




Vector Lakebase: Acaba con el silo de datos de IA
Todos los equipos de IA se topan con el mismo muro: la gravedad de los datos
Todos los equipos de datos modernos han construido alguna versión de la misma arquitectura. Un lakehouse — tablas Iceberg en S3, un pipeline de Spark y Delta Lake para gobernanza — se sitúa en el centro. Funciona bien. Entonces llegan los requisitos de IA.
Tu pipeline de RAG necesita responder preguntas sobre 10 años de documentos empresariales, así que copias todo a una base de datos vectorial. Tus agentes de IA necesitan acceso de baja latencia a embeddings del catálogo de productos: otro pipeline, otra tarea de sincronización. El entrenamiento de tu modelo multimodal requiere deduplicación diaria sobre mil millones de embeddings de imágenes: una tarea de Spark que no puede ver el índice.
Seis meses después, tienes cinco sistemas en lugar de dos. Tu equipo de ingeniería de datos dedica más tiempo a mantener pipelines de sincronización que a crear funcionalidades de IA. Tienes tres copias del mismo conjunto de datos sin garantía de que coincidan. Cada cambio de esquema se propaga en cascada a cuatro lugares distintos.
Esto no es un fallo de ejecución. Es un fallo de arquitectura; específicamente, una arquitectura que sigue luchando contra una propiedad fundamental de los datos: la gravedad. Cada sistema que exige que primero copies los datos te impone un impuesto de gravedad. Cuantas más cargas de trabajo de IA añadas — pipelines de RAG, memoria de agentes, entrenamiento de modelos, recomendaciones en tiempo real — más alto se vuelve ese impuesto.
La solución correcta no es un pipeline mejor. Debería ser un nuevo paradigma arquitectónico: Vector Lakebase.
Tres generaciones de soluciones arquitectónicas, dos callejones sin salida
Antes de profundizar en los detalles de Vector Lakebase, vale la pena analizar cómo ha evolucionado la arquitectura de búsqueda vectorial para abordar el problema de la gravedad de los datos. En términos generales, ha habido tres generaciones de soluciones.
Generación 1: Bases de datos vectoriales dedicadas
Las bases de datos vectoriales dedicadas como Milvus resolvieron un problema real para los sistemas de IA en producción: búsqueda semántica con latencia de milisegundos, con recuperación y rendimiento que las bases de datos de propósito general no podían igualar. Como creadores de la base de datos vectorial de código abierto Milvus, Zilliz lleva mucho tiempo centrada en construir un sistema fiable y de alto rendimiento para almacenar embeddings, construir índices y ofrecer recuperación de baja latencia para RAG, agentes, sistemas de recomendación, búsqueda semántica y aplicaciones multimodales. Esa base sigue siendo importante. Los sistemas de IA en producción aún necesitan recuperación a velocidad de base de datos, y las bases de datos vectoriales siguen siendo la capa de servicio adecuada para muchas cargas de trabajo sensibles a la latencia.
Sin embargo, a medida que las cargas de trabajo de IA maduran, el desafío se extiende cada vez más allá del servicio en línea. Gran parte de los datos fuente de una organización ya vive en almacenamiento de objetos, data lakes, lakehouses y sistemas analíticos posteriores. Para usar esos datos en una base de datos vectorial dedicada, los equipos normalmente los copian a un sistema de servicio separado, construyen pipelines de ingesta, mantienen tareas de sincronización y gestionan la consistencia entre los datos fuente y el índice vectorial. Cuando los modelos de embedding cambian, como inevitablemente ocurre, los equipos necesitan regenerar embeddings, reconstruir índices y mantener múltiples sistemas alineados.
Esto no es una limitación del rendimiento de las bases de datos vectoriales. Es un límite arquitectónico creado por el movimiento de datos. A medida que más equipos quieren usar los mismos datos para recuperación en producción, experimentos de embeddings, evaluación offline, gobernanza, linaje y analítica, la superficie operativa crece. Las bases de datos vectoriales dedicadas resolvieron extremadamente bien el problema de la recuperación en línea, pero por sí solas no eliminan el problema de la gravedad de los datos.
Generación 2: Vector Lake
La siguiente respuesta natural fue acercar la búsqueda vectorial al lake: consultar vectores directamente desde archivos Iceberg, Delta Lake o Parquet sin moverlos primero a un sistema de servicio dedicado. La motivación era correcta. Si los datos ya viven en almacenamiento de objetos o en un lakehouse, ¿por qué duplicarlos en otro lugar solo para hacerlos buscables?
Pero en la práctica, las arquitecturas de lagos vectoriales siguen siendo incompletas para cargas de trabajo de IA en producción por tres razones.
Primero, no están diseñadas para el servicio de baja latencia. La mayoría de los enfoques de lagos vectoriales cargan datos o índices desde el almacenamiento de objetos bajo demanda y están optimizados más para la flexibilidad que para la gestión concurrente de solicitudes sensibles a la latencia. Eso puede ser aceptable para la exploración offline, pero no es suficiente para aplicaciones RAG orientadas al usuario, agentes, recomendación o búsqueda. Cuando una canalización de recuperación se encuentra en la ruta crítica de una llamada a un LLM, los equipos necesitan una latencia predecible inferior a 100 ms con alta concurrencia. Si la latencia p99 se desplaza regularmente al rango de segundos, el sistema aún puede ser útil para el análisis, pero no puede servir como la capa de recuperación de producción.
Segundo, los sistemas de lagos vectoriales suelen detenerse en la etapa de búsqueda. Permiten a los equipos consultar datos vectoriales en el lago, pero no proporcionan un entorno de ejecución más amplio para flujos de trabajo de datos de IA. Los sistemas modernos de IA necesitan más que búsqueda de vecinos más cercanos. Necesitan regenerar embeddings, evaluar la calidad de la recuperación, comprimir la memoria de los agentes, extraer fotogramas de video, procesar datos multimodales, gestionar metadatos y preparar datos para ajuste fino o canalizaciones posteriores. Un sistema que solo añade búsqueda encima de archivos del lago no aborda el ciclo de vida completo de los datos vectoriales y multimodales.
Tercero, la capa de almacenamiento subyacente no fue creada para esta carga de trabajo. Iceberg y Delta Lake fueron diseñados para datos analíticos estructurados: sin tipos vectoriales nativos, sin estructuras de índice, cada consulta es un escaneo completo. Las cargas de trabajo de IA necesitan búsquedas puntuales rápidas (no escaneos secuenciales de grupos de filas de Parquet; formatos como Vortex y Lance existen por esta razón), índices integrados cogestionados con los datos y gestión de datos no estructurados basada en referencias, donde imágenes, audio y video se vinculan por referencia en lugar de incrustarse como blobs. Nada de esto existe hoy en el lago. Un Vector Lake construido sobre Iceberg está luchando contra la capa de almacenamiento en todos los niveles.
Generación 3: Vector Lakebase
Vector Lakebase es lo que obtienes cuando dejas de tratar el lago y la base de datos vectorial como sistemas separados que deben sincronizarse y empiezas a construirlos como dos modos operativos de una única capa unificada. Para ser más específicos:
Un vector lakebase es una nueva arquitectura nativa de IA y nativa de lago evolucionada a partir de sistemas de bases de datos vectoriales. Combina las capacidades de servicio de alto QPS y baja latencia de las bases de datos vectoriales con la apertura, escalabilidad y eficiencia de costos de los lagos de datos multimodales, manteniendo al mismo tiempo todas las cargas de trabajo sobre la misma fuente de verdad sin migración de datos. Al separar el cómputo del almacenamiento, un vector lakebase almacena datos multimodales, vectores, atributos, índices y metadatos directamente en almacenamiento de objetos de bajo costo utilizando formatos abiertos. Las cargas de trabajo de servicio, descubrimiento y analítica pueden entonces ejecutarse de forma independiente sobre los mismos datos.
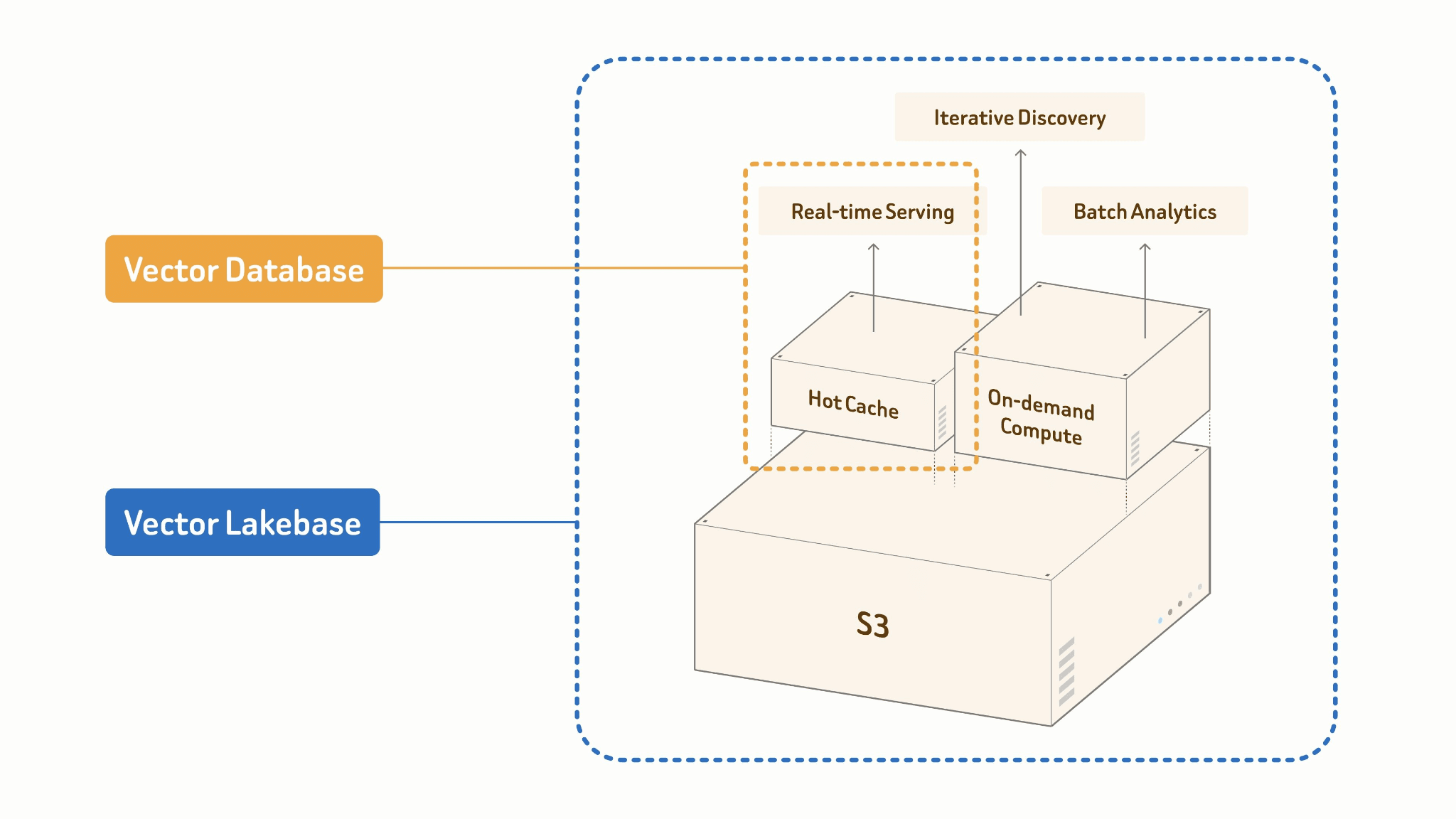
El principio central: Una única fuente de verdad.
Tu tabla del lago es la única fuente de verdad. El servicio online y el procesamiento por lotes offline comparten los mismos datos, índice y esquema. No hay una canalización entre ellos porque no hay una frontera entre ellos.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplicación + obsolescencia
Vector Lake: [Lake + Index] ◀── solo consulta por lotes # sin servicio, sin procesamiento
Vector Lakebase: [Lake + Index + Compute]
├── Online: Caché + Índice de alto rendimiento
│ → consulta ANN, servicio p99 <100 ms
└── Offline: Procesamiento por lotes + Creación de índices rentable
→ embed, cluster, dedup, ingeniería de características
Los dos modos están diseñados de forma diferente por necesidad. El servicio en línea se ejecuta contra una caché activa y un índice en memoria de alto rendimiento, optimizado para concurrencia y latencia de cola. Los trabajos batch sin conexión construyen índices de forma rentable a escala: escaneos columnares, construcción acelerada por GPU, escrituras por etapas de vuelta al lake. Los mismos datos, el mismo formato de índice, perfiles de cómputo radicalmente diferentes.
¿Cómo se ve esto en la práctica? En una tabla Iceberg de 1.000 millones de vectores:
| Modo | Latencia | Contexto |
|---|---|---|
| Escaneo brute-force con Spark (sin índice) | Horas | El valor predeterminado actual para la búsqueda vectorial basada en lake |
| Vector Lakebase — cold (índice recién construido) | ~30 segundos | El índice se construye desde Iceberg en ~20 minutos |
| Vector Lakebase — warm (caché en disco) | Decenas de ms | Índice en caché en SSD local |
| Vector Lakebase — hot (en memoria) | Un solo dígito de ms | RAG en producción y servicio de agentes |
| Vector Lakebase — clustering / dedup | Horas | KMeans de 1B vectores o detección de casi duplicados, totalmente distribuida |
Pasas de horas a milisegundos de un solo dígito — y nunca copias los datos fuera del lake.
Esto no es una elección de producto. Es la dirección hacia la que está convergiendo la arquitectura de datos de IA. Cualquier sistema que requiera que los datos existan en dos lugares te cobra un impuesto permanente: en almacenamiento, en horas de ingeniería, en obsolescencia. Los sistemas que separan el almacenamiento de las operaciones de IA parecerán transitorios en retrospectiva.
Lo que realmente permite una Vector Lakebase
Al menos tres clases de cargas de trabajo que antes requerían sistemas separados ahora pueden manejarse con una vector lakebase.
Colecciones externas: haz que tu lake sea buscable sin mover nada
Tienes petabytes de embeddings en archivos Parquet en S3. Hacerlos buscables para una nueva aplicación RAG hoy significa cargarlos en una base de datos vectorial: una migración medida en días o semanas, además de una obligación continua de sincronización.
Las external collections de Vector Lakebase trabajan con la gravedad de los datos en lugar de hacerlo en su contra. Apuntas al bucket, defines un mapeo de esquema sobre tus columnas existentes y construyes un índice vectorial in situ. Los datos permanecen en S3. El índice se persiste de vuelta en S3. Cuando los datos de origen se actualizan, refrescas de forma incremental: solo se reprocesan los archivos modificados.
# 1. Registra tus datos existentes del lake como una colección externa
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # apunta a tus datos existentes
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Construye un índice vectorial — los datos permanecen en S3, el índice se persiste de vuelta en S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min para 1B vectores. Los datos nunca se mueven.
# 3. Busca — ms de un solo dígito con caché en memoria
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Sin migración, sin pipeline, sin nuevo costo de almacenamiento. Tu sistema RAG consulta los mismos datos que tu equipo de analítica ya gobierna — a través de Spark, Ray, LangChain, PyMilvus o una REST API. El índice se convierte en una propiedad de primera clase de la tabla, no en un sistema externo acoplado junto a ella.
ETL, ingeniería de características e ingeniería de contexto
Esta es la carga de trabajo que tanto Vector Database como Vector Lake ignoran — y se está convirtiendo en la parte más importante del stack de datos de IA.
Las operaciones de datos nativas de IA no solo mueven datos entre sistemas — los enriquecen con significado semántico, in situ, a escala:
- Agrega una columna de embeddings a una tabla existente: inferencia por lotes en 100M filas, escribe los resultados de vuelta en la misma tabla.
- Fragmenta un corpus de documentos para RAG, manteniendo los documentos sin procesar y los fragmentos versionados juntos.
- Actualiza de text-embedding-3-small a un modelo más nuevo — rellena los 500M vectores in situ, con embeddings antiguos y nuevos coexistiendo hasta que hagas el cambio.
- Construye y versiona los paquetes de contexto que tus agentes de IA recuperan en tiempo de ejecución — qué se recupera, cómo está estructurado, cómo se comprime para una ventana de contexto.
A medida que los modelos se comoditizan, la calidad de lo que les alimentas importa más que qué modelo eliges. Esta disciplina emergente — Ingeniería de Contexto — pertenece al lake: cerca de los datos, versionada junto a ellos, reproducible de extremo a extremo. Vector Lakebase la convierte en una operación de primera clase, no en scripts ad hoc unidos con cron jobs.
Clustering, deduplicación y descubrimiento de anomalías
Esencial para cualquier equipo que entrene o ajuste sus propios modelos — y totalmente ausente del paradigma de bases de datos vectoriales:
- Deduplicación: Los ejemplos casi duplicados en tu conjunto de datos de ajuste fino de LLM inflan la pérdida de entrenamiento y sesgan el comportamiento del modelo. Identifica casi duplicados, emite un conjunto canónico, escribe las etiquetas de deduplicación de vuelta como una columna.
- Clustering: Entiende qué contiene realmente tu conjunto de datos antes de entrenar. Agrupa tu espacio de embeddings — a menudo encontrarás que el 40% de un conjunto de datos "diverso" son variaciones menores sobre los mismos pocos temas.
- Descubrimiento de anomalías: Para vehículos autónomos, robótica o cualquier modelo crítico para la seguridad — encuentra el 0,1% de las muestras que no se parecen en nada al resto. Márcalas, priorízalas para etiquetado e inclúyelas en el entrenamiento. No puedes encontrarlas sin un índice; no puedes actuar sobre ellas sin escribir los resultados de vuelta al lake.
Vector Lakebase trata estas tareas como operaciones distribuidas de primera clase: conscientes de los índices, paralelizadas a través de los datos donde viven, escribiendo resultados en formatos abiertos. La salida de una ejecución de deduplicación se convierte en una columna en la misma tabla.
Quién ya está construyendo sobre esto
Los primeros socios de diseño de Vector Lakebase abarcan dos de los problemas de datos de IA más difíciles a escala.
Empresas líderes de conducción autónoma y vehículos eléctricos lo usan para extraer casos límite de miles de millones de embeddings de escenas de conducción — los raros escenarios viales que determinan si un sistema de conducción autónoma es seguro. Una empresa líder de modelos fundacionales lo usa para la detección de casi duplicados en corpus de preentrenamiento — deduplicando miles de millones de ejemplos para mejorar la calidad del modelo antes de gastar una sola hora de GPU en entrenamiento.
Ya tenemos Databricks Lakebase. ¿Necesitamos otro?
Es una pregunta justa, y la respuesta requiere entender qué es realmente Databricks Lakebase.
Databricks Lakebase — construido sobre su adquisición de Neon — integra un motor PostgreSQL serverless en la plataforma Databricks. El problema que resuelve: OLTP y OLAP siempre han sido sistemas separados. Databricks está colapsando esa frontera. Ese es un problema real que vale la pena resolver. Pero es un problema fundamentalmente diferente.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Usuario principal | Ingenieros backend, ingenieros de datos | Ingenieros de ML, equipos de plataformas de IA |
| Datos principales | Filas, cuentas, transacciones | Embeddings, documentos, multimodal |
| Modelo de almacenamiento | Almacenamiento Postgres + Delta Lake (separado) | Tabla única de lake, unificada |
| Embedding por lotes / dedup | Fuera de alcance | Operación de primera clase |
| Ingeniería de Contexto | Fuera de alcance | Capacidad central |
| Se construye sobre el lake existente | Parcial | Sí — migración cero |
| Optimización de formatos | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, datos no estructurados nativos |
| OLTP (transacciones) | ✓ | N/A |
Databricks Lakebase colapsa la frontera OLTP/OLAP. Vector Lakebase colapsa la frontera entre donde viven tus datos de IA y donde se ejecutan tus operaciones de IA. Son complementarios, no competitivos. Muchos equipos usarán ambos.
La apuesta arquitectónica
En 2013, Databricks preguntó: ¿Y si la analítica SQL viviera en el lake? Esa pregunta valía $40 mil millones.
La siguiente pregunta es: ¿Y si las operaciones de datos nativas de IA — recuperación RAG, memoria de agentes, embedding por lotes, curación de datos para entrenamiento de modelos, ingeniería de contexto — también vivieran en el lake?
Esa es la apuesta detrás de Vector Lakebase. No una nueva base de datos a la que migrar. No una capa de consulta añadida a tu lake existente. Una base unificada donde tus datos viven una sola vez, se indexan una sola vez y sirven a cada carga de trabajo de IA — sin duplicación, sin sobrecarga de ETL, sin luchar contra la gravedad.
La carrera de la IA recompensa la velocidad. Cada semana que tu equipo dedica a construir pipelines de sincronización, depurar datos obsoletos o migrar entre sistemas es una semana que tus competidores dedican a lanzar funcionalidades de IA. La infraestructura debería ser un acelerador, no un cuello de botella. Los equipos que ganan no son los que tienen los mejores modelos — son los que eliminaron la fricción entre sus datos y su IA.
Construye sobre tus tablas Iceberg o data lake existentes. Sin migración. Sin duplicación. Avanza rápido — tus datos permanecen donde están y se vuelven buscables, procesables y listos para IA en minutos.
Eso es Vector Lakebase.
Zilliz Vector Lakebase está disponible en vista previa pública
Hemos lanzado la vista previa pública de Zilliz Vector Lakebase — una evolución importante de Zilliz Cloud, de una base de datos vectorial administrada a una plataforma unificada de datos semánticos, que combina el servicio vectorial de baja latencia con la apertura, escalabilidad y economía de un data lake.
Capacidades principales de Zilliz Vector Lakebase:
- Servicio por niveles optimizado para diferentes equilibrios entre rendimiento en tiempo real y coste
- Búsqueda bajo demanda para cargas de trabajo a gran escala o exploratorias sin cómputo siempre activo
- Búsqueda en data lake externo — indexa y busca directamente sobre los datos de tu lake existente
- Búsqueda de espectro completo en vectores, texto, JSON y datos geoespaciales con recuperación híbrida y reranking
- Almacenamiento unificado nativo del lake construido sobre Vortex, un formato abierto con lecturas aleatorias más rápidas y económicas que Lance o Parquet
Si tu stack actual separa el servicio y el descubrimiento en sistemas distintos, podría valer la pena echar un vistazo a Vector Lakebase. Pruébalo en Zilliz Cloud — los nuevos registros con correo electrónico laboral reciben $100 en créditos gratis — o habla con nosotros sobre tu caso de uso.

Sigue leyendo

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.