




Zilliz bei CalHacks 2023
Ich schreibe dies aus dem Herzen von San Franciscos Metreon an einem sonnigen Sonntagnachmittag. Seit Freitagnachmittag (27.–29. Okt.) läuft CalHacks. Mit 137.650 $ Preisgeld plus Sponsorenauszeichnungen gab es:
1949 Personen im CalHacks-Slack-Chat während der Veranstaltung.
Über 1000 Studierende aus der ganzen Welt, die persönlich zusammenkamen, um zu hacken.
764 Studierende, die offiziell an der Veranstaltung teilnahmen.
240 eingereichte Wettbewerbsprojekte.
12 herausragende Projekte, die um Zilliz’ Sponsorenpreis „Best Use of Milvus“ konkurrierten.
 Bildquelle: CalHacks 2023.
Bildquelle: CalHacks 2023.
Wir haben gerade unsere Zilliz-Preise vergeben, und die Projekte waren innovativ und beeindruckend!
Best Use of Milvus - Erster Platz
Der erste Platz ging an das Projekt Second Search. Von
Catherine Jin (BS EECS ‘25 UC Berkeley)
Kanishk Garg (BS CS ‘24 University of Texas at Dallas)
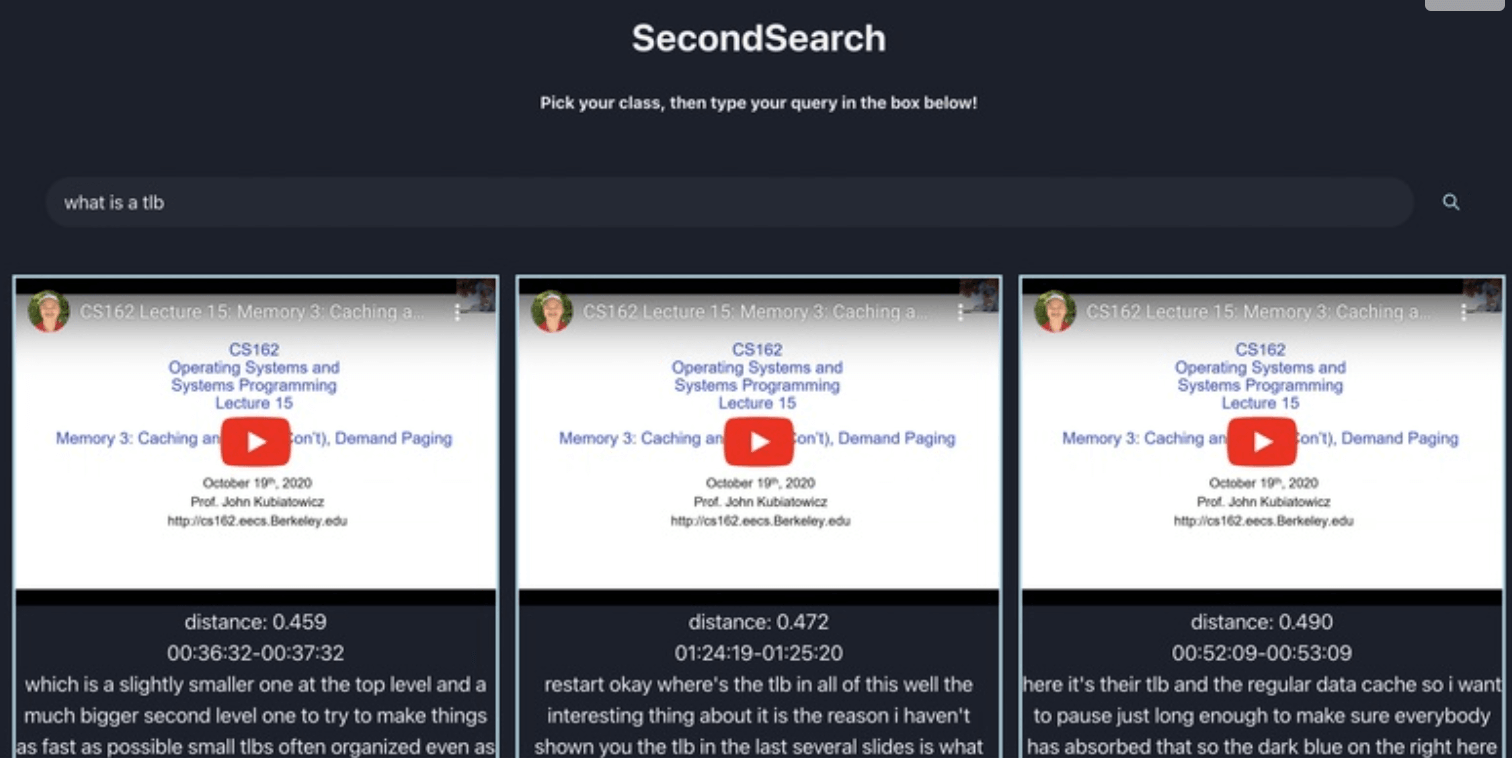
Was sie gemacht haben: Sie nahmen CS162-Vorlesungsvideos, die auf Youtube hochgeladen wurden. Dann nahmen sie den Untertiteltext dieser Videos, betteten den Text ein und speicherten die Einbettungsvektoren in Milvus.
Nutzer konnten ein Thema eingeben, über das sie etwas wissen wollten. Ich tippte „Explain LRU cache“. Mein Kollege tippte „Explain Linux sockets“. Die Suche gab 3 Videosegmente zurück. Jedes Video war mit der Sekunde in diesem Video verlinkt, in der der Professor das gesuchte Thema erklärte. Man musste nur auf „Play“ klicken, um diesen Abschnitt des Videos zu hören. Zusätzlich wurde unter dem Video eine Textzusammenfassung angezeigt, die 1) die Vektorsuch-Distanzmetrik, 2) den Zeitstempel im abgespielten Video, 3) eine Textzusammenfassung dessen zeigte, was der Professor in diesem Videosegment sagte.
Wir fanden, dass die UI einfach zu bedienen war, sich nach Echtzeit anfühlte (~1 Sekunde Antwortzeit), funktionierte (Videos mit relevanten Inhalten zeigte), Milvus auf kreative Weise nutzte und sehr nützlich klang! Wir würden ein solches Produkt gerne auf YouTube verfügbar sehen!
Wie sie es gebaut haben: Sie bauten SecondSearch auf einer lokal laufenden Open-Source-Vektordatenbank Milvus auf, nutzten OpenAI zur Generierung der Einbettungen und vervollständigten das Produkt dann mit einem begleitenden React-Frontend, das mit der Chakra UI-Komponentenbibliothek gebaut wurde. Das Backend wurde mit FastAPI erstellt, und die Milvus-Docker-Container wurden mithilfe von Jupyter-Notebooks befüllt. Milvus ist auf Zilliz (Cloud) sogar noch schneller, aber während des Hackathons gab es im Raum WLAN-Schwierigkeiten.
Best Use of Milvus - Zweiter Platz
Der zweite Platz ging an das Projekt Jarvis. Von
Dhruv Roongta (BS CS ‘27 Georgia Institute of Technology)
Arnav Chintawar (BS CS ‘27 Georgia Institute of Technology)
Shanttanu Oberoi (BTech Engineering Physics ‘26 IIT Bombay)
Sahib Singh (BS CS ‘27 Georgia Institute of Technology)
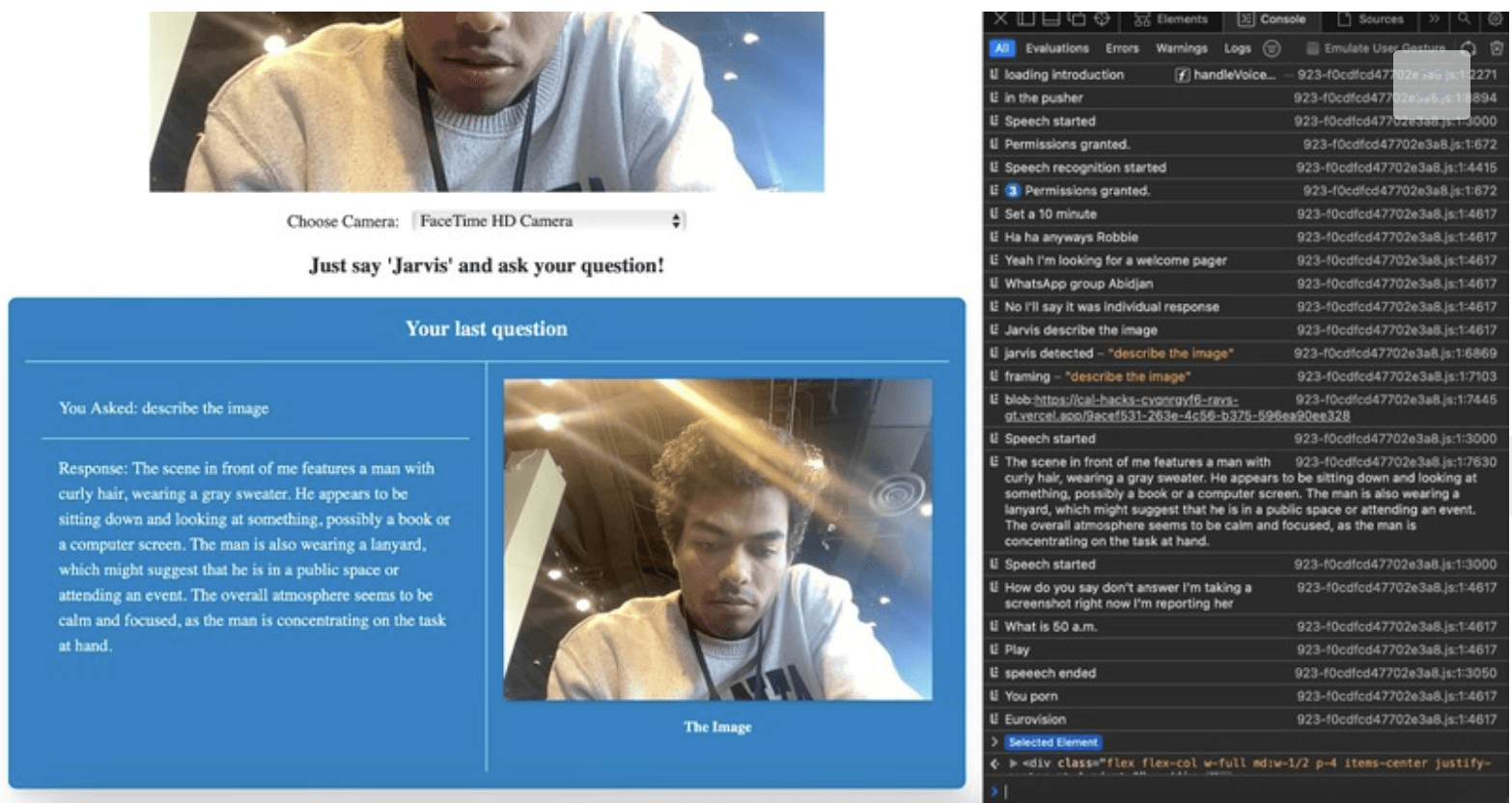
Was sie gemacht haben: Sie bauten ein System, das beschreibt, was eine Kamera sieht, basierend auf der Anfrage eines Nutzers oder auf Fragen dazu, was visuell vor sich geht. Die Anfrage des Nutzers wird per Speech-to-Text umgewandelt (ähnlich wie Siri/Alexa). Gleichzeitig wird das Bild der Kamera in Text umgewandelt. Schließlich kann Text-to-Speech einer sehbehinderten Person beschreiben, was vor sich geht.
Das Modell konnte Gesichtsausdrücke erkennen und blinden Menschen soziale Hinweise geben. Benutzer konnten Fragen stellen, die kritisches Denken erfordern könnten, etwa was sie von einer Speisekarte bestellen sollten oder wie sie sich auf komplexen Karten des öffentlichen Nahverkehrs zurechtfinden. Das System wurde auf Amazfit erweitert, sodass Benutzer mit einem einzigen Tastendruck eine Beschreibung ihrer Umgebung erhalten oder die Menschen um sie herum identifizieren konnten.
Ich ging zur Kamera, und sie konnte erkennen, dass ich eine Frau mit Brille war, vermutlich eine Richterin.
Wie sie es gebaut haben: Sie verwendeten Hume, LlaVa, OpenCV, Resnet-50 und next.js, um das Frontend zu erstellen, das mit ZeppOS unter Verwendung einer Amazfit-Smartwatch eingerichtet wurde. Sie nutzten Zilliz (Cloud), um Milvus online zu hosten, und speicherten einen Datensatz von Bildern und deren Vektor-Einbettungen. Jedes Bild wurde als Person klassifiziert, um mithilfe des Reverse-Image-Search-Tools von Zilliz ein Tool zur Identitätsklassifizierung zu erstellen. Es wurde ein Mindestschwellenwert festgelegt, unterhalb dessen die Identitäten von Personen nicht erkannt wurden, d. h. ihre Daten waren nicht in Zilliz. Die geschätzte Genauigkeit dieses Modells lag bei etwa 95 %.
Beste Nutzung von Milvus - Anerkennende Erwähnung Eins
Zeroth Responder von
Leo Liu (BS CS ‘26 U Michigan College of Engineering)
Brian Travis (BE CS ‘25 U Michigan College of Engineering)
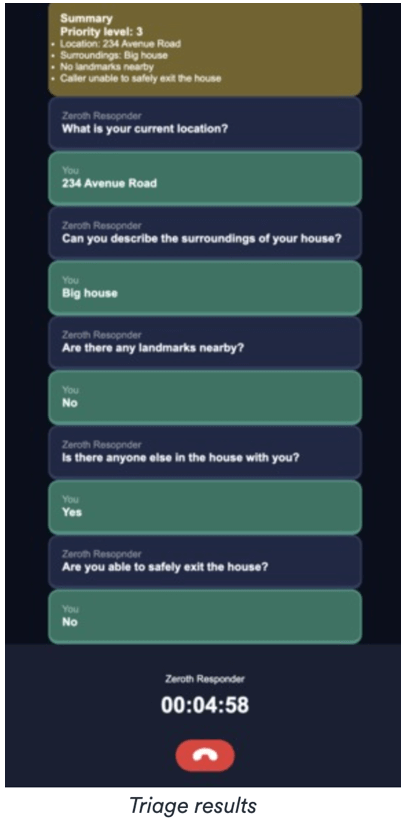
Was sie gemacht haben: Nach dem 911-Protokoll bauten sie einen KI-911-Agenten, der zuhört, was ein Anrufer sagt, um die Situation einzuschätzen, Folgefragen zu stellen, herauszufinden, ob jemand in unmittelbarer Gefahr ist, die Situation zu bewerten und zu klassifizieren und eine Dringlichkeit zuzuweisen. Diese Dringlichkeit wird als 0. Schritt genutzt, um die Zuweisung von Ressourcen zu priorisieren. Die Motivation war, dass es bei den jüngsten Bränden in Lahaina, HI, angeblich 45 Minuten dauerte, bis nach dem ersten gemeldeten Anruf Rettungsdienste entsandt wurden.
Während der Demo, bei der ein von Feuer eingeschlossener Anrufer aus Lahaina simuliert wurde, konnte dieses System die Gefahrensituation innerhalb von etwa 15 Sekunden einschätzen.
 calhacks-2023-image4.png
calhacks-2023-image4.png
Wie sie es gebaut haben: Sie speicherten PDFs des 911-Schulungshandbuchs in der Milvus-Vektordatenbank und fragten sie dann in Verbindung mit LLMs (OpenAI) ab, um Antworten an den Anrufer zu erstellen und die Situation einzuschätzen. Klassisches RAG-Muster. Lokaler Milvus-Server läuft auf Docker, unter Verwendung des node.js SDK. Full Stack: Client, Server und Milvus DB mit FastAPI und NextJS, aufgebaut auf React.
Beste Nutzung von Milvus - Anerkennende Erwähnung Zwei
Mental Maps von
Anirudh Pai (BS EECS ‘26 UC Berkeley)
Kushal Kodnad (BS EECS ‘26 UC Berkeley)
Rushil Desai (BS EECS ‘26 UC Berkeley)
Raghav Punnam (BS EECS ‘25 UC Berkeley)
Was sie gemacht haben: Sie entwickelten einen KI-Chatbot, der sich nach deinen Gefühlen und Erfahrungen erkundigt. Jede Interaktion wird einer Sentiment-Analyse unterzogen, wodurch die App die vorherrschende Stimmung des Benutzers extrahieren kann. Am Ende jeder Woche analysiert die Anwendung deine Emotionen, erstellt wöchentliche Zusammenfassungen und hilft dir, ein besseres Verständnis deines mentalen Wohlbefindens zu gewinnen — alles mit dem Ziel, Selbstbewusstsein zu fördern und eine bessere mentale Gesundheit zu unterstützen.
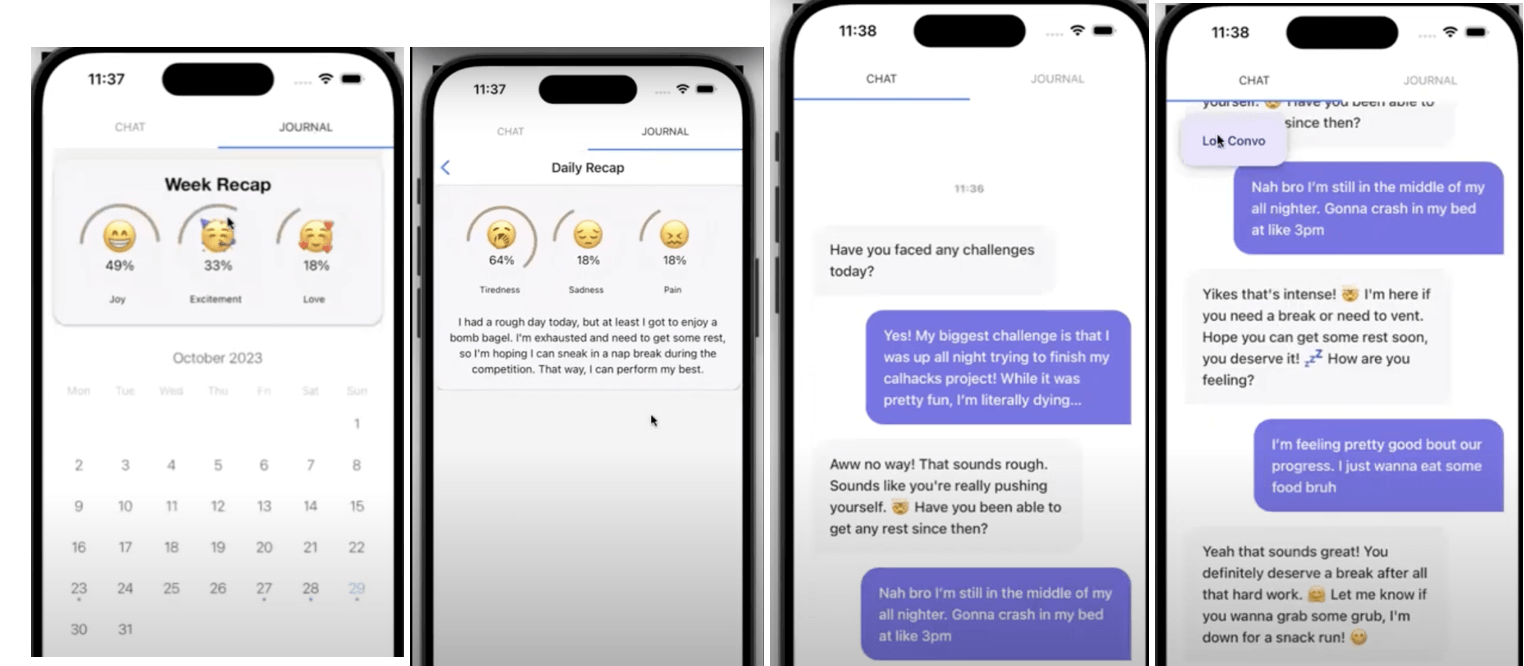
Wie sie es gebaut haben: Sie nutzten die Hume API für textbasierte Sentimentanalyse, um die emotionalen Reaktionen der Nutzer auf die Chat-Oberfläche jeden Tag zu erfassen. Das BERT Hugging Face-Modell wurde verwendet, um Nutzerantworten in hochdimensionale Vektoreinbettungen umzuwandeln, die mithilfe der Milvus-Vektordatenbank gespeichert wurden, wodurch Ähnlichkeitssuchen zwischen Antworten ermöglicht wurden. Für das Frontend nutzten sie React Native, um eine iOS-Anwendung zu erstellen. Der Frontend-Flask-REST-Server verwendete "axios" zum Senden von HTTP-Anfragen. Die Anwendungsnavigation wurde mit Datenbank-Navigationsroutern gesteuert, die Nutzersitzungen sicher speichern.
Vielen Dank an alle Organisatoren von CalHacks! Wir waren von all den Projekten wirklich beeindruckt, und unsere Sponsoring-Erfahrung mit Zilliz war fantastisch (besonderer Dank an Chris Churilo dafür, dass er uns einbezogen hat, und an Chris Chou, den Sponsorenorganisator von CalHacks).
 Oben links: Workshop in einem Kino. Rechts: Chris Churilo am Sponsorentisch von Zilliz. Unten links: Zilliz-Swag-Socken, Bild vom Autor. Alle anderen Bildquellen: CalHacks 2023.
Oben links: Workshop in einem Kino. Rechts: Chris Churilo am Sponsorentisch von Zilliz. Unten links: Zilliz-Swag-Socken, Bild vom Autor. Alle anderen Bildquellen: CalHacks 2023.

Weiterlesen

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.