




Come individuare e correggere le fallacie logiche dei modelli GenAI
Introduzione
I modelli linguistici di grandi dimensioni (LLM) hanno trasformato il campo dell'IA, soprattutto nell'IA conversazionale, nella generazione di testi, ecc. Gli LLM sono addestrati su enormi quantità di dati con miliardi di parametri per generare testo come gli esseri umani. Molte aziende sono in attesa di sviluppare chatbot basati su LLM per gestire le domande dei clienti, raccogliere recensioni, risolvere reclami, ecc. Con la crescita dell'uso e dell'adozione di LLM, dobbiamo affrontare un problema critico: Le fallacie logiche nei risultati degli LLM. È fondamentale affrontare questa sfida e rendere i sistemi di intelligenza artificiale più responsabili e affidabili.
Jon Bennion, ingegnere dell'IA con una ricca esperienza in ML applicato, sicurezza dell'IA e valutazione, ha recentemente discusso un interessante approccio per affrontare le fallacie logiche all' Unstructured Data Meetup ospitato da Zilliz. Jon è un importante collaboratore di LangChain, che implementa nuovi approcci per affrontare le fallacie nell'output.
Guarda il replay del discorso di Jon
Durante la sua presentazione, Jon spiega quali sono le insidie più comuni nel ragionamento per modelli che possono portare a fallacie logiche. Discute inoltre le strategie per identificare e correggere queste fallacie, sottolineando l'importanza di allineare i risultati del modello con un ragionamento logicamente valido e simile a quello umano.
Che cosa sono le fallacie logiche?
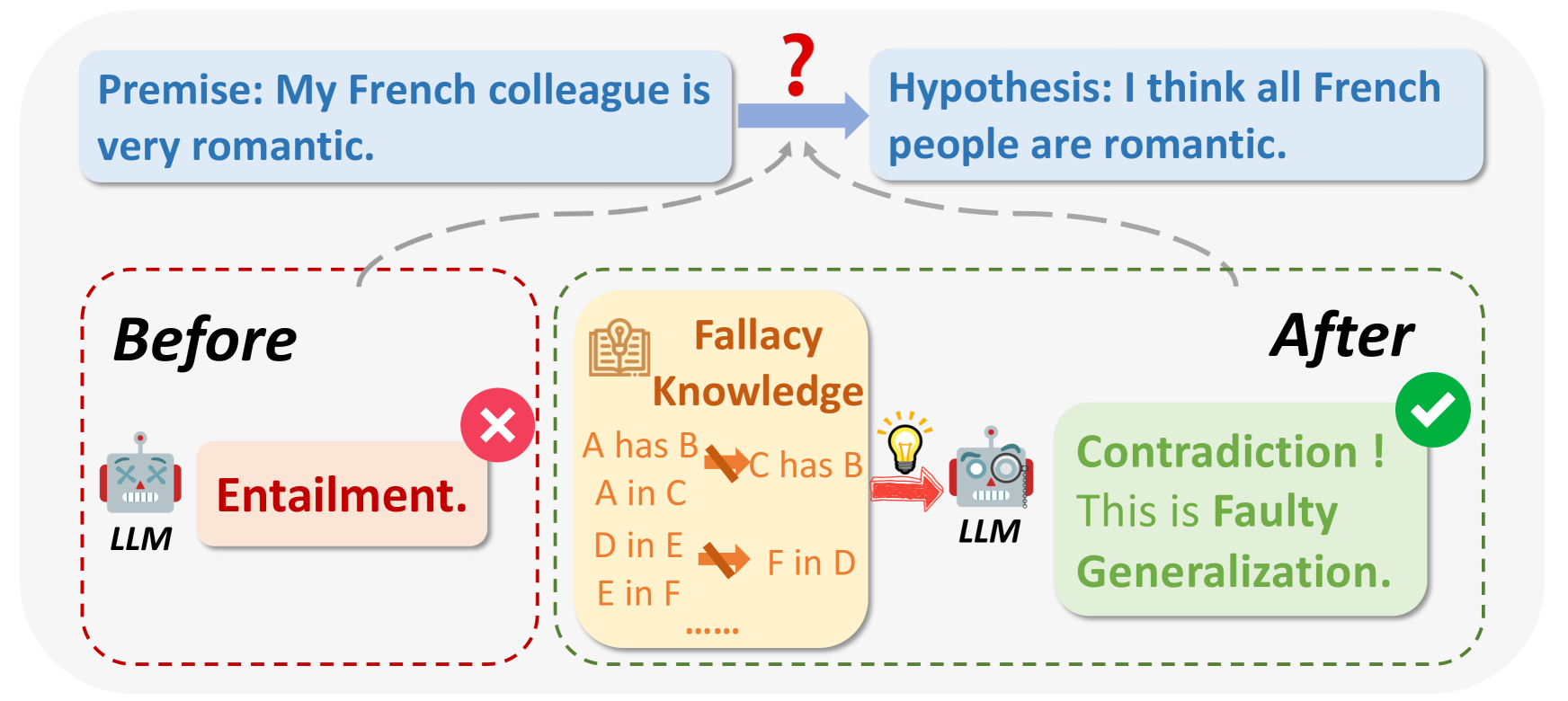
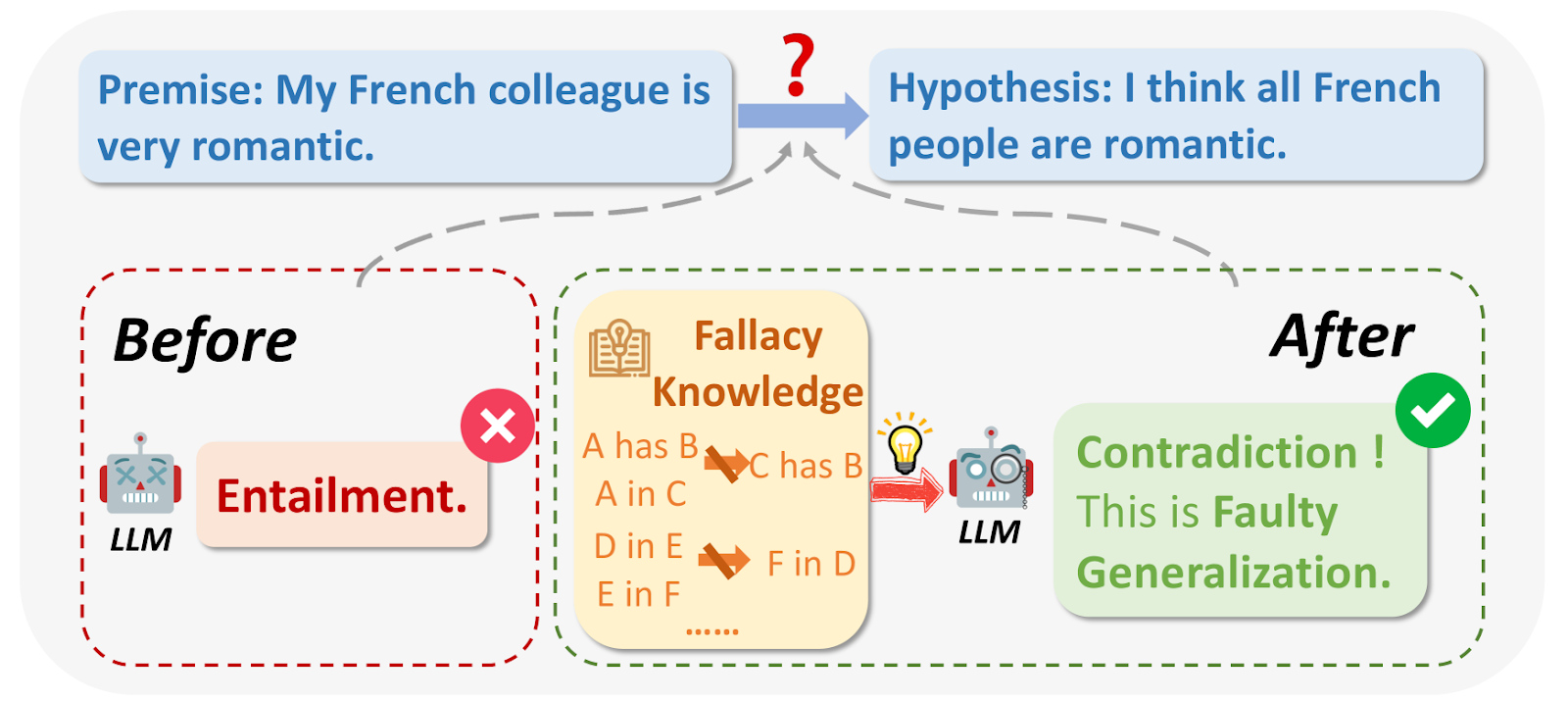 Cosa sono le fallacie logiche?.png
Cosa sono le fallacie logiche?.png
Figura 1: Cosa sono le fallacie logiche?
Fonte dell'immagine:_ https://arxiv.org/html/2404.04293v1/x1.png
Quando si interrogano i LLM, in alcuni casi i risultati possono essere viziati da ragioni logiche o irrilevanti per la domanda. Le fallacie logiche includono Ad Hominem, ragionamento circolare, appello all'autorità, ecc. Spesso fanno ampie generalizzazioni basate su campioni di piccole dimensioni, ad esempio: "Il mio amico francese è maleducato, quindi tutti i francesi devono essere maleducati".
In alcuni casi, si può presumere che qualcosa sia vero o giusto perché è popolare.
Esempio: "Tutti usano questa nuova app, quindi deve essere la migliore". A volte, i LLM hanno difficoltà a ricordare i dettagli della conversione precedente e non riescono a fornire una risposta accurata.
Perché si verificano le fallacie logiche?
Le ragioni per cui si verificano le fallacie logiche sono molteplici. Come tutti sappiamo, i LLM non sono perfettamente addestrati ad affrontare tutte le situazioni nello stesso modo in cui il nostro cervello le comprenderebbe.
Dati di formazione imperfetti
I dati di addestramento che forniamo provengono da varie fonti su Internet e non sono perfetti. Contengono molti pregiudizi umani, incoerenze e persino informazioni errate in casi limite. Durante l'addestramento, il LLM è esposto a ragionamenti errati e incoerenti e impara anche questo. Se i dati di addestramento contengono argomentazioni errate, l'LLM coglierà questi modelli e li imiterà nelle risposte.
Piccola finestra di contesto
Nel discorso, Jon afferma: "Una finestra di contesto piccola può causare problemi nella risposta. Molti team lottano per ottimizzare la finestra di contesto in base ai requisiti di memoria e alle prestazioni".
La finestra di contesto si riferisce alla quantità di informazioni che un LLM può considerare alla volta ed è fissa. Quando la finestra di contesto è piccola, il modello può perdere dettagli importanti e non riesce a formare una risposta coerente. Questo può portare a fallacie come generalizzazioni affrettate o false dicotomie.
Natura probabilistica
I LLM generano il testo in base a quale parola è altamente probabile nella sequenza. Non possono comprendere il vero significato delle parole come fanno gli esseri umani. Addestriamo i modelli a raggiungere una coerenza locale con il contesto. A volte, questo può portare a fallacie logiche, in quanto il contesto più ampio può sfuggire.
Come affrontare le fallacie logiche?
È fondamentale individuare e impedire che l'LLM produca risposte con una logica errata, in modo che gli utenti possano fidarsi. Jon illustra brevemente le pratiche comuni utilizzate per affrontare questo problema, come il feedback umano, l'apprendimento per rinforzo, l'ingegneria del prompt e altro ancora.
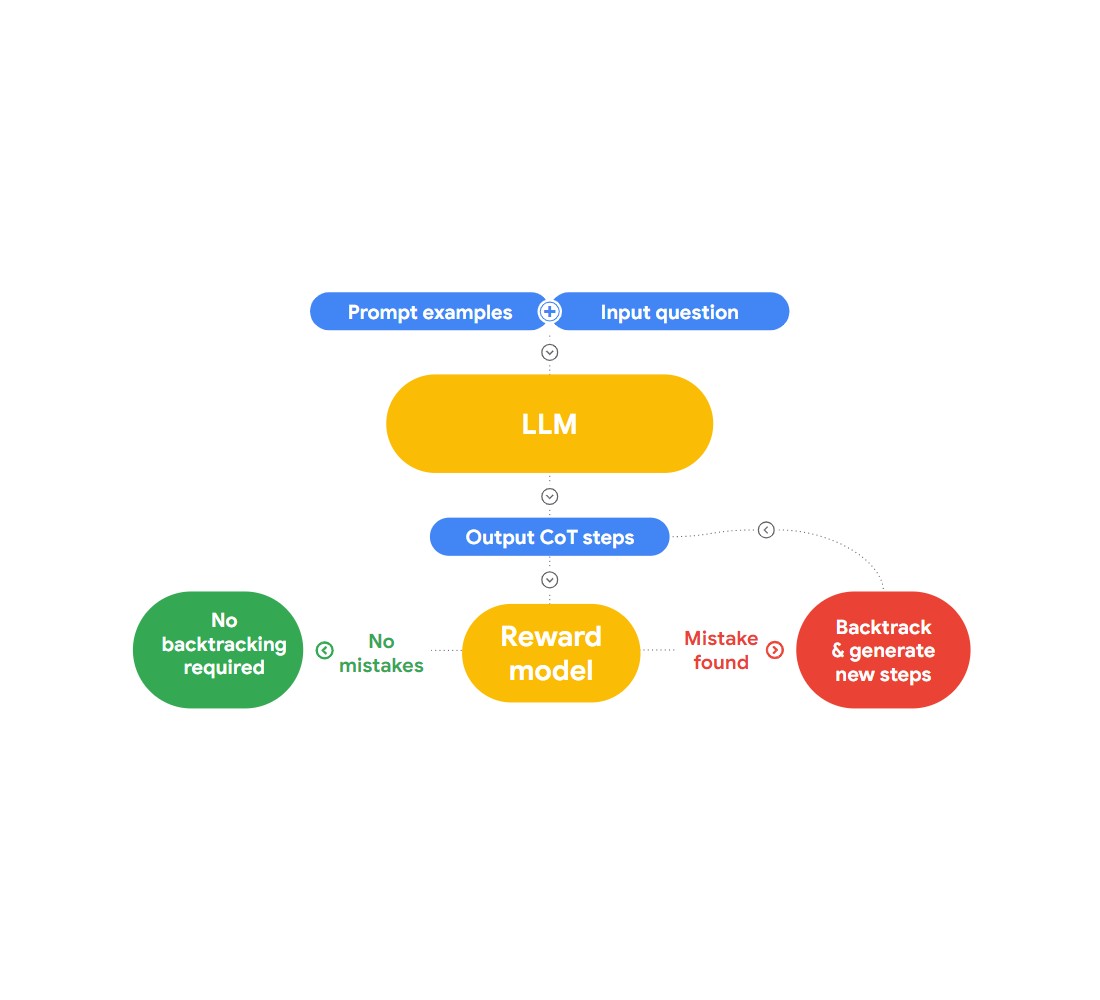
In questo intervento, Jon presenta un approccio interessante per individuare e correggere le fallacie logiche, il "RLAIF". L'idea è di usare l'intelligenza artificiale per correggere se stessa.
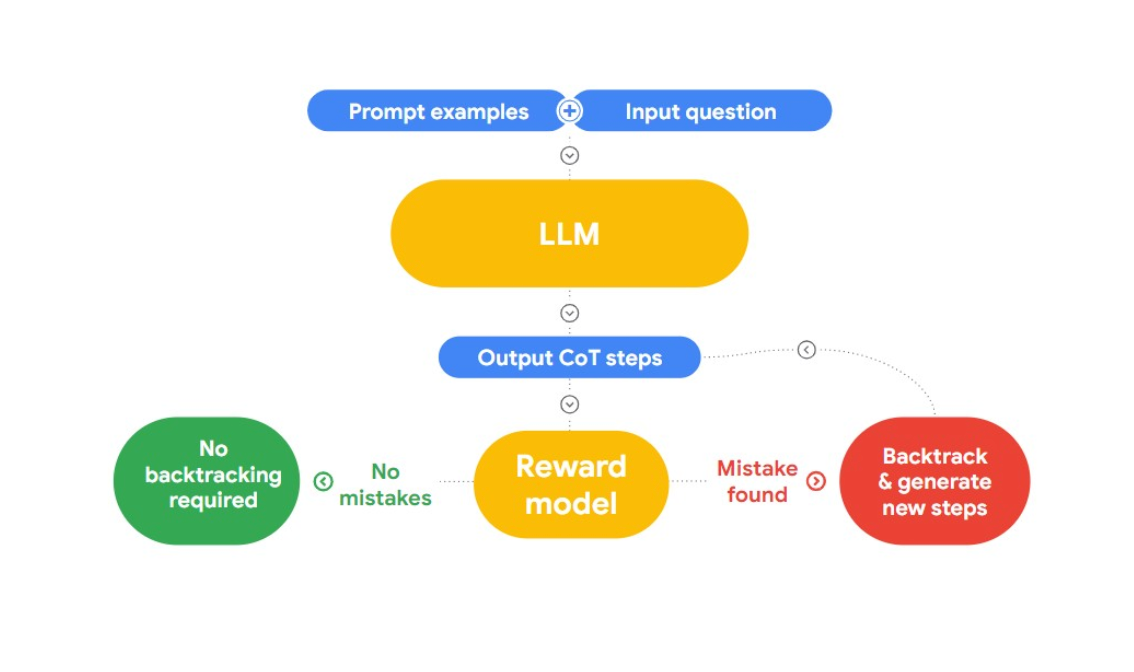
Fig 2: _Come funziona RLAIF?
L'autore fa riferimento al documento di ricerca "Case-based Reasoning with Language Models for Classification of Logical Policies", utile per il nostro problema. Il documento introduce il Case-Based Reasoning (CBR), per classificare le fallacie logiche. Funziona in tre fasi:
**Forniamo a CBR una raccolta di dati testuali (case base) che contengono fallacie logiche e identità umane. Quando viene fornito un nuovo testo, CBR effettua una ricerca nella base di casi per trovare un caso simile.
Adattamento: I casi recuperati vengono adattati al contesto specifico della nuova argomentazione, considerando fattori come gli obiettivi, le spiegazioni e le controargomentazioni.
Classificazione: Sulla base delle informazioni disponibili, CBR identifica e classifica le fallacie logiche.
Jon ha ripreso questo approccio, lo ha sviluppato ulteriormente e ha implementato una funzione di rilevamento delle fallacie in [LangChain] (https://zilliz.com/learn/LangChain).
Prevenire le fallacie logiche usando la catena di fallacie di LangChain
Jon dimostra un esempio chiedendo al modello di fornire output con fallacie logiche. L'esempio seguente mostra un output che soffre di "Appello all'autorità" ed è logicamente errato.
# Esempio di output del modello che viene restituito con una fallacia logica
misleading_prompt = PromptTemplate(
template="""Dovete rispondere utilizzando solo le fallacie logiche insite nelle spiegazioni delle vostre risposte.
Domanda: {domanda}
Risposta errata:""",
input_variables=["domanda"],
)
llm = OpenAI(temperatura=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="Come faccio a sapere che la terra è rotonda?")
L'output:
'La terra è rotonda perché il mio professore ha detto che lo è, e tutti credono al mio professore'.
Si tratta di un metodo di ingegneria inversa in cui individuiamo le fallacie che il modello ha imparato e poi gli impediamo di usarle.
Jon ha spiegato come utilizzare il modulo FallacyChain di LangChain per effettuare le correzioni. Per prima cosa, inizializziamo una LangChain con una richiesta fuorviante per evidenziare le fallacie intrinseche presenti.
fallacie = FallacyChain.get_fallacies(["correzione"])
fallacy_chain = FallacyChain.from_llm(
catena=catena_ingannevole,
fallacie_logiche=fallacie,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="Come faccio a sapere che la terra è rotonda?")
Quindi, inizializziamo una Catena delle fallacie, fornendo la catena delle fallacie come input e il modello LLM. La catena rileverà il tipo di fallacia presente e aggiornerà la risposta rimuovendola.
> Inserimento di una nuova catena FallacyChain...
Risposta iniziale: La terra è rotonda perché il mio professore ha detto che lo è, e tutti credono al mio professore.
Applicazione della correzione...
Critica della fallacia: La risposta del modello utilizza un appello all'autorità e all'ad populum (tutti credono al professore). Critica di fallacia necessaria.
Risposta aggiornata: È possibile trovare prove di una Terra rotonda grazie a prove empiriche come foto dallo spazio, osservazioni di navi che scompaiono all'orizzonte, la visione dell'ombra curva sulla Luna o la capacità di circumnavigare il globo.
> Catena finita.
'Si possono trovare prove di una Terra rotonda grazie a prove empiriche come foto dallo spazio, osservazioni di navi che scompaiono all'orizzonte, vedere l'ombra curva sulla luna o la capacità di circumnavigare il globo.'
Jon si addentra nel funzionamento del modulo Fallacy Chain, che ha incorporato in LangChain. L'architettura della Fallacy Chain ha due componenti principali: La Catena della Critica e la Catena della Revisione. In entrambe le catene si sfrutta l'ingegneria del prompt per individuare e modificare le fallacie nella risposta. Un rapido sguardo al suo funzionamento:
Quando forniamo l'input, l'LLM lo elabora e genera una risposta iniziale.
Il passo successivo è il rilevamento delle fallacie. La catena Critique identifica e classifica le fallacie presenti in base agli schemi individuati. Jon parla di sfruttare l'elenco di fallacie che sono state estratte e utilizzate dal documento di ricerca citato in precedenza.
La catena di revisione è codificata con l'ingegneria del prompt per generare una risposta rivista che eviti le fallacie rilevate. Ciò potrebbe comportare una riformulazione, l'aggiunta di un contesto o la modifica della struttura dell'argomentazione.
Applicazione demo
Jon ha anche mostrato un'applicazione per estrarre le fallacie logiche dagli articoli di cronaca. In questa dimostrazione ha mostrato come i nuovi articoli provenienti da regioni diverse possano avere un pregiudizio politico e autoritario. Ha inoltre mostrato un'applicazione realizzata con Open AI per estrarre nuovi articoli su un determinato argomento e identificarne le principali fallacie. Con questa applicazione, ha cercato nuovi articoli relativi a "Cina" come parola chiave e il risultato è mostrato qui sotto.

Gli articoli spiegano come la Fallacy Chain abbia identificato e spiegato il problema dell'"appello all'autorità". Jon spiega come strumenti come questi possano ripulire i dati di formazione dalle fallacie logiche, fornendo al modello un apprendimento privo di difetti. La FallacyChain può migliorare notevolmente l'affidabilità dei risultati di LLM e aumentare la fiducia degli utenti. Inoltre, fornisce trasparenza spiegando le modifiche e le loro ragioni, aiutando gli utenti a capire come è stata raggiunta la coerenza logica.
Per ulteriori informazioni su questa dimostrazione, guardare il replay dell'intervento di Jon al meetup.
Conclusione
La FallacyChain di LangChain è un approccio potente per migliorare l'integrità logica del testo generato da LLM. Può aumentare la fiducia degli utenti e rendere più facile l'implementazione di LLM secondo le norme. Sebbene i vantaggi siano sorprendenti, è necessario valutare i costi per implementarli su scala. Si tratta di uno spazio stimolante e vengono condotti nuovi esperimenti per migliorarlo utilizzando metodi di apprendimento automatico per la classificazione delle fallacie, ecc.

{kind=link}
{kind=link}
Continua a leggere

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.