




AutoRegressive Integrated Moving Average (ARIMA)

AutoRegressive Integrated Moving Average (ARIMA)
Ti sei mai chiesto come le aziende prevedano con precisione la domanda di prodotti per le stagioni future e ottimizzino i loro lanci? È qui che entra in gioco ARIMA. ARIMA è un modello statistico che prevede i valori futuri delle serie temporali analizzando i pattern passati.
Discutiamo l'importanza, i benefici e le sfide di ARIMA esaminando come funziona.
Che cos'è ARIMA?
AutoRegressive Integrated Moving Average (ARIMA) è un modello statistico popolare per la previsione delle serie temporali. Utilizza dati storici per comprendere i pattern del dataset e prevedere valori futuri. Il modello utilizza tre componenti per prevedere i valori futuri: Auto-regressione (AR), Differenziazione (I) e Media Mobile (MA). Ogni componente modella le previsioni del modello delineando una relazione tra i valori passati e futuri.
Ecco cosa fa ciascuna componente:
Auto-regressione (p): AR assume che il valore futuro dipenda dal valore passato. L'ordine AR si riferisce al numero di valori passati che il modello utilizza per prevedere il valore corrente. Ad esempio, se l'ordine AR è 3, il modello prevede il valore corrente in base ai tre valori passati più recenti.
Differenziazione/ Integrazione (d): Questo determina il grado di differenziazione necessario per rendere stazionaria una serie temporale. Nelle serie temporali non stazionarie, in cui proprietà statistiche come media e varianza cambiano nel tempo, applicare la differenziazione aiuta a stabilizzare la serie.
Media Mobile (q): MA cattura la relazione tra il valore corrente di una serie temporale e gli errori di previsione passati. L'ordine MA riflette la relazione tra il valore corrente della serie temporale e gli errori di previsione passati. Ad esempio, MA(2) o MA di ordine 2 calcola la media ponderata dei due errori passati per prevedere il valore corrente.
Matematicamente, il modello ARIMA è rappresentato come ARIMA (p, d, q) ed espresso come:
y′t=I+α1y′t−1+α2y′t−2+⋯+αpy′t−p+et+θ1et−1+θ2et−2+⋯+θqet−q
Dove:
Yt: Il valore corrente della serie temporale
c: Termine costante
φ₁, φ₂, ..., φp: Coefficienti autoregressivi
θ₁, θ₂, ..., θq: Coefficienti di media mobile
εt: Termine di errore del rumore
p: L'ordine dell'autoregressione
q: L'ordine della media mobile
d: L'ordine di differenziazione/ integrazione
Questo rappresenta che il valore corrente della serie temporale differenziata (y′t) è una combinazione lineare dei suoi valori passati (y′t-₁, y′t-₂, ..., y′t-p) e dei termini di errore passati (et-₁, et-₂, ..., et-q).
Come funziona ARIMA?
L'autocorrelazione e le medie mobili sono componenti essenziali dei modelli ARIMA. L'autocorrelazione aiuta a identificare le relazioni dirette tra valori passati e correnti, mentre le medie mobili aiutano a tenere conto degli effetti indiretti degli errori di previsione passati.
Ecco una spiegazione passo per passo di come funzionano insieme:
Stazionarietà
Il primo passo nella previsione delle serie temporali con i modelli ARIMA è assicurarsi che la serie temporale sia stazionaria. Poiché i dati non stazionari possono portare a previsioni inaccurate e risultati del modello distorti, ARIMA si basa sull'assunzione di stazionarietà. Se i dati della serie temporale non sono stazionari, ARIMA applica la differenziazione per renderli stazionari. Ciò comporta la sottrazione del valore precedente dal valore corrente. L'ordine di differenziazione (d) determina il numero di volte in cui questo processo viene ripetuto.
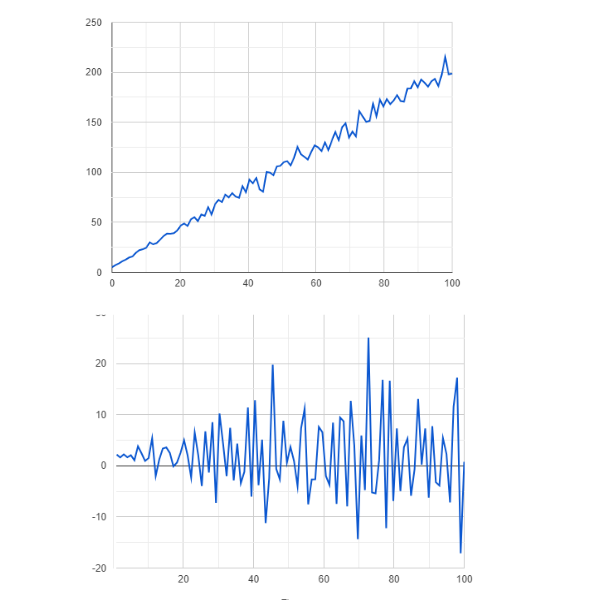 Figure- Non-stationary vs stationary data .png
Figure- Non-stationary vs stationary data .png
Figura: Dati non stazionari vs stazionari
Identificazione del modello
L'identificazione del modello determina i valori appropriati per le componenti autoregressiva (p) e di media mobile (q). La funzione di autocorrelazione (ACF) e la funzione di autocorrelazione parziale (PACF) sono strumenti essenziali per questo processo:
Funzione di autocorrelazione
La funzione di autocorrelazione identifica l'ordine della componente autoregressiva (AR) (p). Se mostra una correlazione al ritardo k, suggerisce che il valore corrente è correlato al valore di k periodi fa, dove k rappresenta il numero di ritardi (intervalli temporali) tra il valore corrente e un valore precedente nella serie temporale.
Funzione di autocorrelazione parziale
La funzione di autocorrelazione parziale (PACF) identifica l'ordine della componente di media mobile (MA) (q). Se mostra una correlazione significativa al ritardo k, indica che il valore corrente è correlato all'errore di previsione verificatosi k periodi fa.
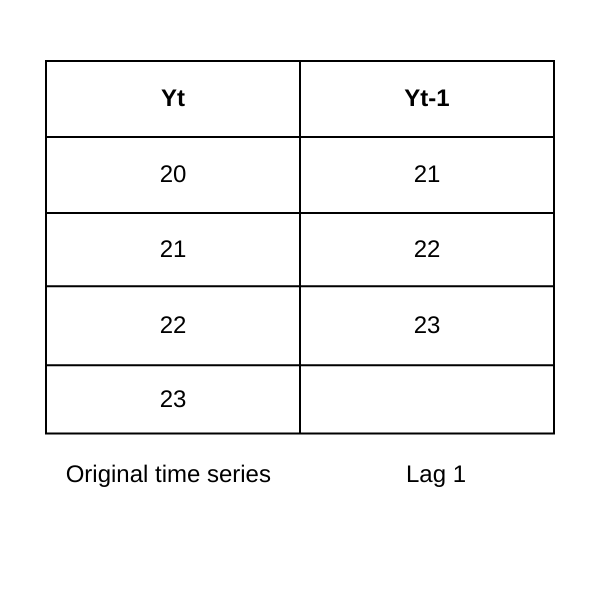 Figure- Lag-1 autocorrelation.png
Figure- Lag-1 autocorrelation.png
Figura: autocorrelazione con ritardo 1
Stima del modello
Dopo aver determinato gli ordini autoregressivi (AR) e le componenti di media mobile (MA), ARIMA stima i parametri del modello. I parametri del modello quantificano la forza delle relazioni tra il valore corrente e i suoi valori passati (AR) e tra il valore corrente e gli errori passati (MA).
La stima di massima verosimiglianza (MLE) è il metodo più comune per la stima dei parametri nei modelli ARIMA. La MLE stima i parametri del modello trovando i valori che massimizzano la probabilità di osservare i dati forniti. Per i modelli ARIMA, la funzione di verosimiglianza si basa in genere sull'ipotesi che gli errori siano distribuiti normalmente. I minimi quadrati e i metodi bayesiani sono altri approcci per la stima dei parametri nei modelli ARIMA.
Previsione del modello
Il modello ARIMA stimato prevede infine i valori futuri sulla base dei dati storici. Se necessario, il modello può anche essere perfezionato regolando gli ordini delle componenti AR e MA o considerando altri fattori come la stagionalità.
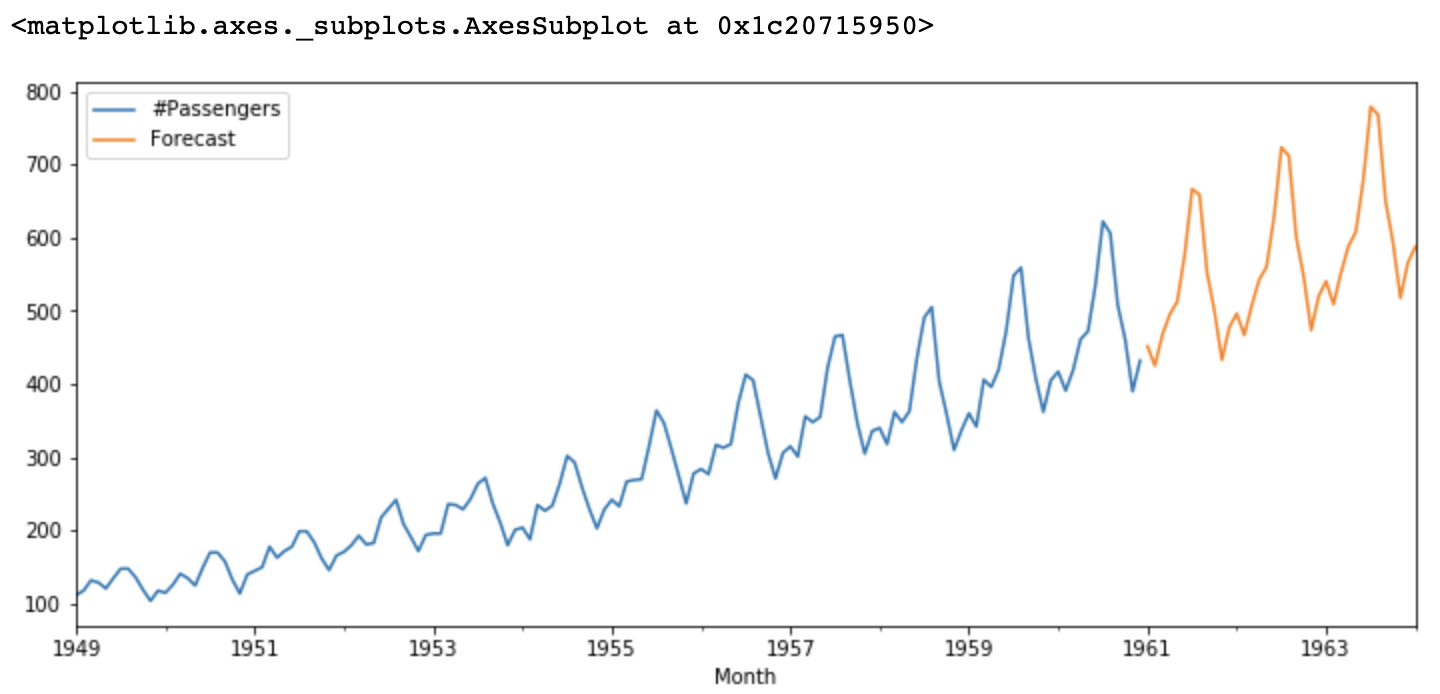 Figure- ARIMA forecasts.png
Figure- ARIMA forecasts.png
Figura: previsioni ARIMA
Confronto con concetti simili
ARIMA viene spesso confrontato con altri concetti simili nel contesto dell'analisi dei dati e della previsione. Ecco un confronto per sfatare equivoci comuni:
ARIMA vs. SARIMA: SARIMA (Seasonal ARIMA) è un'estensione di ARIMA che incorpora specificamente la stagionalità nell'analisi dei dati di serie temporali. ARIMA è un modello statistico per dati di serie temporali senza un chiaro schema stagionale.
ARIMA vs. Exponential Smoothing: ARIMA ed exponential smoothing sono metodi per la previsione delle serie temporali. ARIMA utilizza tecniche statistiche per modellare gli schemi sottostanti, inclusi trend, stagionalità e autocorrelazione. Exponential smoothing, d'altra parte, applica un metodo più semplice di media ponderata, in cui alle osservazioni recenti viene attribuito un peso maggiore rispetto a quelle più vecchie. Mentre ARIMA è più adatto a dati con schemi intricati, exponential smoothing funziona bene per serie temporali con un trend relativamente stabile e una stagionalità minima, rendendolo meno adattabile a dati complessi.
ARIMA vs. Vector Autoregression (VAR): VAR è adatto per la previsione di serie temporali multivariate in cui diverse variabili si influenzano a vicenda. ARIMA è adatto per serie temporali univariate e richiede la differenziazione della serie per ottenere la stazionarietà.
Vantaggi e sfide di ARIMA
ARIMA offre diversi vantaggi, che lo rendono uno dei modelli di previsione delle serie temporali più ampiamente utilizzati. Tuttavia, presenta anche alcune sfide, che richiedono di considerare le proprietà e gli obiettivi specifici della tua analisi prima di applicare ARIMA.
Vantaggi
I vantaggi dell'utilizzo dei modelli ARIMA per la previsione delle serie temporali includono:
Flessibilità: ARIMA può gestire un'ampia gamma di dati di serie temporali, inclusi trend lineari e non lineari, schemi stagionali, volatilità e autocorrelazione. Ciò gli consente di affrontare caratteristiche comuni delle serie temporali reali, come indicatori economici e schemi non lineari nei prezzi delle azioni.
Semplicità: I modelli ARIMA sono facili da comprendere grazie al loro funzionamento semplice e alle ipotesi trasparenti. Possono gestire serie temporali lunghe con un numero relativamente elevato di osservazioni.
Accuratezza: L'accuratezza dei modelli ARIMA dipende dalla qualità dei dati. Pertanto, considerare le ipotesi e scegliere modelli appropriati porta a risultati accurati.
Interpretabilità: I parametri del modello ARIMA hanno interpretazioni chiare, inclusi i coefficienti autoregressivi e di media mobile. Questi coefficienti offrono informazioni su come i valori passati e gli errori influenzano i valori futuri.
Ampia applicabilità: I modelli ARIMA sono ampiamente utilizzati in diversi settori per applicazioni di previsione come la modellazione finanziaria, la previsione della domanda e la previsione del carico. Pertanto, sono integrati in molti linguaggi di programmazione e hanno un'ampia comunità di sostenitori.
Base per altri modelli: I modelli ARIMA sono una base per modelli di serie temporali più complessi come SARIMA e ARIMAX. Tenendo conto di fattori aggiuntivi, aiutano a migliorare l'accuratezza delle previsioni oltre i valori storici della serie temporale.
Sfide
Le sfide dei modelli ARIMA includono:
Ipotesi di stazionarietà: Il modello ****ARIMA presuppone che la serie temporale sia stazionaria; in caso contrario, trasforma i dati per ottenere la stazionarietà. Tuttavia, molti set di dati del mondo reale non sono stazionari e la loro preelaborazione può complicare il processo di modellazione.
Relazioni lineari: ARIMA è un modello lineare e non può catturare relazioni non lineari complesse nei dati. Pertanto, potrebbe non catturare accuratamente cambiamenti improvvisi nei dati causati da crisi economiche, shock esterni, ecc.
Identificazione del modello: Le prestazioni del modello ARIMA dipendono dalla selezione dei parametri appropriati (p, d, q). Tuttavia, spesso richiede tentativi ed errori o metodi di grid search e può portare a overfitting o underfitting.
Sensibilità agli outlier: I modelli ARIMA possono essere sensibili agli outlier, che possono influire sulle loro prestazioni. Pertanto, è necessaria un'attenta preelaborazione dei dati per ottenere i risultati desiderati.
Previsione a lungo termine: ARIMA non è adatto alla previsione a lungo termine. Questo perché i modelli ARIMA si basano su schemi passati e potrebbero non catturare adeguatamente eventi imprevisti o cambiamenti strutturali nel processo di generazione dei dati.
Casi d'uso, strumenti e fornitori di ARIMA
I modelli ARIMA sono ampiamente applicati per la previsione e l'analisi delle serie temporali in vari campi. Ciò include economia e finanza, previsione della domanda, pianificazione della produzione e della capacità, sanità, ecc.
Ad esempio, i modelli ARIMA sono stati utilizzati per prevedere la diffusione dei casi di COVID-19 in India. I ricercatori hanno addestrato i modelli ARIMA utilizzando dati giornalieri sui casi di COVID-19 dal 14 marzo al 3 maggio 2020, ottenendo un'accuratezza soddisfacente.
Molti linguaggi di programmazione e pacchetti statistici forniscono strumenti per implementare i modelli ARIMA. Includono:
R
R dispone di ampie capacità di analisi delle serie temporali, inclusa la modellazione ARIMA. Diverse librerie, tra cui stats, forecast e tseries, offrono funzioni per implementare il modello ARIMA in R.
Python
Python offre anche ampie librerie statistiche per implementare ARIMA. Alcune di queste includono Statsmodels, Numpy e Pandas.
MATLAB
MATLAB è un software commerciale di calcolo matematico con funzioni integrate per la modellazione ARIMA. Consente inoltre l'integrazione con altri strumenti software e linguaggi di programmazione per combinare la modellazione ARIMA con altri flussi di lavoro.
FAQ su ARIMA
A cosa serve ARIMA?
AutoRegressive Integrated Moving Average (ARIMA) è un modello statistico utilizzato per l'analisi e la previsione delle serie temporali. È un metodo popolare per prevedere i valori futuri di una serie temporale in base ai suoi valori passati.
In che modo ARIMA differisce dagli altri modelli di previsione delle serie temporali?
ARIMA differisce dagli altri modelli di previsione delle serie temporali per la sua flessibilità, interpretabilità e ampia applicabilità. ARIMA può catturare un'ampia gamma di pattern nei dati delle serie temporali, inclusi trend, stagionalità e autocorrelazione. I parametri in un modello ARIMA hanno interpretazioni chiare e possono fungere da baseline per il confronto con modelli più complessi.
Come interpretare le previsioni ARIMA?
Le previsioni ARIMA sono in genere interpretate come stime puntuali dei valori futuri attesi della serie temporale. Varie metriche, come l'errore quadratico medio (MSE), l'errore assoluto medio (MAE) e la radice dell'errore quadratico medio (RMSE), possono essere utilizzate per valutare l'accuratezza delle previsioni.
Quali sono le ipotesi del modello ARIMA?
Di seguito sono riportate le ipotesi del modello ARIMA:
Stazionarietà: Le proprietà statistiche delle serie temporali (media, varianza, autocorrelazione) devono rimanere costanti nel tempo.
Linearità: ARIMA presuppone una relazione lineare tra il valore attuale e i suoi valori passati ed errori.
Normalità: Si presume che gli errori siano distribuiti normalmente.
Nessuna autocorrelazione negli errori: Si presume che gli errori non siano correlati.
Risorse correlate
Scopri di più sull'archiviazione e la preelaborazione dei dati delle serie temporali:
- Che cos'è ARIMA?
- Come funziona ARIMA?
- Confronto con concetti simili
- Vantaggi e sfide di ARIMA
- Casi d'uso, strumenti e fornitori di ARIMA
- FAQ su ARIMA
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente