




Desafios de infraestrutura no dimensionamento do RAG com modelos de IA personalizados
Os sistemas Retrieval Augmented Generation (RAG) melhoraram significativamente as aplicações de IA, fornecendo respostas mais exactas e contextualmente relevantes. No entanto, a expansão e a implantação destes sistemas na produção têm apresentado desafios consideráveis à medida que se tornam mais sofisticados e incorporam modelos de IA personalizados.
Durante um recente Unstructured Data Meetup hospedado por Zilliz, Chaoyu Yang, o fundador e CEO da BentoML, compartilhou suas idéias sobre os obstáculos de infraestrutura ao dimensionar sistemas RAG com modelos de IA personalizados e destacou como ferramentas como BentoML poderia simplificar a implantação e o gerenciamento desses componentes. Este post irá recapitular os pontos-chave de Chaoyu Yang e explorar padrões avançados de inferência e técnicas de otimização. Estas estratégias ajudá-lo-ão a construir sistemas RAG que não só são poderosos, mas também eficientes e económicos.
Assista ao replay da palestra de Chaoyu no Youtube
Como o RAG capacita as aplicações de IA
Os sistemas Retrieval Augmented Generation (RAG) surgiram para resolver o problema das alucinações nas aplicações GenAI. Ao integrar as capacidades de recuperação de semelhanças vectoriais de bases de dados vectoriais como Milvus e Zilliz Cloud com o poder generativo de modelos de linguagem de grande dimensão (LLMs), os sistemas RAG permitem que os modelos de IA produzam respostas que são:
Mais exactas
Contextualmente relevantes
Incrivelmente informativo
Sem alucinações
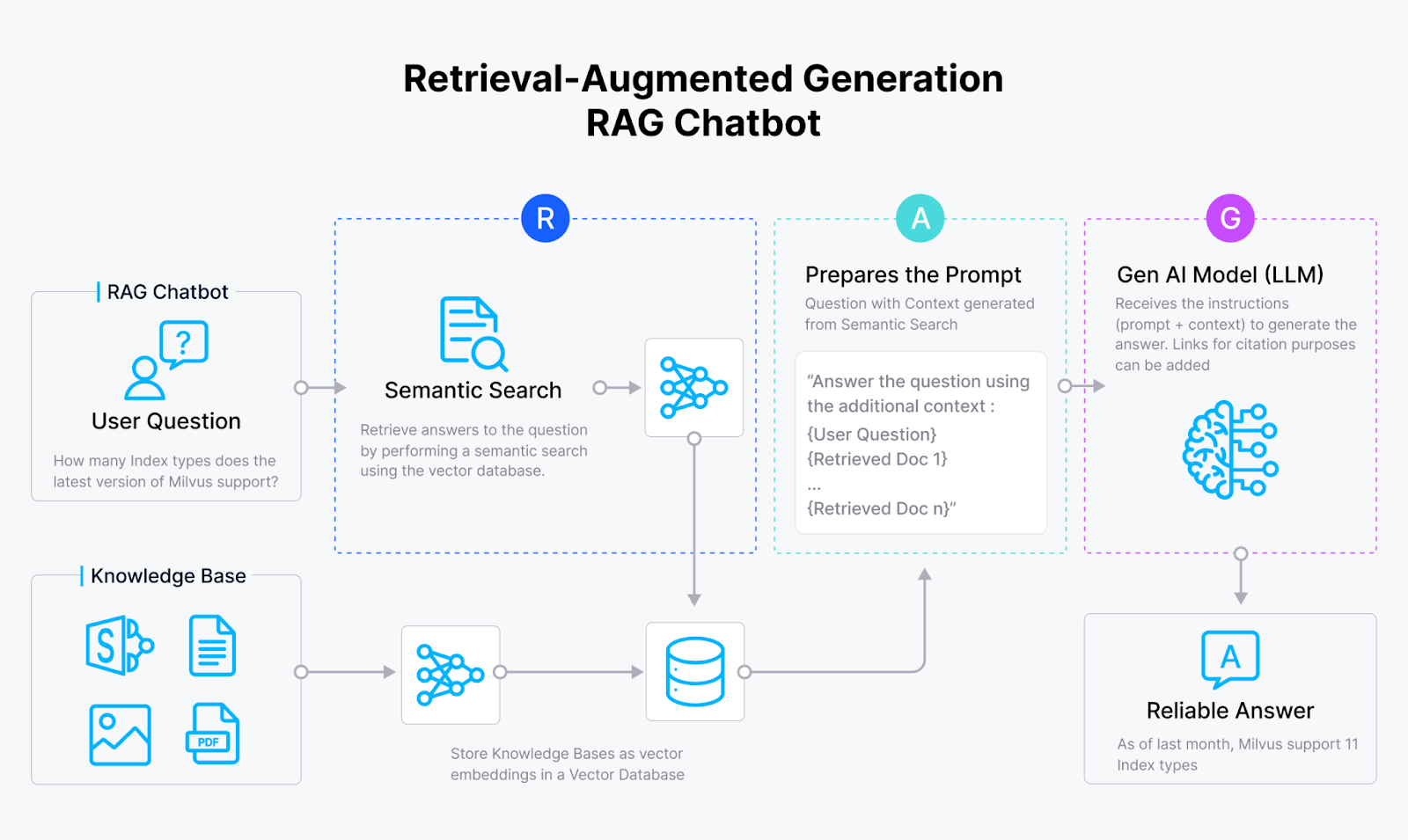
Como funciona um RAG Chatbot
Estes sistemas têm o potencial de transformar uma vasta gama de domínios, incluindo:
Resposta a perguntas
Sumarização de documentos
Geração de conteúdo personalizado
E mais.
Os sistemas RAG atingem este objetivo explorando o vasto conhecimento escondido em fontes externas, como um bibliotecário de IA!
Desafios na implementação de sistemas RAG na produção
Os sistemas RAG têm os seus próprios desafios a ultrapassar antes de poderem salvar o dia em ambientes de produção. Um dos maiores obstáculos é garantir um desempenho de recuperação de alto nível, o que envolve:
Otimizar a recuperação:** Assegurar que todas as informações relevantes são recuperadas
Otimizar a precisão:** Minimizar a quantidade de informação irrelevante
Para tornar as coisas mais interessantes, os sistemas RAG têm frequentemente de lidar com fontes de dados complexas e não estruturadas. Imagine-se a fazer sentido de um PDF com mais esquemas, tabelas e imagens do que uma banda desenhada! Este problema exige algumas técnicas de processamento e compreensão de documentos muito sofisticadas.
Outro desafio que os sistemas RAG enfrentam é gerar respostas precisas, contextualmente apropriadas e alinhadas com a intenção do utilizador. É como escrever uma história coerente utilizando apenas excertos de livros diferentes!
Além disso, garantir a segurança e a fiabilidade do conteúdo gerado também é crucial, especialmente quando os riscos são elevados. Não queremos que os nossos sistemas de IA se tornem desonestos e espalhem desinformação!
Os modelos de IA personalizados são o ajudante de confiança nesta história. Ao afinar e adaptar os modelos de IA a domínios e conjuntos de dados específicos, os programadores podem dar aos seus sistemas RAG os superpoderes de que necessitam para enfrentar estes desafios.
Aproveitamento de modelos de IA personalizados para um melhor desempenho do RAG
Para desbloquear todo o potencial dos sistemas RAG, é crucial tirar partido de modelos de IA personalizados, adaptados ao nosso caso de utilização específico. Ao afinar e otimizar estes modelos, podemos aumentar significativamente o seu desempenho. Vamos explorar algumas áreas-chave onde os modelos de IA personalizados podem ter um impacto significativo.
Modelos de incorporação de texto: A base do sucesso do RAG
Os modelos de incorporação de texto predefinidos, como o "text-embedding-ada-002", muitas vezes não conseguem captar as nuances do nosso domínio específico. Este modelo está classificado em 57º lugar na [tabela de classificação do MTEB] (https://zilliz.com/glossary/massive-text-embedding-benchmark-(mteb)), o que indica que há muito espaço para melhorias.
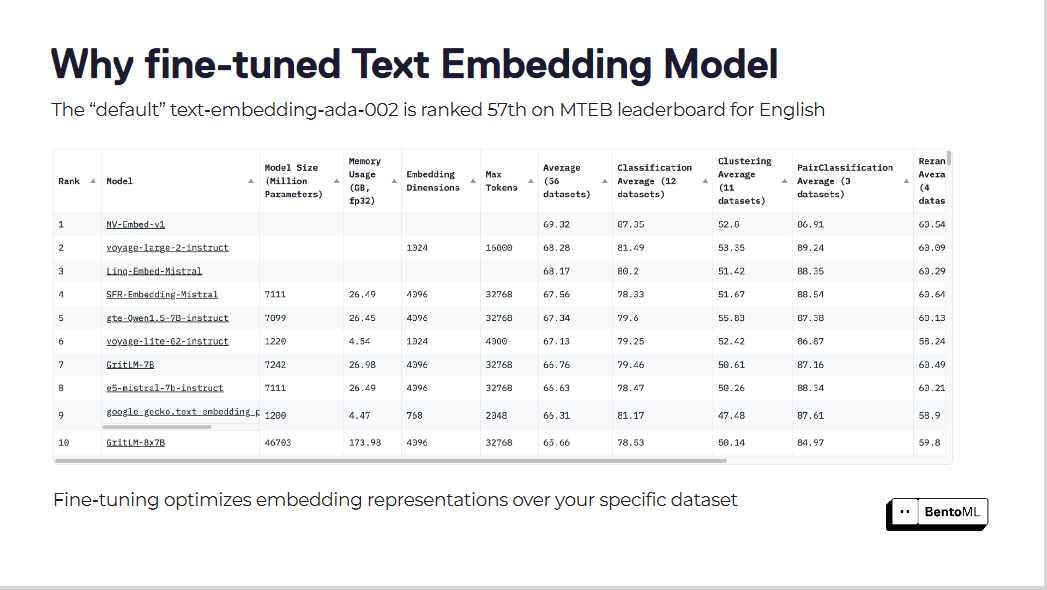
O ajuste fino optimiza as representações de incorporação no seu conjunto de dados específico
O ajuste fino destes modelos de incorporação pode conduzir a melhorias notáveis nos resultados da recuperação. Ao otimizar os modelos de incorporação para os seus conjuntos de dados específicos, os sistemas RAG registaram ganhos substanciais no desempenho.
Hospedando nossos LLMs: Assumir o controlo
Os LLMs proprietários oferecem conveniência, mas podem nem sempre atender às nossas necessidades ou restrições. Os LLMs de código aberto permitem-nos personalizar e adaptar os modelos às nossas necessidades. Ao hospedar nossos LLMs, devemos considerar os seguintes fatores-chave:
Segurança e privacidade dos dados
Latência e desempenho
Capacidades específicas necessárias
Custo e escalabilidade
Manutenção e suporte
Processamento e compreensão de documentos: Extração de insights de dados não estruturados
Os sistemas RAG necessitam frequentemente de processar e compreender documentos complexos e não estruturados, como PDFs, imagens, etc. A integração de vários modelos e técnicas pode ajudar a extrair informações valiosas. Por exemplo, podemos efetuar:
Análise de layout com LayoutLM
Deteção de tabelas com Transformadores de tabelas TATR
OCR com EasyOCR ou Tesseract
Controlo de qualidade visual de documentos com LayoutLM v3 ou Donut
O ajuste fino destes modelos para os seus tipos de documentos específicos pode melhorar significativamente o seu desempenho.
Técnicas avançadas para melhorar a precisão da recuperação
Para melhorar ainda mais a precisão da recuperação, podemos considerar a implementação das seguintes técnicas:
Context-aware chunking e global concept-aware chunking: Estes métodos ajudam a identificar as informações mais relevantes para a recuperação, considerando o contexto e os conceitos abrangentes dentro dos documentos.
Extração de metadados:** A extração de metadados de documentos pode fornecer contexto adicional para uma melhor recuperação e síntese de respostas.
Modelos de reclassificação:** O ajuste fino dos modelos de reclassificação em conjuntos de dados personalizados pode conduzir a um desempenho 10-30% superior ao dos modelos genéricos.
Ao tirar partido dos modelos de IA personalizados nestas áreas-chave, podemos melhorar significativamente o desempenho do nosso sistema RAG.
No entanto, a implantação e o fornecimento eficiente desses modelos trazem seu próprio conjunto de desafios. Na próxima secção, discutiremos alguns desafios de infraestrutura no dimensionamento do RAG com modelos personalizados.
Desafios de infraestrutura no dimensionamento do RAG com modelos personalizados
À medida que os sistemas RAG se tornam mais complexos e incorporam vários modelos personalizados, as exigências em termos de recursos computacionais e a necessidade de uma implementação e gestão eficientes aumentam significativamente. O escalonamento dos sistemas RAG (Retrieval Augmented Generation) com modelos de IA personalizados torna-se um requisito urgente, mas acarreta um conjunto único de desafios em termos de infra-estruturas.
Serviço eficiente de APIs de inferência de modelos personalizados
Um dos principais desafios é o fornecimento eficiente de APIs de inferência de modelos personalizados. Os sistemas RAG geralmente exigem a integração de vários modelos, como:
Modelos de incorporação de texto
Modelos de linguagem de grande porte (LLMs)
Modelos de processamento de documentos
Cada modelo pode ter diferentes requisitos computacionais e caraterísticas de desempenho. A implementação destes modelos como APIs de inferência que podem lidar com pedidos em tempo real e escalar com a procura é complexa.
Para enfrentar este desafio, é essencial ter uma infraestrutura robusta e escalável para servir APIs de inferência de modelos. Essa infraestrutura deve ser capaz de lidar com os requisitos específicos de cada modelo, como alocação de GPU, gerenciamento de memória e restrições de latência. Tecnologias de conteinerização como o Docker podem ajudar a encapsular as dependências do modelo e fornecer um ambiente de tempo de execução consistente em diferentes sistemas.
Mecanismos de escalonamento eficientes
No entanto, simplesmente colocar modelos em contentores não é suficiente. A infraestrutura também deve oferecer suporte a mecanismos de dimensionamento eficientes para lidar com cargas de trabalho variáveis. Esse requisito inclui o dimensionamento automático do número de instâncias de modelo com base no tráfego de solicitação de entrada, garantindo a utilização ideal de recursos e minimizando os tempos de resposta.
Otimização do serviço de modelo
Outro desafio crítico é a otimização da veiculação de modelos para desempenho e eficiência de custos. Modelos de IA personalizados, especialmente modelos de linguagem grandes, podem ser computacionalmente caros. Estratégias de implantação ingênuas podem levar à utilização de recursos abaixo do ideal e ao aumento dos custos. Técnicas como o agrupamento dinâmico, em que várias solicitações são agrupadas para aproveitar o paralelismo das GPUs, podem melhorar significativamente o rendimento e reduzir os tempos de resposta.
Além do batching dinâmico, outras técnicas de otimização, como a quantização, a poda e a destilação de modelos, podem ser aplicadas para reduzir o espaço de memória e os requisitos computacionais dos modelos personalizados. No entanto, a implementação dessas otimizações requer uma consideração cuidadosa das compensações entre o desempenho do modelo e a eficiência dos recursos.
Alocação eficiente de recursos e escalonamento automático
A alocação eficiente de recursos e o escalonamento automático também são aspectos críticos do escalonamento de sistemas RAG com modelos personalizados. A infraestrutura deve ser capaz de alocar recursos dinamicamente com base nos requisitos de carga de trabalho de cada modelo. Esta abordagem envolve a monitorização de métricas importantes, como a utilização da GPU, a utilização da memória e a latência dos pedidos, para tomar decisões de escalonamento informadas. Os mecanismos de dimensionamento automático devem ser capazes de lidar com picos súbitos de tráfego e dimensionar os recursos em conformidade para manter um desempenho ótimo.
Composição e orquestração de vários modelos
Além disso, a infraestrutura deve suportar a composição e a orquestração de vários modelos num sistema RAG. Os sistemas RAG envolvem frequentemente condutas complexas em que o resultado de um modelo serve de entrada para outro. A infraestrutura deve fornecer ferramentas e quadros para definir e gerir estas condutas, garantindo um fluxo de dados sem descontinuidades e uma execução eficiente.
Monitorização e observabilidade
A monitorização e a observabilidade são cruciais para manter a saúde e o desempenho dos sistemas RAG com modelos personalizados. A infraestrutura deve fornecer capacidades de monitorização abrangentes para acompanhar as principais métricas, registos e rastreios em todos os componentes do sistema. Isto permite uma rápida deteção e diagnóstico de problemas e optimiza e afina o sistema com base em dados de desempenho do mundo real.
Integração e implantação contínuas (CI/CD)
Finalmente, a infraestrutura deve suportar a integração e implantação contínuas de modelos personalizados (CI/CD). À medida que os modelos são actualizados e refinados, deve ser estabelecido um processo simplificado para a implementação de novas versões sem perturbar o sistema global. Para tal, são necessários mecanismos robustos de criação de versões, testes e reversão para garantir a estabilidade e a fiabilidade do sistema RAG.
A resolução destes desafios de infraestrutura exige uma combinação de ferramentas, estruturas e melhores práticas. Na próxima secção, vamos explorar a forma como o BentoML, uma plataforma para servir e implementar modelos de aprendizagem automática, pode ajudar a enfrentar estes desafios e simplificar o dimensionamento dos sistemas RAG com modelos de IA personalizados.
Criar APIs de inferência para modelos personalizados com o BentoML
O BentoML simplifica o processo de criação e implementação de APIs de inferência para modelos personalizados em sistemas RAG. Proporciona uma transição perfeita do desenvolvimento de modelos para APIs prontas para produção, permitindo uma iteração mais rápida e uma integração mais fácil com os sistemas existentes. Vamos ver como pode ajudar-nos a ultrapassar os desafios de infraestrutura para escalar o RAG.
Do script de inferência ao ponto de extremidade de serviço
Com apenas algumas linhas de código, pode facilmente converter o seu script de inferência num endpoint de serviço usando o BentoML. Vamos dar uma olhadela a um exemplo de criação de um serviço BentoML para um modelo de incorporação de texto afinado:
import torch
from sentence_transformers import SentenceTransformer, models
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
frases: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Este trecho de código define a classe SentenceTransformers para encapsular o modelo de codificação e seus métodos associados. Dentro do método init__``, o modelo SentenceTransformeré inicializado com um modelo ajustado e configurado para rodar no dispositivo "cuda". O método ``` encode recebe uma lista de sentenças como entrada e retorna seus embeddings como um array NumPy.
Para transformar isso em um serviço BentoML, você pode adicionar os decoradores @bentoml.service`` e @bentoml.api``:
importar bentoml
@bentoml.service
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
frases: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Para servir o modelo, pode usar o CLI do BentoML:
bentoml serve .
Este comando inicia o servidor BentoML e serve o modelo definido no diretório atual. A saída da CLI mostra que o serviço está a ouvir em [http://localhost:3000](http://localhost:3000).
Pode então fazer pedidos ao modelo servido utilizando o cliente BentoML:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
resultado: np.NDArray = cliente.encode(
sentences=["sample input sentence"],
)
Optimizações de serviço
O BentoML fornece várias optimizações de serviço out-of-the-box. Uma das mais poderosas optimizações é o dynamic batching. Ao adicionar o parâmetro ``` batchable=True`` à sua definição de API, o BentoML automaticamente agrupa os pedidos recebidos, optimizando a utilização do GPU e melhorando o rendimento do modelo servido.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
O Dynamic batching forma pequenos lotes de forma inteligente, agrupando os pedidos recebidos, dividindo grandes lotes e ajustando automaticamente o tamanho do lote. Essa otimização pode trazer um tempo de resposta até 3x mais rápido e uma melhoria de ~200% na taxa de transferência para o serviço de incorporação.
Infraestrutura de implantação e de serviço
O BentoML oferece um deployment e uma infraestrutura flexível e escalável para o serving. Suporta várias opções de implementação, incluindo a contentorização com Docker e a orquestração com Kubernetes. Pode facilmente especificar os requisitos de recursos, tais como o número e tipo de GPUs, e configurar definições de tráfego como concorrência e filas externas.
importar bentoml
@bentoml.service(
recursos={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
tráfego={
"concurrency": 512,
"external_queue": True
}
)
classe SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
As capacidades de micro-batching adaptativo e escalonamento elástico do BentoML garantem a utilização óptima dos recursos e o escalonamento automático com base no tráfego de entrada. Ele também fornece um painel de implantação fácil de usar que oferece informações sobre a taxa de solicitação, o tempo de resposta e a utilização de recursos. A seguir, vamos ver como escalar a inferência LLM com o BentoML.
Escalando serviços de inferência LLM com o BentoML
O BentoML fornece funcionalidades e optimizações abrangentes para o ajudar a escalar os seus serviços de inferência LLM de forma eficiente.
Estratégias de Escalonamento Automático
O escalonamento automático assegura que os seus serviços de inferência LLM podem lidar com cargas de trabalho variáveis e manter um desempenho ótimo. No entanto, as métricas tradicionais de dimensionamento automático, como utilização de GPU e consultas por segundo (QPS), podem não refletir com precisão o número desejado de réplicas para serviços LLM.
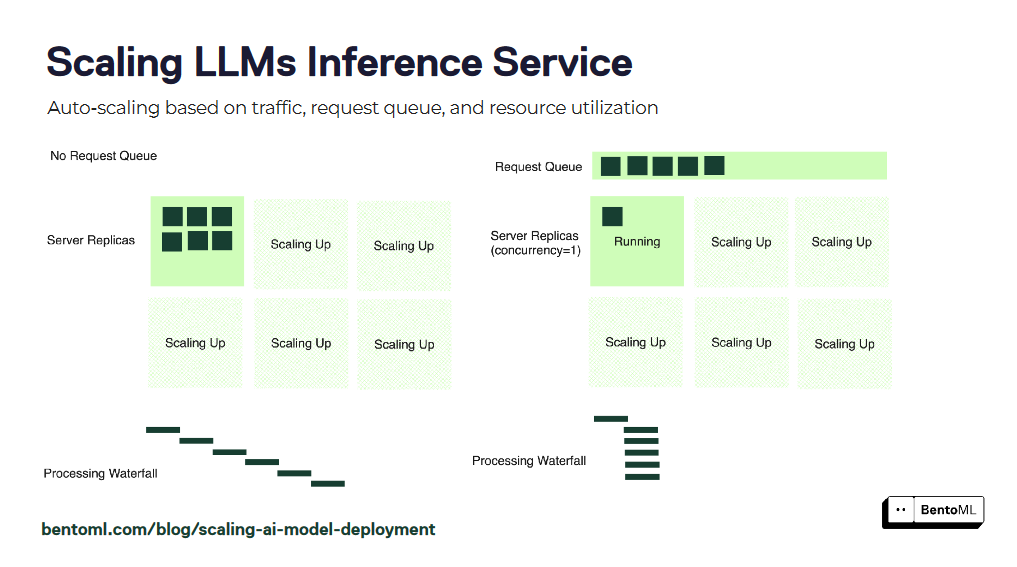
O BentoML introduz o escalonamento automático baseado em concorrência, uma abordagem mais eficaz para escalonar serviços de inferência LLM. O escalonamento automático baseado em concorrência considera o número de pedidos simultâneos que cada réplica do modelo pode tratar, fornecendo uma representação mais precisa da capacidade do serviço.
Otimização de arranque a frio
Os arranques a frio podem ser um desafio significativo quando se escalam serviços de inferência LLM, especialmente com grandes imagens de contentores e ficheiros de modelos. O BentoML oferece várias técnicas de otimização para mitigar a latência do arranque a frio.
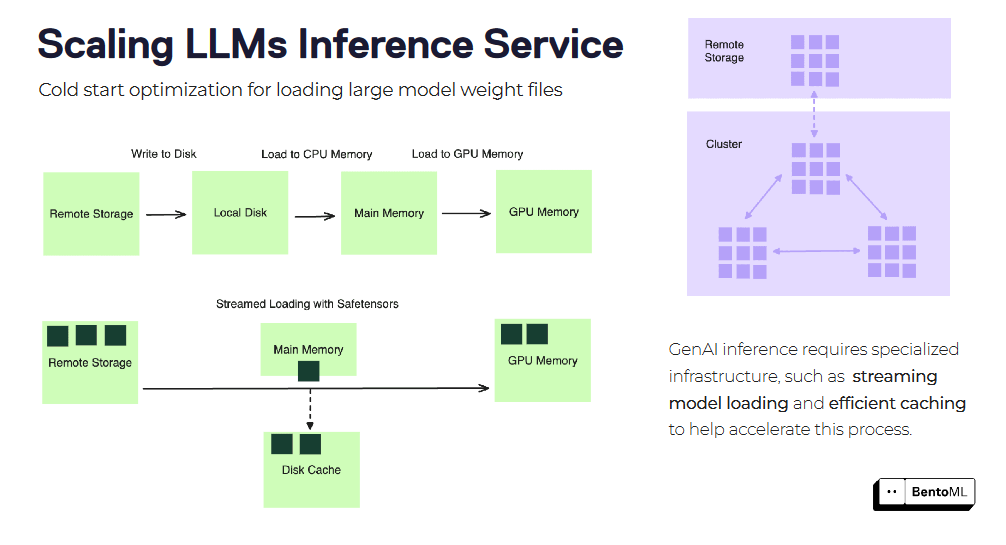
Uma dessas técnicas é o carregamento em fluxo de imagens de contentores. Em vez de descarregar toda a imagem do contentor antes de iniciar o serviço, o BentoML pode carregar a imagem em fluxo, indo buscar apenas os ficheiros necessários a pedido. Isto pode reduzir significativamente o tempo de arranque de novas réplicas.
Outra otimização é o carregamento eficiente do ficheiro de peso do modelo e a sua colocação em cache. O BentoML pode armazenar em cache os pesos do modelo carregado nas réplicas, reduzindo o tempo necessário para carregar o modelo para cada novo pedido. Isto é particularmente benéfico para modelos de linguagem grandes com ficheiros de pesos extensos.
Aproveitando as estratégias de escalonamento automático do BentoML e as optimizações de arranque a frio, pode escalar eficazmente os seus serviços de inferência LLM para lidar com as exigências do seu sistema RAG. O BentoML abstrai as complexidades da gestão da infraestrutura, permitindo-lhe concentrar-se no desenvolvimento e na iteração dos seus modelos, assegurando simultaneamente um desempenho e uma escalabilidade óptimos.
Padrões de Inferência Avançados para Sistemas RAG
Os sistemas RAG requerem frequentemente padrões de inferência avançados para lidar com fluxos de trabalho complexos e otimizar o desempenho. O BentoML fornece uma estrutura flexível e extensível para suportar estes padrões, permitindo a criação de sistemas RAG sofisticados com facilidade.
Os pipelines de processamento de documentos podem ser construídos combinando vários modelos e passos de processamento, tais como análise de layout, extração de tabelas e OCR.
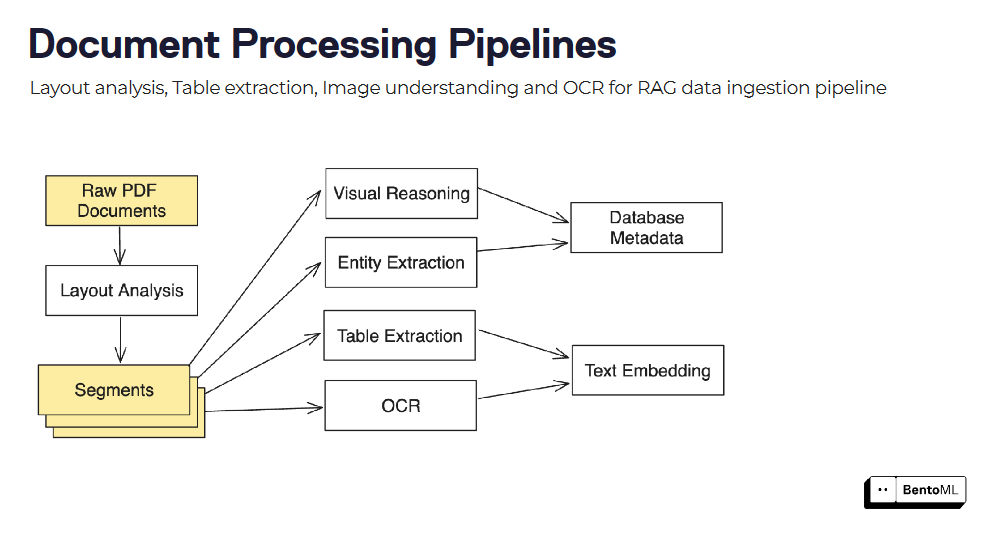
A interface de inferência assíncrona do BentoML lida eficientemente com tarefas de longa duração, enquanto que o seu suporte de inferência em lote permite o processamento de grandes conjuntos de dados aproveitando o paralelismo e as optimizações.
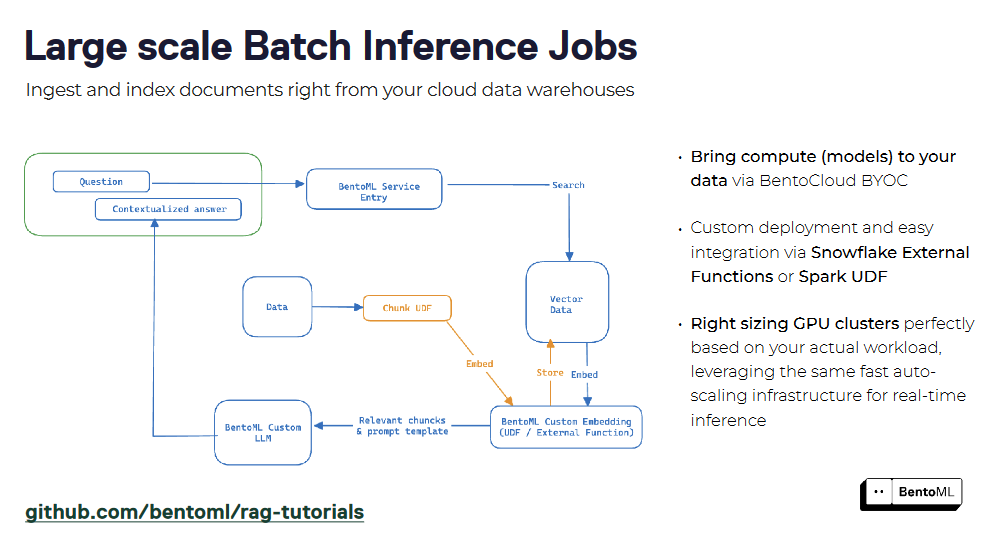
Os sistemas RAG podem ser empacotados como um serviço utilizando o BentoML, criando uma interface unificada para consulta e interação. Ao encapsular os componentes retriever e generator, pode implementar facilmente um serviço RAG e integrá-lo com outras aplicações. O suporte do BentoML para contentorização e orquestração simplifica o escalonamento e a gestão dos serviços RAG em ambientes de produção.
Estes padrões de inferência avançados mostram a flexibilidade e extensibilidade do BentoML na construção de serviços RAG poderosos e eficientes que lidam com várias tarefas e cargas de trabalho.
Para além da infraestrutura para servir LLMs, precisamos também de uma base de dados vetorial robusta para armazenar as nossas incorporações vectoriais e efetuar uma pesquisa de semelhanças. É aqui que a base de dados de vectores Milvus nos ajuda. Na próxima secção, vamos analisar a construção de uma aplicação RAG simples utilizando o BentoML e o Milvus.
Integrando o BentoML e a base de dados vetorial Milvus
O Milvus é uma base de dados vetorial de código aberto concebida para pesquisa de similaridade de alto desempenho e é um componente de infraestrutura essencial para a construção do Retrieval Augmented Generation (RAG).
O Milvus foi integrado com o BentoML, facilitando a criação de aplicações RAG escaláveis. Esta secção irá guiá-lo na construção de uma aplicação RAG com o BentoML e a base de dados vetorial Milvus. Neste exemplo, vamos utilizar o Milvus Lite, a versão mais leve do Milvus, para uma prototipagem rápida.
O conjunto de dados que utilizamos pode ser encontrado aqui: City data.
**Passo 1: Configurar o ambiente
Primeiro, instale as bibliotecas necessárias, conforme mostrado abaixo:
# Instalar as bibliotecas necessárias
pip install -U pymilvus bentoml
Passo 2: Prepare seus dados
Vamos descarregar e processar os dados da cidade.
importar os
importar requests
import urllib.request
# Configurar a fonte de dados
repo = "ytang07/bento_octo_milvus_RAG"
diretório = "dados"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{diretory}"
# Descarregar ficheiros do GitHub
resposta = requests.get(api_url)
dados = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Processar os dados descarregados
def chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
frases = text.split("\n")
return [s for s in sentences if len(s) > 7]
cidades = os.listdir("dados_da_cidade")
pedaços_de_cidades = []
for city in cities:
chunked = chunk_text(f "cidade_data/{cidade}")
city_chunks.append({
"nome_da_cidade": cidade.split(".")[0],
"pedaços": pedaços
})
Passo 3: Configurar clientes BentoML
Agora vamos configurar os clientes BentoML para o modelo de incorporação e para o LLM como mostrado abaixo.
importar bentoml
# Configurar endpoints e token API
EMBEDDING_ENDPOINT = "YOUR_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "SEU_LLM_ENDPOINT"
API_TOKEN = "SEU_API_TOKEN"
# Inicializar os clientes BentoML
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Substitua os endpoints e o token do placeholder pelos seus endpoints de implementação do BentoML e pelo token da API. Estes clientes vão permitir-nos gerar embeddings e usar o modelo de linguagem para a geração de texto.
Passo 4: Gerar Embeddings
Antes de gerar os embeddings, vamos criar uma função de embedding como se mostra abaixo:
Criar função de incorporação
def get_embeddings(texts):
# Lida com grandes lotes de textos
se len(texts) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
para split in splits:
embedding_split = embedding_client.encode(sentences=split)
registos += registos_split
return embeddings
# Lidar diretamente com pequenos lotes
return embedding_client.encode(frases=textos)
Esta função lida com lotes para grandes conjuntos de textos, pois o modelo de embedding pode ter limitações de tamanho de entrada.
Gerar embeddings para todos os chunks.
entradas = []
for city_dict in city_chunks:
# Obter embeddings para os pedaços de texto de cada cidade
embedding_list = get_embeddings(city_dict["chunks"])
# Criar entradas com embeddings e metadados
for i, embedding in enumerate(embedding_list):
entry = {
"embedding": embedding,
"frase": ditado_da_cidade["pedaços"][i],
"city": city_dict["city_name"],
}
entradas.append(entrada)
Aqui, estamos a criar uma lista de entradas, cada uma contendo a incorporação, a frase original e o nome da cidade. Essa estrutura será útil quando você inserir dados no Milvus.
Passo 5: Configurar o Milvus
Agora vamos inicializar uma base de dados vetorial usando o Milvus para adicionar os embeddings.
Inicializar o cliente Milvus e criar o esquema
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # Isto deve corresponder à dimensão de saída do seu modelo de incorporação
# Inicializar o cliente Milvus
milvus_client = MilvusClient("milvus_demo.db")
# Criar um esquema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
Estamos a utilizar o Milvus lite aqui, que está incorporado na aplicação. O esquema define a nossa estrutura de dados em Milvus, incluindo um ID gerado automaticamente e o vetor de incorporação.
Preparar os parâmetros do índice e criar uma coleção
# Preparar os parâmetros do índice
index_params = milvus_client.prepare_index_params()
index_params.add_index(
nome_do_campo="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Criar ou recriar coleção
if milvus_client.has_collection(nome_da_colecção=NOME_DA_COLEÇÃO):
milvus_client.drop_collection(nome_da_colecção=NOME_DA_COLEÇÃO)
milvus_client.create_collection(
nome_da_colecção=NOME_DA_COLEÇÃO, esquema=esquema, parâmetros_de_índice=parâmetros_de_índice
)
Estamos a utilizar o AUTOINDEX, que seleciona automaticamente o melhor tipo de índice com base nos dados. A Cosine similarity é utilizada como métrica de distância para comparações de vectores.
**Inserir dados no Milvus
Agora, vamos inserir os dados no Milvus como mostrado abaixo
# Inserir dados pré-processados no Milvus
milvus_client.insert(nome_da_colecção=NOME_DA_COLECÇÃO, dados=entradas)
Este passo insere todos os nossos dados pré-processados (embeddings e metadados) na coleção do Milvus.
Passo 6: Implementar o RAG
Para implementar o RAG de forma eficiente, vamos criar três funções para gerar a resposta do RAG, obter o contexto relevante da coleção e gerar a resposta, como se mostra abaixo:
Criar uma função para o LLM para gerar respostas
def generate_rag_response(pergunta, contexto):
# Prepara o prompt para o LLM
prompt = (
f "Você é um assistente útil. Responde à pergunta do utilizador com base apenas no contexto: {contexto}. \n"
f "A pergunta do utilizador é {question}"
)
# Gerar resposta utilizando o LLM
resultados = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
Esta função constrói um prompt usando o contexto recuperado e a pergunta do usuário e então usa o LLM para gerar uma resposta.
Criar uma função para obter o contexto relevante
def retrieve_context(pergunta):
# Gera a incorporação para a pergunta
embeddings = get_embeddings([pergunta])
# Procurar vectores semelhantes em Milvus
res = milvus_client.search(
nome_da_colecção=NOME_DA_COLEÇÃO,
data=embeddings,
anns_field="embedding",
limit=5,
output_fields=["sentence"],
)
# Extrair e combinar frases relevantes
frases = [hit["entidade"]["frase"] for hits in res for hit in hits]
return ". ".join(sentences)
Esta função incorpora a pergunta do utilizador, procura vectores semelhantes em Milvus, e recupera os pedaços de texto correspondentes para contexto.
Combine as funções acima para criar o pipeline RAG
def ask_question(question):
# Recupera o contexto relevante
context = retrieve_context(question)
# Gerar resposta baseada no contexto e na pergunta
return generate_rag_response(question, context)
Esta função junta tudo, criando o nosso pipeline RAG.
Etapa 7: Use seu sistema RAG
Agora podemos usar o nosso sistema RAG para responder a perguntas, como mostrado abaixo:
# Exemplo de utilização
pergunta = "Em que estado está Cambridge?"
resposta = ask_question(pergunta)
print(f "Pergunta: {pergunta}")
print(f "Resposta: {answer}")
Este exemplo demonstra como utilizar o sistema RAG para responder a uma pergunta específica sobre uma cidade.
Notas importantes:
Antes de executar este código, certifique-se de que os seus modelos de incorporação e de linguagem de grande dimensão estão corretamente implementados no BentoML.
A dimensão dos seus embeddings (384 neste exemplo) deve corresponder à saída do seu modelo de embedding.
Esta configuração usa o Milvus Lite, que é adequado para conjuntos de dados menores. Considere usar uma implantação completa do Milvus no Docker ou K8s para aplicativos de grande escala.
A eficácia do sistema RAG depende da qualidade e da cobertura dos dados iniciais da cidade. Certifique-se de que o seu conjunto de dados é abrangente e exato para obter os melhores resultados.
Esta integração do BentoML e do Milvus cria um poderoso sistema RAG capaz de responder a perguntas com base na informação fornecida sobre a cidade. Pode alargar este sistema adicionando mais dados ou afinando-o para casos de utilização específicos.
Conclusão
Construir e escalar sistemas Retrieval Augmented Generation (RAG) com modelos de IA personalizados apresenta desafios únicos. Os programadores podem criar sistemas RAG de elevado desempenho e escaláveis, tirando partido do poder dos modelos personalizados, optimizando a implantação e a infraestrutura de serviço e adoptando padrões de inferência avançados.
O BentoML é uma ferramenta valiosa nesta jornada. Simplifica o processo de criação e implementação de APIs de inferência, optimiza o desempenho do serviço e permite um escalonamento contínuo.
Ao integrar o BentoML com a base de dados vetorial Milvus, as organizações podem criar sistemas RAG mais potentes e escaláveis. Esta combinação permite a recuperação eficiente de informações relevantes e a geração de respostas sensíveis ao contexto, abrindo possibilidades para aplicações avançadas de IA em vários domínios e indústrias.
Para mais informações sobre BentoML e RAG, consulte os seguintes recursos
RAG sem OpenAI: BentoML, OctoAI e Milvus - blogue Zilliz](https://zilliz.com/blog/rag-without-open-ai-bentoml-octoai-milvus)
Como melhorar o desempenho do seu pipeline RAG - Zilliz blog
Dominando os desafios do LLM: uma exploração do RAG - Blogue do Zilliz](https://zilliz.com/learn/RAG-handbook)
Por que o Milvus torna a criação de RAG mais fácil, rápida e econômica - blog do Zilliz
Continue lendo

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.