




Cómo Airtable construyó y escaló la infraestructura vectorial con Milvus

Consultas de baja latencia
un rendimiento predecible es fundamental para la confianza del usuario
Escrituras de alto rendimiento
las bases cambian constantemente, y los embeddings deben mantenerse sincronizados
Escalabilidad horizontal
el sistema debe admitir millones de bases independientes
Esta publicación se publicó originalmente en el Medium de Airtable y se vuelve a publicar aquí con permiso.
A medida que la búsqueda semántica en Airtable evolucionó de un concepto a una funcionalidad central del producto, el equipo de Infraestructura de Datos se enfrentó al desafío de escalarla. Como se detalla en nuestra publicación anterior sobre la creación del sistema de embeddings, ya habíamos diseñado una capa de aplicación robusta y eventualmente consistente para gestionar el ciclo de vida de los embeddings. Pero aún faltaba una pieza crítica en nuestro diagrama de arquitectura: la base de datos vectorial en sí.
Necesitábamos un motor de almacenamiento capaz de indexar y servir miles de millones de embeddings, admitir una multitenencia masiva y mantener objetivos de rendimiento y disponibilidad en un entorno de nube distribuido. Esta es la historia de cómo diseñamos, fortalecimos y evolucionamos nuestra plataforma de búsqueda vectorial hasta convertirla en un pilar central de la pila de infraestructura de Airtable.
Antecedentes
En Airtable, nuestro objetivo es ayudar a los clientes a trabajar con sus datos de formas potentes e intuitivas. Con la aparición de LLMs cada vez más potentes y precisos, las funcionalidades que aprovechan el significado semántico de tus datos se han vuelto centrales para nuestro producto.
Cómo usamos la búsqueda semántica
Omni (el chat de IA de Airtable) respondiendo preguntas reales de grandes conjuntos de datos
Imagina hacer una pregunta en lenguaje natural a tu base (base de datos) con medio millón de filas y obtener una respuesta correcta y rica en contexto. Por ejemplo:
“¿Qué están diciendo últimamente los clientes sobre la duración de la batería?”
En conjuntos de datos pequeños, es posible enviar todas las filas directamente a un LLM. A escala, eso se vuelve rápidamente inviable. En su lugar, necesitábamos un sistema capaz de:
- Comprender la intención semántica de una consulta
- Recuperar las filas más relevantes mediante búsqueda por similitud vectorial
- Proporcionar esas filas como contexto a un LLM
Este requisito moldeó casi todas las decisiones de diseño que siguieron: Omni tenía que sentirse instantáneo e inteligente, incluso en bases muy grandes.
Recomendaciones de registros vinculados: significado por encima de coincidencias exactas
La búsqueda semántica también mejora una funcionalidad central de Airtable: los registros vinculados. Los usuarios necesitan sugerencias de relaciones basadas en el contexto en lugar de coincidencias exactas de texto. Por ejemplo, la descripción de un proyecto podría implicar una relación con “Team Infrastructure” sin usar nunca esa frase específica.
Ofrecer estas sugerencias bajo demanda requiere una recuperación semántica de alta calidad con una latencia constante y predecible.
Nuestras prioridades de diseño
Para respaldar estas funcionalidades y más, centramos el sistema en 4 objetivos:
- Consultas de baja latencia (500ms p99): el rendimiento predecible es fundamental para la confianza del usuario
- Escrituras de alto rendimiento: las bases cambian constantemente, y los embeddings deben mantenerse sincronizados
- Escalabilidad horizontal: el sistema debe admitir millones de bases independientes
- Autoalojamiento: todos los datos de los clientes deben permanecer dentro de la infraestructura controlada por Airtable
Estos objetivos moldearon cada decisión arquitectónica que siguió.
Evaluación de proveedores de bases de datos vectoriales
A finales de 2024, evaluamos varias opciones de bases de datos vectoriales y finalmente seleccionamos Milvus basándonos en tres requisitos clave.
