




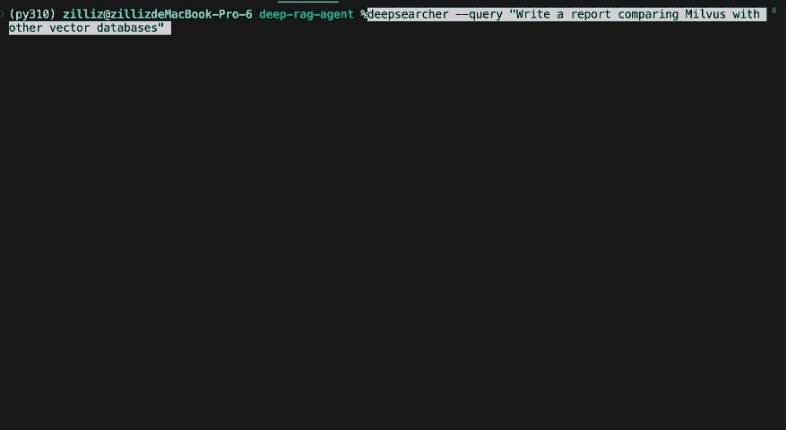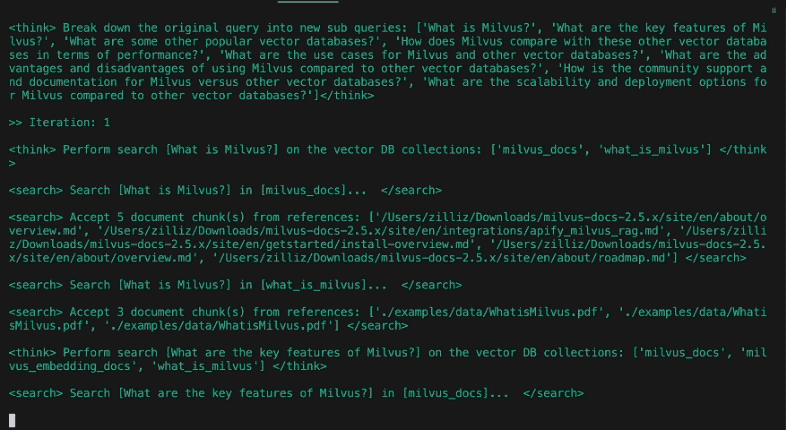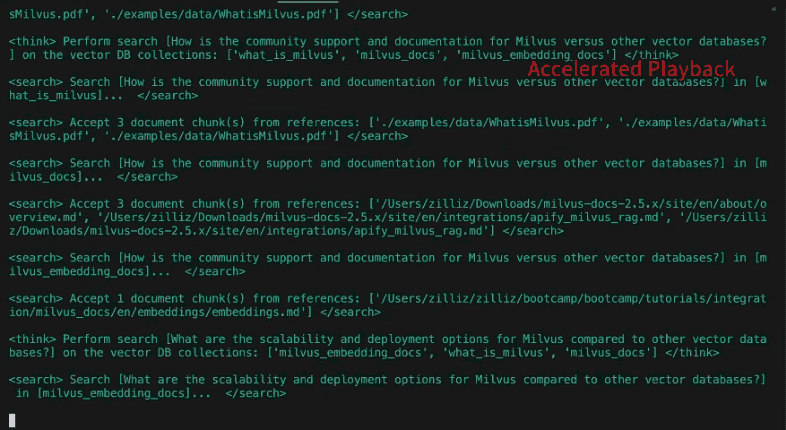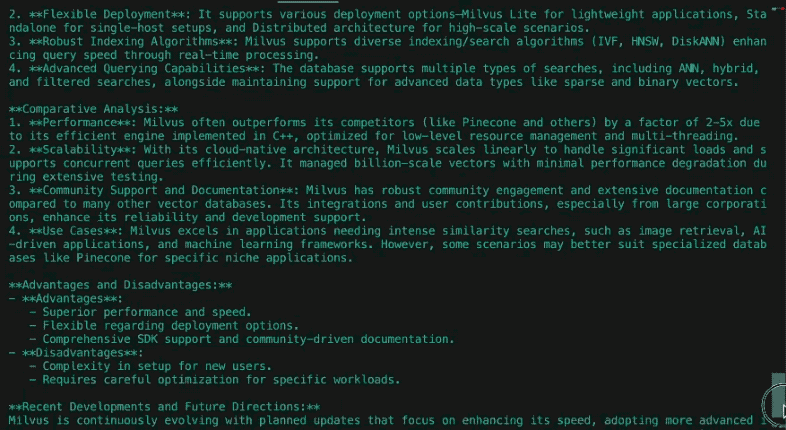
Presentamos DeepSearcher: Una investigación profunda local de código abierto
 deep researcher.gif
deep researcher.gif
En el post anterior, "I Built a Deep Research with Open Source-and So Can You!", explicamos algunos de los principios en los que se basan los agentes de investigación y construimos un prototipo sencillo que genera informes detallados sobre un tema o pregunta determinados. El artículo y el cuaderno correspondiente mostraban los conceptos fundamentales de uso de herramientas, descomposición de consultas, razonamiento y reflexión. El ejemplo de nuestro post anterior, en contraste con la Investigación Profunda de OpenAI, se ejecutó localmente, utilizando sólo modelos y herramientas de código abierto como Milvus y LangChain. (Te animo a que leas el artículo anterior antes de continuar).
En las semanas siguientes, hubo una explosión de interés en comprender y reproducir la Investigación Profunda de OpenAI. Véase, por ejemplo, Perplexity Deep Research y Hugging Face's Open DeepResearch. Estas herramientas difieren en arquitectura y metodología, aunque comparten un objetivo: investigar de forma iterativa un tema o pregunta navegando por la web o por documentos internos y elaborar un informe detallado, fundamentado y bien estructurado. Es importante destacar que el agente subyacente automatiza el razonamiento sobre qué acción tomar en cada paso intermedio.
En este post, nos basamos en el anterior y presentamos el proyecto de código abierto DeepSearcher de Zilliz. Nuestro agente demuestra conceptos adicionales: enrutamiento de consultas, flujo de ejecución condicional y rastreo web como herramienta. Se presenta como una biblioteca Python y una herramienta de línea de comandos en lugar de un cuaderno Jupyter, y cuenta con más funciones que nuestro post anterior. Por ejemplo, puede introducir múltiples documentos fuente y establecer el modelo de incrustación y la base de datos vectorial utilizados mediante un archivo de configuración. Aunque todavía es relativamente simple, DeepSearcher es un gran escaparate de RAG agentic y es un paso más hacia un estado de la técnica de aplicaciones de IA.
Además, exploramos la necesidad de servicios de inferencia más rápidos y eficientes. Los modelos de razonamiento hacen uso del "escalado de inferencia", es decir, del cálculo adicional, para mejorar sus resultados, y eso, combinado con el hecho de que un único informe puede requerir cientos o miles de llamadas LLM, hace que el ancho de banda de inferencia sea el principal cuello de botella. Utilizamos el modelo de razonamiento DeepSeek-R1 en el hardware personalizado de SambaNova, que es el doble de rápido en tokens de salida por segundo que el competidor más cercano (véase la figura siguiente).
SambaNova Cloud también ofrece inferencia como servicio para otros modelos de código abierto, como Llama 3.x, Qwen2.5 y QwQ. El servicio de inferencia se ejecuta en el chip personalizado de SambaNova denominado unidad de flujo de datos reconfigurable (RDU), que está especialmente diseñado para la inferencia eficiente en modelos de IA Generativa, reduciendo el coste y aumentando la velocidad de inferencia. Más información en su sitio web
Velocidad de salida - deepseek r1.png](https://assets.zilliz.com/Output_speed_deepseek_r1_d820329f0a.png)
Arquitectura de DeepSearcher
La arquitectura de DeepSearcher sigue nuestro post anterior dividiendo el problema en cuatro pasos - definir/refinar la pregunta, investigar, analizar, sintetizar - aunque esta vez con algún solapamiento. Repasamos cada paso, destacando las mejoras de DeepSearcher.
arquitectura.png](https://assets.zilliz.com/deepsearcher_architecture_088c7066d1.png)
Definir y refinar la pregunta
Descomponga la pregunta original en nuevas subpreguntas: [
¿Cómo ha evolucionado el impacto cultural y la relevancia social de Los Simpson desde su estreno hasta la actualidad?
¿Qué cambios se han producido en el desarrollo de los personajes, el humor y los estilos narrativos en las distintas temporadas de Los Simpson?
¿Cómo ha cambiado el estilo de animación y la tecnología de producción de Los Simpson a lo largo del tiempo?
¿Cómo han cambiado la demografía, la recepción y los índices de audiencia de Los Simpson a lo largo de su historia?]
En el diseño de DeepSearcher, los límites entre investigar y refinar la pregunta son difusos. La consulta inicial del usuario se descompone en subconsultas, de forma muy similar a la entrada anterior. Véase más arriba las subconsultas iniciales producidas a partir de la consulta "¿Cómo han cambiado Los Simpson con el tiempo?". Sin embargo, el siguiente paso de la investigación continuará refinando la pregunta según sea necesario.
Investigación y análisis
Una vez desglosada la consulta en subconsultas, comienza la parte de investigación del agente. Tiene, a grandes rasgos, cuatro pasos: enrutamiento, búsqueda, reflexión y repetición condicional.
Enrutamiento
Nuestra base de datos contiene múltiples tablas o colecciones de diferentes fuentes. Sería más eficiente si pudiéramos restringir nuestra búsqueda semántica sólo a aquellas fuentes que son relevantes para la consulta en cuestión. Un enrutador de consultas pide a un LLM que decida de qué colecciones debe recuperarse la información.
Este es el método para formar el indicador de enrutamiento de consultas:
def get_vector_db_search_prompt(
pregunta: str,
nombres_colección: Lista[str],
descripciones_colección: Lista[str],
contexto: Lista[str] = None,
):
secciones = []
# prompt común
common_prompt = f"""Eres un analista avanzado de problemas de IA. Utiliza tu capacidad de razonamiento y la información histórica de las conversaciones, basándote en todos los conjuntos de datos existentes, para obtener respuestas absolutamente precisas a las siguientes preguntas, y genera una pregunta adecuada para cada conjunto de datos según la descripción del conjunto de datos que pueda estar relacionada con la pregunta.
Pregunta {pregunta}
"""
sections.append(pregunta_común)
# conjunto_de_datos
conjunto_datos = []
for i, nombre_colección in enumerar(nombres_colección):
data_set.append(f"{nombre_colección}: {descripciones_colección[i]}")
data_set_prompt = f"""A continuación se muestra toda la información del conjunto de datos. El formato de la información del conjunto de datos es nombre del conjunto de datos: descripción del conjunto de datos.
Conjuntos de datos y descripciones:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# indicación de contexto
si contexto:
context_prompt = f"""La siguiente es una versión condensada de la conversación histórica. Esta información debe combinarse en este análisis para generar preguntas que se acerquen más a la respuesta. No debe generar preguntas iguales o similares para el mismo conjunto de datos, ni puede regenerar preguntas para conjuntos de datos que se haya determinado que no están relacionados.
Conversación histórica:
"""
sections.append(context_prompt + "\n".join(context))
# solicitud de respuesta
response_prompt = f"""Basándose en lo anterior, sólo puede seleccionar algunos conjuntos de datos de la siguiente lista de conjuntos de datos para generar preguntas relacionadas adecuadas para los conjuntos de datos seleccionados con el fin de resolver los problemas anteriores. El formato de salida es json, donde la clave es el nombre del conjunto de datos y el valor es la pregunta generada correspondiente.
Conjuntos de datos:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """"Responda exclusivamente en formato JSON válido que coincida con el esquema JSON exacto.
Requisitos críticos:
- Incluir SÓLO UN tipo de acción
- No añadir nunca claves no compatibles
- Excluir todo texto, markdown o explicaciones que no sean JSON
- Mantener una sintaxis JSON estricta"""
sections.append(pie de página)
return "\n\n".join(sections)
Hacemos que el LLM devuelva la salida estructurada como JSON para convertir fácilmente su salida en una decisión sobre qué hacer a continuación.
Búsqueda
Una vez seleccionadas varias colecciones de bases de datos mediante el paso anterior, el paso de búsqueda realiza una búsqueda de similitud con Milvus. Al igual que en el paso anterior, los datos de origen se han especificado de antemano, troceado, incrustado y almacenado en la base de datos vectorial. Para DeepSearcher, las fuentes de datos, tanto locales como en línea, deben especificarse manualmente. Dejamos la búsqueda en línea para futuros trabajos.
Reflexión
A diferencia del post anterior, DeepSearcher ilustra una verdadera forma de reflexión agéntica, introduciendo los resultados anteriores como contexto en un indicador que "reflexiona" sobre si las preguntas formuladas hasta el momento y los trozos recuperados relevantes contienen alguna laguna informativa. Esto puede considerarse un paso del análisis.
Este es el método para crear la pregunta:
``python def get_reflect_prompt( pregunta: str, mini_preguntas: Lista[str], mini_preguntas: Lista[str], ): mini_cadena_str = "" for i, chunk in enumerate(mini_chuncks): mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" reflect_prompt = f"""Determine si se necesitan consultas de búsqueda adicionales basándose en la consulta original, las subconsultas anteriores y todos los trozos de documentos recuperados. Si se requiere más investigación, proporcione una lista Python de hasta 3 consultas de búsqueda. Si no es necesario realizar más búsquedas, devuelva una lista vacía.
Si la consulta original es para escribir un informe, entonces prefiere generar algunas consultas adicionales, en su lugar devuelva una lista vacía.
Consulta original: {pregunta}
Subconsultas Anteriores: {mini_consultas}
Trozos relacionados:
{mini_chunk_str}
"""
footer = """Responde exclusivamente en formato válido List of str sin ningún otro texto."""
return reflect_prompt + footer
Una vez más, hacemos que el LLM devuelva una salida estructurada, esta vez como datos interpretables por Python.
He aquí un ejemplo de nuevas subconsultas "descubiertas" por reflexión tras responder a las subconsultas iniciales anteriores:
Nuevas consultas de búsqueda para la siguiente iteración: [ "¿Cómo han influido los cambios en el reparto de voces y el equipo de producción de Los Simpson en la evolución del programa a lo largo de las distintas temporadas?", "¿Qué papel ha desempeñado la sátira y el comentario social de Los Simpson en su adaptación a temas contemporáneos a lo largo de las décadas?", "¿Cómo han abordado e incorporado Los Simpson los cambios en el consumo de medios, como los servicios de streaming, a sus estrategias de distribución y contenidos?"].
#### Repetición condicional
A diferencia de nuestro post anterior, DeepSearcher ilustra el flujo de ejecución condicional. Después de reflexionar sobre si las preguntas y respuestas hasta el momento están completas, si hay preguntas adicionales que hacer el agente repite los pasos anteriores. Es importante destacar que el flujo de ejecución (un bucle while) es una función de la salida del LLM en lugar de estar codificado. En este caso sólo hay una opción binaria: _repetir la investigación_ o _generar un informe_. En agentes más complejos puede haber varias como: _seguir hipervínculo_, _recuperar trozos, almacenar en memoria, reflexionar_, etc. De esta forma, la pregunta sigue refinándose según el agente lo considere oportuno hasta que decide salir del bucle y generar el informe. En nuestro ejemplo de Los Simpson, DeepSearcher realiza dos rondas más para rellenar los huecos con subconsultas adicionales.
### Sintetizar
Por último, la pregunta totalmente descompuesta y los trozos recuperados se sintetizan en un informe con una única pregunta. Este es el código para crear la pregunta:
```python
def get_final_answer_prompt(
pregunta: str,
mini_preguntas: Lista[str],
mini_preguntas: Lista[str],
):
mini_cadena_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""Eres un experto en análisis de contenidos de IA, bueno resumiendo contenidos. Por favor, resume una respuesta o informe específico y detallado basado en las consultas anteriores y los trozos de documentos recuperados.
Consulta original: {pregunta}
Subconsultas anteriores: {mini_preguntas}
Trozos relacionados:
{mini_chunk_str}
"""
return resumen_prompt
Este enfoque tiene la ventaja sobre nuestro prototipo, que analizaba cada pregunta por separado y simplemente concatenaba el resultado, de producir un informe en el que todas las secciones son coherentes entre sí, es decir, que no contiene información repetida o contradictoria. Un sistema más complejo podría combinar aspectos de ambos, utilizando un flujo de ejecución condicional para estructurar el informe, resumir, reescribir, reflexionar y pivotar, etc., lo que dejamos para futuros trabajos.
Resultados
He aquí una muestra del informe generado por la consulta "¿Cómo han cambiado Los Simpson a lo largo del tiempo?" con DeepSeek-R1 pasando la página de Wikipedia sobre Los Simpson como material fuente:
Informe: La evolución de Los Simpson (1989-Presente)
1. Impacto cultural y relevancia social
Los Simpson debutaron como una crítica subversiva de la vida de la clase media estadounidense, ganando notoriedad por su audaz sátira en la década de 1990. Inicialmente un fenómeno contracultural, desafiaba las normas con episodios que abordaban la religión, la política y el consumismo. Con el tiempo, su dominio cultural fue disminuyendo a medida que competidores como South Park y Padre de familia iban más allá. En la década de 2010, la serie pasó de marcar tendencias a convertirse en una institución nostálgica, equilibrando el atractivo de su legado con intentos de abordar temas modernos como el cambio climático y los derechos LGBTQ+, aunque con menos resonancia social.
...
Conclusión
Los Simpson pasaron de ser una sátira radical a una institución televisiva, sorteando los cambios tecnológicos, políticos y las expectativas de la audiencia. Aunque su brillantez de la época dorada sigue siendo inigualable, su adaptabilidad -a través del streaming, la actualización del humor y el alcance global- mantiene su lugar como piedra de toque cultural. La longevidad del programa refleja tanto la nostalgia como una aceptación pragmática del cambio, incluso cuando se enfrenta a los retos de la relevancia en un panorama mediático fragmentado.
Para comparar, consulte el informe completo aquí y un informe elaborado por DeepSearcher con GPT-4o mini.
Discusión
Presentamos DeepSearcher, un agente para realizar investigaciones y escribir informes. Nuestro sistema está construido sobre la idea de nuestro artículo anterior, añadiendo características como flujo de ejecución condicional, enrutamiento de consultas y una interfaz mejorada. Pasamos de la inferencia local con un pequeño modelo de razonamiento cuantificado de 4 bits a un servicio de inferencia en línea para el modelo masivo DeepSeek-R1, mejorando cualitativamente nuestro informe de resultados. DeepSearcher funciona con la mayoría de los servicios de inferencia como OpenAI, Gemini, DeepSeek y Grok 3 (¡próximamente!).
Los modelos de razonamiento, especialmente los utilizados en los agentes de investigación, se basan en la inferencia, y tuvimos la suerte de poder utilizar la versión más rápida de DeepSeek-R1 de SambaNova, que se ejecuta en su hardware personalizado. Para nuestra consulta de demostración, realizamos sesenta y cinco llamadas al servicio de inferencia DeepSeek-R1 de SambaNova, introduciendo alrededor de 25.000 tokens, generando 22.000 tokens y costando 0,30 dólares. Nos impresionó la velocidad de inferencia, dado que el modelo contiene 671.000 millones de parámetros y tiene un tamaño de 3/4 de terabyte. Más información aquí
Seguiremos profundizando en este trabajo en futuros posts, examinando conceptos agenticos adicionales y el espacio de diseño de los agentes de investigación. Mientras tanto, invitamos a todo el mundo a que pruebe DeepSearcher, nos incluya en GitHub, ¡y comparta sus comentarios!
Recursos
DeepSearcher** de Zilliz](https://github.com/zilliztech/deep-searcher)
Lecturas de fondo: "Construí una investigación profunda con código abierto, ¡y tú también puedes!"
"SambaNova lanza el DeepSeek-R1 671B más rápido y con mayor eficiencia"".
DeepSearcher: Informe DeepSeek-R1 sobre Los Simpson
DeepSearcher: GPT-4o mini informe sobre Los Simpson
Base de datos vectorial de código abierto Milvus](https://milvus.io/docs)

Sigue leyendo

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.