





Qu'est-ce qu'un réseau neuronal convolutif ? Guide de l'ingénieur
Un [réseau neuronal convolutif] (https://zilliz.com/glossary/convolutional-neural-network) (CNN) est un modèle d'apprentissage profond conçu pour les données visuelles telles que les images, les vidéos et parfois même les fichiers audio.
Les CNN ont transformé des domaines tels que la [vision par ordinateur] (https://www.ibm.com/topics/computer-vision), l'analyse et le[ traitement] d'images (https://www.v7labs.com/blog/image-processing-guide), la [détection d'objets] (https://en.wikipedia.org/wiki/Object_detection) et même le [traitement du langage naturel (NLP)] (https://www.ibm.com/topics/natural-language-processing).
Les réseaux neuronaux traditionnels tels que les MLP (perceptron multicouche) ou les réseaux entièrement connectés traitent les données d'image comme des vecteurs plats, ce qui peut s'avérer limitatif lorsqu'il s'agit de traiter les informations spatiales présentes dans les données visuelles. Cela peut conduire à une faible précision en raison d'hypothèses erronées (biais inductif).
Les CNN résolvent ces problèmes en préservant la structure de l'image, telle que la connectivité locale et le contenu des pixels des données de l'image, ce qui les rend efficaces pour la reconnaissance des formes.
Ce billet met en évidence les avantages des CNN, explique leur architecture et donne un exemple simple de conception d'un modèle CNN.
Raisons clés pour l'utilisation d'un CNN
Les CNN excellent dans l'extraction de caractéristiques significatives à partir de données visuelles brutes, surpassant ainsi les réseaux neuronaux traditionnels. Les raisons d'utiliser un CNN sont les suivantes
Partage des paramètresUn CNN partage le même ensemble de paramètres entre différentes régions d'entrée, ce qui permet d'identifier efficacement les modèles cachés dans les données à haute dimension.
Nombre réduit de paramètres**-Les CNN utilisent la technique du pooling et de la convolution, ce qui réduit considérablement le nombre de paramètres par rapport aux réseaux entièrement connectés.
Apprentissage hiérarchique des caractéristiques**Un CNN imite la structure hiérarchique du système visuel humain.
Performances de pointe**-Les CNN sont toujours plus performants que les réseaux neuronaux traditionnels dans des tâches telles que la détection d'objets, le traitement d'images, la reconnaissance vocale et la segmentation d'images. Il convient de noter que les progrès récents dans le domaine de la vision par ordinateur ont introduit des [Transformateurs] (https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)) convolutifs et non-convolutifs.
Avantages et inconvénients des réseaux neuronaux convolutifs
Si les réseaux neuronaux convolutifs ont changé la donne en matière de vision par ordinateur, il convient d'en connaître les avantages et les inconvénients. Examinons les avantages et les inconvénients des réseaux neuronaux convolutifs :
Avantages des réseaux neuronaux convolutifs :
- Détection de motifs et de caractéristiques : Les réseaux neuronaux convolutifs sont excellents pour détecter des modèles et des caractéristiques dans les images, les vidéos et les signaux audio. Leur structure hiérarchique leur permet d'apprendre des caractéristiques complexes à partir de données brutes.
- Invariance aux transformations : Les CNN sont invariants à la translation, à la rotation et à l'échelle. Cela signifie qu'ils peuvent reconnaître des objets même s'ils se trouvent dans des positions, des orientations ou des tailles différentes dans une image.
- Extraction automatique des caractéristiques : Les CNN permettent un apprentissage de bout en bout, sans qu'il soit nécessaire de procéder à une extraction manuelle des caractéristiques. Le réseau apprend à trouver les caractéristiques pertinentes directement à partir des données d'entrée brutes.
- Évolutivité et précision : Les CNN peuvent traiter de grandes quantités de données et sont précis dans les tâches complexes. Plus les données sont nombreuses, plus leurs performances s'améliorent.
Inconvénients des réseaux neuronaux convolutifs :
Coût de calcul : La formation des réseaux neuronaux convolutifs est coûteuse en termes de calcul et nécessite beaucoup de mémoire. Cela peut être un défi à mettre en œuvre sans matériel spécialisé comme les GPU.
Ajustement excessif : S'ils ne disposent pas de suffisamment de données ou de [techniques de régularisation] appropriées (https://zilliz.com/learn/understanding-regularization-in-nueral-networks), les CNN peuvent s'adapter de manière excessive. Cela signifie qu'ils obtiennent de bons résultats sur les données d'apprentissage, mais qu'ils ne parviennent pas à s'adapter à de nouvelles données inédites.
Exigences en matière de données : Les CNN nécessitent de grandes quantités de données étiquetées pour la formation. Dans les domaines où les données étiquetées sont rares ou coûteuses à obtenir, cela peut constituer une limitation importante.
Interprétabilité : Il est difficile d'interpréter ce qu'un CNN a appris. La nature "boîte noire" des modèles d'apprentissage profond fait qu'il est difficile de comprendre le raisonnement derrière leurs prédictions, ce qui peut être un problème dans les applications sensibles.
Il est essentiel de comprendre ces avantages et ces inconvénients pour décider d'utiliser les CNN pour une tâche particulière et pour concevoir et mettre en œuvre des solutions basées sur les CNN.
Techniques de régularisation courantes dans les CNN
Comme nous l'avons mentionné dans les inconvénients, les CNN peuvent être enclins à un surajustement, en particulier lorsqu'ils travaillent avec des données limitées. Les techniques de régularisation sont utilisées pour empêcher les CNN de surajuster les données d'apprentissage, afin que le modèle puisse mieux se généraliser aux données non vues. Voici quelques techniques de régularisation couramment utilisées dans les CNN :
Abandon : Cette technique "élimine" de manière aléatoire (c'est-à-dire qu'elle met à zéro) certaines caractéristiques de sortie de la couche au cours de la formation. L'abandon oblige le réseau à apprendre des caractéristiques plus robustes qui ne dépendent pas d'un seul neurone. Ce faisant, le réseau devient moins sensible aux poids spécifiques des neurones, ce qui se traduit par une meilleure généralisation. Lors des tests, tous les neurones sont utilisés, mais leurs sorties sont réduites pour compenser les neurones manquants lors de la formation.
Régularisation L1 : Également connue sous le nom de régularisation Lasso, la régularisation L1 ajoute un terme de pénalité à la fonction de perte qui est proportionnel à la valeur absolue des poids. Cette technique encourage la rareté dans le modèle en poussant certains poids à zéro. La régularisation L1 est utile lorsque vous souhaitez créer un modèle plus simple en supprimant les caractéristiques les moins importantes.
Régularisation L2 : Également connue sous le nom de régularisation Ridge, la régularisation L2 ajoute un terme de pénalité à la fonction de perte qui est proportionnel au carré des poids. Cette technique décourage les poids importants et répartit les valeurs de poids de manière plus uniforme. La régularisation L2 n'aboutit pas à des modèles clairsemés comme L1, mais elle peut contribuer à réduire l'impact des caractéristiques les moins pertinentes.
L1 et L2 peuvent toutes deux réduire le nombre de poids et rendre le réseau plus efficace. Le choix entre L1 et L2 (ou une combinaison des deux, connue sous le nom de régularisation Elastic Net) dépend du problème et de l'ensemble de données.
Ces techniques de régularisation, lorsqu'elles sont utilisées correctement, permettent de résoudre l'un des plus grands problèmes actuels de l'apprentissage profond et de l'apprentissage automatique.
L'architecture d'un réseau de neurones et son fonctionnement
Un CNN possède de grandes capacités, ce qui permet à ces réseaux de trouver des modèles cachés et de déchiffrer des données visuelles avec une précision exceptionnelle.
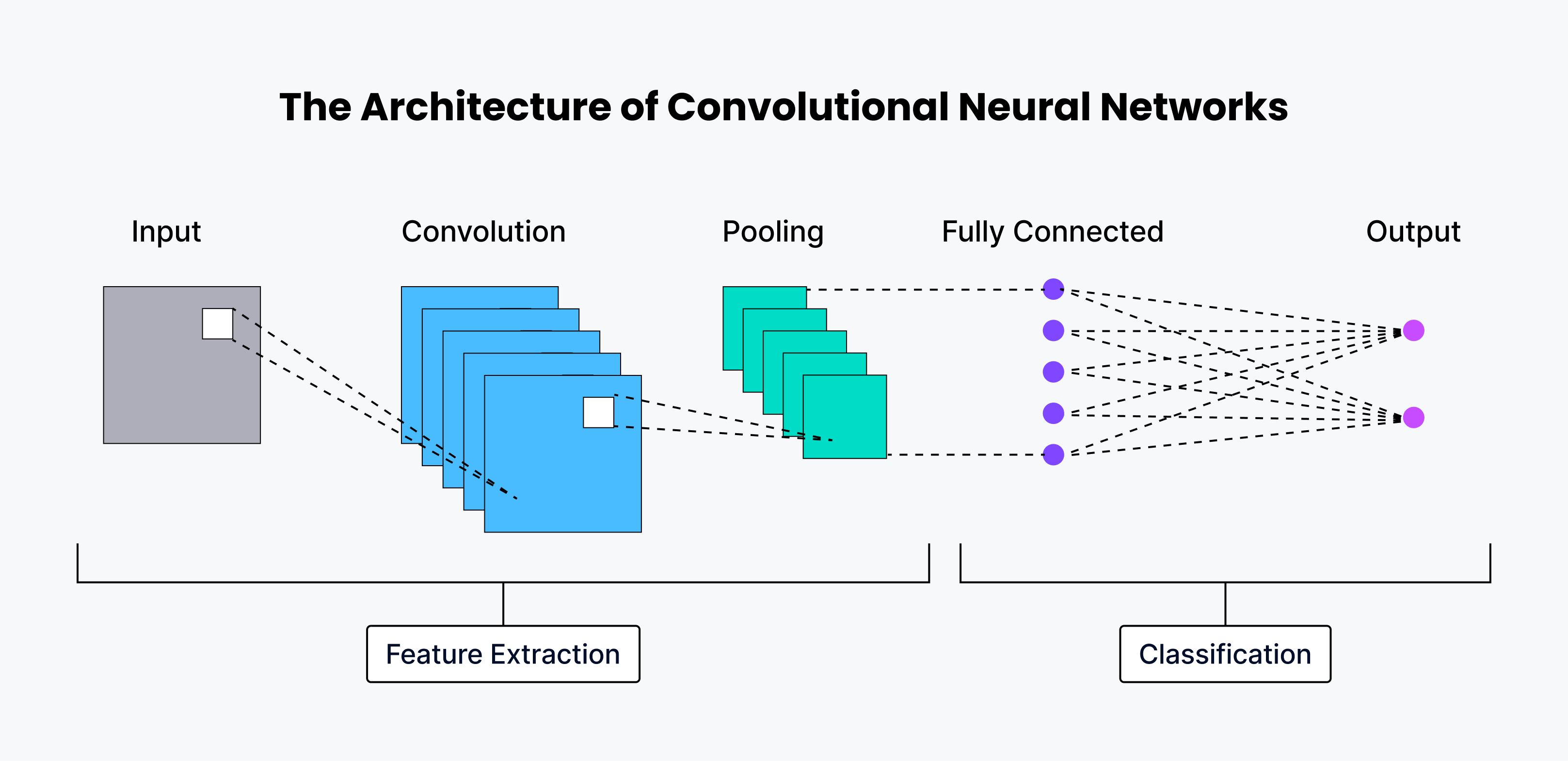
Le système neuronal humain comporte plusieurs couches, chacune d'entre elles étant chargée d'exécuter une fonction unique. Les CNN ont une architecture similaire, chaque couche extrayant différentes caractéristiques de l'image d'entrée. Vous trouverez ci-dessous une explication détaillée de toutes les couches impliquées dans l'architecture du CNN.
Les premières couches sont des couches de convolution, chargées d'extraire les caractéristiques de base de l'image, telles que les bords et la forme.
Les couches suivantes sont des couches de mise en commun, qui constituent la couche de sortie chargée de réduire la taille des [cartes de caractéristiques] (https://www.baeldung.com/cs/cnn-feature-map).
Enfin, la dernière couche est la couche entièrement connectée (FC), qui est chargée de classer l'image dans l'une des catégories données.
Presque toutes les architectures convolutives pures modernes ne comportent qu'une couche de mise en commun globale à la fin, suivie d'une couche entièrement connectée.
Couche de convolution
La couche de convolution est le cœur d'un CNN, conçu pour trouver des modèles distinctifs dans les données d'entrée. Elle prend l'image d'entrée et applique un ensemble de filtres pour produire une sortie appelée carte de caractéristiques. Les filtres sont de petites matrices de poids qui parcourent l'image d'entrée pour identifier différents motifs. Lorsque le filtre se déplace sur l'image, il le fait par étapes définies par le stride - le nombre de pixels que le filtre déplace à chaque étape. Parfois, le remplissage est utilisé pour contrôler la taille de la sortie en ajoutant des pixels supplémentaires autour de l'entrée. Il existe différents types de remplissage, notamment le remplissage valide, le remplissage nul (pas de remplissage), le remplissage identique (la taille de la sortie est égale à celle de l'entrée) et le remplissage complet (qui augmente la taille de la sortie). Après l'opération de convolution, une fonction d'activation non linéaire, généralement ReLU (Rectified Linear Unit), est appliquée pour introduire la non-linéarité dans le modèle.
Plus de couches convolutives
Comme nous l'avons mentionné précédemment, une autre couche convolutive peut venir après la première couche convolutive. Dans ce cas, le CNN devient hiérarchique, car les couches ultérieures peuvent voir les pixels situés dans les champs réceptifs des couches précédentes. Cette structure hiérarchique permet aux couches cachées du réseau d'apprendre des caractéristiques plus complexes au fur et à mesure que les données circulent dans les couches.
Supposons que nous voulions reconnaître un visage humain dans une image. On peut considérer qu'un visage est une composition de diverses caractéristiques. Il s'agit des yeux, du nez, de la bouche, des sourcils, etc. Chaque caractéristique individuelle du visage est un modèle de niveau inférieur dans le réseau neuronal et la combinaison de ces caractéristiques est un modèle de niveau supérieur, une hiérarchie de caractéristiques dans le cortex visuel du CNN.
Dans la première couche convolutive, le réseau peut apprendre à détecter des caractéristiques simples telles que les bords, les courbes et les formes de base. Il peut s'agir du contour des traits du visage ou du contraste entre différentes parties du visage.
La deuxième couche de classification d'images peut combiner ces caractéristiques de base pour reconnaître des formes plus complexes. Par exemple, elle peut détecter des formes circulaires (peut-être des yeux) ou des lignes courbes (peut-être le contour de la bouche ou des sourcils).
Dans les couches suivantes, le réseau pourrait commencer à reconnaître des caractéristiques faciales entières en combinant les modèles des couches précédentes. Un neurone peut se déclencher lorsqu'il détecte une structure semblable à celle des yeux, un autre lorsqu'il détecte une structure semblable à celle du nez.
Dans les dernières couches, le CNN combine toutes ces caractéristiques faciales pour reconnaître un visage complet. À ce stade, le réseau ne se contente pas de détecter des caractéristiques individuelles, mais comprend comment ces caractéristiques sont liées les unes aux autres dans le contexte d'un visage.
Enfin, les couches convolutives convertissent l'image en valeurs numériques afin que le réseau neuronal puisse interpréter les images d'entrée et extraire des modèles à différents niveaux d'abstraction. Cet apprentissage hiérarchique des caractéristiques est l'un des principaux atouts des réseaux neuronaux nationaux dans les tâches de reconnaissance d'images, pour comprendre des objets complexes à composantes multiples comme les visages.
Couche de mise en commun
Après la couche de convolution, on trouve souvent une couche de mise en commun. L'objectif de cette couche de mise en commun (sous-échantillonnage) est de réduire la taille des cartes de caractéristiques tout en préservant les caractéristiques les plus importantes. Cela permet de réduire la complexité des calculs et de contrôler l'adaptation excessive. Il existe deux techniques de pooling courantes : le pooling max, qui prend la valeur maximale d'une petite région de la carte de caractéristiques, et le pooling average, qui prend la valeur moyenne d'une petite région.
Couche entièrement connectée (FC)
La dernière couche d'un CNN est généralement une couche entièrement connectée qui classifie la sortie du CNN. Cette couche est similaire à une couche de réseau neuronal traditionnelle, se connectant à tous les neurones de la couche précédente. Elle utilise les caractéristiques de haut niveau apprises par les couches convolutives pour effectuer la tâche finale de classification ou de régression.
 The-Architecture-of-Convolutional-Neural-Networks.png
The-Architecture-of-Convolutional-Neural-Networks.png
Terminologie essentielle
Lorsque l'on travaille avec des CNN, il est important de comprendre certains termes essentiels. Une époque correspond à un passage complet dans l'ensemble des données d'apprentissage. L'exclusion est une technique utilisée pour éviter l'ajustement excessif en éliminant aléatoirement des neurones au cours du processus de formation. La profondeur stochastique est une autre méthode qui raccourcit le réseau pendant la formation en éliminant de manière aléatoire les blocs résiduels.
Pas - Il s'agit d'une taille de pas que le filtre prend pendant l'opération de convolution.
Padding - Le padding dans le CNN consiste à ajouter des zéros autour des bords de l'image afin de préserver sa dimension spatiale après la convolution. Cela permet d'éviter que l'image ne rétrécisse et de prévenir la perte d'informations après chaque opération de convolution.
Période - Un passage complet dans l'ensemble des données d'apprentissage.
**La régularisation (dropout) est une technique qui permet d'éviter l'ajustement excessif en supprimant aléatoirement des neurones pendant la formation, ce qui oblige le réseau à apprendre plutôt qu'à s'appuyer sur un plus grand nombre de neurones.
Profondeur stochastique - Raccourcit le réseau pendant la formation en éliminant les blocs résiduels de manière aléatoire et en contournant leurs transformations par des connexions sautées. Pendant ce temps, au moment des tests, l'ensemble du réseau est utilisé pour faire des prédictions. Il en résulte une amélioration de l'erreur de test et une réduction significative du temps de formation.
Types de réseaux neuronaux convolutifs
L'histoire et le développement des réseaux neuronaux convolutifs remontent à plusieurs décennies et de nombreux chercheurs y ont contribué. Comprendre cette histoire vous aidera à comprendre l'état actuel des réseaux neuronaux convolutifs.
Base historique
Kunihiko Fukushima a jeté les bases des CNN en 1980 avec ses travaux sur le "Neocognitron", un réseau neuronal artificiel hiérarchique à plusieurs couches. Ce premier modèle pouvait apprendre à reconnaître des formes visuelles robustes.
Yann LeCun a apporté une autre contribution importante en 1989 avec son article "Backpropagation Applied to Handwritten Zip Code Recognition" (rétropropagation appliquée à la reconnaissance de codes postaux manuscrits). LeCun a appliqué la rétropropagation pour entraîner des réseaux neuronaux à reconnaître des motifs dans des codes postaux manuscrits. Il s'agissait d'un grand pas vers les applications pratiques des réseaux neuronaux.
LeNet-5 : l'architecture CNN originale
LeCun et son équipe ont continué à travailler sur cette architecture tout au long des années 1990 et ont finalement mis au point LeNet-5 en 1998. LeNet-5 a appliqué les principes des travaux antérieurs à la reconnaissance de documents. Il est considéré comme l'architecture CNN originale et la base de tous les travaux futurs.
Évolution des architectures CNN
Depuis LeNet-5, de nombreuses variantes d'architectures CNN ont été développées. De nouveaux ensembles de données tels que MNIST et CIFAR-10 et des concours tels que ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ont été à l'origine de la plupart de ces innovations. Voici quelques-unes des architectures CNN les plus remarquables qui ont été développées :
AlexNet : Développé par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton, AlexNet a remporté l'ILSVRC 2012. Il était plus profond et plus large que les CNN précédents, utilisait les activations ReLU et le dropout pour la régularisation.
VGGNet : Développé par le Visual Geometry Group à Oxford, VGGNet est connu pour sa simplicité et sa profondeur. Il utilise de petits filtres convolutifs 3x3 dans l'ensemble du réseau.
GoogLeNet (Inception) : Développé par Google, il a introduit le module "Inception" qui permet un calcul plus efficace et des réseaux plus profonds.
ResNet : Développé par Microsoft Research, ResNet a introduit le saut de connexion et a permis la formation de réseaux beaucoup plus profonds (jusqu'à 152 couches dans l'article original).
ZFNet : Amélioration d'AlexNet, ZFNet (du nom de ses créateurs Zeiler et Fergus) a remporté l'ILSVRC 2013 en ajustant les hyperparamètres de l'architecture.
Chacune de ces architectures a apporté des innovations qui ont repoussé les limites de ce qui était possible avec les CNN, améliorant les performances dans diverses tâches de vision par ordinateur.
Comment concevoir un réseau neuronal à convolution
Lors de la conception d'un CNN, plusieurs décisions clés doivent être prises. Il s'agit notamment de choisir la taille de l'entrée, de déterminer le nombre de couches de convolution, de sélectionner la taille et le nombre de filtres par couche d'entrée, de choisir la méthode de mise en commun, de décider du nombre de couches entièrement connectées et de sélectionner les fonctions d'activation. Chacun de ces choix peut avoir un impact significatif sur les performances et l'efficacité du réseau.
Choisir la taille de l'entrée-La taille de l'entrée représente la taille d'une image sur laquelle le CNN sera entraîné. La taille d'entrée doit être suffisamment grande pour que le réseau soit capable d'extraire les caractéristiques d'un objet qu'il cherche à classifier.
Choisissez le nombre de couches de convolution - Cela détermine le nombre de caractéristiques que le réseau sera capable d'apprendre. Un plus grand nombre de couches de convolution lui permet d'apprendre des caractéristiques plus complexes, mais le temps de calcul augmente.
Choisir la taille du filtre-La taille du filtre, ainsi que le pas de convolution, détermine la taille des caractéristiques qui seront extraites des images. Un filtre de plus grande dimension permettra d'extraire un plus grand nombre de caractéristiques.
Choisir le nombre de filtres par couche-Cela détermine le nombre de caractéristiques différentes qui peuvent être extraites d'une image.
Choisir la méthode de pooling-Les deux techniques de pooling les plus courantes sont le pooling max et le pooling average. Le pooling max prend la valeur maximale d'une petite région de la carte des caractéristiques, tandis que le pooling average prend la valeur moyenne d'une petite région de la carte des caractéristiques.
Choisissez le nombre de couches entièrement connectées - Cela détermine le nombre de classes que le réseau peut classer.
Choisissez la fonction d'activation-La [fonction d'activation] (https://zilliz.com/learn/class-activation-mapping-CAM) permet l'apprentissage de modèles plus complexes à partir de l'ensemble de données d'images. Pour la classification binaire, il est normal d'utiliser la fonction sigmoïde. Dans un problème de classification multi-classes, la couche FC utilise la [fonction d'activation softmax] (https://zilliz.com/learn/decoding-softmax-understanding-functions-and-impact-in-ai). Pour introduire la non-linéarité dans les données, les gens utilisent principalement les [fonctions d'activation] GeLU ou Swish(https://zilliz.com/glossary/activation-functions) de nos jours.
Vous trouverez ci-dessous un exemple simple de mise en œuvre d'un CNN avec Python pour classer les panneaux de signalisation. Trouvez l'ensemble de données [sur le site Web de Kaggle] (https://www.kaggle.com/datasets/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign).
Mise en œuvre simple d'un CNN avec PyTorch
Pour mettre en œuvre un modèle CNN en Python, utilisez des frameworks tels que PyTorch, TensorFlow, Keras, etc. Ces frameworks fournissent l'implémentation de toutes les couches nécessaires à un CNN.
Le processus commence par l'importation des modules nécessaires comme suit :
# dépendances pour le calcul
import pandas as pd
import numpy as np
# dépendances pour la lecture et l'affichage des images
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib inline
# dépendance pour créer un ensemble de validation
from sklearn.model_selection import train_test_split
# dépendance pour évaluer le modèle
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# bibliothèques et modules PyTorch
import torch
from torch.autograd import Variable
from torch.nn import (Linear, ReLU, CrossEntropyLoss,
séquentiel, Conv2d, MaxPool2d, Module,
Softmax, BatchNorm2d, Dropout)
from torch.optim import Adam, SGD
Une fois que c'est fait, chargez le jeu de données et les images avec le code suivant :
# chargement du jeu de données
train = pd.read_csv('Data/train.csv')
# chargement des images d'entraînement
train_img = []
for img_name in tqdm(train['Path']) :
# définition du chemin d'accès à l'image
image_path = 'Data/' + str(img_name)
# lecture de l'image
img = imread(chemin_image, as_gray=True)
# redimensionner l'image
img = resize(img, (28, 28))
# normalisation des valeurs des pixels
img /= 255.0
# conversion du type de pixel en flottant 32
img = img.astype('float32')
# introduire l'image dans la liste
train_img.append(img)
# convertir la liste en tableau numpy
train_x = np.array(train_img)
# définir la cible
train_y = train['ClassId'].values
train_x.shape
Une fois les données d'entraînement chargées, vous devrez créer un jeu de données d'entraînement et de validation en utilisant la méthode train_test_split() de sklearn.
# créer l'ensemble de validation
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# Vérifier les formes des ensembles de formation et de validation
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
Vous devrez également remodeler les données pour le modèle Torch comme suit :
# conversion des images d'entraînement au format Torch
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# conversion de la cible au format torch
train_y = train_y.astype(int) ;
train_y = torch.from_numpy(train_y)
# conversion des images de validation au format torch
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# conversion de la cible au format torch
val_y = val_y.astype(int) ;
val_y = torch.from_numpy(val_y)
Définissez ensuite les différentes couches d'un CNN comme suit :
classe Net(Module) :
def __init__(self) :
super(Net, self).__init__()
self.cnn_layers = Sequential(
# Définition d'une couche de convolution 2D
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Définition d'une autre couche de convolution 2D
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# couche dense finale pour la prédiction
self.linear_layers = Sequential(
Linéaire(4 * 7 * 7, 43)
)
# Définition de la passe avant
def forward(self, x) :
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
Retourne x
Le réseau CNN ci-dessus comporte deux couches de convolution suivies d'une couche de mise en commun maximale avec des dimensions spatiales de 2 par 2.
Une couche d'aplatissement peut aider à classer les couches cachées de l'image du panneau dans des classes respectives.
Décidons ensuite de l'optimiseur et de la fonction de perte et définissons la procédure d'apprentissage.
# définition du modèle
modèle = Net()
# définition de l'optimiseur
optimiseur = Adam(model.parameters(), lr=0.07)
# définition de la fonction de perte
criterion = CrossEntropyLoss()
# vérification de la disponibilité du GPU
if torch.cuda.is_available() :
modèle = modèle.cuda()
criterion = criterion.cuda()
print(modèle)
def train(epoch) :
model.train()
tr_loss = 0
# obtention de l'ensemble d'entraînement
x_train, y_train = Variable(train_x), Variable(train_y)
# obtention de l'ensemble de validation
x_val, y_val = Variable(val_x), Variable(val_y)
# conversion des données au format GPU
if torch.cuda.is_available() :
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# efface les gradients des paramètres du modèle
optimizer.zero_grad()
# prédiction pour les ensembles d'entraînement et de validation
output_train = model(x_train)
output_val = model(x_val)
# calcul de la perte de l'ensemble d'entraînement et de validation
loss_train = criterion(output_train, y_train)
perte_val = critère(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# rétropropagation et mise à jour des paramètres du modèle
loss_train.backward()
optimiseur.step()
tr_loss = loss_train.item()
if epoch%2 == 0 :
# impression de la perte de validation
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
Enfin, entraînez le modèle pour 25 époques sur les données d'entraînement comme suit :
# définir le nombre d'époques
n_epochs = 25
# liste vide pour stocker les pertes d'entraînement
train_losses = []
# liste vide pour stocker les pertes de validation
val_losses = []
# entraînement du modèle
for epoch in range(n_epochs) :
train(epoch)
Au final, chaque modèle sera là pour faire des prédictions sur les données de test. Pour plus de détails, référez-vous à ce blog pour [comment écrire des CNNs à partir de rien dans PyTorch] (https://blog.paperspace.com/writing-cnns-from-scratch-in-pytorch/).
FAQs
Quelle est la différence entre CNN et Deep Neural Networks?
Un CNN est un type de réseau neuronal capable de traiter des données visuelles telles que des images, des discours, des vidéos, etc., tandis que les réseaux neuronaux profonds (DNN) sont un type de réseau neuronal artificiel capable d'apprendre des modèles complexes à partir de données.
Voici les principales différences entre les CNN et les DNN.
Un CNN possède une architecture spécifique pour le traitement des images. En revanche, un DNN n'a pas d'architecture spécifique et peut fonctionner pour une variété de tâches.
Un CNN apprend les caractéristiques des images en utilisant des couches de convolution, tandis qu'un DNN apprend les caractéristiques à l'aide de différents [types de couches] (https://www.geeksforgeeks.org/deep-neural-network-with-l-layers/).
Un CNN est plus difficile à former, nécessite plus de données et est plus coûteux en termes de calcul qu'un DNN.
Quelles sont les trois couches d'un CNN?
Les trois couches d'un CNN sont la couche d'activation, la couche de convolution, la couche de mise en commun et la couche entièrement connectée.
Couche de convolution : Cette couche est chargée d'extraire les caractéristiques des images. Elle fonctionne en balayant les images à l'aide d'un filtre, qui est une petite matrice de poids. Le filtre se déplace sur l'image et les poids sont multipliés par les valeurs des pixels de l'image. Enfin, elle produit une carte contenant les caractéristiques extraites.
Couche de mise en commun**-La couche de mise en commun réduit la taille des cartes de caractéristiques. Pour ce faire, deux techniques de pooling courantes sont le pooling max et le pooling average.
Couche entièrement connectée** - Il s'agit de la même chose que les réseaux neuronaux traditionnels qui classifient la sortie du CNN. Les neurones des couches entièrement connectées classent ensuite l'image dans un ensemble de classes.
Qu'est-ce qu'un réseau neuronal convolutif dans l'apprentissage profond ?
Un réseau neuronal convolutif est un type de réseau neuronal profond qui traite les images, les discours et les vidéos afin que vous puissiez les utiliser pour faire des prédictions réelles sur les données structurées/[non structurées] (https://zilliz.com/blog/introduction-to-unstructured-data) dans le monde numérique en pleine croissance.
Un CNN permet de prédire facilement et efficacement les émotions, les comportements, les intérêts, les goûts, etc. de l'être humain.
- **Raisons clés pour l'utilisation d'un CNN**
- Avantages et inconvénients des réseaux neuronaux convolutifs
- Techniques de régularisation courantes dans les CNN
- **L'architecture d'un réseau de neurones et son fonctionnement**
- Types de réseaux neuronaux convolutifs
- **Comment concevoir un réseau neuronal à convolution**
- **Mise en œuvre simple d'un CNN avec PyTorch**
- **FAQs**
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement