




Desglose de habilidades de Zilliz: cómo los agentes de IA dominan las bases de datos vectoriales
Originalmente por ShugeX, profesional independiente de AI-ops y colaborador activo de la comunidad de Milvus. Traducido y republicado con permiso.
Imagina que estás usando Claude Code para crear una aplicación RAG con Milvus. Cada paso —crear una colección, definir un esquema, insertar vectores, ejecutar búsqueda híbrida— te hace ir y venir por la documentación de pymilvus para encontrar la API correcta, y luego volver al editor para integrarla. Y si estás en Zilliz Cloud, también estás saltando al navegador para iniciar sesión en la consola para la gestión de clústeres, la supervisión y la configuración de copias de seguridad. El entorno de desarrollo y el entorno de operaciones son dos mundos diferentes.
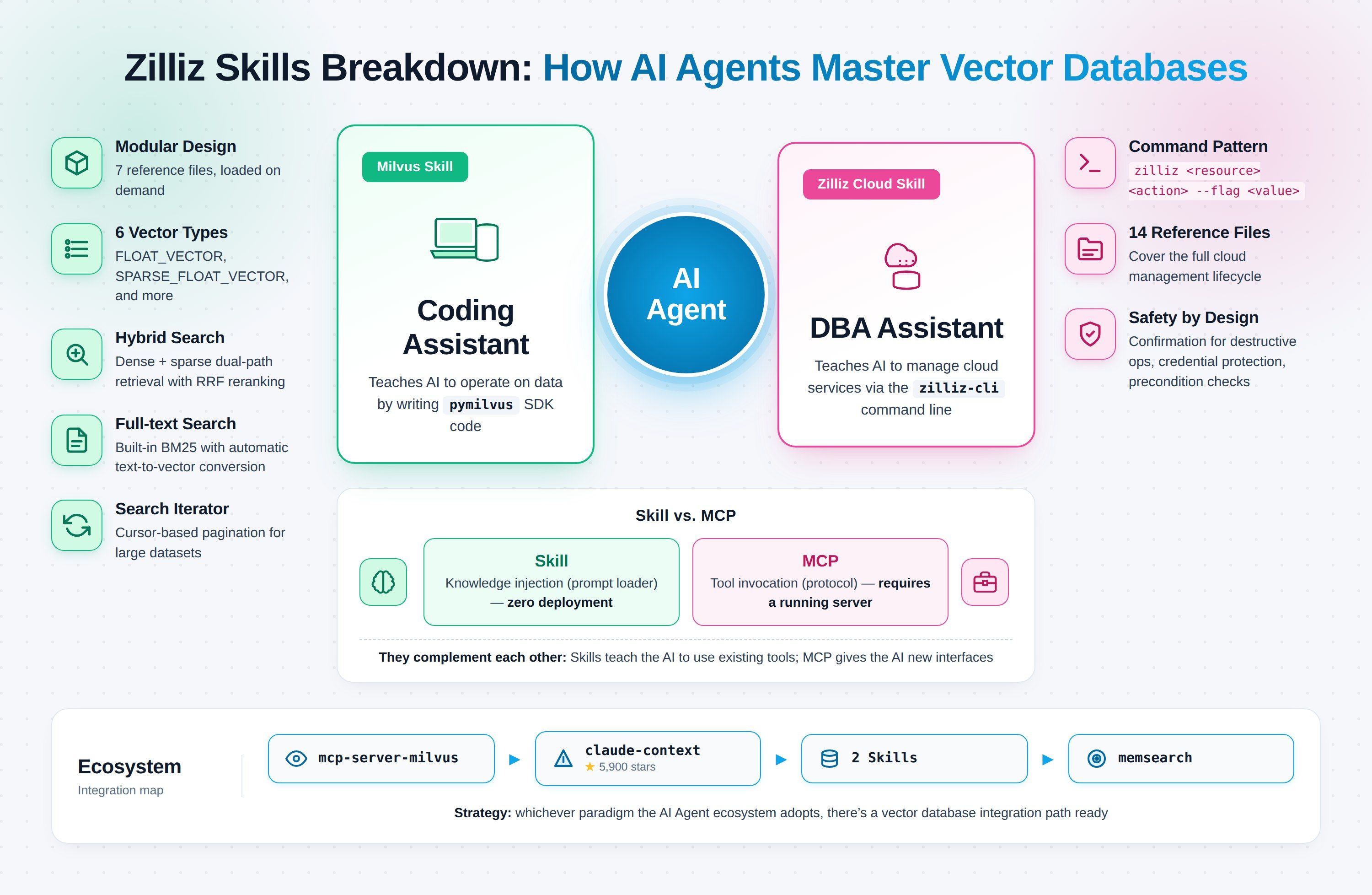
Las dos Claude Code Skills recientes de Zilliz apuntan exactamente a ese punto de ruptura. Milvus Skill enseña al agente a operar la base de datos vectorial mediante el SDK de Python. Zilliz Cloud Skill enseña al agente a gestionar todo lo del lado de la nube mediante zilliz-cli. Cada Skill se encarga de un dominio; juntas convierten dev y ops en una sesión continua de Claude Code.
Después de leer de principio a fin el código fuente de ambas Skills, encontré mucho que vale la pena desglosar: diseño modular, patrones de seguridad y dónde encaja Skill junto a MCP. Este artículo recorre cada una.
Qué hacen Milvus Skill y Zilliz Cloud Skill
Las dos Skills no son dos versiones de lo mismo. Apuntan a dos fallos de corrección diferentes.
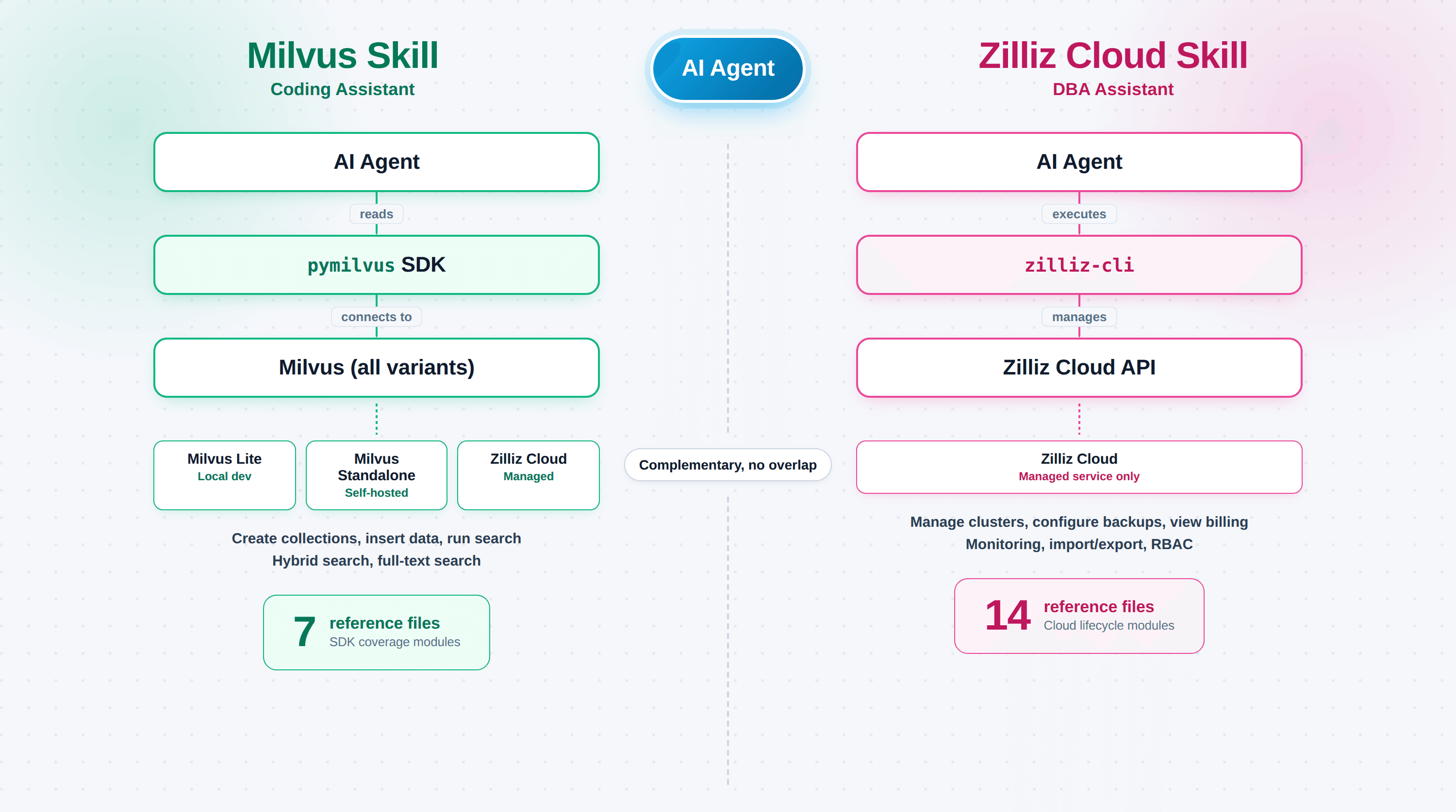
Milvus Skill (zilliztech/milvus-skill) enseña al agente pymilvus, el SDK de Python para conectarse, crear colecciones, insertar vectores y ejecutar búsquedas. Es un asistente de programación, y funciona contra cualquier despliegue de Milvus: Milvus Lite, Standalone/Cluster autohospedado o Zilliz Cloud. El fallo que corrige: código de pymilvus que compila pero no hace lo que pediste porque el agente usó una forma de API obsoleta.
Zilliz Cloud Skill (zilliztech/zilliz-skill) enseña al agente zilliz-cli, la herramienta de línea de comandos que cubre clústeres, copias de seguridad, supervisión y facturación. Es un asistente DBA, y solo funciona contra Zilliz Cloud (Milvus autohospedado no tiene plano de control). El fallo que corrige: comandos alucinados contra un sistema de producción en vivo, donde un mal zilliz cluster delete cuesta más que un error de compilación.
En una línea:
- Milvus Skill → el agente escribe código que opera datos
- Zilliz Cloud Skill → el agente ejecuta comandos que gestionan servicios
| Dimensión | Milvus Skill | Zilliz Cloud Skill |
|---|---|---|
| Interfaz | Python (pymilvus) | CLI (zilliz-cli) |
| Rol | Asistente de programación | Asistente DBA |
| Funciona contra | Todos los despliegues de Milvus + Zilliz Cloud | Solo Zilliz Cloud |
| Archivos | 7 módulos de referencia | 14 sub-skills |
| Objetivo de corrección | APIs de SDK obsoletas | Comandos de ops poco documentados |
| Tarea típica | Crear colección, insertar, buscar | Aprovisionar clúster, configurar copias de seguridad, revisar facturación |
Milvus Skill: enseñar al agente a escribir pymilvus fiable
La carpeta references/ de Milvus Skill contiene siete archivos, cada uno mapeado a un área independiente de capacidades de pymilvus. Cuando el agente maneja una tarea específica, carga solo el archivo relevante en lugar de volcar toda la documentación en el contexto:
| Archivo | Cubre |
|---|---|
collection.md | Tipos de datos, definiciones de campos, operaciones de colección |
vector.md | CRUD de vectores, búsqueda híbrida, búsqueda de texto completo, iteradores |
index.md | Tipos de índice, tipos de métrica, gestión de índices |
partition.md | Gestión de particiones |
database.md | Gestión de bases de datos |
user-role.md | RBAC |
patterns.md | Patrones comunes (RAG, búsqueda híbrida, etc.) |
¿Estás creando un esquema? El agente extrae collection.md. ¿Estás ejecutando una búsqueda? Extrae vector.md. El resto queda fuera. Las ventanas de contexto son finitas; la carga bajo demanda supera a volcarlo todo.
Tipos de datos admitidos: más ricos de lo que esperarías
Al hojear collection.md, Milvus admite más tipos de vectores de los que la mayoría de los desarrolladores cree:
- Escalares:
BOOL,INT8/16/32/64,FLOAT,DOUBLE,VARCHAR,JSON,ARRAY - Vectores:
FLOAT_VECTOR— flotante de 32 bits, el valor predeterminadoFLOAT16_VECTOR— media precisión, ahorra memoriaBFLOAT16_VECTOR— BF16, común en pipelines de aprendizaje profundoBINARY_VECTOR— binarioSPARSE_FLOAT_VECTOR— disperso, para búsqueda de texto completoINT8_VECTOR— cuantizado, compresión adicional
Búsqueda híbrida: la característica más destacable que cubren estas Skills
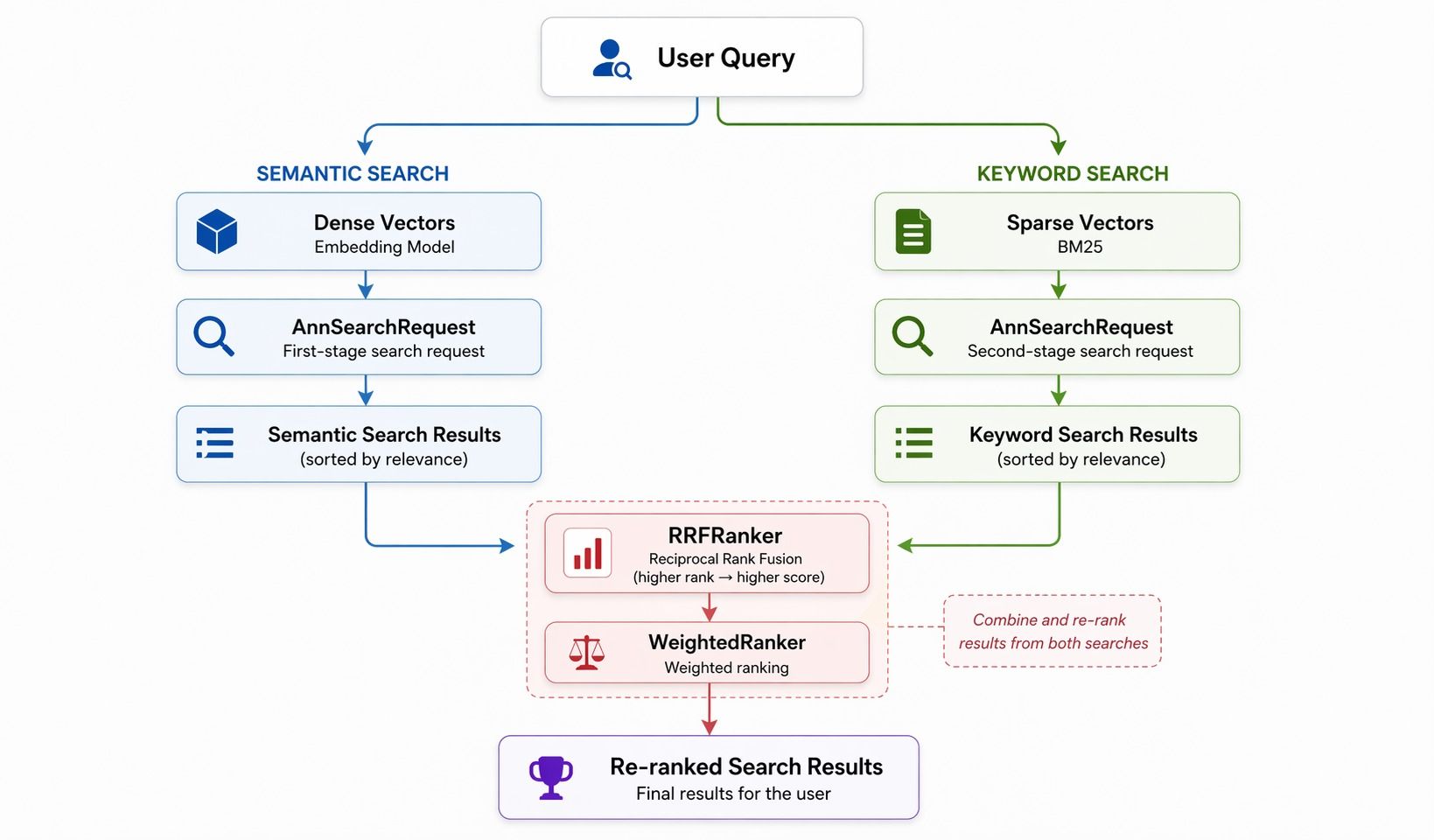
patterns.md documenta cuatro patrones comunes. La búsqueda híbrida tiene la mayor cantidad de partes. La búsqueda de vectores densos (semántica) y la búsqueda de vectores dispersos (palabra clave) se ejecutan en paralelo, luego RRF (Reciprocal Rank Fusion) o la clasificación ponderada fusionan las dos listas.
Tres componentes básicos:
AnnSearchRequest— uno por cada rama de búsquedaRRFRanker/WeightedRanker— estrategia de fusiónSPARSE_FLOAT_VECTOR— el campo de vector disperso
RRF es simple: para cada resultado, puntuación = 1/rango, sumada entre ramas. Los elementos con rangos más altos ganan. WeightedRanker es una suma ponderada por rama. La Skill explica esto, de modo que el agente genera código utilizable de búsqueda híbrida sin que el desarrollador lea el artículo de RRF.
Búsqueda de texto completo BM25 integrada de Milvus
Milvus Skill también codifica: la búsqueda de texto completo Sparse-BM25 integrada de Milvus 2.5. Combinado con Function y FunctionType.BM25, Milvus convierte texto sin procesar en vectores dispersos internamente, omitiendo modelos de embeddings externos y pipelines manuales de TF-IDF.
Antes de la versión 2.5, la búsqueda de texto completo significaba que tenías que lidiar con un tokenizador, calcular TF-IDF a mano y generar tú mismo el vector disperso. Ahora le dices al agente lo que quieres, y la Skill lo guía para generar la colección con la Function BM25 conectada correctamente.
Iteradores de búsqueda: paginación para colecciones de millones de filas
vector.md también cubre search_iterator y query_iterator, paginación estilo cursor para colecciones de millones o miles de millones de filas. Una search simple devuelve un conjunto de resultados de tamaño fijo. Los iteradores recorren páginas sin pérdidas ni duplicados, que es lo que necesita la enumeración completa.
Zilliz Cloud Skill: enseñar al agente a ser tu DBA en la nube
El trabajo de Zilliz Cloud Skill es diferente del de Milvus Skill. En lugar de escribir Python, el agente compone invocaciones de CLI contra un plano de control en vivo, y como un comando incorrecto puede borrar producción, la Skill envuelve esas invocaciones en reglas de seguridad.
Modo de comandos: cómo compone el agente invocaciones de CLI
La Skill codifica una forma de comando consistente:
zilliz <resource> <action> --flag <value>
Ejemplos:
zilliz cluster list— listar todos los clústereszilliz collection create --name my_collection— crear una colecciónzilliz backup create --name daily-backup— crear una copia de seguridad
Tres formatos de salida: json (legible por máquina), table (amigable para humanos), text (simple). El agente elige el que encaje.
14 sub-Skills que cubren todo el ciclo de vida en la nube
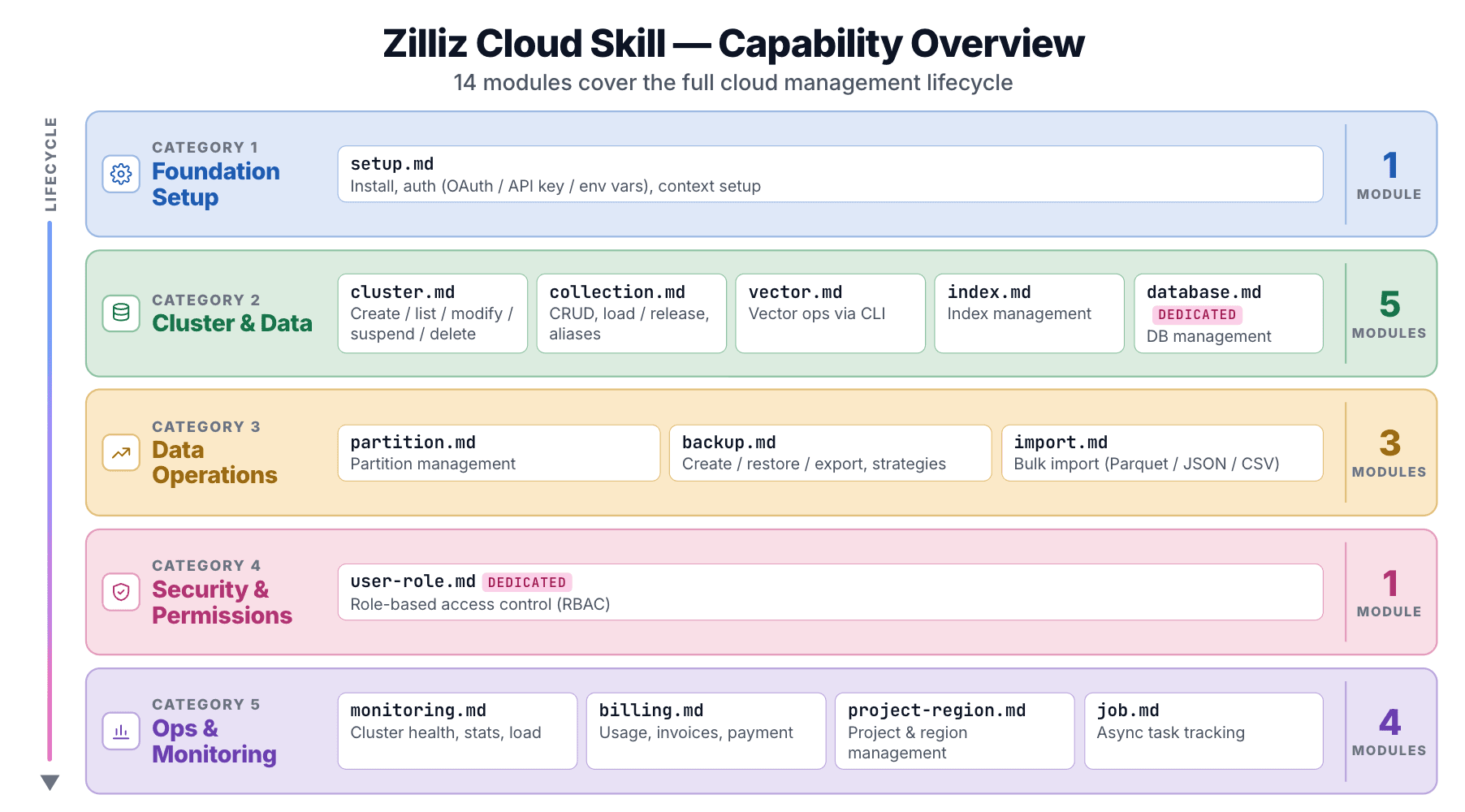
El repo zilliz-plugin incluye 14 sub-skills, cada una bajo skills/<name>/SKILL.md:
| Módulo | Cubre |
|---|---|
setup | Instalación, autenticación (OAuth / clave de API / variable de entorno), configuración del contexto |
cluster | Crear, listar, modificar, suspender, reanudar, eliminar |
collection | CRUD de colecciones, cargar/liberar, alias |
vector | Operaciones vectoriales mediante CLI |
index | Gestión de índices |
database | Gestión de bases de datos (solo Dedicated) |
partition | Gestión de particiones |
user-role | RBAC (solo Dedicated) |
backup | Crear, restaurar, exportar, políticas de copia de seguridad |
import | Importación masiva desde almacenamiento en la nube (Parquet / JSON / CSV) |
billing | Uso, facturas, métodos de pago |
monitoring | Estado del clúster, estadísticas, estados de carga |
project-region | Gestión de proyectos y regiones |
job | Seguimiento de tareas asíncronas |
Poner en marcha un clúster, configurar la retención de copias de seguridad, revisar una factura: 14 módulos cubren cada operación de la consola de Zilliz Cloud.
La conciencia del nivel está integrada. database y user-role están marcados como solo Dedicated. La Skill sabe que los niveles Free, Serverless y Dedicated tienen diferentes capacidades, así que el agente no intentará operaciones que el nivel de un clúster no pueda admitir.
Tres reglas de seguridad, una en cada módulo
El diseño de seguridad de Zilliz Cloud Skill va varias capas más profundo que el de Milvus Skill. Tres reglas principales aparecen en los archivos SKILL.md individuales:
- Las operaciones destructivas requieren confirmación explícita del usuario. La guía del módulo de clúster dice: "Antes de eliminar un clúster, confirma siempre con el usuario: esto es irreversible." Cada operación destructiva (colecciones, copias de seguridad, bases de datos, usuarios) lleva la misma instrucción.
- Los comandos sensibles se ejecutan en la propia terminal del usuario. El módulo
setupes explícito: "Los comandos de inicio de sesión (zilliz login, zilliz configure) requieren una terminal interactiva y NO PUEDEN ejecutarse dentro de Claude Code. Indica siempre al usuario que los ejecute en su propia terminal." Las credenciales no pasan por el agente. - Las credenciales nunca se muestran. La autenticación se realiza mediante el flujo OAuth del navegador, una clave de API desde la consola o una variable de entorno
ZILLIZ_API_KEY. La Skill nunca imprime secretos.
Esto suena básico, pero un agente con credenciales de Cloud y sin una capa de confirmación podría tomar "limpia los clústeres de prueba" y destruir producción. La Skill cierra esa brecha en la capa de instrucciones, antes de que cualquier comando destructivo llegue a la API.
La puerta de requisitos previos: tres comprobaciones antes de ejecutar cualquier comando
Cada sub-skill ejecuta una comprobación de tres pasos, definida en skills/setup/SKILL.md:
- ¿
zilliz-cliestá instalado? Si no, instalar. - ¿El usuario ha iniciado sesión? Si no, redirigir a autenticación.
- ¿Está establecido el contexto del clúster? Si no, solicitar selección.
La puerta garantiza que el entorno esté listo antes de que se dispare cualquier comando, lo que es más fiable que ejecutar a ciegas y depurar errores después.
¿Por qué son Zilliz Skills y no simplemente MCP?
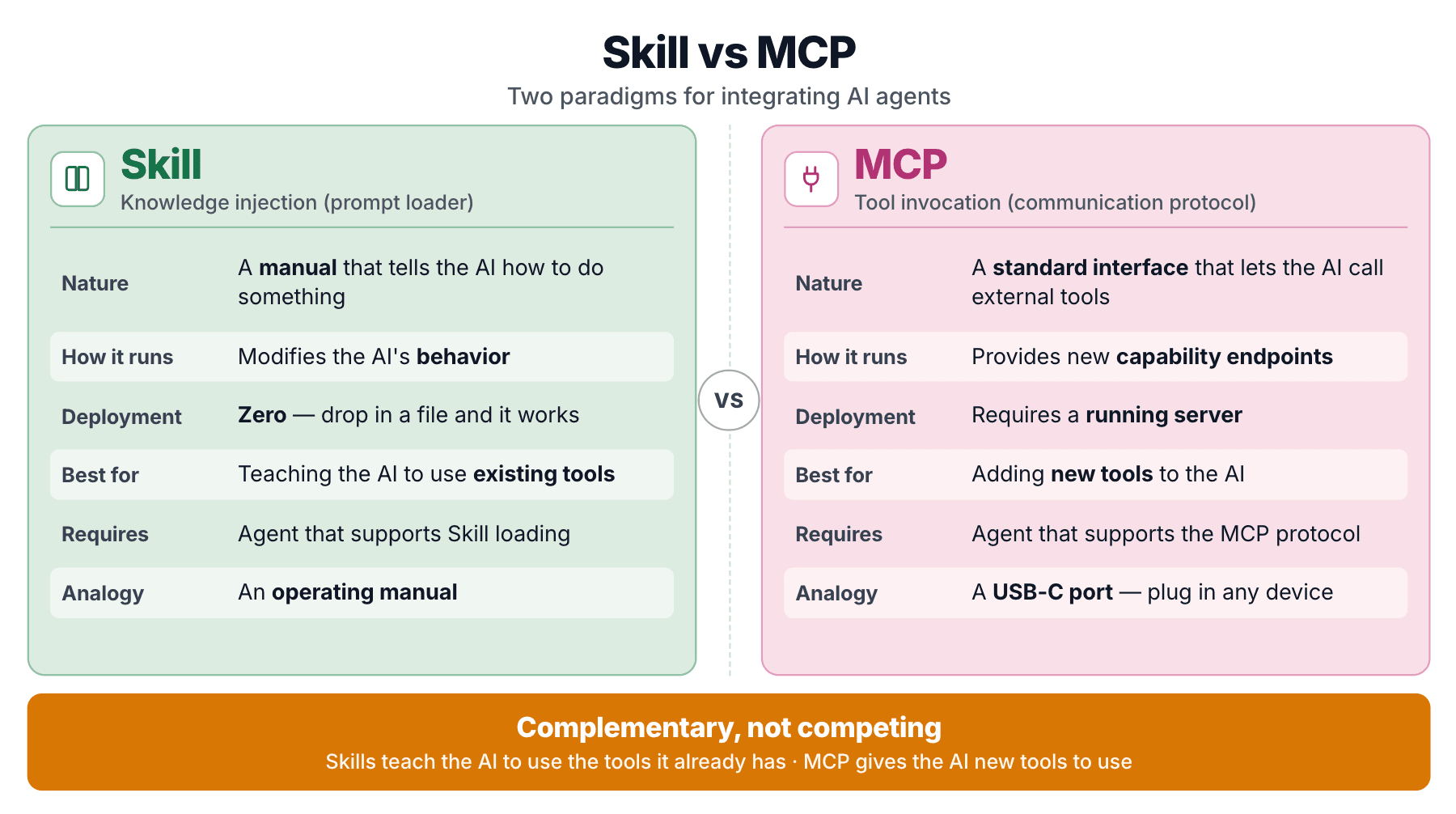
Zilliz ofrece ambos porque resuelven problemas diferentes. Una Skill inyecta conocimiento que el agente consulta al escribir código. Un servidor MCP expone endpoints invocables que el agente puede llamar. mcp-server-milvus es el brazo MCP; Milvus Skill es el brazo de conocimiento. Se superponen en capas en lugar de competir.
Skill es un cargador de prompts
La Skill mínima es una carpeta y un SKILL.md:
my-skill/
├── SKILL.md # instrucciones + metadatos
├── references/ # documentación de referencia (opcional)
├── scripts/ # scripts ejecutables (opcional)
└── assets/ # plantillas, recursos (opcional)
SKILL.md es un manual de instrucciones. Le dice al agente cómo manejar una tarea determinada. Sin código ejecutable, sin proceso de servidor. Solo conocimiento estructurado inyectado en el contexto del modelo bajo demanda.
Una Skill es un cargador de prompts. Conocimiento de dominio empaquetado como un prompt estructurado, cargado dinámicamente.
MCP es un protocolo de herramientas
MCP (Model Context Protocol) adopta una forma diferente. Es un protocolo estandarizado que permite a un agente llamar a herramientas externas a través de una interfaz uniforme. mcp-server-milvus es un servidor MCP que expone endpoints de herramientas como milvus_text_search, milvus_create_collection, etc.
MCP ha sido descrito como "el puerto USB-C para agentes de IA." Resuelve el problema de la estandarización de interfaces de herramientas.
Zilliz Skill vs zilliz MCP
| Dimensión | Skill | MCP |
|---|---|---|
| Esencia | Inyección de conocimiento (prompt) | Invocación de herramientas (protocolo) |
| Qué hace | Modifica cómo se comporta el agente | Da al agente una nueva capacidad |
| Costo de despliegue | Soltar archivos, listo | Se requiere un proceso de servidor |
| Encaja con | Enseñar al agente a usar herramientas que ya tiene | Dar al agente herramientas que no tiene |
| Dependencia | El agente admite la carga de Skills | El agente admite MCP |
La distinción fundamental: Milvus Skill enseña al agente a usar pymilvus. pymilvus ya existe. El Skill no añade capacidad. Corrige la precisión para una capacidad que el agente ya tiene. MCP, en cambio, da al agente endpoints invocables a los que de otro modo no podría acceder.
Un Skill es un manual de operación para una máquina que ya tienes. MCP es un control remoto que hace que una nueva máquina se mueva. Zilliz lo ha dicho directamente en "¿Está muerto MCP? MCP vs CLI vs Agent Skills comparados": ambos patrones persisten.
Dicho esto, los Skills se están popularizando rápidamente. Los rastreadores de la comunidad sitúan el recuento en más de 700,000 paquetes en distintos registros, con ClawHub solo listando más de 5,700 skills. Un proyecto de paquetes de skills en GitHub consiguió 6,600 estrellas en cinco días en abril de 2026.
Escenarios del mundo real: cómo los desarrolladores realmente los usan
Escenario 1: Crear una aplicación RAG
Estás creando una app RAG. Con Milvus Skill instalado, dices:
"Crea una colección de recuperación de documentos: vectores de 768 dimensiones, búsqueda de texto completo BM25, campos para título, cuerpo e embedding."
El agente consulta collection.md y patterns.md y escribe:
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="<URI>", token="<TOKEN>")
schema = client.create_schema(auto_id=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("title", DataType.VARCHAR, max_length=512)
schema.add_field("body", DataType.VARCHAR, max_length=4096, enable_analyzer=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
schema.add_field("body_sparse", DataType.SPARSE_FLOAT_VECTOR)
# Wire BM25 full-text search
schema.add_function(Function(
name="body_bm25",
input_field_names=["body"],
output_field_names=["body_sparse"],
function_type=FunctionType.BM25,
))
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", index_type="AUTOINDEX", metric_type="COSINE")
index_params.add_index(field_name="body_sparse", index_type="AUTOINDEX", metric_type="BM25")
client.create_collection("documents", schema=schema, index_params=index_params)
enable_analyzer=True, el cableado de la Function BM25, la combinación AUTOINDEX con la métrica BM25: ninguna de estas son cosas que quieras que el agente adivine. El Skill las codifica.
Escenario 2: Gestionar un clúster de Zilliz Cloud
"Crea un clúster Serverless en us-east-1 y luego crea una colección con vectores de 768 dimensiones."
El agente ejecuta la comprobación de prerrequisitos y luego emite los comandos de CLI en orden. O bien:
"Muéstrame el estado y el uso de recursos de todos mis clústeres."
El agente ejecuta zilliz cluster list y los comandos zilliz monitoring correspondientes, y luego resume. Las credenciales nunca salen de tu terminal.
Escenario 3: Copias de seguridad y migración de datos
"Configura una política de copia de seguridad diaria para producción, conserva 7 días."
backup.md documenta la sintaxis completa de la política. El agente configura la política directamente.
"Exporta la colección orders del clúster de prueba a S3."
import.md cubre la importación y exportación masivas desde almacenamiento en la nube, incluidos los formatos admitidos (Parquet, JSON, CSV).
Escenario 4: Actualización a búsqueda híbrida
"Actualiza mi búsqueda a híbrida densa + dispersa con RRF."
El agente consulta las notas de vector.md sobre AnnSearchRequest y RRFRanker y escribe el código de búsqueda híbrida. No necesitas estudiar los parámetros de RRF.
Stack de agentes de Zilliz: dónde encajan las dos Skills
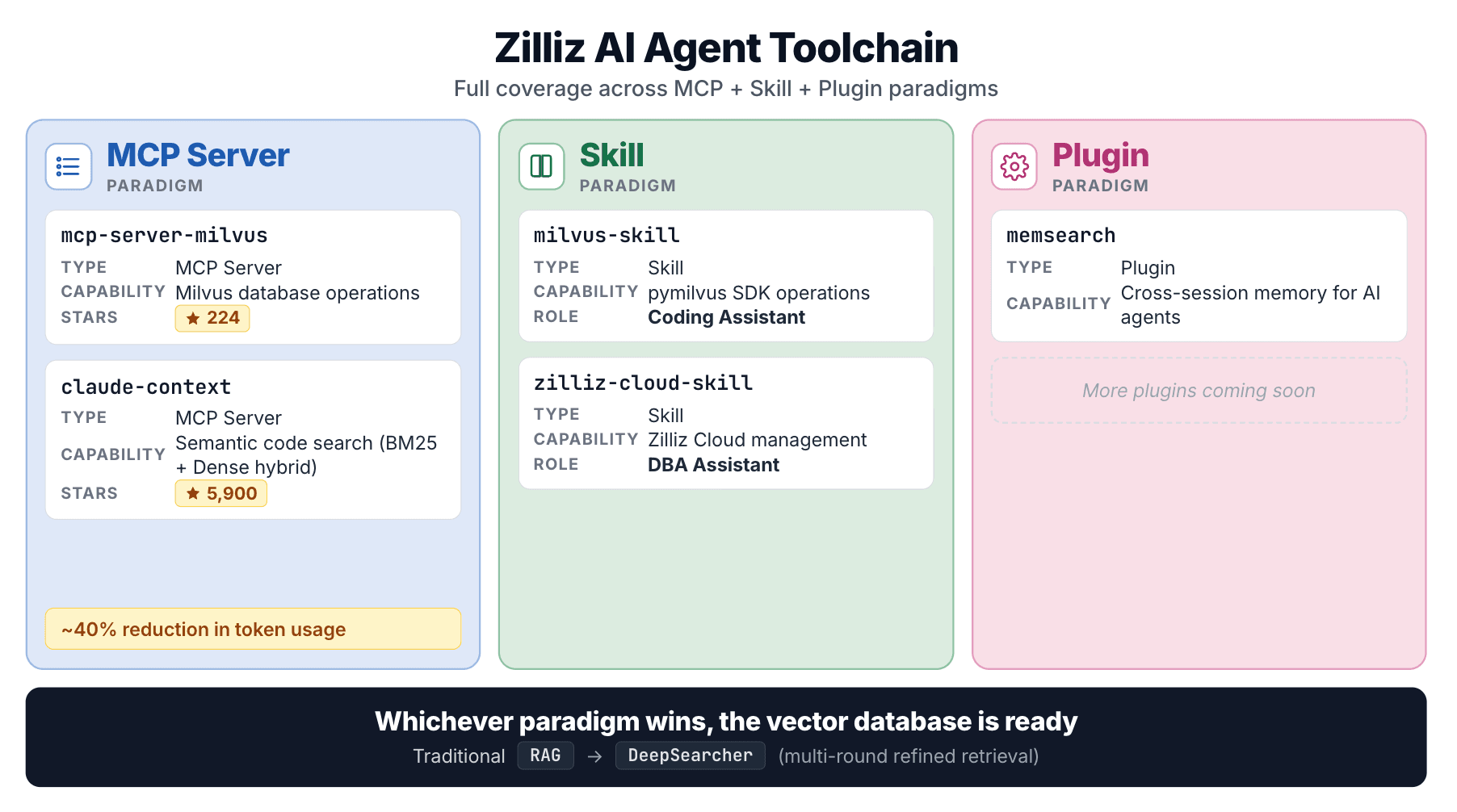
Estas dos Skills forman parte de un esfuerzo más amplio de Zilliz en todos los patrones de integración de agentes:
| Proyecto | Tipo | Cubre |
|---|---|---|
| mcp-server-milvus | Servidor MCP | Operaciones de base de datos Milvus |
| claude-context | Servidor MCP | Búsqueda semántica de código |
| milvus-skill | Skill | SDK pymilvus |
| zilliz-skill | Skill | Gestión de Zilliz Cloud |
| DeepSearcher | Framework de agentes | RAG agéntico de múltiples pasos |
claude-context es el más destacado. Indexa una base de código en una base de datos vectorial, recupera código relevante bajo demanda con búsqueda híbrida (BM25 + densa) y reporta una reducción de tokens de ~40% con una calidad de recuperación equivalente.
Desde MCP hasta Skill, búsqueda de código y frameworks de agentes, la estrategia de Zilliz es consistente: sea cual sea el patrón de integración de agentes que gane, una base de datos vectorial debe tener un punto de entrada de primera clase. Las dos Skills son la entrada de Zilliz en ese carril.
Conclusión
Milvus Skill y Zilliz Cloud Skill se apoyan en cuatro decisiones de diseño en común:
- Las dos Skills tienen roles claros y no superpuestos. Milvus Skill gestiona la capa de codificación con SDK; Zilliz Cloud Skill gestiona la capa de operaciones con CLI. Juntas, cubren todo el ciclo de vida de la base de datos vectorial sin interferir entre sí.
- La carga modular de conocimiento mantiene el contexto ligero. Dividir el conocimiento entre 7 y 14 archivos de referencia permite que el agente extraiga solo el archivo que coincide con la tarea actual, en lugar de inundar la ventana de contexto con toda la documentación.
- Zilliz Cloud Skill incorpora seguridad en la capa de instrucciones. La confirmación de operaciones destructivas, la protección de credenciales y las verificaciones de prerrequisitos muestran que el equipo pensó cuidadosamente en lo que un agente con claves de Cloud puede hacer a una base de datos en producción.
- Zilliz está cubriéndose entre paradigmas, no eligiendo un ganador. Al lanzar implementaciones tanto de MCP como de Skill, Zilliz tiene cobertura cualquiera que sea la dirección que tome el ecosistema de integración de agentes.
Si estás creando agentes sobre una base de datos vectorial, instala ambas Skills la próxima vez que pongas en marcha una app RAG o gestiones un clúster.
Comienza
Instala las dos Skills en tu próxima sesión de Claude Code:
- Milvus Skill — corrección de pymilvus. Funciona con Milvus Lite, Standalone/Cluster autohospedado y Zilliz Cloud.
- Zilliz Cloud Skill — gestión de clústeres en vivo mediante
zilliz-cli. Instala la CLI junto con ella.
Si aún no tienes un clúster, regístrate en Zilliz Cloud (las cuentas nuevas con correo electrónico de trabajo reciben créditos gratuitos) o inicia sesión, luego pega la Skill en Claude Code, y el agente se encarga de lo demás.
Lecturas adicionales
- "¿Está muerto MCP?" — El enfoque de Zilliz sobre dónde se sitúan las CLI y las Skills junto a MCP.
- Milvus SDK Code Helper — Contraparte MCP de Milvus Skill, el mismo problema de pymilvus desactualizado desde un ángulo diferente.
claude-context— búsqueda semántica en bases de código que informa una reducción de tokens de ~40%.- Documentación de Milvus y Zilliz Cloud para toda la superficie del producto.
Sigue leyendo

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS