




Comprendere l'algoritmo CURE: un'esplorazione completa del clustering con rappresentanti
 Rappresentazione visiva del clustering
Rappresentazione visiva del clustering
Figura 1: Rappresentazione visiva del clustering
Come possono le aziende orientarsi in un mercato in continua evoluzione e raggruppare efficacemente i clienti con modelli simili? I metodi tradizionali di clustering spesso risultano insufficienti quando si ha a che fare con forme di dati irregolari e outlier. La complessità dei dataset moderni richiede soluzioni più intelligenti e adattabili.
Ecco l'algoritmo CURE (Clustering Using Representatives), un metodo efficace che affronta i limiti degli approcci di clustering standard. CURE utilizza una selezione di punti rappresentativi per differenziarsi dai metodi di clustering classici, migliorando così la sua intelligenza nel distinguere distribuzioni di dati complesse. Questi punti rappresentativi si avvicinano alla media del cluster, rendendo l'algoritmo più avanzato consentendogli di gestire cluster di forma arbitraria.
CURE può diventare computazionalmente intensivo quando applicato a dataset di grandi dimensioni. Nonostante ciò, il suo approccio alla gestione di anomalie e cluster complessi rimane altamente efficace. Discutiamo le operazioni dell'algoritmo CURE esplorandone l'approccio principale, i vantaggi e le applicazioni pratiche. Esamineremo anche le sfide che potresti incontrare durante l'implementazione di CURE.
Che cos'è l'algoritmo CURE?
L'algoritmo CURE utilizza un approccio di clustering gerarchico, che identifica forme di cluster intricate e gestisce efficacemente gli outlier. ****A differenza degli algoritmi basati su centroidi come k-means, CURE rappresenta i cluster utilizzando più punti rappresentativi. Questi punti si spostano verso le medie dei cluster con un fattore di contrazione fisso per creare rappresentazioni dei cluster resilienti.
CURE dimostra una maggiore flessibilità rispetto a k-means perché il suo design gli consente di lavorare con vari tipi di dataset irregolari. La sua capacità di superare i vincoli degli algoritmi tradizionali relativi a cluster convessi o equidistanti porta al rilevamento preciso dei confini e delle forme dei cluster.
Come funziona
Gli algoritmi CURE prevedono più passaggi per produrre l'output finale. Scopriamo come selezionano i dati per creare un cluster privo di outlier.
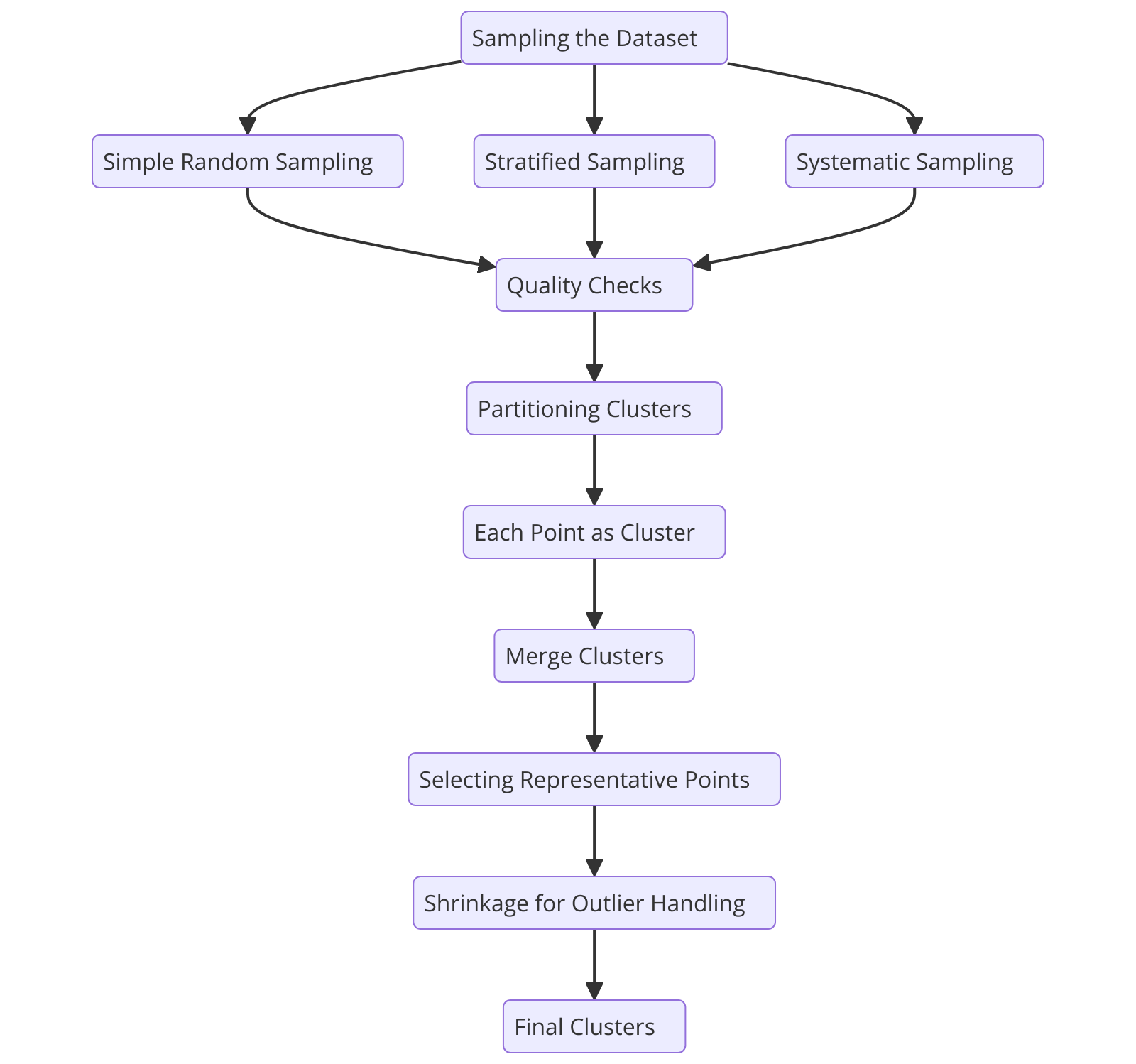 Flusso del processo dell'algoritmo di clustering CURE
Flusso del processo dell'algoritmo di clustering CURE
Figura 2: Flusso del processo dell'algoritmo di clustering CURE
Flusso del processo dell'algoritmo di clustering CURE
Per comprendere come funziona l'algoritmo CURE, analizziamo il suo processo passo dopo passo, iniziando dal campionamento del dataset.
Campionamento del dataset
CURE inizia selezionando un campione casuale rappresentativo dal dataset. Il processo di campionamento riduce il numero di punti dati, accelerando la velocità di calcolo mantenendo al contempo l'integrità dei cluster.
Il campionamento casuale semplice offre un'implementazione rapida ma non riesce a catturare casi limite cruciali. Ciò produce una rappresentazione inadeguata dei gruppi minoritari nei dataset sbilanciati. Il campionamento stratificato diventa necessario quando è necessario mantenere la distribuzione proporzionale delle diverse classi nei dati.
Questo metodo garantisce che tutti i piccoli sottoinsiemi significativi di dati rimangano visibili per l'analisi. Un altro metodo è il campionamento sistematico, che seleziona i punti dati attraverso un sistema a intervalli regolari. Il campionamento sistematico eccelle nelle serie temporali e nei dati ordinati poiché preserva la natura temporale e il modello di ordinamento sequenziale nei dataset.
I controlli di qualità verificano la coerenza del campione con la distribuzione del dataset originale dopo la raccolta. Confrontare i valori medi, i livelli di varianza e le caratteristiche di distribuzione aiuta a valutare le somiglianze tra il campione ottenuto e il dataset originale completo. Le rigorose strategie di campionamento implementate da CURE consentono al clustering successivo di rappresentare accuratamente la complessità e la diversità dell'intero dataset.
Partizionamento dei cluster
Dopo aver campionato il dataset, CURE applica un metodo gerarchico che divide i dati in sottoinsiemi gestibili. In particolare, utilizza una strategia di fusione bottom-up per il clustering. L'algoritmo misura le somiglianze tra punti dati tramite metriche di distanza che utilizzano la distanza euclidea o la distanza di Manhattan. Le metriche di calcolo della distanza sono essenziali per determinare la prossimità dei punti, stabilendo al contempo una base solida per un'efficace fusione dei cluster.
All'inizio del processo, ogni punto dati funziona come il proprio cluster per rappresentare la natura a grana fine dei dati. L'algoritmo esegue successive fusioni di cluster utilizzando standard di prossimità per raggruppare punti simili. L'algoritmo continua attraverso operazioni di fusione dei cluster fino a quando viene raggiunto un numero definito di cluster o si attiva una condizione di terminazione alternativa.
Il processo di selezione dei gruppi in CURE crea cluster che si allineano con le categorie naturali presenti nei dati. Utilizzando il partizionamento gerarchico, CURE supera i limiti degli algoritmi di clustering tradizionali che richiedono che i cluster abbiano forme convesse.
Selezione dei punti rappresentativi
CURE seleziona più punti rappresentativi per rappresentare ciascun cluster anziché dipendere da un singolo centroide. Questi punti, scelti con cura dal cluster, ne catturano l'estensione spaziale e la struttura. CURE ottiene un migliore riconoscimento dei confini dei cluster e una migliore comprensione della struttura interna utilizzando più punti per rappresentare ciascun cluster.
Dopo aver selezionato i punti rappresentativi, l'algoritmo li sposta verso la media del cluster con una quantità di contrazione specificata. La procedura di contrazione rende l'algoritmo meno reattivo agli outlier spostando i punti distanti verso i punti centrali del cluster.
Il successo dell'algoritmo dipende fortemente da quanti punti rappresentativi vengono utilizzati durante l'esecuzione. La selezione appropriata dei punti rappresentativi è cruciale. Usare pochi punti rappresentativi potrebbe non riuscire a catturare la complessità del cluster, mentre usarne troppi può aumentare i costi computazionali.
Fusione dei cluster
Dopo aver identificato i punti rappresentativi, l'algoritmo fonde i cluster utilizzando un approccio iterativo sistematico. La procedura dipende dalla misurazione della distanza tra punti rappresentativi di cluster diversi. Metriche predefinite, come la distanza euclidea, vengono utilizzate per misurare le distanze, eliminando così conflitti nell'individuazione dei cluster più vicini.
L'algoritmo identifica quali coppie di cluster hanno la distanza minima dalla separazione dei punti rappresentativi durante ogni fase di valutazione. L'algoritmo prende decisioni accurate di fusione dei cluster preservando al contempo le relazioni spaziali e i modelli naturali di allineamento dei dati all'interno dei cluster.
Il processo itera fino a quando vengono raggiunti alcuni cluster predeterminati o viene soddisfatto un altro criterio di terminazione. Il criterio di terminazione dipende da fattori come la distanza minima tra cluster o la massima similarità consentita all'interno dei cluster. Ciò assicura che i cluster prodotti corrispondano ai raggruppamenti naturali nei dati e siano abbastanza flessibili da catturare forme irregolari e complesse.
Gestione degli outlier
Quando esistono outlier, i risultati diventano distorti perché causano forme di cluster errate e interpretano in modo scorretto la struttura dei dati. L'algoritmo CURE risolve queste limitazioni utilizzando più punti rappresentativi, che identificano accuratamente la forma e la distribuzione effettive dei cluster.
Il meccanismo di contrazione rappresenta un altro avanzamento fondamentale in CURE, rendendo il sistema più resiliente e aumentandone la sofisticazione. Questo aggiustamento deliberato diminuisce la sensibilità dell'algoritmo ai valori estremi, spostando i punti rappresentativi verso le posizioni centrali del cluster.
Il fattore di contrazione è un parametro di regolazione che consente agli utenti di personalizzarne il valore in base alle caratteristiche del dataset. Ciò consente una mitigazione flessibile degli outlier preservando al contempo i confini naturali dei cluster.
Confronto con altri metodi di clustering
L’approccio innovativo dell’algoritmo CURE lo distingue da altre tecniche di clustering popolari. Ecco un confronto più approfondito:
| Aspetto | CURE | k-means | DBSCAN |
| Rappresentazione | Più punti rappresentativi | Singolo centroide | Basato sulla densità |
| Gestione degli outlier | Eccellente | Scarsa | Buona |
| Flessibilità della forma | Forme arbitrarie | Solo forme convesse | Forme arbitrarie |
| Scalabilità | Alta (con campionamento) | Alta | Moderata |
| Complessità | Maggiore | Minore | Moderata |
Vantaggi e sfide
Quando applicato a scenari del mondo reale, CURE offre un insieme di vantaggi e sfide. Vediamo come CURE può offrire valore presentando al contempo alcuni ostacoli nelle applicazioni pratiche.
Vantaggi
Scalabilità: CURE raggiunge la scalabilità tramite la sua strategia di campionamento dei dati, che riduce i carichi di lavoro computazionali senza compromettere l’accuratezza della precisione dei cluster.
Robustezza: CURE aumenta la robustezza utilizzando più punti rappresentativi per catturare la forma e la struttura di un cluster. Pertanto, il clustering produrrà risultati affidabili e stabili anche quando i dati sono rumorosi e incoerenti.
Versatilità: CURE cattura cluster di qualsiasi forma e gestisce irregolarità o strutture non convesse. Ciò è particolarmente utile in dataset diversi, dove tecniche tradizionali come k-means non riescono a rappresentarli accuratamente.
Sfide
Sensibilità ai parametri: L’algoritmo richiede una regolazione precisa dei parametri per il fattore di contrazione e il numero di punti rappresentativi. Trovare il giusto equilibrio è fondamentale per prestazioni ottimali, richiedendo sia sperimentazione sia competenza di dominio.
Bias di campionamento: Tecniche di campionamento insufficienti producono una formazione dei cluster inaccurata e risultati scadenti. Mantenere campioni rappresentativi privi di bias è essenziale per garantire che le strutture del dataset rimangano intatte.
Esigenze computazionali: Le sfide di scalabilità di CURE aumentano con dataset grandi, ad alta dimensionalità o non strutturati a causa della necessità di molteplici valutazioni delle distanze. Tecniche come PCA e calcolo parallelo possono ridurre la dimensionalità, abbassando i costi computazionali e preservando al contempo le relazioni chiave.
Casi d’uso
Per vedere l’impatto pratico dell’algoritmo CURE, esaminiamo come può risolvere sfide di clustering del mondo reale in vari domini.
Rilevamento delle anomalie
CURE identifica efficacemente le anomalie raggruppando le transazioni tipiche e isolando quelle irregolari che possono indicare frodi. Ciò consente agli istituti finanziari di rilevare rapidamente attività sospette e migliorare le proprie misure di sicurezza.
Segmentazione del mercato
Nel marketing, CURE può segmentare i clienti in base ad attributi come comportamento d’acquisto, dati demografici e preferenze. Ciò consente campagne di marketing mirate, migliorando la fidelizzazione dei clienti e prevedendo le tendenze future. Ad esempio, i clienti ad alto valore possono essere raggruppati in cluster per offerte esclusive al fine di aumentare la fedeltà.
Analisi dei dati geospaziali
Gli urbanisti possono implementare CURE per categorizzare regioni con climi, densità di popolazione o sviluppi infrastrutturali simili. Gli scienziati ambientali possono usarlo per raggruppare aree in base alla loro biodiversità e alla disponibilità di risorse durante lo studio degli ecosistemi.
Clustering di documenti
CURE dimostra un’eccellente efficacia nel text mining raggruppando ampi cataloghi di documenti in base ai loro temi e argomenti standard. I motori di ricerca utilizzano questo metodo per creare categorie di risultati precise che consentono agli utenti di trovare rapidamente contenuti pertinenti.
CURE consente ai sistemi di raccomandazione di identificare articoli e documenti di ricerca con argomenti simili. Ciò si traduce in raccomandazioni personalizzate e significative per gli utenti. CURE può raggruppare efficacemente strutture testuali diverse per mantenere risultati di raggruppamento precisi indipendentemente dalla complessità e dalle dimensioni dei dataset ad alta dimensionalità. L’algoritmo si adatta bene ai dataset testuali multilingue e alle voci di dati eterogenee, posizionandosi come una soluzione essenziale per le piattaforme contemporanee di recupero delle informazioni.
Conclusione
L’algoritmo di clustering CURE rappresenta un importante passo avanti nei metodi di clustering. Offre una soluzione efficace e scalabile per i problemi di dati contemporanei. L’algoritmo utilizza punti rappresentativi insieme a principi gerarchici per superare le limitazioni del clustering tradizionale, garantendo al contempo risultati flessibili e accurati. Sebbene l’algoritmo affronti sfide legate all’ottimizzazione dei parametri e ai requisiti computazionali, la sua capacità di gestire dati rumorosi e pattern complessi è essenziale per molteplici settori aziendali.
La crescente complessità dei dataset continuerà ad aumentare in futuro la necessità di algoritmi di clustering flessibili come CURE. I data scientist e i professionisti del machine learning che comprendono i principi di CURE saranno in grado di massimizzare il loro potenziale nel generare insight significativi da dataset complessi.
FAQ
- Cosa rende CURE unico rispetto a k-means?
CURE si distingue da k-means utilizzando più punti rappresentativi invece di un singolo centroide del cluster. Il metodo consente il rilevamento di forme di cluster irregolari e pattern non lineari in dataset complessi senza richiedere ipotesi di cluster convessi.
- In che modo CURE gestisce dataset di grandi dimensioni?
CURE gestisce dataset di grandi dimensioni tramite tecniche di campionamento casuale che minimizzano i requisiti di elaborazione computazionale. La strategia di campionamento consente all’algoritmo di elaborare sottoinsiemi di dati ridotti, preservando l’integrità delle relazioni tra cluster.
- Qual è il ruolo dello shrink factor in CURE?
Lo shrink factor di CURE controlla la distanza alla quale i punti rappresentativi si spostano verso la posizione media del loro cluster. Questo fattore consente agli utenti di ottenere risultati ottimali tra accuratezza e robustezza. Il successo delle implementazioni di CURE dipende fortemente dall’individuazione dello shrink factor corretto per ciascun dataset.
- CURE può funzionare con dati ad alta dimensionalità?
L’utilizzo degli algoritmi CURE su dati ad alta dimensionalità richiede una pre-elaborazione preventiva tramite tecniche come PCA. L’elaborazione di dati ad alta dimensionalità richiede una riduzione efficiente delle dimensioni per individuare pattern essenziali anche mantenendo la semplicità dei dati.
- Quali sono le applicazioni tipiche di CURE?
Le applicazioni tipiche di CURE includono il rilevamento di anomalie, la segmentazione del mercato, l’analisi geospaziale e l’analisi del clustering di documenti. Può identificare pattern finanziari insoliti per il rilevamento delle frodi, raggruppare i clienti in base al comportamento e analizzare regioni in base alle caratteristiche.
Risorse correlate
https://zilliz.com/ai-faq/how-are-embeddings-used-for-clustering
https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search
https://zilliz.com/ai-faq/how-does-swarm-intelligence-improve-data-clustering
https://zilliz.com/ai-faq/what-is-graph-clustering-in-knowledge-graphs
https://zilliz.com/ai-faq/what-are-the-most-common-algorithms-for-anomaly-detection
- Comprendere l'algoritmo CURE: un'esplorazione completa del clustering con rappresentanti
- Che cos'è l'algoritmo CURE?
- Come funziona
- Flusso del processo dell'algoritmo di clustering CURE
- Confronto con altri metodi di clustering
- Vantaggi e sfide
- Casi d’uso
- Conclusione
- FAQ
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente