




Tutto ciò che devi sapere su Llama 2

Tutto ciò che devi sapere su Llama 2
Che cos'è Llama 2?
Llama 2, introdotto da Meta AI nel 2023, rappresenta un progresso significativo nei modelli linguistici di grandi dimensioni (LLM). Questi modelli, Llama 2 e Llama 2-CHAT, arrivano fino a 70 miliardi di parametri e sono disponibili gratuitamente per scopi di ricerca e commerciali, rappresentando un balzo in avanti nelle capacità di elaborazione del linguaggio naturale (NLP), dalla generazione di testo all'interpretazione del codice di programmazione.
Basandosi sul suo predecessore, LLaMa 1, che inizialmente era accessibile solo agli istituti di ricerca con una licenza non commerciale, Llama 2 segna un importante passaggio verso la democratizzazione dell'accesso alle tecnologie di IA all'avanguardia. A differenza del suo predecessore, i modelli Llama 2 sono “open-source” e quindi liberamente disponibili per applicazioni di ricerca e commerciali, riflettendo l'impegno di Meta nel promuovere un ecosistema di IA generativa più inclusivo e collaborativo.
Il rilascio di Llama 2 offre accesso a LLM all'avanguardia e affronta le sfide computazionali associate al loro sviluppo. Ottimizzando le prestazioni senza aumentare esponenzialmente il numero di parametri, Llama 2 offre modelli con dimensioni dei parametri variabili, da 7 miliardi a 70 miliardi. Questo approccio strategico consente alle organizzazioni più piccole e alle comunità di ricerca di sfruttare la potenza degli LLM senza risorse di calcolo esorbitanti.
Inoltre, la dedizione di Meta alla trasparenza è evidente nella sua decisione di rilasciare sia il codice sia i pesi del modello di Llama 2, facilitando una maggiore comprensione e collaborazione all'interno della comunità di ricerca sull'IA. Riducendo le barriere all'ingresso e promuovendo l'accessibilità, Llama 2 apre la strada a un futuro più inclusivo e innovativo nella ricerca e nello sviluppo dell'IA.
Llama 2
Llama 2 è una versione aggiornata di Llama 1 addestrata su un nuovo mix di dati pubblici. Il set di dati pre-addestrato è stato aumentato del 40%, la lunghezza del contesto è stata raddoppiata e il team di Meta ha adottato l'attenzione grouped-query nella costruzione di Llama 2.
| Dati di addestramento | Parametri | Lunghezza del contesto | Attenzione group-query | Token | |
| Llama 1 | Vedi Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Un nuovo mix di dati online pubblicamente disponibili | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT è una versione ottimizzata di Llama 2 che il team di Meta ha ottimizzato per casi d'uso del linguaggio naturale. Le varianti di questo modello sono disponibili con 7B, 13B e 70B parametri. Llama 2-Chat è soggetto alle stesse limitazioni ben riconosciute di altri LLM, inclusa la cessazione degli aggiornamenti della conoscenza dopo il preaddestramento, il potenziale di generazione non fattuale come consigli non qualificati e una propensione alle allucinazioni.
Llama 2 open source
Sebbene Meta abbia generosamente fornito accesso al codice iniziale e ai pesi dei modelli Llama 2 per scopi di ricerca e commerciali, sono sorte discussioni sull'appropriatezza di etichettarlo come "open source" a causa di alcune restrizioni delineate nel suo accordo di licenza.
Il dibattito sulla classificazione dei termini di licenza di Llama 2 dipende da sfumature tecniche e semantiche. Sebbene "open source" sia comunemente usato colloquialmente per indicare qualsiasi software con codice sorgente liberamente accessibile, ha un significato specifico come designazione formale supervisionata dalla Open Source Initiative (OSI). Per qualificarsi come "approvata dalla Open Source Initiative", una licenza software deve aderire ai dieci criteri delineati nella Open Source Definition (OSD) ufficiale.
Pertanto, l'applicabilità dell'etichetta "open source" ai modelli Llama 2 dipende dal fatto che i suoi termini di licenza siano allineati ai rigorosi criteri stabiliti dall'OSI. Questa distinzione sottolinea l'importanza della chiarezza e della precisione nel discutere l'accessibilità e la distribuzione delle risorse software all'interno della più ampia comunità di sviluppo.
Tuttavia, sebbene Llama 2 non sia completamente open-source, offre agli sviluppatori un modello interessante con molta più flessibilità rispetto ai modelli chiusi creati da OpenAI, Google e altri importanti attori nel campo dell'IA generativa.
Architettura di Llama 2
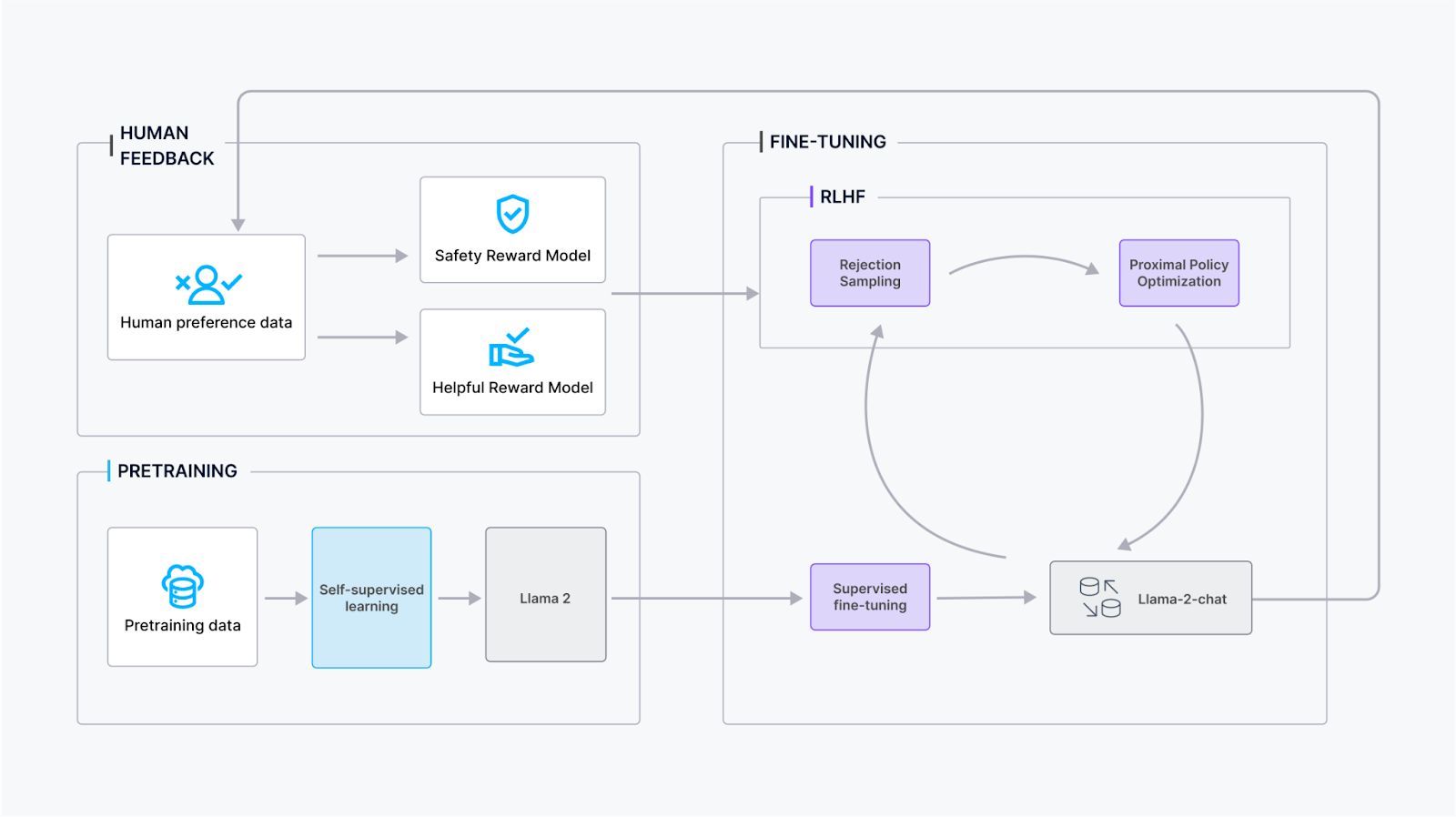
Il processo di addestramento per Llama 2-Chat prevede diverse fasi per garantire prestazioni e affinamento ottimali:
Preaddestramento: Llama 2 viene sottoposto a preaddestramento utilizzando fonti online pubblicamente disponibili per stabilire conoscenze fondamentali e comprensione del linguaggio.
Fine-tuning supervisionato: Il team di Meta ha creato una versione iniziale di Llama 2-Chat tramite fine-tuning supervisionato, in cui il modello apprende da dati etichettati per migliorare le sue capacità conversazionali.
Apprendimento per rinforzo con feedback umano (RLHF): Il modello viene sottoposto ad affinamento iterativo utilizzando metodologie RLHF, principalmente tramite rejection sampling e Proximal Policy Optimization (PPO). Questa fase prevede un'interazione continua con il feedback umano per migliorare la qualità conversazionale.
Modellazione iterativa della ricompensa: Durante tutta la fase RLHF, l'accumulo dei dati di modellazione iterativa della ricompensa avviene in parallelo con i miglioramenti del modello. La modellazione iterativa della ricompensa garantisce che i modelli di ricompensa rimangano all'interno della distribuzione, contribuendo a migliorare costantemente le capacità conversazionali del modello.
Incorporando questi passaggi, l'addestramento di Llama 2-Chat mira a raggiungere prestazioni conversazionali solide adattandosi al feedback degli utenti e mantenendo l'allineamento con i modelli di ricompensa.
Che cos'è un embedding nel machine learning?
Nel machine learning, un embedding si riferisce a una rappresentazione appresa di oggetti in uno spazio vettoriale continuo, come parole, immagini o entità. Questi embedding catturano relazioni semantiche e somiglianze tra oggetti, rendendoli più adatti alle attività computazionali. Nel natural language processing (NLP), gli embedding di parole, ad esempio, mappano le parole da un vocabolario a vettori densi in uno spazio ad alta dimensionalità, dove parole simili sono vicine tra loro.
In Llama 2, gli embedding svolgono un ruolo cruciale nella comprensione e nella generazione del linguaggio naturale. Llama 2 utilizza gli embedding per rappresentare parole, frasi o intere proposizioni in uno spazio vettoriale continuo. Llama 2 può elaborare e generare testo in modo efficace incorporando input e output linguistici, catturando al contempo relazioni semantiche e sfumature.
Ad esempio, Llama 2 apprende embedding per parole e frasi dall'enorme corpus di testo su cui viene addestrato durante il processo di addestramento. Questi embedding codificano informazioni semantiche sulla lingua, consentendo a Llama 2 di comprendere e generare risposte coerenti a query o prompt.
Gli embedding nel machine learning, inclusi quelli utilizzati in Llama 2, facilitano la rappresentazione del linguaggio e di altri dati in modo strutturato e semanticamente significativo, consentendo un'elaborazione, una comprensione e una generazione efficaci del linguaggio naturale.
Come usare Llama 2?
Per usare Llama 2 in modo efficace, accedi al modello tramite l'interfaccia o l'API fornita, assicurandoti che le autorizzazioni siano configurate. Prepara i tuoi dati di input, che siano testo, immagini o formati compatibili, e pre-elaborali secondo necessità. Specifica il compito per Llama 2, come la generazione di testo o la sintesi. Inserisci i dati pre-elaborati in Llama 2, recupera l'output e valutane la qualità. Sperimenta con formati e configurazioni diversi per ottimizzare i risultati. Monitora metriche di prestazione come accuratezza e velocità, adattando le strategie in base al feedback. Rimani aggiornato sui miglioramenti per massimizzare l'efficacia, sbloccando nuove possibilità per progetti e applicazioni. Puoi anche usare Llama 2 con strumenti come LangChain, LlamaIndex e Semantic Kernel quando crei applicazioni RAG.
Prestazioni di Llama 2
Le prestazioni complessive possono essere valutate osservando alcuni popolari benchmark aggregati. Ecco una tabella dei risultati sulle prestazioni rispetto ai modelli basati su open-source, come indicato nel paper di LLama 2:
| Modello | Dimensione | Codice | Ragionamento di buon senso | Conoscenza del mondo | Comprensione della lettura | Matematica | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Puoi vedere che Llama 2 supera Llama 1 in diverse categorie come MMLU e BBH, e ottiene risultati buoni anche rispetto al modello Falcon.
Llama 2 vs GPT 4
Il paper su Llama 2 include anche alcuni confronti tra Llama 2 e GPT 4 e alcuni altri, come mostrato di seguito:
| Benchmark (shot) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot): Al modello vengono forniti 5 passaggi o esempi per generare una risposta.
- TriviaQA (1-shot): Un dataset in cui al modello viene fornito un singolo contesto o una singola domanda prima di generare una risposta.
- Natural Questions (1-shot): Un altro dataset in cui al modello viene data una domanda come input.
- GSM8K (8-shot): Un dataset in cui al modello vengono forniti 8 passaggi o esempi per rispondere a domande o svolgere compiti.
- HumanEval (0-shot): Un dataset o contesto di valutazione in cui il modello viene valutato su compiti o domande su cui non è stato esplicitamente addestrato, da cui "0-shot."
Zilliz funziona con Llama 2?
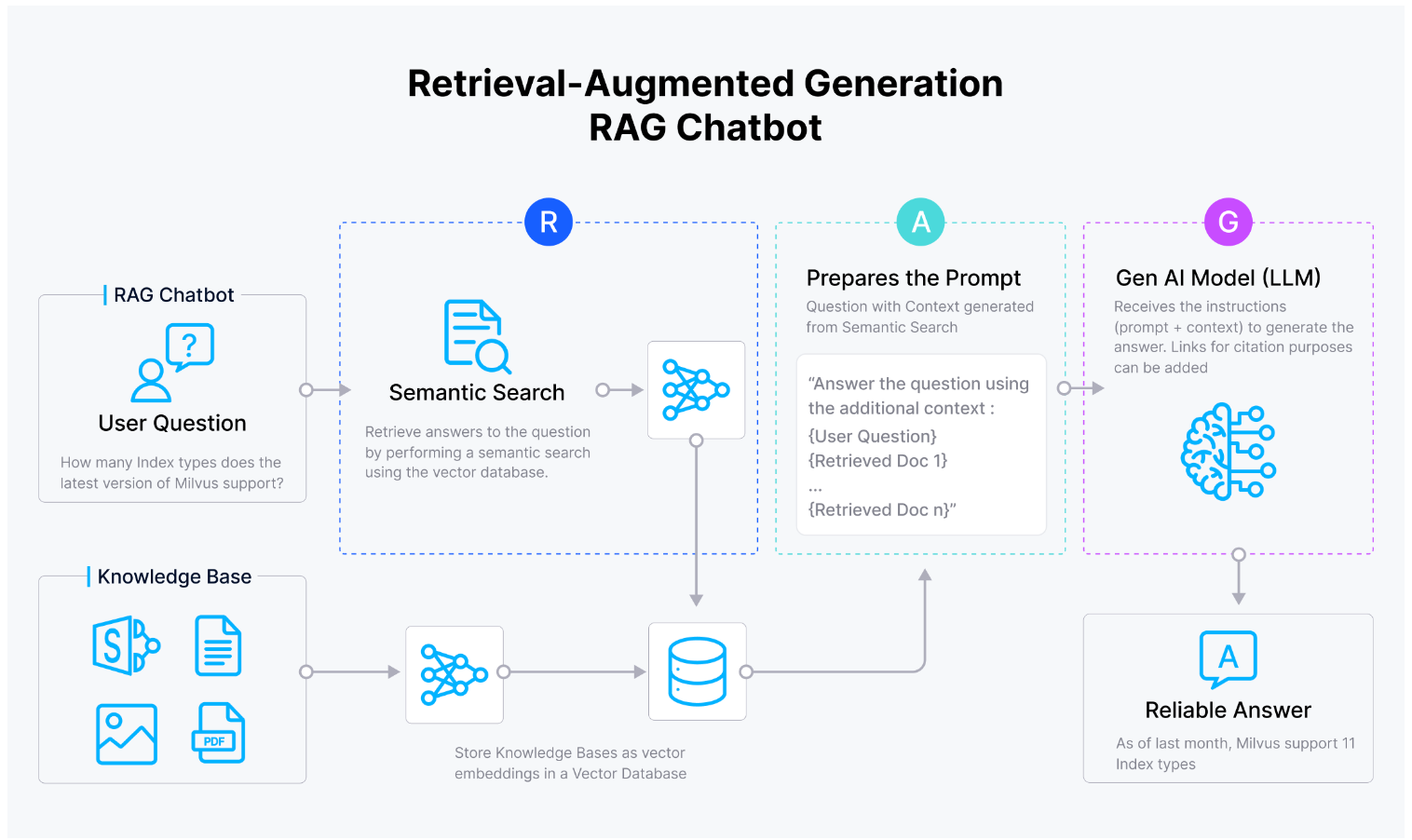
Il caso d'uso più comune per Zilliz Cloud in combinazione con Llama 2 è lo sviluppo di applicazioni di Retrieval Augmented Generation (RAG). Le applicazioni RAG sfruttano le capacità dei large language models (LLMs) come Llama 2, che sono addestrati su vasti dataset ma operano intrinsecamente entro i limiti di dati finiti. Da solo, Llama 2 ha la tendenza ad "allucinare" le risposte, generando risposte anche quando potrebbe non esserci un contesto sufficiente o informazioni accurate. RAG è un modo per affrontare questa allucinazione.
La combinazione di Zilliz Cloud e Llama 2 consente agli utenti di integrare perfettamente capacità avanzate di comprensione e generazione del linguaggio con sistemi di recupero basati su vettori efficienti e scalabili forniti da Zilliz Cloud. Sfruttando i punti di forza di entrambe le piattaforme, gli sviluppatori possono creare applicazioni sofisticate che eccellono in attività che richiedono elaborazione completa del linguaggio, recupero delle informazioni e funzionalità di generazione.
Risorse chiave
- Che cos'è Llama 2?
- Architettura di Llama 2
- Che cos'è un embedding nel machine learning?
- Come usare Llama 2?
- Prestazioni di Llama 2
- Llama 2 vs GPT 4
- Zilliz funziona con Llama 2?
- Risorse chiave
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente