




Exa desarrolla un motor de búsqueda de entidades para agentes de IA con Zilliz Cloud
latencia de búsqueda <200ms
La latencia de búsqueda neuronal de Exa se redujo de segundos a menos de 200 ms con la búsqueda híbrida de Zilliz
Alta fiabilidad
Incidentes operativos casi nulos, liberando tiempo de ingeniería para el trabajo de producto
Sin tiempo de inactividad para cambios de esquema
Se pueden añadir nuevos campos filtrables y metadatos sin reconstruir índices ni desconectar colecciones
We believe AI agents will become a fundamental interface for how people work, learn, and make decisions, and that only happens if those systems can access real-world information with speed, precision, and trust. That’s what we’re building at Exa. Aside from web search, Exa also operates entity search, and Zilliz Cloud has been an important part of that journey, giving us the retrieval performance and operational simplicity we need to scale our entity search product quickly and confidently.
Jeffrey Wang
La búsqueda para agentes de IA suena como una extensión natural de la búsqueda web, pero en la práctica exige un estándar de producto diferente. Los agentes no solo necesitan enlaces; necesitan información fundamentada, actual, estructurada y entregada con la rapidez suficiente para respaldar flujos de trabajo reales, desde interacciones de voz hasta tareas de investigación profunda.
Exa está creando exactamente ese tipo de motor de búsqueda para IA. Su Search API brinda a los desarrolladores acceso a búsqueda web de alta calidad y baja latencia en una amplia gama de cómputo-latencia, desde búsqueda instantánea para agentes de voz hasta investigación más profunda con salidas estructuradas y enriquecimientos. Exa atiende a clientes que van desde startups nativas de IA como Cursor y Lovable hasta empresas corporativas como AWS, todas las cuales dependen de contexto fundamentado y del mundo real para flujos de trabajo impulsados por agentes.
A medida que Exa se expande hacia la búsqueda de entidades para empresas, personas y código, se enfrentó a un desafío de infraestructura más especializado: cómo admitir recuperación híbrida, filtrado de metadatos enriquecidos, actualizaciones frecuentes y latencia de nivel de milisegundos sin desviar el enfoque de ingeniería del motor de búsqueda principal. Ese es el papel específico que Zilliz Cloud (Milvus completamente gestionado) desempeña en la historia a continuación.
| 200ms de baja latencia de búsqueda | Búsqueda híbrida que combina vectores densos, vectores dispersos, reranking RRF y filtros de metadatos en una sola llamada de API. Exa Instant redujo la latencia de búsqueda neuronal de segundos a menos de 200ms |
| Alta fiabilidad | El servicio gestionado ha ofrecido incidentes operativos casi nulos, liberando tiempo de ingeniería para el trabajo de producto |
| Cero tiempo de inactividad para cambios de esquema | Se pueden agregar nuevos campos filtrables y metadatos sin reconstruir índices ni desconectar colecciones |
A continuación se muestra el guion de una conversación con Exa sobre su misión de producto, el cambio de la búsqueda web general a la búsqueda de entidades y cómo Zilliz Cloud encaja en esa evolución.
1. La promesa de producto de Exa: búsqueda fundamentada para agentes de IA
Comenzamos pidiendo a Exa que describiera el producto que está creando y los clientes a los que atiende, porque ese contexto explica por qué la calidad de recuperación y la latencia no son preocupaciones secundarias para la empresa.
P: ¿Qué producto o servicio ofrece Exa y quiénes son sus clientes principales?
Exa: Exa está creando el motor de búsqueda para IA. Hemos creado una API de búsqueda que permite a los desarrolladores acceder a búsqueda web de alta calidad y baja latencia en sus agentes. Nuestra API ofrece búsqueda a lo largo del espectro de latencia de cómputo, desde búsquedas instantáneas (<200ms) para agentes de voz hasta investigación profunda con salidas estructuradas y enriquecimientos. Nos especializamos en búsqueda de código, baja latencia y búsqueda de personas/empresas, con destacados que garantizan eficiencia de tokens.
