




Métricas de semelhança para pesquisa vetorial
Métricas de semelhança vetorial para pesquisa - Zilliz Blog
Não se pode comparar maçãs e laranjas. Ou pode? Bases de dados vectoriais como o Milvus permitem-lhe comparar qualquer dados que possa vetorizar. Pode até fazê-lo diretamente no seu Jupyter Notebook. Mas como funciona a pesquisa de similaridade vetorial?
A pesquisa vetorial tem dois componentes conceituais críticos: índices e métricas de distância. Alguns índices vetoriais populares incluem HNSW, IVF e ScaNN. Existem três métricas de distância principais: L2 ou distância euclidiana, similaridade de cosseno e produto interno. A distância de Manhattan calcula a distância entre pontos através da soma das diferenças absolutas em cada dimensão e é vantajosa em cenários em que a sensibilidade a valores atípicos tem de ser minimizada. Outras métricas para vectores binários incluem a distância de Hamming e o índice de Jaccard.
Neste artigo, abordaremos:
Métricas de similaridade de vetor
L2 ou Euclidiano
Como é que a distância L2 funciona?
Quando se deve usar a distância euclidiana?
Similaridade de cosseno
Como funciona a similaridade de cosseno?
Quando se deve usar a similaridade de cosseno?
Produto interno
Como funciona o Inner Product?
Quando é que deve utilizar o Inner Product?
Outras métricas interessantes de similaridade de vetor ou distância
Distância de Hamming
Índice de Jaccard
Resumo das métricas de pesquisa de similaridade de vectores
Os vectores podem ser representados como listas de números ou como uma orientação e uma magnitude. Para uma compreensão mais fácil, pode imaginar os vectores como segmentos de linha que apontam em direcções específicas no espaço.
A métrica L2 ou Euclidiana** é a métrica da "hipotenusa" de dois vectores. Mede a magnitude da distância entre as extremidades das linhas dos seus vectores.
A semelhança de cosseno** é o ângulo entre as linhas que se encontram.
O produto interno** é a "projeção" de um vetor sobre o outro. Intuitivamente, mede tanto a distância como o ângulo entre os vectores.
A métrica de distância mais intuitiva é L2 ou distância euclidiana. Podemos imaginá-la como a quantidade de espaço entre dois objectos. Por exemplo, a distância entre o seu ecrã e o seu rosto.
Já imaginámos como funciona a distância L2 no espaço; como é que funciona em matemática? Vamos começar por imaginar ambos os vectores como uma lista de números. Alinhe as listas uma em cima da outra e subtraia para baixo. Depois, elevar todos os resultados ao quadrado e somá-los. Por fim, tirar uma raiz quadrada.
A Milvus salta a raiz quadrada porque a ordem de classificação com raiz quadrada e sem raiz quadrada é a mesma. Desta forma, podemos saltar uma operação e obter o mesmo resultado, reduzindo a latência e o custo e aumentando o débito. Abaixo está um exemplo de como funciona a distância Euclidiana ou L2.
d(Rainha, Rei) = √(0.3-0.5)2 + (0.9-0.7)2
= √(0.2)2 + (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28
Uma das principais razões para usar a distância euclidiana é quando os seus vectores](https://zilliz.com/glossary/vetor-distance) têm magnitudes diferentes. O que mais importa é a distância espacial das palavras ou a distância semântica.
Utilizamos o termo "semelhança de cosseno" ou "distância de cosseno" para designar a diferença entre a orientação de dois vectores. Por exemplo, a que distância se viraria para ficar de frente para a porta da frente?
Facto divertido e aplicável: apesar de "semelhança" e "distância" terem significados diferentes por si só, adicionar cosseno antes de ambos os termos faz com que signifiquem quase a mesma coisa! Este é outro exemplo de [semelhança semântica] (https://zilliz.com/glossary/semantic-similarity) em ação.
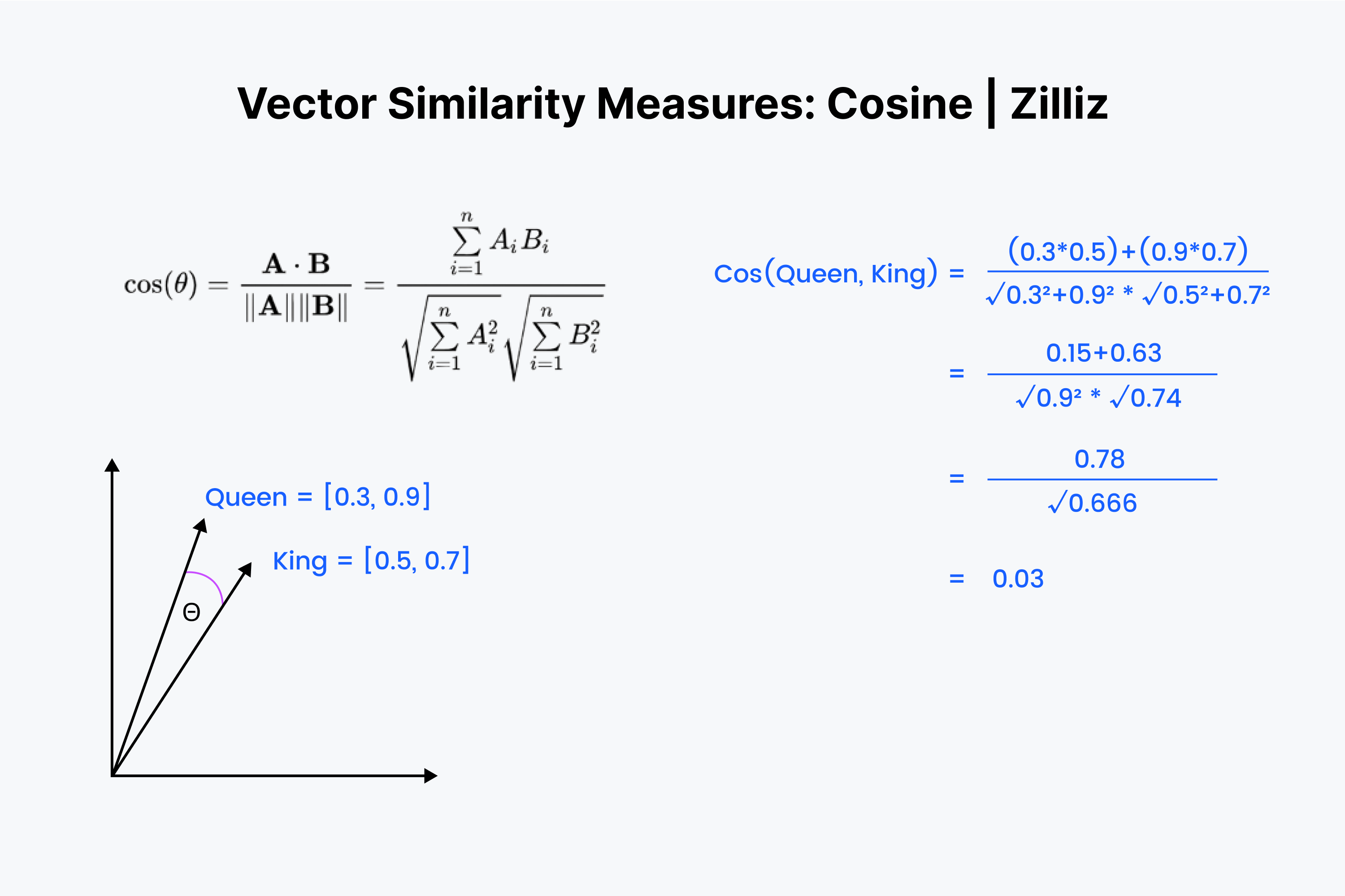
Assim, sabemos que a semelhança de cosseno mede o ângulo entre dois vectores. Mais uma vez, imaginamos os nossos vectores como uma lista de números. No entanto, desta vez o processo é um pouco mais complexo.
Começamos por alinhar os vectores uns sobre os outros. Comece por multiplicar os números e depois adicione todos os resultados. Agora guarde esse número; chame-lhe "x". Em seguida, temos de elevar cada número ao quadrado e adicionar os números em cada vetor. Imagine que eleva cada número ao quadrado horizontalmente e os adiciona a ambos os vectores.
Pegue na raiz quadrada de ambas as somas, multiplique-as e chame a este resultado "y". Encontramos o valor da nossa distância cosseno como "x" dividido por "y".
A semelhança de cosseno é utilizada principalmente em [aplicações de PNL] (https://zilliz.com/learn/top-5-nlp-applications). A principal coisa que a semelhança de cosseno mede é a diferença na orientação semântica. Se trabalhar com vectores normalizados, a semelhança de cosseno é equivalente ao produto interno.
O produto interno é a projeção de um vetor no outro. O valor do produto interno é o comprimento do vetor desenhado. Quanto maior for o ângulo entre os dois vectores, menor será o produto interno. O produto interno também aumenta com o comprimento do vetor mais pequeno. Assim, utilizamos o produto interno quando nos preocupamos com a orientação e a distância. Por exemplo, teria de percorrer uma distância reta através das paredes até ao seu frigorífico.
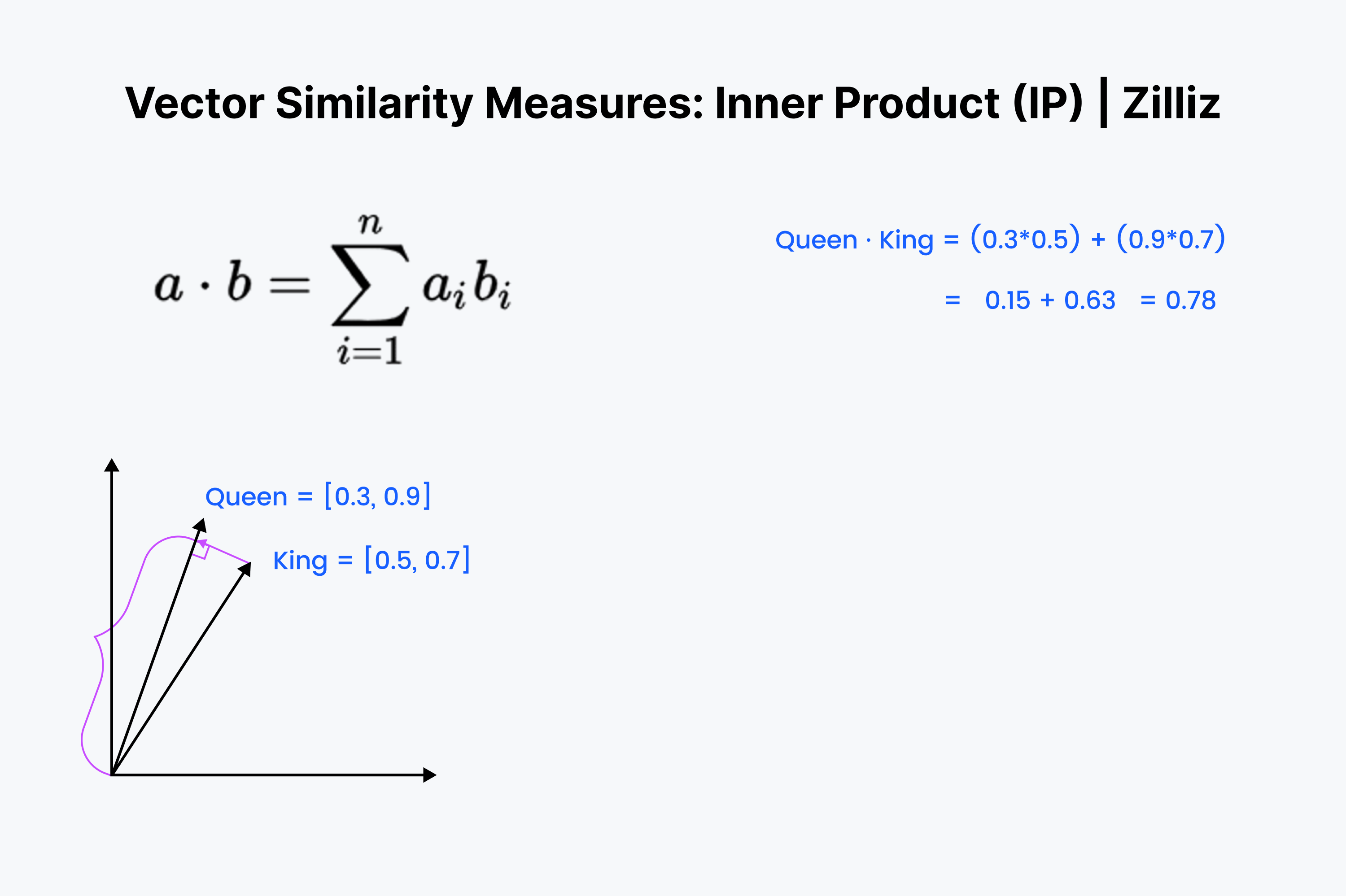
O produto interno deve parecer familiar. É apenas o primeiro ⅓ do cálculo do cosseno. Alinhe esses vetores em sua mente e desça a linha, multiplicando para baixo. Depois, soma-os. Isto mede a distância em linha reta entre si e a soma mais próxima.
O produto interno é como um cruzamento entre a distância euclidiana e a semelhança de cosseno. Quando se trata de conjuntos de dados normalizados, é o mesmo que a similaridade de cosseno, portanto o PI é adequado para conjuntos de dados normalizados ou não normalizados. É uma opção mais rápida do que a similaridade de cosseno e é uma opção mais flexível.
Uma coisa a ter em mente com o produto interno é que ele não segue a desigualdade triangular. Comprimentos maiores (grandes magnitudes) são priorizados. Isso significa que devemos ter cuidado ao usar o IP com [Índice de arquivo invertido] (https://zilliz.com/learn/vetor-index) ou um índice de gráfico como [HNSW] (https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW).
As três métricas vectoriais mencionadas acima são as mais úteis no que diz respeito a vetor embeddings. No entanto, não são as únicas formas de medir a distância entre dois vectores. Eis duas outras formas de medir a distância ou a semelhança entre vectores.
 Grupo 13401.png
Grupo 13401.png
A distância de Hamming pode ser aplicada a vectores ou cadeias de caracteres. Para nossos casos de uso, vamos nos ater aos vetores. A distância de Hamming mede a "diferença" nas entradas de dois vectores. Por exemplo, "1011" e "0111" têm uma distância de Hamming de 2.
Em termos de integração de vectores, a distância de Hamming só faz realmente sentido medir para vectores binários. Os Float vetor embeddings, as saídas da penúltima camada das redes neurais, são constituídos por números de vírgula flutuante entre 0 e 1. Os exemplos podem incluir [0.24, 0.111, 0.21, 0.51235] e [0.33, 0.664, 0.125152, 0.1].
Como se pode ver, a distância de Hamming entre duas incorporações vectoriais será quase sempre apenas o comprimento do próprio vetor. Há demasiadas possibilidades para cada valor. É por isso que a distância de Hamming só pode ser aplicada a vectores binários ou esparsos. O tipo de vectores que são produzidos a partir de um processo como TF-IDF, BM25, ou SPLADE.
A distância de Hamming é boa para medir algo como a diferença de redação entre dois textos, a diferença na ortografia das palavras ou a diferença entre quaisquer dois vectores binários. Mas não é boa para medir a diferença entre as incorporações vectoriais.
Eis um facto divertido. A distância de Hamming é equivalente a somar o resultado de uma operação XOR em dois vectores.
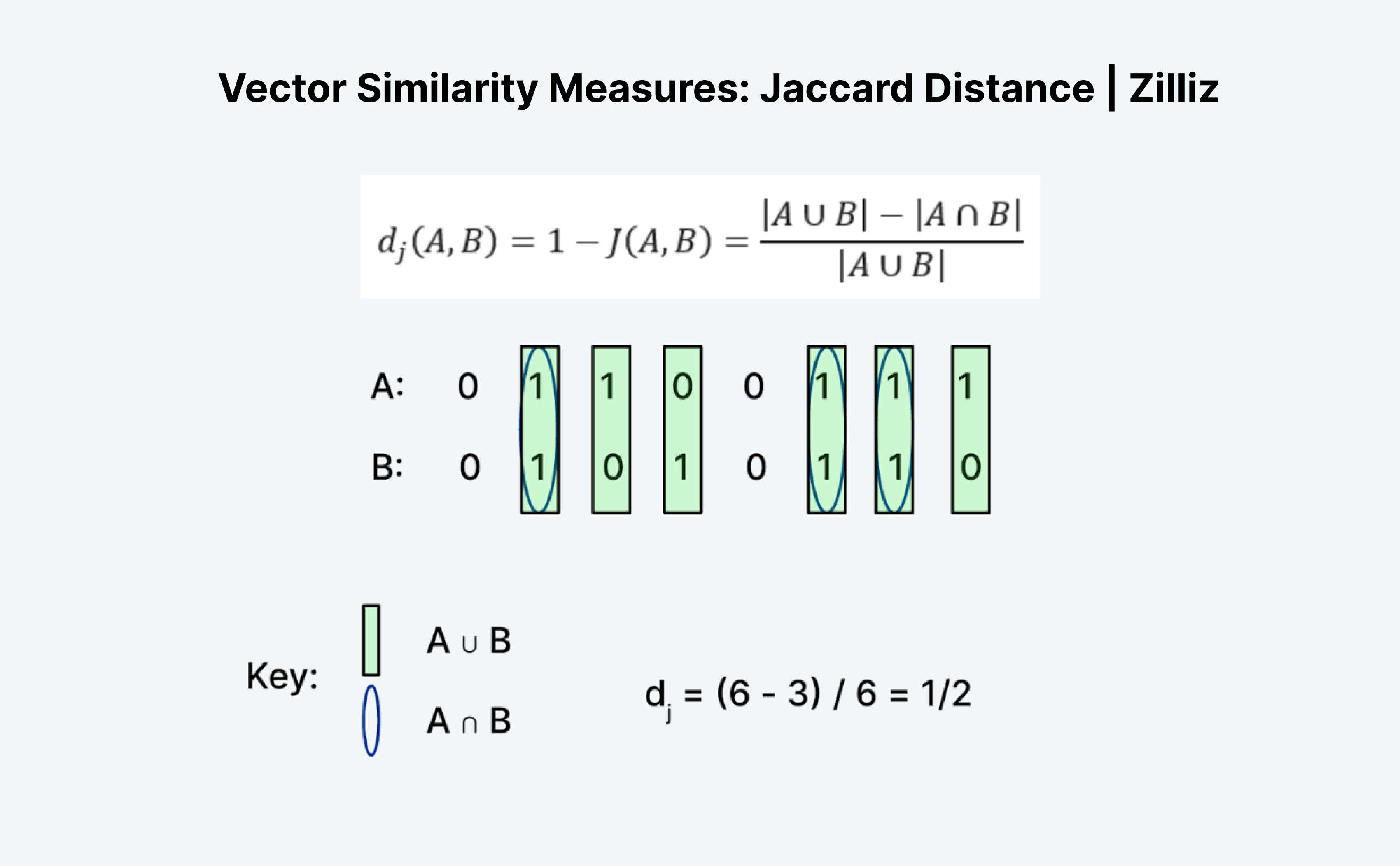
A distância de Jaccard é outra forma de medir a semelhança ou distância de dois vectores. O que é interessante sobre Jaccard é que existe um índice de Jaccard e uma distância de Jaccard. A distância Jaccard é 1 menos o índice Jaccard, a métrica de distância que Milvus implementa.
Calcular a distância ou o índice de Jaccard é uma tarefa interessante porque não faz exatamente sentido à primeira vista. Tal como a distância de Hamming, Jaccard só funciona com dados binários. Considero confusa a formação tradicional de "uniões" e "intersecções". A forma como penso nisto é com a lógica. É essencialmente A "OU" B menos A "E" B dividido por A "OU" B.
Como mostra a imagem acima, contamos o número de entradas em que A ou B é 1 como a "união" e em que A e B são 1 como a "intersecção". Assim, o índice de Jaccard para A (01100111) e B (01010110) é ½. Neste caso, a distância de Jaccard, 1 menos o índice de Jaccard, também é ½.
Nesta postagem, aprendemos sobre as três métricas de pesquisa de similaridade de vetor mais úteis: Distância L2 (também conhecida como Euclidiana), distância cosseno e produto interno. Cada uma delas tem casos de uso diferentes. Euclidiana é para quando nos importamos com a diferença de magnitude. O cosseno é para quando nos preocupamos com a diferença de orientação. O produto interno é quando nos preocupamos com a diferença de magnitude e orientação.
Veja estes vídeos para saber mais sobre a Métrica de Similaridade Vetorial, ou read the docs para saber como configurar estas métricas em Milvus.
Introdução à métrica de similaridade
As métricas de similaridade são uma ferramenta crucial em várias tarefas de análise de dados e aprendizado de máquina. Elas nos permitem comparar e avaliar a similaridade entre diferentes partes de dados, facilitando aplicações como agrupamento, classificação e recomendações. Com inúmeras métricas de semelhança disponíveis, cada uma com os seus pontos fortes e fracos, escolher a métrica correta para uma tarefa específica pode ser um desafio. Nesta secção, introduzimos o conceito de métricas de similaridade, a sua importância e apresentamos uma visão geral das métricas mais utilizadas.
Similaridade de cosseno
A similaridade de cosseno é uma métrica de similaridade amplamente utilizada que mede o cosseno do ângulo entre dois vectores. É comummente utilizada no processamento de linguagem natural e em tarefas de [recuperação de informação] (https://zilliz.com/learn/what-is-information-retrieval). A métrica de semelhança do cosseno é particularmente útil quando se lida com dados de elevada dimensão, uma vez que é computacionalmente eficiente e pode lidar com dados esparsos. A semelhança de cosseno entre dois vectores pode ser calculada utilizando o produto escalar dos vectores dividido pelo produto das suas magnitudes.
Distância Euclidiana
A distância euclidiana, também conhecida como distância em linha reta, é uma métrica de distância amplamente utilizada que mede a distância entre dois pontos num espaço n-dimensional. É calculada como a raiz quadrada da soma das diferenças quadráticas entre os elementos correspondentes dos dois vectores. A distância euclidiana é normalmente utilizada em várias aplicações, incluindo agrupamento, classificação e análise de regressão. No entanto, pode ser sensível a valores atípicos e pode não ter um bom desempenho com dados de elevada dimensão.
Escolhendo a métrica de similaridade correta
A escolha da métrica de similaridade correta depende de vários fatores, incluindo o tipo de dados, os objetivos da análise e a relação entre as variáveis. Por exemplo, a similaridade de cosseno é adequada para dados de alta dimensão e tarefas de processamento de linguagem natural, enquanto a distância euclidiana é normalmente usada para tarefas de agrupamento e classificação. A distância de Manhattan, também conhecida como distância L1, é adequada para dados com valores aberrantes, enquanto a distância de Hamming é utilizada para dados binários. É essencial compreender as caraterísticas e limitações de cada métrica de semelhança para escolher a mais adequada para uma tarefa específica.
Aplicações do mundo real
As métricas de similaridade têm inúmeras aplicações no mundo real em vários campos, incluindo:
Processamento de linguagem natural: A similaridade cosseno é amplamente utilizada na classificação de textos, análise de sentimentos e tarefas de recuperação de informações.
Sistemas de recomendação: As métricas de semelhança, como a semelhança de cosseno e a distância euclidiana, são utilizadas para recomendar produtos ou serviços com base no comportamento e nas preferências do utilizador.
Análise de imagens e vídeos: As métricas de semelhança, como a distância euclidiana e a distância de Manhattan, são utilizadas na classificação de imagens e vídeos, [deteção de objectos] (https://zilliz.com/learn/what-is-object-detection) e tarefas de localização.
Agrupamento e classificação: As métricas de semelhança, como a distância euclidiana e a semelhança cosseno, são utilizadas em tarefas de agrupamento e classificação para agrupar pontos de dados semelhantes.
Em conclusão, as métricas de semelhança são uma ferramenta crucial em várias tarefas de análise de dados e de aprendizagem automática. Compreender as caraterísticas e limitações de cada métrica de semelhança é essencial para escolher a mais adequada para uma tarefa específica. Ao selecionar a métrica de similaridade correta, podemos melhorar a precisão e a relevância dos nossos resultados, conduzindo a melhores decisões e conhecimentos.

Continue lendo

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.