




Dall'estrazione agli approfondimenti: Capire l'ETL

Dall'estrazione agli approfondimenti: Capire l'ETL
 ETL Pipeline.png
ETL Pipeline.png
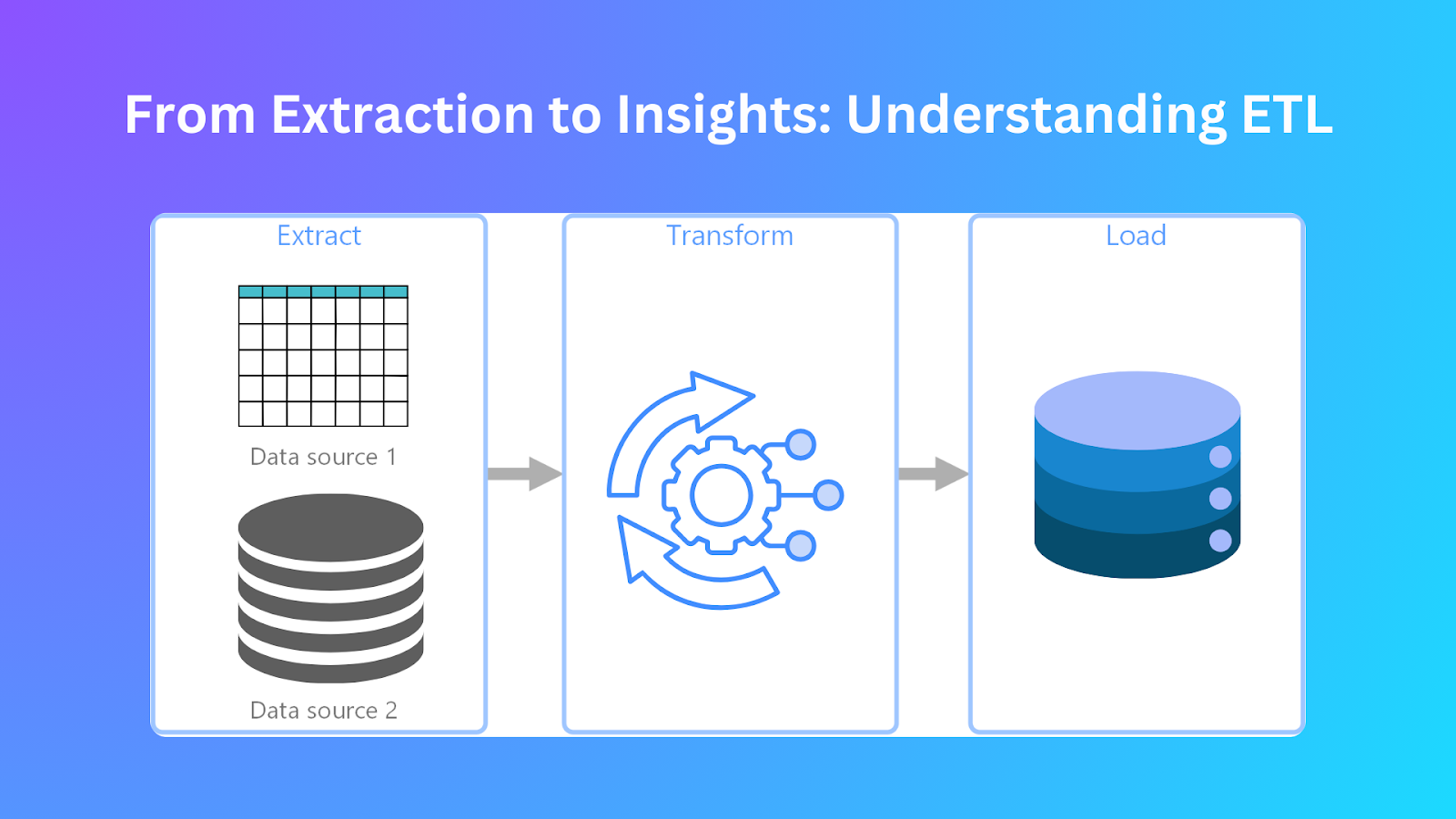
Come fanno le aziende a convertire enormi insiemi di dati in potenti approfondimenti? Quali sono i passi che le organizzazioni compiono per integrare e raffinare i dati prima dell'analisi? La risposta si trova in Estrazione, trasformazione e caricamento (ETL**).
L'ETL è la chiave della moderna gestione dei dati. Consente alle organizzazioni di raccogliere, elaborare e caricare i dati per l'analisi. L'ETL estrae le informazioni da diverse risorse, le modifica per eliminare gli errori e le inserisce in un database centralizzato. Questo processo consente di ottenere informazioni raffinate, accurate e organizzate, favorendo il processo decisionale aziendale.
I dati senza ETL sono difficili da analizzare a causa della loro natura dispersa e distorta. L'inefficienza dei dati può portare a errori, con ripercussioni su vari aspetti come le relazioni con i clienti o le prestazioni operative. L'ETL risolve la scarsa qualità dei dati automatizzando i flussi di lavoro e mantenendo l'integrità dei dati. Questo aiuta l'azienda a semplificare il reporting, a potenziare le analisi e a migliorare il processo decisionale.
Con le aziende che fanno tutto in funzione dei dati, la comprensione dell'ETL diventa fondamentale. Che si tratti di [database] strutturati (https://docs.zilliz.com/docs/database), di sistemi cloud o di analisi in tempo reale, l'ETL garantisce l'integrazione e l'elaborazione di dati di qualità.
In questo articolo si parlerà di come funziona l'ETL, del suo impatto e di come un'organizzazione può utilizzarlo appieno. Scopriremo inoltre quali sono i principali strumenti da utilizzare per rendere più fluido il processo di ETL.
Che cos'è l'ETL (Extract, Transform, and Load)?
L'ETL è il processo principale di gestione e integrazione dei dati. Inizia con l'estrazione dei dati da fonti diverse prima di trasformarli in un formato adatto al caricamento in destinazioni di destinazione come data warehouse o data lake. Le organizzazioni ottengono il consolidamento dei dati unendo fonti di dati separate in un unico repository per supportare l'analisi.
L'ETL è la spina dorsale per mantenere la coerenza, la qualità e l'accessibilità dei dati, indipendentemente dalle differenze di sistema o di piattaforma. Questo approccio serve a diversi settori, tra cui quello finanziario, sanitario e dell'e-commerce.
Le aziende utilizzano questo metodo per organizzare i dati e rimuovere le incoerenze, migliorando così le capacità decisionali. I moderni strumenti ETL sono in grado di elaborare in modo efficiente sia i dati strutturati che quelli non strutturati.
Un sistema di pipeline ETL ben progettato consente alle organizzazioni di analizzare le tendenze e scoprire le intuizioni. Il flusso di lavoro automatizzato migliora l'efficienza operativa grazie all'automazione dell'elaborazione dei dati. Le aziende utilizzano l'ETL per creare una visione unificata che supporta attività di reporting e pianificazione strategica accurate.
Come funziona l'ETL
L'elaborazione dei dati attraverso l'ETL segue un processo in tre fasi che garantisce precisione ed efficienza in ogni fase. Queste fasi sono:
Estrazione
La pipeline ETL inizia con l'estrazione dei dati come fase iniziale. Questa fase raccoglie i dati da diverse fonti prima di unirli per l'elaborazione. Attraverso il processo di estrazione, le organizzazioni acquisiscono set di dati completi dai loro diversi sistemi, tra cui database, file piatti, cloud storage e API. Ecco alcuni dei passaggi della fase di estrazione dei dati:
Identificazione della fonte dei dati: La prima fase dell'estrazione determina dove risiedono i dati. I dati possono provenire da database relazionali MySQL e PostgreSQL, database NoSQL MongoDB e Cassandra, API di terze parti, file CSV o JSON e piattaforme di dati in streaming. La costruzione di una pipeline ETL efficace richiede la corretta identificazione delle fonti di dati adeguate.
Recupero dei dati: I metodi di recupero dei dati dipendono dai requisiti aziendali e dalle funzionalità del sistema disponibili. I dati possono essere recuperati in due modi: in modo completo o incrementale. L'estrazione completa raccoglie tutti i dati dalle fonti, mentre l'estrazione incrementale raccoglie solo le modifiche rispetto all'ultima estrazione. L'estrazione incrementale è preferibile perché riduce la durata dell'elaborazione e diminuisce la pressione sui sistemi di origine.
I dati estratti possono contenere campi vuoti, tipi di dati incoerenti e formati strutturali. Le organizzazioni dovrebbero effettuare controlli di pre-elaborazione per identificare e gestire le incongruenze prima di iniziare la fase di trasformazione.
Trasformazione
Dopo l'estrazione, i dati devono essere trasformati per garantire la compatibilità con lo schema del sistema di destinazione e applicare le regole aziendali. Questo processo di trasformazione porta a una migliore qualità dei dati, a dati coerenti e a una maggiore usabilità. Ecco alcuni modi per trasformare i dati:
Pulizia dei dati: È una delle procedure di trasformazione fondamentali. Richiede la rimozione dei duplicati, l'imputazione dei valori per i dati mancanti e la standardizzazione delle convenzioni di denominazione. Questo aiuta a produrre report precisi e privi di errori.
Integrazione dei dati: I dati provengono da più fonti che contengono strutture di dati separate. L'integrazione dei dati crea un'unica visione coerente dei dati da diversi set di dati separati. Il processo prevede la mappatura dei diversi nomi delle colonne, la riconciliazione delle differenze di fuso orario e la garanzia dell'integrità referenziale.
Aggregazione dei dati: Aiuta a riassumere i dati per un'analisi efficiente. Le aziende hanno spesso bisogno di report contenenti i totali delle vendite regionali, le medie di spesa trimestrali dei clienti e i modelli di fatturato mensili. Il processo di aggregazione consente di velocizzare le interrogazioni e di semplificare l'interpretazione dei dati.
Conversione dei dati: È necessario convertire diversi tipi di dati per renderli compatibili con il sistema richiesto. La standardizzazione dei formati dei dati è fondamentale, mentre la normalizzazione dei campi di testo e la conversione delle unità di misura per i dati numerici completano il processo. Il processo di trasformazione dei dati assicura che tutti i dati caricati corrispondano esattamente alle esigenze analitiche.
Applicazione di regole aziendali: Le organizzazioni creano tipicamente regole di business per i processi di trasformazione dei dati. Un istituto finanziario utilizza soglie di transazione per sviluppare categorie, mentre le aziende di e-commerce dividono i clienti in segmenti in base alla loro attività di acquisto. Le regole definite generano valore organizzando i dati non elaborati in categorie funzionali.
Caricamento
I dati trasformati devono essere caricati in un sistema di destinazione, che può essere un data warehouse, un data lake o un database analitico. Il processo di caricamento stabilisce il livello a cui i dati possono essere interrogati e analizzati in modo efficiente.
Caricamento nel sistema di destinazione: Durante le procedure di caricamento completo, il sistema di destinazione riceve tutti i dati in un'unica operazione. Questo metodo viene utilizzato principalmente durante la prima migrazione dei dati o per gestire insiemi di dati più piccoli. Un altro metodo consiste nel caricare solo i nuovi record e gli aggiornamenti dal sistema di origine. Questo metodo riduce la durata dell'elaborazione e rende le operazioni più efficienti.
Metodi di indicizzazione dei dati e tecniche di partizionamento accelerano le prestazioni del sistema nella ricerca dei record. Le tecniche di partizionamento dividono le raccolte di dati in segmenti più piccoli, migliorando le prestazioni delle query e rendendo i dati più gestibili.
Le organizzazioni stabiliscono strategie di backup per proteggere i dati dalla perdita durante i guasti del sistema. Questo metodo mantiene la protezione dei dati e ne garantisce la disponibilità in ogni momento.
Confronto: ETL vs. ELT
L'integrazione dei dati si basa su ETL (Extract, Transform, Load) e ELT (Extract, Load, Transform) come metodi principali per trasferire i dati da varie fonti in data warehouse o laghi di dati. I due metodi condividono l'obiettivo di un trasferimento efficiente dei dati, ma operano in modo diverso quando elaborano e inseriscono i dati nei sistemi contemporanei. Ecco il confronto tra i due:
| Aspect | ETL | ELT |
| Sequenza di processo | Estrazione -> Trasformazione -> Carico | Estrazione -> Carico -> Trasformazione |
| Trasformazione | La trasformazione avviene prima del caricamento nel sistema di destinazione | La trasformazione avviene dopo il caricamento nel sistema di destinazione |
| Memorizzazione dei dati | I dati vengono memorizzati in un'area di staging temporanea durante la trasformazione | I dati vengono memorizzati nel sistema di destinazione e la trasformazione avviene in loco |
| Elaborazione dei dati | I dati vengono elaborati in lotti e l'elaborazione avviene tipicamente in modo lineare | I dati vengono elaborati in tempo reale o quasi, e l'elaborazione può essere eseguita in parallelo |
| Scalabilità** | Può essere meno scalabile a causa della necessità di un'area di staging e dell'elaborazione in batch | Più scalabile grazie alla capacità di elaborare i dati in tempo reale e in parallelo |
| Può essere più costoso a causa della necessità di un'area di staging e di un'elaborazione batch. Può essere meno costoso grazie alla capacità di elaborare i dati in tempo reale e in parallelo. | ||
| Meno flessibile a causa della rigidità dell'ordine di processo. Più flessibile grazie alla possibilità di eseguire trasformazioni in qualsiasi momento. | ||
| Casi di utilizzo | Adatto per l'elaborazione batch, il data warehousing e la business intelligence | Adatto per l'analisi in tempo reale, l'integrazione dei dati e l'elaborazione dei big data |
RTL vs ELT | Fonte
Vantaggi e sfide
Sebbene l'ETL supporti l'estrazione, la trasformazione e il caricamento dei dati, presenta anche vantaggi e sfide. Vediamoli:
Vantaggi
Tracciamento del percorso dei dati: i processi ETL tracciano il movimento dei dati dalle fonti alle destinazioni. Le loro funzioni principali comprendono l'identificazione degli errori, il mantenimento dell'integrità e la garanzia della conformità all'accuratezza.
Preservazione dei dati storici: Il processo ETL cattura le istantanee dei dati lungo il loro percorso, consentendo alle organizzazioni di conservare le informazioni storiche necessarie per l'analisi delle tendenze e la reportistica. Le aziende possono tenere traccia dei dati mentre effettuano confronti per aiutare il loro processo decisionale.
Trasformazione complessa dei dati: Gli strumenti ETL eccellono nell'esecuzione di trasformazioni complesse dei dati, compresi i processi di aggregazione, le conversioni dei tipi di dati e l'implementazione della logica aziendale. Le funzionalità del sistema facilitano le operazioni di pulizia dei dati, producendo informazioni strutturate e standardizzate prima che il sistema di destinazione le riceva.
Il processo di arricchimento dei dati dell'ETL consente alle aziende di combinare le informazioni provenienti da vari database esterni, migliorando così la qualità e la completezza del set di dati. L'incorporazione di informazioni contestuali attraverso l'arricchimento aumenta la comprensione analitica aggiungendo valore ai dati ai fini del processo decisionale.
Efficienza dell'elaborazione in batch: I flussi di lavoro ETL raggiungono la massima efficienza grazie all'elaborazione in batch, che gestisce grandi volumi di dati durante i cicli programmati non di punta. Il processo riduce al minimo l'impatto sulle prestazioni del sistema durante il normale orario di lavoro, gestendo in modo efficiente grandi insiemi di dati.
Sfide
Limiti dell'integrazione in tempo reale**: I processi ETL tradizionali integrano i dati in batch programmati, limitando i requisiti di dati in tempo reale. Le organizzazioni che richiedono capacità analitiche e decisionali immediate incontrano difficoltà a causa dei ritardi associati ai processi ETL tradizionali.
I requisiti computazionali dei carichi di lavoro ETL diventano particolarmente impegnativi quando si verificano i processi di trasformazione e caricamento dei dati. L'elevato utilizzo delle risorse di CPU e di memoria riduce la velocità delle operazioni di sistema, incidendo così sui livelli di prestazione.
Complessità nella gestione degli errori: La gestione degli errori diventa difficile perché le pipeline ETL devono gestire numerose fonti di dati e regole di trasformazione complesse. Sono necessari robusti strumenti di monitoraggio e sistemi di debug per identificare le incongruenze, gestire i dati mancanti e gestire la qualità.
Costrizioni di scalabilità: Il crescente volume di dati pone problemi di scalabilità che richiedono ai processi ETL di garantire nuovi investimenti in infrastrutture o di adottare architetture riprogettate. Quando l'ottimizzazione dei dati è insufficiente, l'aumento dei volumi di dati può causare ritardi di elaborazione e limitazioni delle prestazioni del sistema.
Gestione delle dipendenze: Le varie fasi dei flussi di lavoro ETL dipendono l'una dall'altra, per cui il fallimento di una fase può creare un effetto a cascata sull'intera pipeline. Per evitare interruzioni operative, una gestione efficace delle dipendenze richiede una pianificazione accurata, oltre a sistemi di monitoraggio e piani di recupero degli errori.
Casi d'uso e strumenti
Il processo di ETL è un requisito operativo fondamentale per diversi settori industriali, in quanto contribuisce all'integrazione e all'analisi efficiente dei dati. Ecco alcuni casi d'uso e strumenti:
Casi d'uso
Il processo ETL consente ai negozi al dettaglio di raccogliere i dati del sistema di cassa e di normalizzarli rispetto ai record dell'inventario prima di archiviarli in un database unificato. Il sistema consente di tracciare i dati di vendita, di gestire le scorte e di comprendere meglio i clienti.
Le istituzioni finanziarie applicano metodi ETL per unire i dati delle transazioni provenienti da più sistemi prima di trasformarli e caricarli in sistemi di archiviazione dati integrati. Il processo di consolidamento consente alle organizzazioni di rilevare efficacemente le frodi, gestire i rischi e produrre report conformi.
Sanità: Le organizzazioni sanitarie applicano processi ETL per unire i dati provenienti da cartelle cliniche elettroniche (EMR), database clinici e sistemi amministrativi. L'integrazione del sistema consente una migliore gestione dell'assistenza ai pazienti, con miglioramenti dell'efficienza operativa e il supporto di processi decisionali informati.
Strumenti ETL più diffusi
AWS Glue: Un servizio di integrazione dei dati senza server che facilita la connessione a oltre 70 fonti di dati diverse. Offre un catalogo di dati centralizzato, un ambiente serverless e script personalizzabili.
Apache NiFi: È un sistema open-source che consente l'elaborazione automatizzata del flusso di dati grazie alla sua funzionalità ETL. Il sistema offre un accesso facile da usare basato sul web, capacità di elaborazione istantanea e ampie opzioni di personalizzazione a vantaggio di complesse operazioni di routing dei dati.
Matillion: Uno strumento ETL cloud-native che funziona senza problemi sulle principali piattaforme di dati basate su cloud. Offre funzionalità come l'intelligenza artificiale generativa, connettori precostituiti e flussi di lavoro collaborativi.
Gli strumenti e le loro applicazioni dimostrano quanto siano essenziali i metodi ETL per convertire i dati grezzi in approfondimenti pratici in diversi ambiti aziendali.
FAQ
- Qual è lo scopo principale dell'ETL?
L'ETL ha la funzione di unire i dati provenienti da varie fonti in un unico repository unificato. Il flusso di lavoro di elaborazione dei dati comprende tre fasi: i dati vengono estratti dalle fonti e poi trasformati per le esigenze operative prima di essere caricati in un sistema analitico.
- In cosa si differenzia l'ETL dall'ELT?
Il processo ETL inizia con l'estrazione dei dati dai sistemi di origine prima di trasformarli in un'area di staging per caricarli nel sistema di destinazione. I dati vengono quindi caricati nel sistema di destinazione e le trasformazioni vengono eseguite direttamente su tale sistema.
- Quali sono le sfide più comuni nell'implementazione dei processi ETL?
L'implementazione delle procedure ETL incontra molteplici ostacoli perché richiede una gestione efficace dei dati provenienti da diverse origini, il controllo della qualità e la gestione efficiente di quantità di dati considerevoli. Le sfide creano problemi di prestazioni che richiedono un'accurata pianificazione delle risorse per essere risolti in modo efficace.
- È possibile automatizzare i processi ETL?
Gli strumenti ETL offrono funzionalità di automazione attraverso funzioni di pianificazione e gestione dei flussi di lavoro per l'esecuzione dei processi di trasferimento dei dati. L'automazione consente operazioni efficienti grazie all'elaborazione automatica dei dati che riduce il coinvolgimento umano, mantenendo una qualità dei dati costante per mantenere i set di dati aggiornati per l'analisi.
- Perché la trasformazione dei dati è importante nell'ETL?
La trasformazione dei dati nell'ambito delle operazioni di ETL è fondamentale per ripulire, standardizzare e formattare i dati ottenuti da fonti diverse. Il processo di trasformazione dei dati garantisce che il sistema di destinazione riceva dati accurati e coerenti per l'analisi e il reporting, a supporto di decisioni aziendali affidabili.
Risorse correlate
- Che cos'è l'ETL (Extract, Transform, and Load)?
- Come funziona l'ETL
- Confronto: ETL vs. ELT
- Vantaggi e sfide
- Casi d'uso e strumenti
- FAQ
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente