




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
Verwenden Sie diese Integration kostenlos
Die Kombination der Datenverarbeitung mit den Vektorsuchfunktionen von Milvus & Zilliz Cloud
Databricks ist eine einheitliche Analyseplattform zur Vereinfachung von Datenverarbeitung und maschinellen Lernaufgaben. Sie basiert auf Apache Spark, einem Open-Source-System für verteilte Datenverarbeitung. Sie bietet eine kollaborative Umgebung für Dateningenieure, Datenwissenschaftler und Analysten, die gemeinsam an Big-Data-Projekten arbeiten. Databricks abstrahiert die Komplexität der Verwaltung von Spark-Clustern, so dass sich die Benutzer auf die Datenanalyse und maschinelle Lernaufgaben konzentrieren können. Es bietet interaktive Notebooks, automatisierte Clusterverwaltung und integrierte Unterstützung für verschiedene Datenquellen und Bibliotheken für maschinelles Lernen. Insgesamt verbessert Databricks die Benutzerfreundlichkeit und Skalierbarkeit von Spark und macht es für Unternehmen einfacher, Erkenntnisse aus großen Datensätzen zu gewinnen.
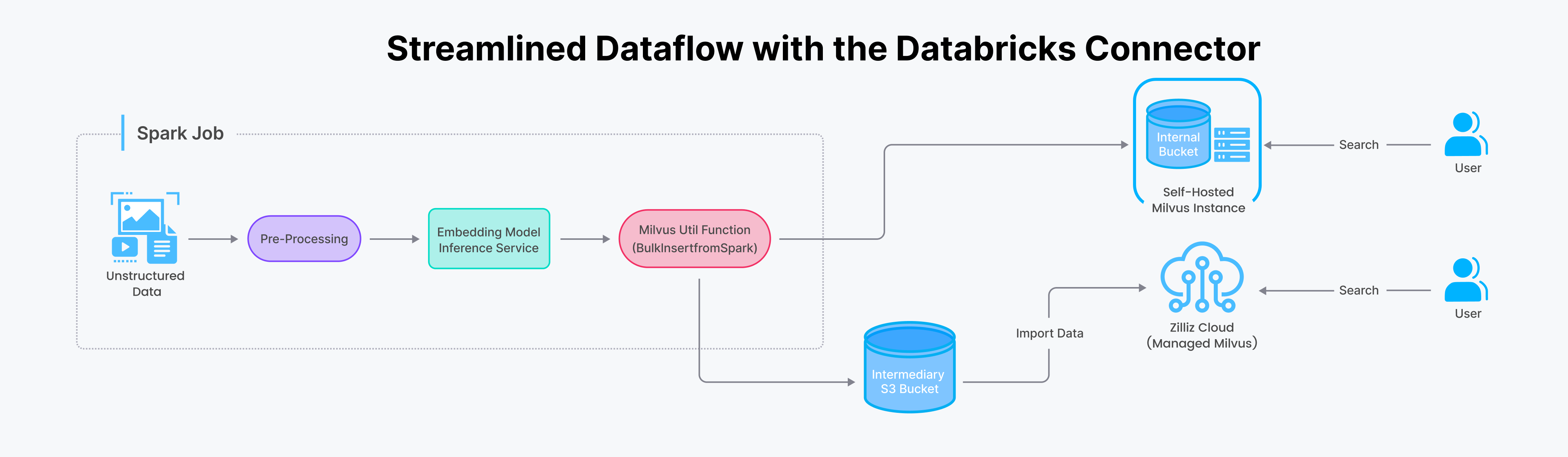
Der Spark Milvus Connector schafft Synergien zwischen Apache Spark und Milvus, so dass Benutzer die Verarbeitungsfähigkeiten von Spark zusammen mit den Vektordatenspeicher- und Abfragefunktionalitäten von Milvus nutzen können. Diese Integration erschließt eine Reihe wertvoller Anwendungen, wie z. B. die nahtlose Datenübertragung und Integration zwischen Milvus und verschiedenen Speichersystemen oder Datenbanken, die optimierte Datenverarbeitung und -analyse innerhalb von Milvus sowie effiziente Vektorverarbeitungsvorgänge unter Nutzung der Spark MLlib und anderer KI-Bibliotheken.
Derselbe Konnektor kann zwischen Zilliz Cloud und Databricks verwendet werden und vereinfacht den Übergang von Daten von der Offline-Verarbeitung zur Online-Verarbeitung, was für die KI-gesteuerte Suche wichtig ist.
Zu den wichtigsten Highlights der Integration gehören:
- Ermöglichung von vektorerzeugenden Spark-Jobs zum direkten Laden von Daten in Milvus mit einem einfachen Aufruf einer Utility-Funktion, wodurch die Notwendigkeit für benutzerdefinierten Glue-Code oder zusätzliche Spark-Jobs entfällt
- Direktes Einfügen von Spark DataFrame-Datensätzen in Milvus mit dem Spark-Milvus-Connector vereinfacht die Integration, da kein Code für den Verbindungsaufbau und keine API-Aufrufe mehr erforderlich sind.
Wie es funktioniert
Lassen Sie uns in den Prozess der Übertragung von Daten von Spark zu Milvus eintauchen. Traditionell erforderte diese Aufgabe komplexen Backend-Glue-Code. Mit dem Spark-Milvus-Konnektor wird dies jedoch in einem einzigen Funktionsaufruf innerhalb Ihrer Spark-Anwendung rationalisiert.
 Streamlined Dataflow with the Databricks Connector.png
Streamlined Dataflow with the Databricks Connector.png
Mit dem Spark/Databricks Connector können Sie Daten auf zwei Arten in die Zilliz Cloud (oder Milvus) importieren: Streaming für Echtzeit-Updates und Batch für große Datensätze. In unseren Beispiel-Notebooks finden Sie eine Schritt-für-Schritt-Anleitung für die effektive Nutzung.
Lernen Sie, wie man die Sparks und Databricks Connectors verwendet
Schauen Sie sich diese Ressourcen an, die Ihnen den Einstieg in die Nutzung von Zilliz Cloud, Spark und Databricks Connectors erleichtern
Spark Milvus Connector
Databricks Connector