




Comprendre le sharding des bases de données

Comprendre le sharding des bases de données
Les sites web et les applications modernes s'appuient fortement sur les technologies de base de données pour gérer les requêtes de lecture et d'écriture de plusieurs utilisateurs. Cependant, à mesure que la popularité d'une application augmente, le nombre d'utilisateurs s'accroît et il devient difficile d'offrir une expérience client optimale en raison des pannes fréquentes de la base de données.
Alors, comment les développeurs peuvent-ils faire évoluer leurs bases de données pour répondre à la demande croissante ? Bien que la réponse puisse varier en fonction du cas d'utilisation, le partage de base de données est une méthode simple et rentable. Elle est facile à mettre en œuvre et offre des améliorations significatives en termes de performances.
Malgré sa simplicité, le partage de bases de données peut être un concept déroutant. Ce billet explique sa signification, les techniques de mise en œuvre, les alternatives, les avantages et les défis, ainsi que les cas d'utilisation pour vous aider à comprendre quand et comment appliquer la méthode de sharding la plus appropriée.
Qu'est-ce que le sharding de base de données ?
Le sharding de base de données divise une base de données étendue en morceaux plus petits appelés "shards" et les distribue sur plusieurs machines. Chaque machine utilise la même technologie et travaille en parallèle pour traiter de gros volumes de données.
C'est l'une des nombreuses méthodes permettant d'accélérer le traitement des données et d'assurer une [haute disponibilité] (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Si une machine ou un serveur de base de données tombe en panne en raison d'une surcharge de demandes, les autres serveurs peuvent toujours traiter les demandes de lecture et d'écriture, ce qui permet à l'utilisateur de continuer à bénéficier d'une expérience fluide.
Cependant, le sharding ne fonctionne que tant que les données sont disponibles et accessibles. Il permet aux développeurs de répartir organiquement la charge de travail et de réduire la latence.
La réplication et le partitionnement sont d'autres techniques permettant d'éviter les temps d'arrêt. Ces méthodes sont plus appropriées pour les petites bases de données. La réplication consiste à copier une base de données entière sur plusieurs serveurs, tandis que le partitionnement décompose une base de données et la stocke sur une seule machine. Les sections suivantes expliquent ces approches plus en détail.
Comment fonctionne le sharding de base de données ?
Le sharding est une forme de mise à l'échelle horizontale dans laquelle les développeurs installent des nœuds ou des serveurs supplémentaires pour stocker plusieurs partitions de données. Chaque partition devient une table indépendante partageant le même schéma que la base de données d'origine. Toutefois, les informations contenues dans chaque partition sont uniques et les développeurs stockent les différents morceaux sur plusieurs ordinateurs, appelés nœuds.
Par exemple, le tableau suivant illustre une base de données unique représentant des informations sur les clients et les articles qu'ils ont achetés.
| Identifiant du client | Nom | Article acheté |
| 10001 | A | Chemise |
| 10002 | B | Casquette |
| 10003 | C | Chemise |
| 10004 | D | Chaussures |
Un développeur peut utiliser le sharding de base de données pour diviser la base de données en partitions plus petites, appelées "logical shards", sur des machines distinctes ou "physical shards".
Serveur 1
| Identification du client | Nom | Orticle acheté | Identification du client | Identification du client | **Identification du client |
| 10001 | A | Chemise | |||
| 10002 | B | Casquette |
Serveur 2
| Identification du client | Nom | Orticle acheté |
| 10003 | C | Chemise |
| 10004 | D | Chaussures |
Le sharding fonctionne selon une architecture "shared-nothing", où chaque nœud d'une grappe d'ordinateurs traite les demandes des utilisateurs de manière indépendante. Lorsqu'un utilisateur tente d'accéder à la base de données, seul le shard contenant les informations de l'utilisateur devient actif et traite la demande entrante.
Les développeurs répartissent les données dans des ensembles logiques à l'aide d'une clé d'ensemble de données (shard key). Ils peuvent sélectionner la clé en fonction d'une colonne qui organise les données en groupes ou en créer une nouvelle. Les sections suivantes expliquent le fonctionnement d'une clé de partage et aident à développer des groupes de données pour un partage efficace.
Méthodes de partage
Les développeurs peuvent mettre en œuvre plusieurs techniques de partage en fonction du cas d'utilisation et de la nature des données qu'ils souhaitent traiter. Parmi les méthodes les plus répandues, on peut citer la répartition par plage, la répartition par hachage, la répartition par répertoire et la répartition géographique.
Sharding basé sur l'intervalle
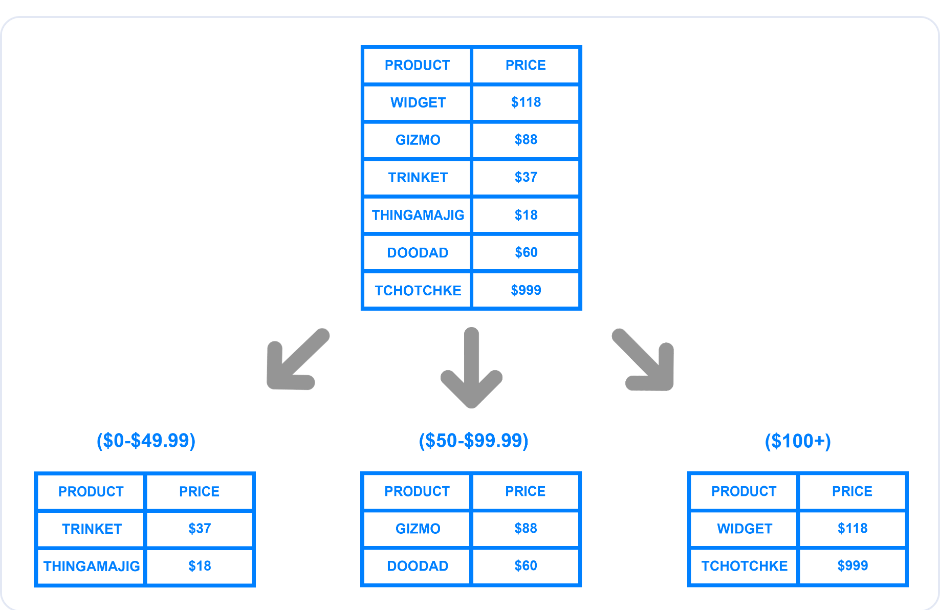
Le sharding dynamique ou basé sur une plage divise une base de données en plusieurs parties sur la base d'une plage de valeurs spécifique. Le diagramme ci-dessous illustre la manière dont un développeur peut diviser une table en groupes à l'aide d'une fourchette de prix.
 Range-based sharding based on price.png
Range-based sharding based on price.png
Sharding basé sur une fourchette de prix
L'exemple montre trois unités logiques créées à l'aide de fourchettes de prix. Le développeur peut attribuer à chaque morceau une clé unique et les stocker sur des machines ou des unités physiques distinctes. Lors de l'écriture d'un enregistrement dans la base de données, le système déterminera le groupe approprié auquel les données appartiennent en fonction de la fourchette de prix et le mettra à jour en conséquence.
Bien que la mise en œuvre de la répartition dynamique soit simple, elle peut entraîner une surcharge d'un groupe particulier s'il contient plus d'enregistrements que les autres. Dans l'exemple ci-dessus, si davantage de clients achètent des articles dont le prix est supérieur à 100 $, le volume de données dans le troisième groupe de stockage sera plus important que le volume dans les autres groupes.
Cette distribution inégale peut aller à l'encontre de l'objectif de la répartition, car un seul groupe de données contiendra la plupart des données, ce qui entraînera un ralentissement du système. En outre, cette méthode nécessite une table de recherche qui stocke la clé unique du dépôt et les plages correspondantes.
Répartition par hachage
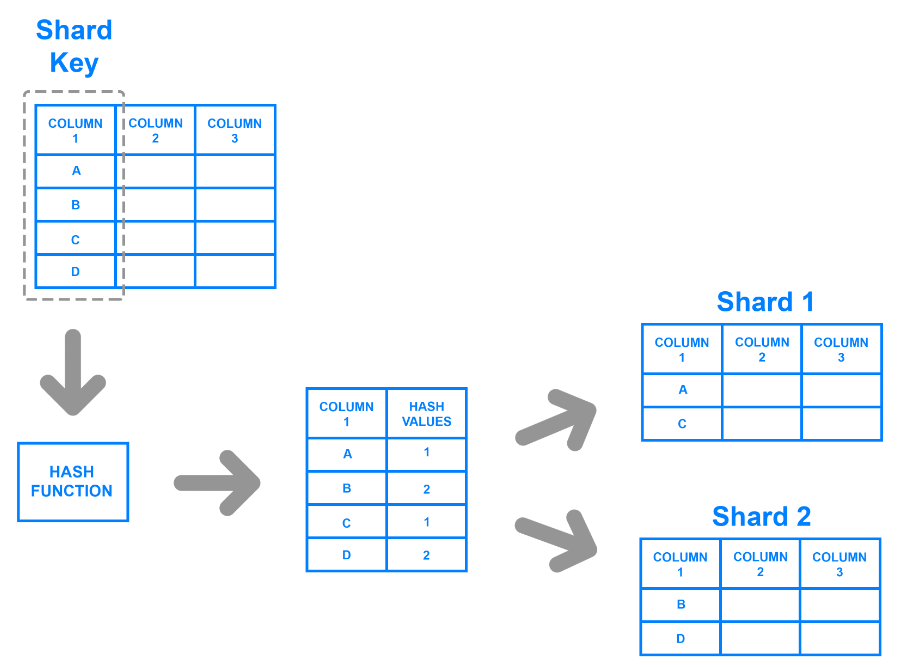
La répartition par hachage attribue une clé de hachage à chaque enregistrement en fonction d'une colonne spécifique. Les développeurs génèrent des clés de hachage à l'aide d'une fonction de hachage qui prend les valeurs de la colonne en entrée. Ils peuvent diviser les données en déterminant les enregistrements qui appartiennent à une clé ou à une valeur de hachage correspondante.
Par exemple, les développeurs peuvent sélectionner une colonne et utiliser ses valeurs pour générer des valeurs de hachage. Ces valeurs peuvent servir de clé de partage pour chaque morceau, et les développeurs peuvent les stocker sur différentes machines. Le diagramme ci-dessous illustre le processus.
 Hashed sharding.png
Hashed sharding.png
La répartition par hachage résout le problème de la distribution inégale, car la fonction ou l'algorithme de hachage n'a pas besoin d'une clé de répartition définie par l'utilisateur pour partitionner les données. Cependant, il devient difficile d'interroger les données des différents fichiers car les clés ne regroupent pas les données sur la base de critères significatifs. Un algorithme génère aléatoirement les valeurs de hachage et divise les données de manière ad hoc.
Par exemple, dans le cas d'une répartition basée sur les plages, les clés reflètent les plages d'une valeur particulière dans la table et se rapportent à la structure des données de manière plus significative. [L'interrogation] (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) de tableaux de partage basés sur des plages de valeurs est plus rapide que l'interrogation de données basées sur des clés de hachage.
En outre, l'ajout de nouvelles unités ou la mise à niveau des systèmes oblige le développeur à réexécuter l'ensemble de l'algorithme de hachage sur tous les enregistrements. Ce processus est nécessaire pour équilibrer le volume de données entre les machines, mais il peut entraîner des temps d'arrêt et des ressources informatiques considérables.
Directory Sharding (répartition de l'annuaire)
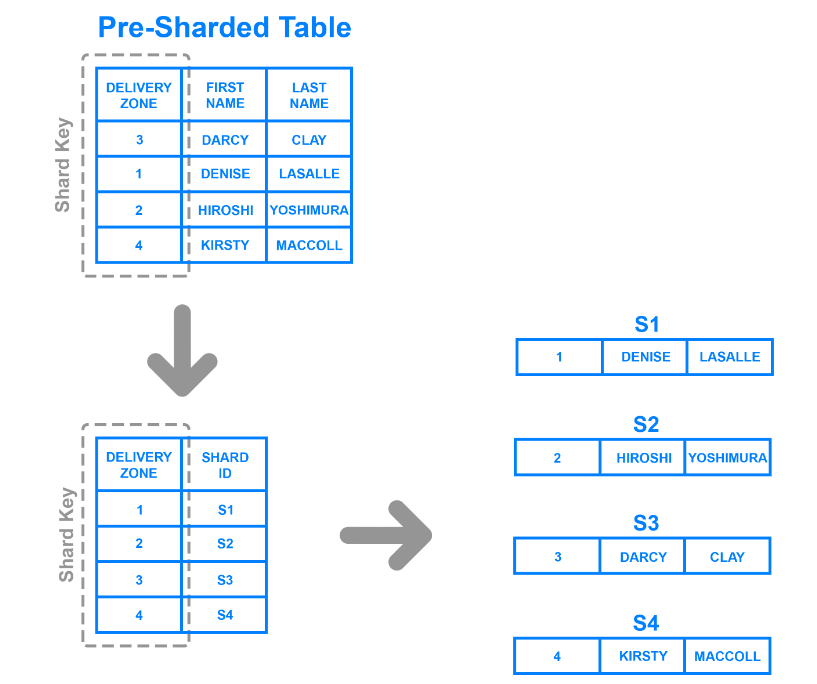
La répartition dans les répertoires est plus souple que les méthodes décrites ci-dessus. Il divise les données en fonction des valeurs d'une colonne particulière et utilise une table de recherche pour déterminer à quel répertoire un enregistrement appartient.
 Classement de l'annuaire en fonction de la zone de livraison.png
Classement de l'annuaire en fonction de la zone de livraison.png
Directory sharding based on delivery zone
Par exemple, l'illustration montre comment utiliser la colonne Zone de livraison comme clé de tri et diviser les données en fonction des zones auxquelles un client appartient. Cette méthode a permis de créer quatre répertoires distincts, car la table comporte quatre zones.
Contrairement au sharding basé sur des plages, les partitions de données sont plus polyvalentes car elles n'ont pas à respecter des plages de valeurs strictes. En outre, elles permettent aux développeurs de mettre à jour plus rapidement les tableaux, puisqu'ils n'ont pas à générer des clés de manière algorithmique pour toutes les valeurs d'une colonne donnée.
Toutefois, cette technique nécessite une table de consultation pour traiter les demandes entrantes, ce qui ralentit la vitesse de traitement. En outre, la sélection d'une colonne qui donne lieu à un grand nombre de fichiers peut augmenter considérablement la taille et la latence de la table de recherche.
Sélection d'une clé de dépôt
Pour assurer une répartition efficace de la base de données, les développeurs doivent déterminer une clé de répartition appropriée afin de garantir une distribution égale des données entre les différentes unités. Dans le cas d'une répartition inégale, certains disques peuvent devenir des points chauds contenant plus de données que d'autres.
La clé de répartition doit également simplifier le processus d'interrogation afin d'augmenter la vitesse de traitement et d'éviter les temps d'arrêt. En outre, la détermination d'une clé de répartition appropriée repose sur la sélection de la bonne colonne.
La liste ci-dessous met en évidence trois facteurs importants que les développeurs peuvent prendre en compte lorsqu'ils choisissent la colonne la plus appropriée pour générer la clé de tri.
- Cardinalité:** La cardinalité indique le nombre maximal de fichiers de stockage qu'un développeur peut créer sur la base de valeurs distinctes dans une colonne. Par exemple, la sélection d'une colonne contenant trois valeurs distinctes entraînera la création de trois groupes de stockage. Le sharding basé sur un répertoire est utile lorsque la cardinalité d'une colonne est faible.
Fréquence: La fréquence fait référence au pourcentage de données appartenant à une clé de tri particulière. Par exemple, dans le cas d'un triage basé sur des plages de prix, des plages de prix spécifiques peuvent contenir environ 80 % du total des enregistrements, ce qui constitue un point chaud pour les données.
- Le volume de données dans les fichiers dynamiques change en fonction de l'évolution de la demande d'une application. Par exemple, lorsque l'application devient populaire, les caractéristiques démographiques des utilisateurs peuvent changer et les inscriptions de clients âgés de 20 à 25 ans peuvent augmenter. La répartition basée sur l'âge peut créer un point névralgique pour les données, car il y aura plus de données dans la répartition correspondant à la tranche d'âge des 20-25 ans.
Pour garantir un partage efficace de la base de données, les développeurs doivent tenir compte de la cardinalité et de la fréquence d'une clé de partage et déterminer si elle donnera lieu à des partages dynamiques.
Comparaison avec les autres solutions
Le partage de bases de données est l'une des méthodes de mise à l'échelle des bases de données. Parmi les autres méthodes, citons la mise à l'échelle verticale, la réplication et le partitionnement. Comprendre en quoi elles diffèrent de la mise en commun aidera les développeurs à utiliser la bonne méthode de mise à l'échelle pour des scénarios spécifiques.
Mise à l'échelle verticale
La mise à l'échelle verticale consiste à augmenter la capacité d'un serveur existant. Les développeurs peuvent installer des unités centrales, des disques durs et d'autres logiciels supplémentaires pour améliorer les performances.
Cette méthode est utile lorsqu'une seule machine suffit à traiter les demandes des utilisateurs et que seules des améliorations progressives sont nécessaires pour accroître les performances.
Bien qu'elle soit moins coûteuse que le sharding, elle n'augmente la capacité du serveur que dans une mesure limitée, puisqu'une seule machine est disponible pour traiter les demandes des utilisateurs.
Réplication
Il y a réplication lorsque les développeurs font des copies de la même base de données et les stockent sur plusieurs ordinateurs. Tout comme le partage, cette méthode garantit une haute disponibilité, car si un ordinateur tombe en panne, les autres restent actifs.
La répartition et la réplication sont similaires car elles distribuent le traitement sur plusieurs machines. Cependant, le sharding divise les données en plusieurs morceaux, tandis que la réplication copie l'intégralité des données sans les décomposer.
Le sharding est plus approprié pour les grandes bases de données, tandis que la réplication nécessite des serveurs à forte capacité de stockage. La maintenance et la mise à jour de chaque réplique sur différentes machines est coûteuse et prend du temps.
Partitionnement
Le partitionnement divise une base de données en plusieurs groupes et les stocke sur une seule machine. Cette méthode convient lorsque vous souhaitez améliorer les performances des requêtes et que la taille de la base de données n'est pas suffisamment importante pour justifier le stockage des partitions sur différentes machines.
Elle peut contribuer à optimiser l'archivage des données en permettant aux développeurs de partitionner les données en fonction de la date et de l'heure. Ils peuvent déplacer les enregistrements spécifiques dont l'horodatage est supérieur à un certain seuil vers une table d'archivage et utiliser une autre table pour stocker les enregistrements les plus récents.
Avantages du sharding de base de données
Le partage des bases de données est une stratégie précieuse pour une gestion efficace des données. Les entreprises qui dépendent d'un grand nombre de données pour faire fonctionner leurs sites web, applications et autres logiciels axés sur les données doivent adopter le sharding pour maximiser les avantages de leur technologie de base de données.
La liste ci-dessous présente plus en détail quelques avantages que le sharding offre aux entreprises.
En répartissant les données sur plusieurs machines, le sharding permet aux entreprises de faire évoluer leurs systèmes de base de données plus efficacement afin de prendre en charge des charges de travail croissantes.
Temps d'arrêt minimal:** Le sharding garantit une haute disponibilité en fonctionnant sur une architecture de type "shared-nothing". Cette stratégie permet d'améliorer l'expérience des utilisateurs, car la défaillance d'une machine n'affecte pas les performances des autres.
La mise à jour des performances est plus efficace, car les développeurs peuvent mettre à jour séparément des machines individuelles sans arrêter l'ensemble du système.
Les défis du sharding de base de données
Bien que le sharding offre des avantages significatifs, les développeurs peuvent être confrontés à quelques défis qui augmentent la complexité de la mise en œuvre. La liste ci-dessous présente ces problèmes ainsi que des stratégies d'atténuation potentielles.
Distribution inégale:** L'incertitude concernant le volume et la variété des données peut entraîner l'apparition de points chauds. Malgré l'existence d'une clé de répartition efficace, la nature des données peut changer, ce qui oblige les développeurs à sélectionner ou à créer une nouvelle clé. Les développeurs doivent évaluer avec soin l'adéquation du sharding de base de données dans des scénarios spécifiques. Il est possible que la réplication ou la mise à l'échelle verticale soient plus pratiques que la mise en commun dans différentes situations.
La gestion de plusieurs machines est complexe car les développeurs doivent constamment surveiller l'état de santé de chaque nœud afin d'identifier et de résoudre rapidement les problèmes. Des systèmes de surveillance robustes dotés de mécanismes d'alerte en temps réel peuvent contribuer à atténuer ces problèmes en avertissant les équipes concernées en cas de défaillance d'un serveur.
Coûts de maintenance:** La maintenance de plusieurs serveurs sur site est coûteuse et nécessite du personnel supplémentaire possédant l'expertise nécessaire pour résoudre les problèmes lors de la maintenance. Les organisations peuvent migrer vers une [infrastructure en nuage] (https://zilliz.com/blog/zilliz-cloud-available-in-11-regions-across-3-major-cloud-providers) pour héberger différents serveurs et demander au fournisseur de nuage d'effectuer des contrôles de maintenance réguliers en arrière-plan.
Cas d'utilisation du sharding de base de données
Bien que les sections précédentes mettent brièvement en évidence les cas d'utilisation dans lesquels le sharding est bénéfique, la liste ci-dessous catégorise et explique ces scénarios de manière plus détaillée.
Applications Web à grande échelle:** Les sites de commerce électronique avec une base d'utilisateurs étendue, les plateformes de médias sociaux, les applications de covoiturage et les sites Web de jeux sont des candidats idéaux pour le sharding de base de données. Le sharding peut aider les administrateurs de ces sites à équilibrer la charge plus efficacement et à éviter les temps d'arrêt pendant les heures de pointe.
Pour les utilisateurs qui analysent des données volumineuses, le sharding peut aider à améliorer la vitesse de traitement en répartissant la charge sur plusieurs serveurs.
Réseaux de diffusion de contenu (CDN):** Un CDN est un groupe de serveurs répartis sur différents sites pour traiter les demandes des utilisateurs situés dans des zones géographiques proches. Les développeurs peuvent répartir les bases de données en fonction de la localisation des utilisateurs et distribuer les données sur ces serveurs afin d'accélérer les temps de réponse.
FAQ sur le partage de bases de données
- **Quelle est la différence entre le sharding et le partitionnement ?
Alors que le sharding et le partitionnement divisent les données en morceaux plus petits, le sharding distribue chaque morceau sur différentes machines ou nœuds. En revanche, le partitionnement stocke chaque morceau sur une seule machine.
- **Quelle est la différence entre le sharding et la réplication ?
La réplication copie l'intégralité de la base de données et la stocke sur différentes machines. Par rapport à la répartition, qui partitionne la base de données en lignes et stocke chaque morceau sur plusieurs serveurs, la réplication offre une plus grande disponibilité, mais nécessite davantage de ressources informatiques et de capacité de stockage.
- **Comment choisir la bonne clé de répartition ?
Le choix d'une clé de répartition appropriée exige des développeurs qu'ils déterminent la colonne adéquate pour diviser les données. Une clé de tri doit avoir une faible cardinalité et une fréquence égale.
La cardinalité fait référence au nombre maximal de briques possibles en fonction des valeurs de la colonne. Par exemple, la sélection d'une colonne contenant quatre valeurs distinctes donnera lieu à quatre tessons. La fréquence fait référence à la proportion de données que chaque nuage contient.
Par ailleurs, il convient de sélectionner ou de créer des fichiers qui restent statiques tout au long du cycle de vie de l'application. Les fichiers dont le volume de données est susceptible de changer peuvent donner lieu à des points chauds, certains fichiers recevant plus de volume que d'autres.
- **Quels sont les principaux défis posés par le sharding de base de données ?
La répartition des bases de données augmente la charge de travail liée aux requêtes, car les développeurs doivent écrire des requêtes pour accéder aux données de plusieurs machines afin d'effectuer des analyses.
Il augmente également les coûts d'infrastructure, car les entreprises doivent maintenir plusieurs serveurs et surveiller leur état pour éviter les pannes.
En outre, la mise à jour et le rééquilibrage des serveurs sont complexes si le volume et la variété des données augmentent. Une technique de répartition adaptée à une situation peut ne plus être pratique dans d'autres.
- **Le sharding de base de données est-il adapté aux petites applications ?
Bien que la répartition des bases de données soit une technique intéressante pour améliorer la vitesse de traitement et le débit, elle n'est pas adaptée aux petites applications. Elle n'est pratique à mettre en œuvre que lorsque le volume de données atteint un point tel qu'il devient insoutenable de maintenir une seule base de données sur un seul serveur.
Ressources connexes
Bien que les développeurs appliquent généralement le sharding aux ensembles de données structurées, les ressources suivantes vous aideront à comprendre le concept dans le contexte des [données non structurées] (https://zilliz.com/learn/introduction-to-unstructured-data) et des [bases de données vectorielles] (https://zilliz.com/learn/what-is-vector-database) :
Sharding, Partitioning, and Segments - Getting the Most From Your Database
[Qu'est-ce qu'un schéma dynamique ?] (https://zilliz.com/blog/what-is-dynamic-schema)
Déploiement de bases de données vectorielles dans des environnements multi-cloud
Anatomie d'un système de gestion de bases de données vectorielles natif du cloud](https://zilliz.com/blog/anatomy-of-a-cloud-native-vector-database-management-system)
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ? ](https://zilliz.com/learn/what-is-vector-database)
Qu'est-ce que RAG ? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Modèles d'IA les plus performants pour vos applications GenAI
- Qu'est-ce que le sharding de base de données ?
- Comment fonctionne le sharding de base de données ?
- Méthodes de partage
- Sélection d'une clé de dépôt
- Comparaison avec les autres solutions
- Avantages du sharding de base de données
- Les défis du sharding de base de données
- Cas d'utilisation du sharding de base de données
- FAQ sur le partage de bases de données
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement