




Construire RAG avec Milvus, vLLM, et Llama 3.1
L'Université de Californie - Berkeley a fait don de vLLM, une bibliothèque rapide et facile à utiliser pour l'inférence et le service LLM, à la LF AI & Data Foundation en tant que projet en phase d'incubation en juillet 2024. En tant que projet membre, nous souhaitons la bienvenue à vLLM qui rejoint la famille LF AI & Data ! 🎉
Les grands modèles de langage (LLM) et les bases de données vectorielles sont généralement associés pour construire Retrieval Augmented Generation (RAG), une architecture d'application d'IA populaire pour répondre aux Hallucinations de l'IA. Ce blog vous montrera comment construire et exécuter une RAG avec Milvus, vLLM et Llama 3.1. Plus précisément, je vous montrerai comment intégrer et stocker des informations textuelles sous forme de [vector embeddings] (https://zilliz.com/glossary/vector-embeddings) dans Milvus et utiliser ce stockage vectoriel comme base de connaissances pour récupérer efficacement des morceaux de texte pertinents pour les questions de l'utilisateur. Enfin, nous utiliserons vLLM pour servir le modèle Llama 3.1-8B de Meta afin de générer des réponses enrichies par le texte récupéré. Allons-y, plongeons !
Introduction à Milvus, vLLM et Meta's Llama 3.1
Base de données vectorielles Milvus
Milvus** est une base de données vectorielles distribuée à code source ouvert, conçue à cet effet, qui permet de stocker, d'indexer et de rechercher des vecteurs pour les charges de travail d'IA générative (GenAI). Sa capacité à effectuer des recherches hybrides, filtrage des métadonnées, des reclassements et à gérer efficacement des trillions de vecteurs fait de Milvus un choix incontournable pour les charges de travail d'IA et d'apprentissage automatique. Milvus peut être exécuté localement, sur un cluster ou hébergé dans le Zilliz Cloud entièrement géré.
vLLM
vLLM est un projet open-source lancé au SkyLab de l'université de Berkeley et axé sur l'optimisation des performances de service LLM. Il utilise une gestion efficace de la mémoire avec PagedAttention, une mise en lots continue et des noyaux CUDA optimisés. Par rapport aux méthodes traditionnelles, vLLM améliore les performances de service jusqu'à 24 fois tout en réduisant de moitié l'utilisation de la mémoire du GPU.
Selon l'article "[Efficient Memory Management for Large Language Model Serving with PagedAttention] (https://arxiv.org/abs/2309.06180)", le cache KV utilise environ 30 % de la mémoire du GPU, ce qui peut entraîner des problèmes de mémoire. Le cache KV est stocké dans une mémoire contiguë, mais une modification de sa taille peut entraîner une fragmentation de la mémoire, ce qui est inefficace pour les calculs.

Image 1. Gestion de la mémoire cache KV dans les systèmes existants (2023 Paged Attention_ paper)
En utilisant la mémoire virtuelle pour le cache KV, vLLM n'alloue la mémoire physique du GPU qu'en cas de besoin, éliminant ainsi la fragmentation de la mémoire et évitant la pré-allocation. Lors des tests, vLLM a surpassé HuggingFace Transformers (HF) et Text Generation Inference (TGI), atteignant un débit jusqu'à 24 fois plus élevé que HF et 3,5 fois plus élevé que TGI sur les GPU NVIDIA A10G et A100.
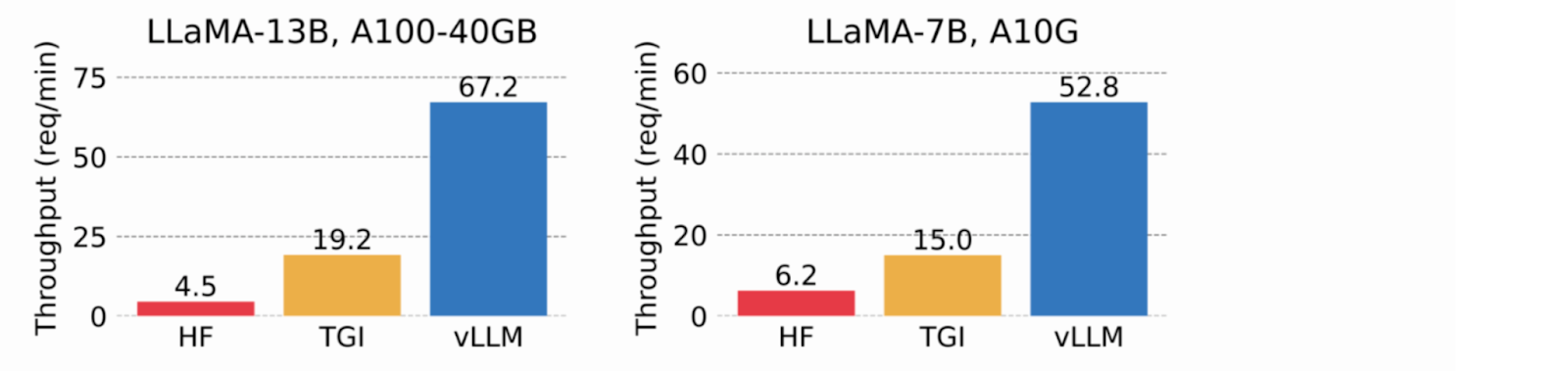
Image 2. Débit de service lorsque chaque requête demande trois sorties parallèles. vLLM atteint un débit 8,5x-15x plus élevé que HF et 3,3x-3,5x plus élevé que TGI (2023_ vLLM blog).
Le lama de Meta 3.1
Meta's Llama 3.1 a été annoncé le 23 juillet 2024. Le modèle 405B offre des performances de pointe sur plusieurs benchmarks publics et dispose d'une fenêtre contextuelle de 128 000 jetons d'entrée avec diverses utilisations commerciales autorisées. Parallèlement au modèle à 405 milliards de paramètres, Meta a publié une version mise à jour du Llama3 70B (70 milliards de paramètres) et 8B (8 milliards de paramètres). Les poids des modèles peuvent être téléchargés [sur le site web de Meta] (https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
L'une des principales conclusions est qu'un réglage fin des données générées peut améliorer les performances, mais que des exemples de mauvaise qualité peuvent les dégrader. L'équipe Llama a beaucoup travaillé pour identifier et supprimer ces mauvais exemples en utilisant le modèle lui-même, des modèles auxiliaires et d'autres outils.
Construire et exécuter le RAG-Retrieval avec Milvus
Préparez votre ensemble de données
J'ai utilisé la [documentation Milvus] officielle (https://milvus.io/docs/) comme ensemble de données pour cette démo, que j'ai téléchargée et sauvegardée localement.
from langchain.document_loaders import DirectoryLoader
# Charge les fichiers HTML déjà sauvegardés dans un répertoire local
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(path=path, glob=global_pattern)
docs = loader.load()
# Imprimer les documents num et un aperçu.
print(f "chargé {len(docs)} documents")
print(docs[0].page_content)
pprint.pprint(docs[0].metadata)
 loaded 22 docs
loaded 22 docs
Télécharger un modèle d'intégration
Ensuite, téléchargez un [modèle d'intégration] (https://zilliz.com/ai-models) libre et gratuit à partir de HuggingFace.
import torch
from sentence_transformers import SentenceTransformer
# Initialiser les paramètres de torch pour le code agnostique.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Télécharger le modèle depuis le hub de modèles de huggingface.
nom_du_modèle = "BAAI/bge-large-fr-v1.5"
encoder = SentenceTransformer(model_name, device=DEVICE)
# Obtenir les paramètres du modèle et les sauvegarder pour plus tard.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Inspecter les paramètres du modèle.
print(f "nom_du_modèle : {nom_du_modèle}")
print(f "EMBEDDING_DIM : {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH : {MAX_SEQ_LENGTH}")

Réunir et encoder vos données personnalisées sous forme de vecteurs.
J'utiliserai une longueur fixe de 512 caractères avec un chevauchement de 10%.
from langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size : {CHUNK_SIZE}, chunk_overlap : {chunk_overlap}")
# Définir le séparateur.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap)
# Découper les documents en morceaux.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} docs split into {len(chunks)} child documents.")
# L'entrée de l'encodeur est doc.page_content sous forme de chaînes.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')]
# Inférence d'intégration utilisant l'encodeur HuggingFace.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Normaliser les embeddings.
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus attend une liste de `numpy.ndarray` de nombres `numpy.float32`.
valeurs_converties = list(map(np.float32, embeddings))
# Créer une dict_list pour l'insertion dans Milvus.
dict_list = []
for chunk, vector in zip(chunks, converted_values) :
# Assembler le vecteur d'intégration, le morceau de texte original, les métadonnées.
chunk_dict = {
'chunk' : chunk.page_content,
'source' : chunk.metadata.get('source', ""),
'vector' : vector,
}
dict_list.append(chunk_dict)

Sauvegarder les vecteurs dans Milvus
Intégrez le vecteur encodé dans la base de données vectorielles Milvus.
# Connecter un client au serveur Milvus Lite.
from pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Créer une collection avec un schéma flexible et un AUTOINDEX.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
# Insérer les données dans la collection Milvus.
print("Start inserting entities")
start_time = time.time()
mc.insert(
NOM_DE_LA_COLLECTION,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f "Milvus insert time for {len(dict_list)} vectors : ", end="")
print(f"{round(end_time - start_time, 2)} secondes")

Effectuer une recherche vectorielle
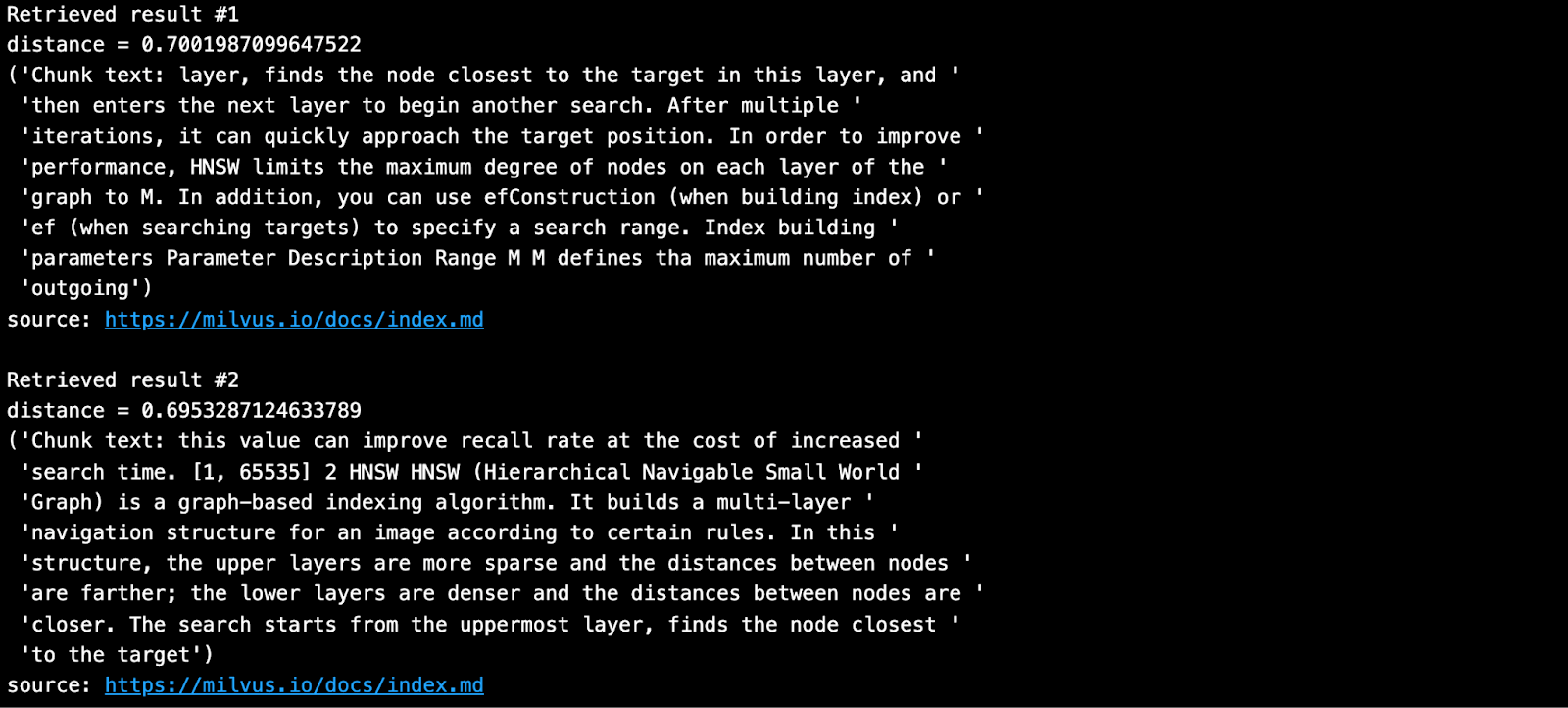
Posez une question et recherchez les morceaux les plus proches de votre base de connaissances dans Milvus.
SAMPLE_QUESTION = "Que signifient les paramètres de HNSW ?"
# Encoder la question en utilisant le même encodeur.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Normaliser les embeddings à une longueur unitaire.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# Convertir les embeddings en liste de np.float32.
query_embeddings = list(map(np.float32, query_embeddings))
# Définir les champs de métadonnées sur lesquels vous pouvez filtrer.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# Définissez le nombre de résultats top-k que vous souhaitez récupérer.
TOP_K = 2
# Lancez une recherche vectorielle sémantique en utilisant votre requête et la base de données vectorielle.
results = mc.search(
NOM_DE_LA_COLLECTION,
data=requête_embeddings,
output_fields=OUTPUT_FIELDS,
limit=TOP_K,
consistency_level="Eventually")
Le résultat obtenu est le suivant.
Construire et réaliser la génération RAG avec vLLM et Llama 3.1-8B
Installer vLLM et les modèles de HuggingFace
Par défaut, vLLM télécharge de grands modèles linguistiques à partir de HuggingFace. En général, chaque fois que vous voulez utiliser un nouveau modèle sur HuggingFace, vous devez faire un pip install--update ou -U. De plus, vous aurez besoin d'un GPU pour exécuter l'inférence des modèles Llama 3.1 de Meta avec vLLM.
Pour une liste complète de tous les modèles supportés par vLLM, voir cette [page de documentation] (https://docs.vllm.ai/en/latest/models/supported_models.html#supported-models).
# (Recommandé) Créer un nouvel environnement conda.
conda create -n myenv python=3.11 -y
conda activate myenv
# Installer vLLM avec CUDA 12.1.
pip install -U vllm transformers torch
import vllm, torch
from vllm import LLM, SamplingParams
# Vider le cache mémoire du GPU.
torch.cuda.empty_cache()
# Vérifier le GPU.
!nvidia-smi
Pour en savoir plus sur l'installation de vLLM, consultez la page installation.
Obtenir un jeton HuggingFace
Certains modèles sur HuggingFace, comme Meta Llama 3.1, exigent que l'utilisateur accepte leur licence avant de pouvoir télécharger les poids. Par conséquent, vous devez créer un compte HuggingFace, accepter la licence du modèle et générer un jeton.
Lorsque vous visitez cette page Llama3.1 sur HuggingFace, vous recevrez un message vous demandant d'accepter les conditions. Cliquez sur "Accept License" pour accepter les termes de Meta avant de télécharger les poids modèles. L'approbation prend généralement moins d'un jour.
Après avoir reçu l'approbation, vous devez générer un nouveau jeton HuggingFace. Vos anciens jetons ne fonctionneront pas avec les nouvelles autorisations.
Avant d'installer vLLM, connectez-vous à HuggingFace avec votre nouveau jeton. Ci-dessous, j'ai utilisé Colab secrets pour stocker le jeton.
# Connectez-vous à HuggingFace en utilisant votre nouveau jeton.
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Exécuter la génération RAG
Dans la démo, nous exécutons le modèle Llama-3.1-8B, qui nécessite un GPU et une mémoire importante pour tourner. L'exemple suivant a été exécuté sur Google Colab Pro (10$/mois) avec un GPU A100. Pour en savoir plus sur l'utilisation de vLLM, vous pouvez consulter la [documentation de démarrage rapide] (https://docs.vllm.ai/en/latest/getting_started/quickstart.html).
# 1. Choisissez un modèle
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# 2. Videz le cache mémoire du GPU, vous allez avoir besoin de tout !
torch.cuda.empty_cache()
# 3. Instanciez une instance de modèle vLLM.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Rédigez une invite en utilisant les contextes et les sources extraites de Milvus.
# Séparez tous les contextes par un espace.
contexts_combinés = ' '.join(contextes)
# Lance Martin, LangChain, dit de mettre les meilleurs contextes à la fin.
contexts_combinés = ' '.join(reversed(contexts))
# Séparez toutes les sources uniques par une virgule.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""Tout d'abord, vérifiez si le contexte fourni est pertinent pour la question de l'utilisateur.
à la question de l'utilisateur. Ensuite, seulement si le contexte fourni est fortement pertinent, répondez à la question en utilisant le contexte. Dans le cas contraire, si le contexte n'est pas très pertinent, répondez à la question sans utiliser le contexte.
Soyez clair, concis et pertinent. Répondez clairement, en moins de 2 phrases.
Sources d'ancrage : {source_combined}
Contexte : {contextes_combinés}
Question de l'utilisateur : {SAMPLE_QUESTION}
"""
invites = [SYSTEM_PROMPT]
Maintenant, générez une réponse en utilisant les morceaux récupérés et la question originale insérée dans l'invite.
# Paramètres d'échantillonnage
sampling_params = SamplingParams(temperature=0.2, top_p=0.95)
# Invoquer le modèle vLLM.
outputs = llm.generate(prompts, sampling_params)
# Imprimer les sorties.
pour output dans outputs :
prompt = output.prompt
generated_text = output.outputs[0].text
# !r appelle repr(), qui imprime une chaîne entre guillemets.
print()
print(f "Question : {SAMPLE_QUESTION!r}")
pprint.pprint(f "Texte généré : {texte_généré!r}")

La réponse ci-dessus me semble parfaite !
Si cette démo vous intéresse, n'hésitez pas à l'essayer vous-même et à nous faire part de vos impressions. Vous pouvez également rejoindre notre communauté Milvus sur Discord pour discuter directement avec tous les développeurs de GenAI.
Références
vLLM documentation officielle et page modèle.
Présentation de vLLM 2023](https://www.youtube.com/watch?v=80bIUggRJf4) au Ray Summit
blog vLLM : vLLM : Easy, Fast, and Cheap LLM Serving with PagedAttention
Blog utile sur le fonctionnement du serveur vLLM : Déploiement de vLLM : un guide étape par étape
The Llama 3 Herd of Models | Research - AI at Meta](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)

Continuer à lire

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.