




Cómo Biomap transforma el descubrimiento en ciencias de la vida a escala con búsqueda vectorial impulsada por IA usando Milvus
22× más rápido
Búsquedas de proteínas con tiempos de consulta reducidos de 10–20 minutos a menos de un minuto.
50 mil millones+
Sequence Scale se expandió de cientos de millones a decenas de miles de millones de secuencias biológicas.
Descubrimiento en tiempo real
Respuestas en menos de un segundo para consultas biológicas complejas en flujos de trabajo RAG.
Integración intermodal
Unificó proteínas, ADN, ARN, texto y datos celulares en un único marco de búsqueda.
Milvus has become the bridge that connects our multi-modal foundation models with real-world applications. It's not just about performance – it's about enabling entirely new approaches to biological discovery that were previously impossible.
Xiaoming Zhang
Acerca de Biomap
Biomap es una empresa líder de IA en ciencias de la vida centrada en crear modelos de IA que aceleran el descubrimiento en el desarrollo de fármacos, la biología sintética y la investigación médica. En el núcleo de su plataforma se encuentra xTrimo, una familia de modelos fundacionales a gran escala diseñados específicamente para la biología. Con una escala de hasta 210 mil millones de parámetros, xTrimo unifica proteínas, ADN, ARN, células, moléculas y texto científico en un único marco, ofreciendo predicciones e información que los métodos tradicionales no pueden igualar.
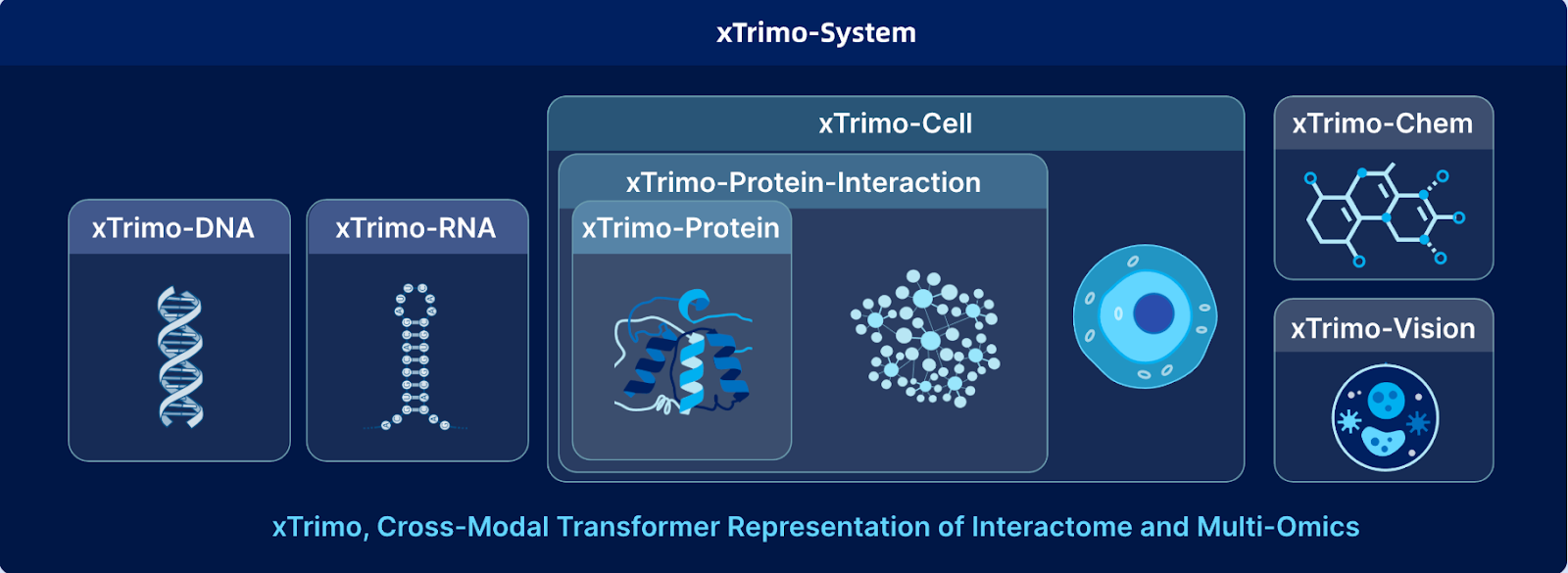
Lograr esta capacidad requirió superar barreras técnicas, incluidos datos biológicos ruidosos, formatos muy diversos y la necesidad de buscar entre miles de millones de secuencias en tiempo real. Biomap abordó estos desafíos desarrollando modelos de embeddings personalizados para entidades biológicas e implementando infraestructura de datos avanzada, como Milvus Vector Database, para permitir una recuperación rápida y precisa a escala. Con esta base, los investigadores ahora pueden acelerar avances en diversos campos, incluida la inmunología, la neurología, la oncología y el tratamiento de enfermedades raras.
Barreras técnicas para escalar la IA biológica
A medida que Biomap ampliaba sus capacidades de IA, el equipo se encontró con varios cuellos de botella que las herramientas tradicionales no podían superar.
1. Búsqueda lenta de proteínas
El pipeline de predicción de estructuras proteicas de Biomap dependía anteriormente del Alineamiento Múltiple de Secuencias (MSA), que requería entre 10 y 20 minutos para devolver un solo resultado. Si bien era aceptable para la investigación a pequeña escala, este retraso resultaba poco práctico para cargas de trabajo de producción, especialmente al escalar a cientos de millones —o incluso miles de millones— de secuencias.
2. Complejidad de los datos multimodales
Los datos biológicos se presentan inherentemente en muchas formas: proteínas, ADN, ARN, imágenes celulares e incluso texto. Los métodos de búsqueda tradicionales no podían conectar eficazmente estas modalidades, por lo que perdían el tipo de conocimientos intermodales que son cruciales para comprender sistemas biológicos complejos.
3. Dilema entre velocidad y precisión
En la investigación biomédica, los errores menores pueden tener grandes consecuencias. El asistente de descubrimiento basado en RAG de Biomap necesitaba tanto respuestas a consultas en menos de un segundo para la interactividad como precisión de nivel investigador para la fiabilidad científica. Sin embargo, la mayoría de las soluciones obligaban a elegir entre velocidad y precisión.
4. Requisitos de datos especializados
Los datos biológicos tienen características únicas que requieren estrategias de indexación personalizadas, modelos de embeddings específicos del dominio y optimización ajustada para cargas de trabajo científicas, capacidades que las soluciones listas para usar no podían proporcionar.
5. Diversas demandas de rendimiento
Los diferentes casos de uso de Biomap tenían necesidades muy distintas: los asistentes conversacionales requerían respuestas instantáneas, la predicción de proteínas podía tolerar minutos por consulta pero necesitaba un procesamiento por lotes eficiente, y el entrenamiento de modelos fundacionales exigía pipelines de datos de alto rendimiento. Gestionar estos diversos requisitos dentro de una única infraestructura unificada resultó especialmente desafiante.
Por qué Biomap eligió Milvus para impulsar la IA biológica a escala
Biomap se dio cuenta rápidamente de que escalar sus cargas de trabajo de IA requeriría una plataforma de búsqueda vectorial diseñada específicamente. El equipo recurrió primero a Faiss, una popular biblioteca de búsqueda vectorial, para pruebas de concepto a pequeña escala. Aunque Faiss funcionó bien en los primeros experimentos, falló cuando se llevó a cargas de trabajo de producción, incapaz de cumplir los requisitos de escala, fiabilidad y flexibilidad de las aplicaciones reales de ciencias de la vida. Tras probar múltiples alternativas, el equipo descubrió que Milvus era la única solución que cumplía todos los requisitos debido a los siguientes factores:
Flexibilidad de código abierto: Los datos de ciencias de la vida son altamente especializados y a menudo requieren indexación y algoritmos personalizados adaptados a casos de uso biológicos. El diseño de código abierto de Milvus le dio a Biomap la libertad de adaptar y ampliar el sistema sin restricciones. Como explicó Xiaoming Zhang, vicepresidente de Tecnología de Biomap, “Si no es de código abierto, probablemente no haya margen para dichas personalizaciones, lo cual no encaja con nuestros escenarios.”
Estabilidad lista para producción: Para las implementaciones en producción, Biomap requería una plataforma madura respaldada por una base de usuarios activa, particularmente entre empresas biotecnológicas empresariales. Con un historial comprobado en distintos sectores y una sólida adopción comunitaria entre empresas biotecnológicas, Milvus ofreció la fiabilidad y el respaldo del ecosistema que Biomap requería.
Conjunto integral de funciones: Milvus admite una amplia gama de tipos de índices y capacidades de búsqueda híbrida, lo que permite la optimización de búsquedas en proteínas, ADN, ARN, texto y otras modalidades, todo dentro de un único sistema.
Rendimiento a escala: Desde asistentes interactivos hasta búsquedas de proteínas a gran escala, Biomap necesitaba una infraestructura que pudiera manejar tanto consultas en menos de un segundo como trabajos por lotes masivos. La arquitectura escalable horizontalmente de Milvus garantizó un rendimiento constante en todas las cargas de trabajo, independientemente de su tamaño y escala.
Comunidad y asociación: El equipo de Biomap también valoró la activa comunidad de código abierto de Milvus y el potencial de asociación a largo plazo con Zilliz, la empresa detrás de Milvus.
Esta combinación de profundidad técnica, madurez del ecosistema y soporte orientado al futuro hizo de Milvus la opción clara para la infraestructura de producción de Biomap.
Cómo Biomap utiliza Milvus para impulsar sus servicios de IA biológica
Biomap implementó Milvus en tres casos de uso críticos, cada uno abordando un desafío científico único y formando en conjunto la columna vertebral de su plataforma de IA biológica.
Asistente de descubrimiento con IA (RAG)
En el núcleo de los flujos de trabajo de investigación de Biomap se encuentra un asistente de descubrimiento impulsado por Retrieval-Augmented Generation (RAG) avanzada. Construido sobre LangGraph para la orquestación, el asistente extrae datos de vastas colecciones de literatura científica, patentes y bases de datos biológicas especializadas. Dichos datos, ricos en fórmulas, estructuras de proteínas y notación específica del dominio, se convierten luego en embeddings vectoriales y se almacenan en Milvus.
Milvus realiza búsqueda híbrida vectorial y de texto completo para ofrecer los resultados más precisos para las consultas en menos de un segundo. Esto permite a los investigadores buscar en conocimiento biológico especializado y recibir respuestas precisas en tiempo real, en lugar de pasar horas revisando la literatura.
Predicción de estructura de proteínas a escala
Biomap también reinventó el proceso tradicional de búsqueda de proteínas al reemplazar los métodos lentos de Multiple Sequence Alignment (MSA) por búsqueda vectorial. Sus modelos fundacionales de proteínas propietarios generan embeddings de alta dimensionalidad, que se almacenan y consultan en Milvus. Esta nueva arquitectura amplió su escala de búsqueda de cientos de millones a más de 5 mil millones de secuencias de proteínas, permitiendo descubrimientos que antes estaban fuera de alcance. El rendimiento también mejoró drásticamente: las consultas que antes tardaban entre 10 y 20 minutos ahora se completan en menos de un minuto, con mayor precisión gracias a métricas de similitud impulsadas por IA.
Generación de muestras multimodales para entrenamiento de modelos
Para avanzar en el desarrollo de modelos fundacionales multimodales, Biomap se apoya en Milvus para conectar datos entre modalidades biológicas. Los investigadores pueden, por ejemplo, recuperar imágenes celulares vinculadas a secuencias de proteínas específicas o alinear datos a nivel molecular y a nivel celular en un espacio vectorial unificado. Esta capacidad admite una sofisticada ampliación de datos y el descubrimiento de asociaciones multimodales, acelerando el entrenamiento de modelos que conectan datos de texto, secuencia e imagen.
En conjunto, estas aplicaciones muestran cómo Milvus permite a Biomap combinar escala, precisión y velocidad en distintos dominios: desde el descubrimiento cotidiano hasta el entrenamiento de modelos biológicos de vanguardia.
Impacto de Milvus en la plataforma de Biomap
Al adoptar Milvus, Biomap logró resultados que la infraestructura tradicional no podía ofrecer, transformando tanto la velocidad como el alcance de su investigación.
Búsquedas más rápidas a escala de miles de millones
El motor de indexación de alto rendimiento de Milvus impulsó una aceleración de 22× en las búsquedas de secuencias de proteínas. Las consultas que antes tardaban entre 10 y 20 minutos ahora devuelven resultados en menos de un minuto, incluso a escalas de 50 mil millones de secuencias. Esto representa un aumento de escala de más de 10 veces—de cientos de millones a decenas de miles de millones de secuencias biológicas—sin sacrificar precisión ni fiabilidad.
Descubrimiento biológico más inteligente
Milvus también cambió la forma en que Biomap aborda el descubrimiento en sí. Dado que la calidad de la búsqueda está directamente vinculada al rendimiento de sus modelos fundacionales, las mejoras en la precisión del modelo se traducen de inmediato en mejores resultados de recuperación. Esto crea un círculo virtuoso: a medida que los modelos evolucionan, el motor de búsqueda impulsado por Milvus se vuelve más preciso, desbloqueando conocimientos científicos que los métodos estáticos basados en alineamiento nunca podrían lograr.
Avances multimodales
Con Milvus, Biomap ahora puede conectar datos a nivel molecular y celular dentro del mismo espacio vectorial. Este “aplanamiento” de las diferencias de escala permite búsquedas multimodales fluidas, respaldando el entrenamiento de sus modelos fundacionales multimodales de próxima generación. Es un paso fundamental hacia su visión a largo plazo de construir un simulador de IA integral para la biología.
Una plataforma escalable para las ciencias de la vida
En última instancia, Milvus proporciona a Biomap la infraestructura para expandirse más allá de la investigación interna hacia aplicaciones más amplias en las ciencias de la vida. La misma plataforma ahora admite bases de conocimiento personalizadas y agentes inteligentes para compañías farmacéuticas, hospitales y empresas de biología sintética, extendiendo los beneficios de una IA biológica rápida y escalable a todo el ecosistema.
Mirando hacia el futuro
El éxito de Biomap con Milvus ha sentado las bases para la expansión en todo el ecosistema de las ciencias de la vida. El equipo ahora está ampliando su plataforma para atender a una variedad de partes interesadas, incluidas compañías farmacéuticas que aceleran el descubrimiento de fármacos, instituciones médicas que impulsan la investigación clínica, empresas de biología sintética que optimizan el diseño de organismos y compañías de biotecnología agrícola que impulsan mejoras genéticas en los cultivos. Cada nuevo caso de uso se basa en la misma infraestructura central—búsqueda vectorial con Milvus—que hace que los datos biológicos complejos sean accesibles y accionables a escala.
Como señaló Xiaoming, “Milvus se ha convertido en la única opción técnica para bases de datos vectoriales en nuestra próxima expansión comercial en la industria de las ciencias de la vida.”
Esta asociación va más allá de la integración técnica. Está creando una base para cómo se llevará a cabo el descubrimiento biológico en el futuro: más rápido, más preciso y capaz de abarcar modalidades que antes estaban aisladas. A medida que Biomap continúa persiguiendo su visión de un “simulador de IA para la vida,” Zilliz proporciona la infraestructura de base de datos vectorial que convierte esta ambición en realidad, permitiendo avances que podrían transformar tanto la ciencia como la industria.
- Acerca de Biomap
- Barreras técnicas para escalar la IA biológica
- Por qué Biomap eligió Milvus para impulsar la IA biológica a escala
- Cómo Biomap utiliza Milvus para impulsar sus servicios de IA biológica
- Impacto de Milvus en la plataforma de Biomap
- Mirando hacia el futuro
Contenido
Industria
Ciencias de la vida
Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.
Xiaoming Zhang