Creamos nuestro motor de búsqueda desde cero usando arquitecturas neuronales novedosas, en lugar de depender de motores de búsqueda heredados. Crear tu propio motor de búsqueda requiere de todo, desde entrenar modelos de embeddings y rerankers hasta rastrear e indexar miles de millones de páginas web. Esta propiedad de extremo a extremo nos permite optimizar cada capa de la pila para calidad y velocidad. En el reciente lanzamiento de Exa Instant, por ejemplo, logramos una latencia de búsqueda de <200ms, una mejora significativa que hace que la búsqueda neuronal sea viable como primitiva en tiempo real para agentes de IA. La combinación de calidad, velocidad y capacidad de personalización es un diferenciador clave.
Nuestros clientes van desde empresas nativas de IA como Cursor y Lovable hasta grandes empresas. Cualquier empresa que use agentes para impulsar el trabajo del conocimiento necesita contexto fundamentado para responder al mundo real, por lo que, independientemente del tamaño de la empresa, trabajamos con equipos que priorizan flujos de trabajo impulsados por agentes.
2. El punto de inflexión: de la búsqueda web a la búsqueda de entidades
Ese contexto de producto también aclara por qué la decisión de base de datos de Exa no consistía en reemplazar su pila de búsqueda principal. La búsqueda vectorial ya era fundamental para la empresa. El verdadero cambio llegó cuando la búsqueda de entidades introdujo nuevas restricciones.
P: ¿En qué punto de su recorrido de producto se dieron cuenta de que necesitaban una base de datos vectorial?
Exa: Dado que nuestro motor de búsqueda se construyó sobre embeddings y similitud vectorial, la búsqueda vectorial ha sido una parte integral del stack tecnológico de Exa. A medida que nos expandimos hacia la búsqueda de entidades, necesitábamos actualizar nuestra infraestructura de base de datos vectorial para dar cabida a los resultados estructurados y los enriquecimientos que ahora ofrecíamos.
La búsqueda de entidades requiere esquemas de metadatos ricos, actualizaciones de datos frecuentes y escalabilidad gestionada. Nuestra base de datos interna estaba optimizada para estas restricciones actualizadas, pero queríamos mejorar aún más la velocidad de iteración en esta capa de búsqueda de entidades, lo que nos llevó a usar Zilliz Cloud. Nuestro índice web principal permanece en nuestra infraestructura interna, y Zilliz Cloud se incorporó específicamente para impulsar esta capa de búsqueda de entidades.
P: ¿Qué desafíos o requisitos enfrentaron con su solución anterior?
Exa: Cuando empezamos a construir la búsqueda de entidades, los requisitos eran muy diferentes: búsqueda híbrida que combinara vectores densos y dispersos, esquemas de metadatos ricos y que cambiaban con frecuencia, y la sobrecarga operativa de gestionar múltiples colecciones especializadas. Buscábamos una solución gestionada que permitiera a nuestros ingenieros iterar rápidamente y admitir respuestas rápidas a escala.
P: ¿Qué caso(s) de uso específico(s) están resolviendo con búsqueda vectorial/base de datos vectorial?
Exa: Hoy, Zilliz Cloud impulsa nuestra capa de búsqueda de entidades, sirviendo tanto como índice principal como caché de actualidad en colecciones de entidades, mientras que nuestro índice web principal se ejecuta en una infraestructura interna separada. Cada vertical exige búsqueda filtrada de baja latencia sobre datos actualizados con frecuencia, donde las capacidades gestionadas de recuperación híbrida y hot-upsert de Zilliz mantienen los resultados actualizados sin reconstruir índices. Estas verticales alimentan directamente nuestra Search API, por lo que la velocidad y el recall son críticos para el negocio.
3. Lo que Exa necesitaba de una capa gestionada de recuperación vectorial
Una vez que la búsqueda de entidades se convirtió en una capa diferenciada, la evaluación realmente giró en torno al encaje: ¿podía un sistema gestionado respaldar el estándar de calidad de búsqueda de Exa sin ralentizar al equipo ni forzar compromisos arquitectónicos?
P: ¿Qué bases de datos vectoriales evaluaron antes de elegir Zilliz Cloud? ¿Cuáles fueron los criterios clave en su evaluación?
Exa: Cuando empezamos a construir la búsqueda de entidades, los requisitos eran muy diferentes: búsqueda híbrida que combinara vectores densos y dispersos, esquemas de metadatos ricos y que cambiaban con frecuencia, y la sobrecarga operativa de gestionar múltiples colecciones especializadas. Buscábamos una solución gestionada que permitiera a nuestros ingenieros iterar rápidamente y admitir respuestas rápidas a escala.
Analizamos todas las principales opciones de bases de datos vectoriales del espacio. Nuestros criterios clave fueron:
Soporte para búsqueda híbrida: Capacidad nativa para combinar vectores semánticos densos con vectores dispersos de palabras clave en una sola consulta, con reranking integrado
Latencia de consulta: Respuestas consistentemente rápidas en colecciones con decenas de millones de vectores
Filtrado de metadatos ricos: Filtros complejos en campos estructurados sin degradar el rendimiento de búsqueda
Escalabilidad: Escalado fluido a medida que agregamos nuevas verticales y fuentes de datos
Zilliz Cloud cumplía con todos los requisitos, y su rendimiento en benchmarks de búsqueda híbrida estaba claramente por delante del resto del mercado.
P: ¿Cómo se enteraron por primera vez de Zilliz Cloud / Milvus?
Exa: Conocemos Milvus desde hace mucho tiempo, ya que es una de las bases de datos vectoriales open-source más maduras, y como equipo que vive y respira búsqueda vectorial, es difícil pasarla por alto. Cuando empezamos a definir el alcance de nuestra infraestructura de búsqueda de entidades, Zilliz Cloud destacó como la oferta gestionada natural sobre Milvus, con mejoras de rendimiento de nivel empresarial.
P: ¿Qué destacó de Zilliz Cloud durante su evaluación? ¿Cuáles fueron las principales razones que los llevaron a elegir Zilliz Cloud?
Exa: Algunas cosas destacaron de inmediato.
Búsqueda híbrida nativa: Zilliz Cloud admite búsqueda vectorial densa y dispersa en una sola llamada a la API, con estrategias de reordenamiento integradas (RRF, ponderada). Este era un requisito imprescindible para varios competidores, y nosotros no lo admitíamos de forma nativa.
Rendimiento a escala: su motor de indexación Cardinal ofrece tiempos de consulta consistentemente rápidos incluso cuando nuestras colecciones crecen hasta cientos de millones de vectores.
Filtrado maduro: la capacidad de combinar la búsqueda vectorial con filtros complejos de metadatos en una sola solicitud, sin una caída abrupta del rendimiento.
En cuanto a los factores decisivos para la adopción:
Velocidad: la latencia de consulta de Zilliz Cloud cumplió nuestros estrictos requisitos para la búsqueda en producción. Nuestros usuarios esperan resultados en milisegundos, y Zilliz es capaz de respaldar esto.
Capacidades de búsqueda híbrida: la capacidad de fusionar la búsqueda semántica densa con la coincidencia de palabras clave dispersa BM25 y aplicar el reordenamiento Reciprocal Rank Fusion (RRF) en una sola llamada a la API fue importante para la calidad de la búsqueda.
Simplicidad operativa: como servicio completamente gestionado, Zilliz Cloud permite que nuestro equipo se centre en crear mejores experiencias de búsqueda e iterar rápidamente sobre mejoras en la infraestructura de bases de datos vectoriales a escala.
4. Cómo encajan la arquitectura de Zilliz y Exa
P: ¿Cómo encaja Zilliz Cloud en su arquitectura?
Exa: Nuestra arquitectura de búsqueda de entidades comprende tres capas: ingesta, búsqueda y API.
En la ingesta, enriquecemos e incrustamos datos de entidades utilizando nuestros propios pipelines de ML, y luego hacemos upsert de vectores densos y dispersos en Zilliz Cloud.
En la búsqueda, nuestro backend genera embeddings a partir de consultas de usuarios y envía solicitudes de búsqueda híbrida a Zilliz Cloud, combinando coincidencia semántica y de palabras clave con reordenamiento RRF.
En la capa de API, los resultados se enriquecen con metadatos estructurados y se sirven a través de nuestra Search API y el producto Websets. Zilliz Cloud se encuentra en el núcleo de la recuperación para este flujo de trabajo: almacena todos los vectores y metadatos de entidades y gestiona la búsqueda de baja latencia. Nuestro índice web principal se construye y gestiona en una infraestructura interna separada.
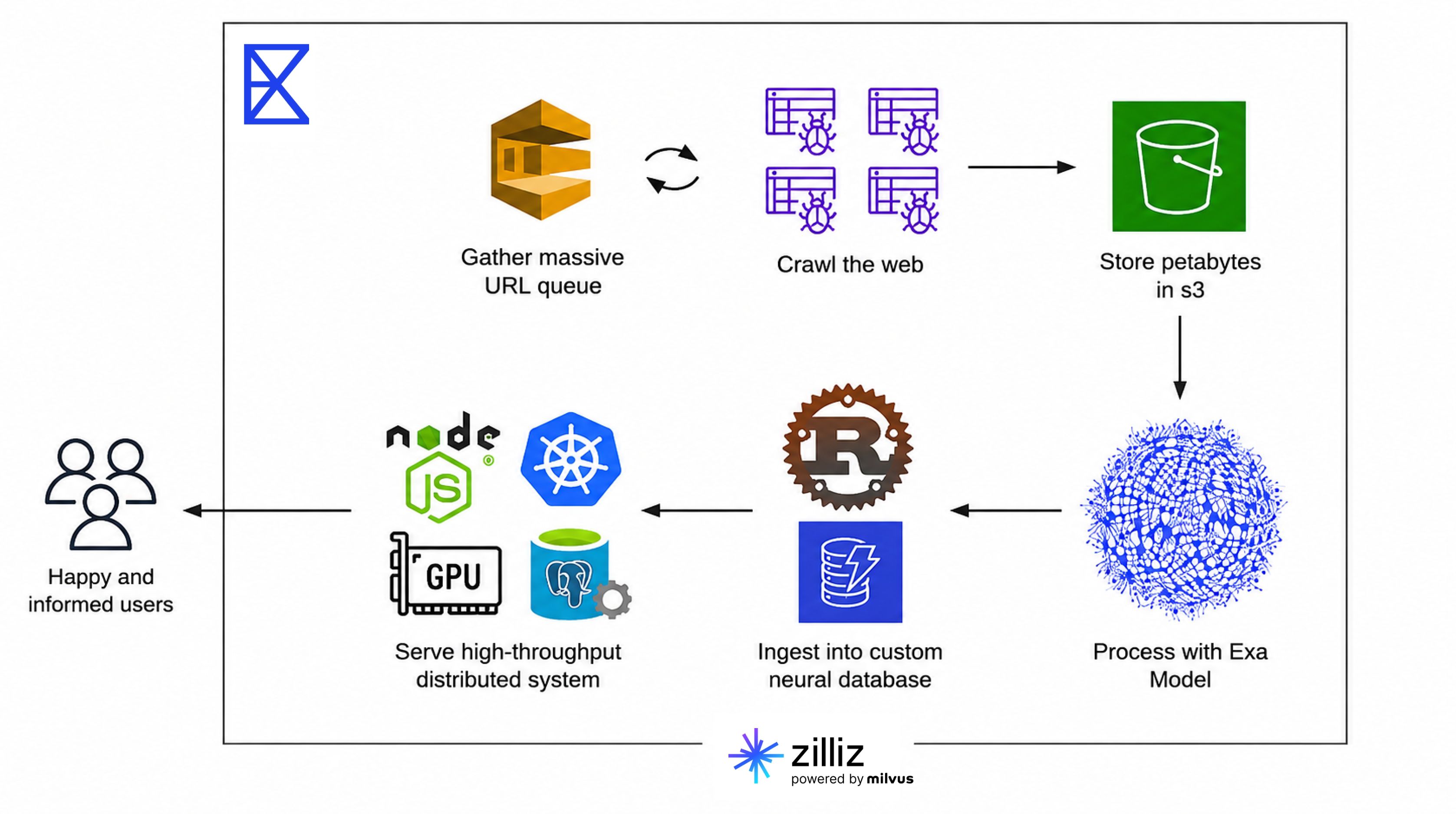
P: ¿Cómo ha sido la experiencia de su equipo usando Zilliz Cloud o Milvus?
Exa: La API es intuitiva, la documentación es sólida y el sistema ha sido fiable en producción. La curva de aprendizaje fue mínima porque los conceptos de Milvus: colecciones, índices, parámetros de búsqueda, encajan bien con la forma en que ya pensamos sobre la búsqueda vectorial. La naturaleza gestionada de Zilliz Cloud significa que hemos tenido muy pocos incidentes operativos con los que lidiar.
P: ¿Cómo ha sido la experiencia de integrar Zilliz Cloud con AWS u otros servicios en la nube?
Exa: Perfecta. Ejecutamos nuestra infraestructura principalmente en AWS, y Zilliz Cloud encaja limpiamente en ese stack nativo de AWS. Debido a que se ejecuta en AWS, la latencia de red entre nuestros servicios EKS y Zilliz Cloud es mínima.
5. Qué cambió después de la adopción
P: ¿Cuáles son los 3 principales beneficios que han visto? ¿Pueden compartir alguna métrica o mejora medible?
Exa: El primer beneficio ha sido la velocidad de desarrollo: el servicio gestionado y la API clara significaron que nuestro equipo pudo lanzar rápidamente nuevos verticales de búsqueda de entidades sin construir ni gestionar infraestructura adicional.
Más allá de eso, la flexibilidad y adaptabilidad del esquema han sido muy importantes a medida que estos conjuntos de datos verticales evolucionan, y la calidad de búsqueda mediante autoindex también ha sido valiosa en la práctica.
P: ¿Qué características de Zilliz Cloud consideran más valiosas?
Exa: Dos cosas destacan más en el uso diario.
Filtrado sin caída abrupta del rendimiento: Filtros complejos de metadatos superpuestos a la búsqueda vectorial con un impacto insignificante en la latencia.
Lanzamientos rápidos de verticales: El escalado gestionado nos permite lanzar nuevos verticales de búsqueda rápidamente sin levantar nueva infraestructura cada vez.
Comienza con Zilliz Cloud
Zilliz es el creador de Milvus, la base de datos vectorial de código abierto más popular del mundo, y Zilliz Cloud, el servicio de base de datos vectorial completamente administrado basado en Milvus. Zilliz Cloud permite a las organizaciones crear aplicaciones de IA listas para producción con búsqueda vectorial de alto rendimiento, recuperación híbrida y seguridad y cumplimiento de nivel empresarial.
- Comienza con Zilliz Cloud gratis con $100 en créditos al registrarte con un correo electrónico empresarial
- 1. La promesa de producto de Exa: búsqueda fundamentada para agentes de IA
- 2. El punto de inflexión: de la búsqueda web a la búsqueda de entidades
- 3. Lo que Exa necesitaba de una capa gestionada de recuperación vectorial
- 4. Cómo encajan la arquitectura de Zilliz y Exa
- 5. Qué cambió después de la adopción
- Comienza con Zilliz Cloud
Contenido
Caso de uso
Industria
Infraestructura de IA