- Primero, priorizamos una solución autoalojada para garantizar la privacidad de los datos y mantener un control detallado de nuestra infraestructura.
- Segundo, nuestra carga de trabajo con muchas escrituras y patrones de consulta con ráfagas requerían un sistema que pudiera escalar elásticamente manteniendo una latencia baja y predecible.
- Finalmente, nuestra arquitectura requería un fuerte aislamiento entre millones de inquilinos de clientes.
Milvus surgió como la mejor opción: su naturaleza distribuida admite una multitenencia masiva y nos permite escalar la ingesta, la indexación y la ejecución de consultas de forma independiente, ofreciendo rendimiento y manteniendo los costos predecibles.
Diseño de arquitectura
Después de elegir una tecnología, tuvimos que determinar una arquitectura para representar la forma de datos única de Airtable: millones de “bases” distintas propiedad de diferentes clientes.
El desafío del particionamiento
Evaluamos dos estrategias principales de particionamiento de datos:
Opción 1: Particiones compartidas
Varias bases comparten una partición, y las consultas se delimitan filtrando por un id de base. Esto mejora la utilización de recursos, pero introduce una sobrecarga adicional de filtrado y hace que la eliminación de bases sea más compleja.
Opción 2: Una base por partición
Cada base de Airtable se asigna a su propia partición física en Milvus. Esto proporciona un fuerte aislamiento, permite una eliminación de bases rápida y sencilla, y evita el impacto en el rendimiento del filtrado posterior a la consulta.
Estrategia final
Elegimos la opción 2 por su simplicidad y fuerte aislamiento. Sin embargo, las primeras pruebas mostraron que crear 100k particiones en una sola colección de Milvus causaba una degradación significativa del rendimiento:
- La latencia de creación de particiones aumentó de ~20 ms a ~250 ms
- Los tiempos de carga de particiones superaron los 30 segundos
Para abordar esto, limitamos el número de particiones por colección. Para cada clúster de Milvus, creamos 400 colecciones, cada una con un máximo de 1,000 particiones. Esto limita el número total de bases por clúster a 400k, y se aprovisionan nuevos clústeres a medida que se incorporan clientes adicionales.
Indexación y recuperación
La elección del índice resultó ser una de las compensaciones más importantes de nuestro sistema. Cuando se carga una partición, su índice se almacena en caché en memoria o en disco. Para lograr un equilibrio entre la tasa de recuperación, el tamaño del índice y el rendimiento, evaluamos varios tipos de índices.
- IVF-SQ8: Ofreció una huella de memoria pequeña pero una recuperación menor.
- HNSW: Ofrece la mejor recuperación (99%-100%) pero consume mucha memoria.
- DiskANN: Ofrece una recuperación similar a HNSW pero con mayor latencia de consulta
Finalmente, seleccionamos HNSW por sus características superiores de recuperación y rendimiento.
La capa de aplicación
A alto nivel, el pipeline de búsqueda semántica de Airtable implica dos flujos principales:
- Flujo de ingesta: Convertir filas de Airtable en embeddings y almacenarlos en Milvus
- Flujo de consulta: Insertar consultas de usuarios como embeddings, recuperar IDs de filas relevantes y proporcionar contexto al LLM
Ambos flujos deben operar de forma continua y fiable a escala, y analizamos cada uno a continuación. Analizamos cada uno a continuación.
Flujo de ingesta: Mantener Milvus sincronizado con Airtable
Cuando un usuario abre Omni, Airtable comienza a sincronizar su base con Milvus. Creamos una partición, luego procesamos las filas en fragmentos, generando embeddings y realizando upserts en Milvus. A partir de entonces, capturamos cualquier cambio realizado en la base, y volvemos a generar embeddings y a hacer upsert de esas filas para mantener los datos consistentes.
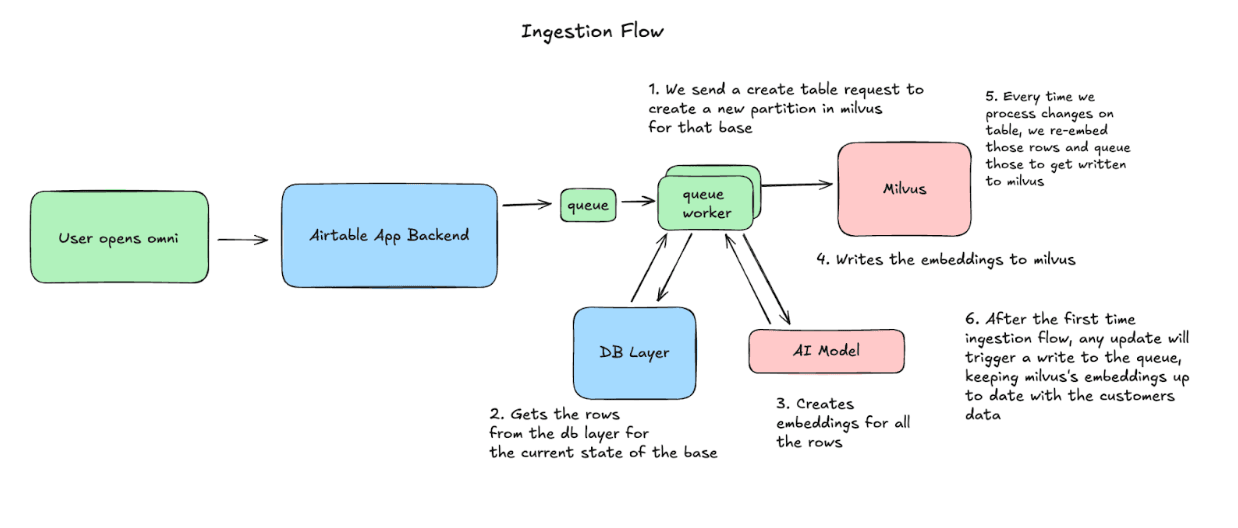
Flujo de consulta: Cómo usamos los datos
En el lado de la consulta, generamos un embedding de la solicitud del usuario y la enviamos a Milvus para recuperar los IDs de fila más relevantes. Luego obtenemos las versiones más recientes de esas filas y las incluimos como contexto en la solicitud al LLM.
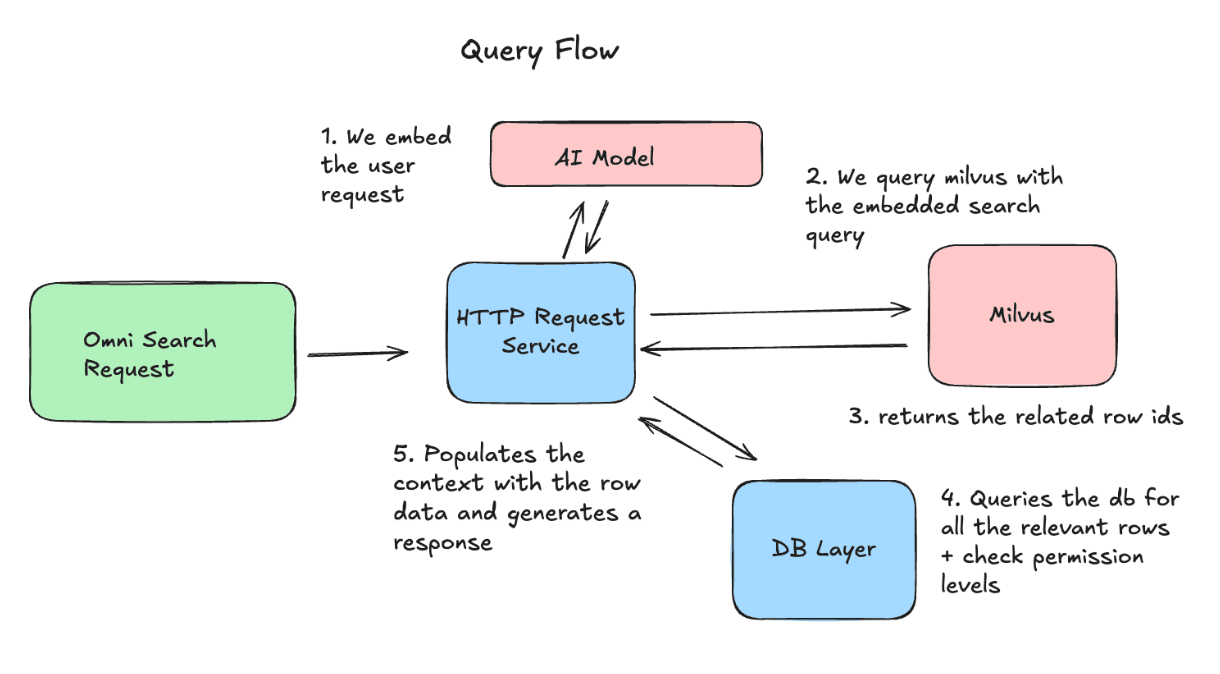
Desafíos operativos y cómo los resolvimos
Construir una arquitectura de búsqueda semántica es un desafío; ejecutarla de forma fiable para cientos de miles de bases es otro. A continuación, se presentan algunas lecciones operativas clave que aprendimos en el camino.
Despliegue
Desplegamos Milvus mediante su CRD de Kubernetes con el Milvus operator, lo que nos permite definir y gestionar clústeres de forma declarativa. Cada cambio, ya sea una actualización de configuración, una mejora del cliente o una actualización de Milvus, pasa por pruebas unitarias y una prueba de carga bajo demanda que simula tráfico de producción antes de implementarse para los usuarios.
En la versión 2.5, el clúster de Milvus está compuesto por estos componentes principales:
- Los nodos de consulta mantienen los índices vectoriales en memoria y ejecutan búsquedas vectoriales
- Los nodos de datos gestionan la ingesta y la compactación, y persisten los datos nuevos en el almacenamiento
- Los nodos de índice crean y mantienen índices vectoriales para que la búsqueda siga siendo rápida a medida que crecen los datos
- El nodo coordinador orquesta toda la actividad del clúster y la asignación de shards
- Los nodos proxy enrutan el tráfico de API y equilibran la carga entre los nodos
- Kafka proporciona la columna vertebral de logs/streaming para la mensajería interna y el flujo de datos
- Etcd almacena los metadatos del clúster y el estado de coordinación
Con automatización impulsada por CRD y un pipeline de pruebas riguroso, podemos desplegar actualizaciones de forma rápida y segura.
Observabilidad: comprender el estado del sistema de extremo a extremo
Monitoreamos el sistema en dos niveles para garantizar que la búsqueda semántica siga siendo rápida y predecible.
A nivel de infraestructura, hacemos seguimiento de la CPU, el uso de memoria y el estado de los pods en todos los componentes de Milvus. Estas señales nos indican si el clúster está operando dentro de límites seguros y nos ayudan a detectar problemas como la saturación de recursos o nodos no saludables antes de que afecten a los usuarios.
En la capa de servicio, nos centramos en qué tan bien se mantiene cada base al día con nuestras cargas de trabajo de ingesta y consulta. Métricas como el rendimiento de compactación e indexación nos dan visibilidad sobre la eficiencia con la que se están ingiriendo los datos. Las tasas de éxito y la latencia de las consultas nos dan una comprensión de la experiencia del usuario al consultar los datos, y el crecimiento de las particiones nos permite saber cómo están creciendo nuestros datos, de modo que recibimos alertas si necesitamos escalar.
Rotación de nodos
Por razones de seguridad y cumplimiento, rotamos regularmente los nodos de Kubernetes. En un clúster de búsqueda vectorial, esto no es trivial:
- A medida que se rotan los nodos de consulta, el coordinador reequilibrará los datos en memoria entre los nodos de consulta
- Kafka y Etcd almacenan información con estado y requieren quórum y disponibilidad continua
Abordamos esto con presupuestos de interrupción estrictos y una política de rotación de un nodo a la vez. Al coordinador de Milvus se le da tiempo para reequilibrar antes de pasar al siguiente nodo. Esta orquestación cuidadosa preserva la fiabilidad sin ralentizar nuestra velocidad.
Descarga de particiones frías
Uno de nuestros mayores logros operativos fue reconocer que nuestros datos tienen patrones claros de acceso caliente/frío. Al analizar el uso, descubrimos que solo ~25% de los datos en Milvus se escriben o se leen en una semana determinada. Milvus nos permite descargar particiones enteras, liberando memoria en los nodos de consulta. Si esos datos se necesitan más adelante, podemos recargarlos en cuestión de segundos. Esto nos permite mantener los datos calientes en memoria y descargar el resto, reduciendo costos y permitiéndonos escalar de manera más eficiente con el tiempo.
Recuperación de datos
Antes de desplegar Milvus ampliamente, necesitábamos tener la confianza de que podíamos recuperarnos rápidamente de cualquier escenario de fallo. Aunque la mayoría de los problemas están cubiertos por la tolerancia a fallos integrada del clúster, también planificamos casos poco frecuentes en los que los datos pudieran corromperse o el sistema pudiera entrar en un estado irrecuperable.
En esas situaciones, nuestra ruta de recuperación es sencilla. Primero levantamos un clúster de Milvus nuevo para poder reanudar el servicio de tráfico casi de inmediato. Una vez que el nuevo clúster está en vivo, volvemos a generar embeddings de forma proactiva para las bases más utilizadas y luego procesamos el resto de manera diferida a medida que se accede a ellas. Esto minimiza el tiempo de inactividad para los datos más consultados mientras el sistema reconstruye gradualmente un índice semántico consistente.
Qué sigue
Nuestro trabajo con Milvus ha sentado una base sólida para la búsqueda semántica en Airtable: impulsando experiencias de IA rápidas y significativas a escala. Con este sistema en marcha, ahora estamos explorando pipelines de recuperación más enriquecidos e integraciones de IA más profundas en todo el producto. Hay mucho trabajo emocionante por delante, y apenas estamos comenzando.
Gracias a todos los Airtablets, pasados y presentes, de Data Infrastructure y de toda la organización que contribuyeron a este proyecto: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Acerca de Airtable
Airtable es una plataforma líder de operaciones digitales que permite a las organizaciones crear aplicaciones personalizadas, automatizar flujos de trabajo y gestionar datos compartidos a escala empresarial. Diseñada para respaldar procesos complejos y multifuncionales, Airtable ayuda a los equipos a crear sistemas flexibles para la planificación, la coordinación y la ejecución sobre una fuente de verdad compartida. A medida que Airtable expande su plataforma impulsada por IA, tecnologías como Milvus desempeñan un papel importante en el fortalecimiento de la infraestructura de recuperación necesaria para ofrecer experiencias de producto más rápidas e inteligentes.
- Antecedentes
- Cómo usamos la búsqueda semántica
- Nuestras prioridades de diseño
- Evaluación de proveedores de bases de datos vectoriales
- Diseño de arquitectura
- El desafío del particionamiento
- Indexación y recuperación
- La capa de aplicación
- Flujo de ingesta: Mantener Milvus sincronizado con Airtable
- Flujo de consulta: Cómo usamos los datos
- Desafíos operativos y cómo los resolvimos
- Observabilidad: comprender el estado del sistema de extremo a extremo
- Rotación de nodos
- Descarga de particiones frías
- Recuperación de datos
- Qué sigue
- Acerca de Airtable
Contenido
Caso de uso
Industria
SaaS de IA