Esses sinais nos dizem se o cluster está operando dentro de limites seguros e nos ajudam a detectar problemas como saturação de recursos ou nós não saudáveis antes que afetem os usuários.
Na camada de serviço, focamos em quão bem cada base está acompanhando nossas cargas de trabalho de ingestão e consulta. Métricas como throughput de compactação e indexação nos dão visibilidade sobre a eficiência com que os dados estão sendo ingeridos. Taxas de sucesso de consulta e latência nos dão uma compreensão da experiência do usuário ao consultar os dados, e o crescimento de partições nos permite saber como nossos dados estão crescendo, para que sejamos alertados se precisarmos escalar.
Rotação de Nós
Por razões de segurança e conformidade, rotacionamos regularmente os nós do Kubernetes. Em um cluster de busca vetorial, isso não é trivial:
- À medida que os nós de consulta são rotacionados, o coordenador reequilibrará os dados em memória entre os nós de consulta
- Kafka e Etcd armazenam informações com estado e exigem quórum e disponibilidade contínua
Abordamos isso com orçamentos de interrupção rigorosos e uma política de rotação de um nó por vez. O coordenador do Milvus recebe tempo para reequilibrar antes que o próximo nó seja alternado. Essa orquestração cuidadosa preserva a confiabilidade sem reduzir nossa velocidade.
Descarregamento de Partições Frias
Uma das nossas maiores vitórias operacionais foi reconhecer que nossos dados têm padrões claros de acesso quente/frio. Ao analisar o uso, descobrimos que apenas ~25% dos dados no Milvus são gravados ou lidos em uma determinada semana. O Milvus nos permite descarregar partições inteiras, liberando memória nos Nós de Consulta. Se esses dados forem necessários posteriormente, podemos recarregá-los em segundos. Isso nos permite manter os dados quentes em memória e descarregar o restante, reduzindo custos e permitindo escalar de forma mais eficiente ao longo do tempo.
Recuperação de Dados
Antes de lançar o Milvus amplamente, precisávamos ter confiança de que poderíamos nos recuperar rapidamente de qualquer cenário de falha. Embora a maioria dos problemas seja coberta pela tolerância a falhas integrada do cluster, também planejamos casos raros em que os dados poderiam ser corrompidos ou o sistema poderia entrar em um estado irrecuperável.
Nessas situações, nosso caminho de recuperação é direto. Primeiro, colocamos em funcionamento um novo cluster Milvus para que possamos retomar o atendimento ao tráfego quase imediatamente. Assim que o novo cluster estiver ativo, reembutimos proativamente as bases mais comumente usadas e, em seguida, processamos o restante de forma preguiçosa à medida que são acessadas. Isso minimiza o tempo de inatividade para os dados mais acessados enquanto o sistema reconstrói gradualmente um índice semântico consistente.
O Que Vem a Seguir
Nosso trabalho com Milvus estabeleceu uma base sólida para a busca semântica na Airtable: impulsionando experiências de IA rápidas e significativas em escala. Com esse sistema em funcionamento, agora estamos explorando pipelines de recuperação mais ricos e integrações de IA mais profundas em todo o produto. Há muito trabalho empolgante pela frente, e estamos apenas começando.
Agradecemos a todos os Airtablets passados e presentes na Infraestrutura de Dados e em toda a organização que contribuíram para este projeto: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Sobre a Airtable
Airtable é uma plataforma líder de operações digitais que permite às organizações criar aplicativos personalizados, automatizar fluxos de trabalho e gerenciar dados compartilhados em escala empresarial. Projetado para oferecer suporte a processos complexos e multifuncionais, o Airtable ajuda as equipes a criar sistemas flexíveis para planejamento, coordenação e execução com base em uma fonte única de verdade compartilhada. À medida que o Airtable expande sua plataforma impulsionada por IA, tecnologias como Milvus desempenham um papel importante no fortalecimento da infraestrutura de recuperação necessária para oferecer experiências de produto mais rápidas e inteligentes.
- Contexto
- Como Usamos a Busca Semântica
- Nossas Prioridades de Design
- Avaliação de Fornecedores de Banco de Dados Vetorial
- Design da Arquitetura
- O Desafio de Particionamento
- Indexação & Recall
- A camada de Aplicação
- Fluxo de Ingestão: Mantendo o Milvus em Sincronia com o Airtable
- Fluxo de Consulta: Como usamos os Dados
- Desafios Operacionais & Como os Resolvemos
- Observabilidade: Entendendo a Saúde do Sistema de Ponta a Ponta
- Rotação de Nós
- Descarregamento de Partições Frias
- Recuperação de Dados
- O Que Vem a Seguir
- Sobre a Airtable
Conteúdo
Caso de uso
Indústria
SaaS de IA