




Paper-Lektüre|HM-ANN: Wenn ANNS auf heterogenen Speicher trifft
HM-ANN: Effiziente Nearest-Neighbor-Suche im Milliardenbereich auf heterogenem Speicher ist eine Forschungsarbeit, die auf der Conference on Neural Information Processing Systems 2020 (NeurIPS 2020) angenommen wurde. In dieser Arbeit wird ein neuartiger Algorithmus für graphbasierte Ähnlichkeitssuche namens HM-ANN vorgeschlagen. Dieser Algorithmus berücksichtigt sowohl Speicherheterogenität als auch Datenheterogenität in einer modernen Hardwareumgebung. HM-ANN ermöglicht Ähnlichkeitssuche im Milliardenmaßstab auf einer einzelnen Maschine ohne Kompressionstechnologien. Heterogener Speicher (HM) stellt die Kombination aus schnellem, aber kleinem Dynamic Random-Access Memory (DRAM) und langsamem, aber großem persistentem Speicher (PMem) dar. HM-ANN erreicht niedrige Suchlatenz und hohe Suchgenauigkeit, insbesondere wenn der Datensatz nicht in DRAM passt. Der Algorithmus hat einen deutlichen Vorteil gegenüber den modernsten Lösungen für Approximate-Nearest-Neighbor-(ANN)-Suche.
Motivation
Seit ihrer Entstehung weisen ANN-Suchalgorithmen aufgrund der begrenzten DRAM-Kapazität einen grundlegenden Zielkonflikt zwischen Abfragegenauigkeit und Abfragelatenz auf. Um Indizes für schnellen Abfragezugriff in DRAM zu speichern, ist es notwendig, die Anzahl der Datenpunkte zu begrenzen oder komprimierte Vektoren zu speichern, was beides die Suchgenauigkeit beeinträchtigt. Graphbasierte Indizes (z. B. Hierarchical Navigable Small World, HNSW) bieten eine überlegene Abfragelaufzeitleistung und Abfragegenauigkeit. Diese Indizes können jedoch auch DRAM im Bereich von 1 TiB verbrauchen, wenn sie auf Datensätzen im Milliardenmaßstab arbeiten.
Es gibt andere Umgehungslösungen, um zu vermeiden, dass DRAM Datensätze im Milliardenmaßstab im Rohformat speichern muss. Wenn ein Datensatz zu groß ist, um auf einer einzelnen Maschine in den Speicher zu passen, werden komprimierte Ansätze wie Produktquantisierung der Punkte des Datensatzes verwendet. Der Recall dieser Indizes mit dem komprimierten Datensatz ist jedoch normalerweise gering, da während der Quantisierung Präzision verloren geht. Subramanya et al. [1] untersuchen die Nutzung von Solid-State-Drives (SSD), um ANN-Suche im Milliardenmaßstab mit einer einzelnen Maschine durch einen Ansatz namens Disk-ANN zu erreichen, bei dem der Rohdatensatz auf SSD und die komprimierte Darstellung in DRAM gespeichert wird.
Einführung in heterogenen Speicher
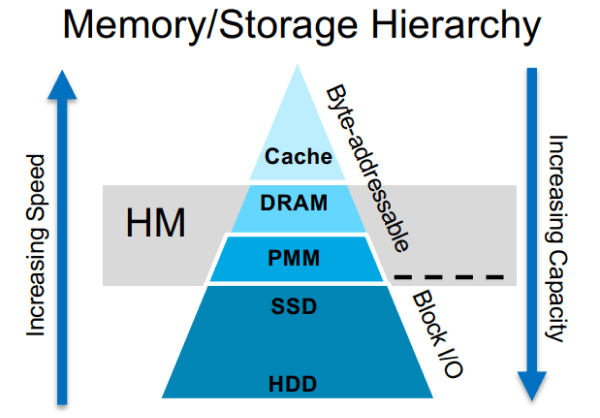 Name des Bildes Speicher-/Storage-Hierarchie mit HMxx
Name des Bildes Speicher-/Storage-Hierarchie mit HMxx
Name des Bildes Speicher-/Storage-Hierarchie mit HMxx
Quelle: http://nvmw.ucsd.edu/nvmw2021-program/nvmw2021-data/nvmw2021-paper63-presentation_slides.pdf
Heterogener Speicher (HM) stellt die Kombination aus schnellem, aber kleinem DRAM und langsamem, aber großem PMem dar. DRAM ist normale Hardware, die in jedem modernen Server zu finden ist, und der Zugriff darauf ist relativ schnell. Neue PMem-Technologien, wie Intel® Optane™ DC Persistent Memory Modules, schließen die Lücke zwischen NAND-basiertem Flash (SSD) und DRAM und beseitigen den I/O-Engpass. PMem ist langlebig wie SSD und wie Speicher direkt von der CPU adressierbar. Renen et al. [2] stellen fest, dass die PMem-Lesebandbreite in der konfigurierten Experimentumgebung 2,6× niedriger und die Schreibbandbreite 7,5× niedriger ist als bei DRAM.
HM-ANN-Design
HM-ANN ist ein genauer und schneller ANN-Suchalgorithmus im Milliardenmaßstab, der ohne Kompression auf einer einzelnen Maschine läuft. Das Design von HM-ANN verallgemeinert die Idee von HNSW, dessen hierarchische Struktur auf natürliche Weise zu HM passt. HNSW besteht aus mehreren Schichten—nur Schicht 0 enthält den gesamten Datensatz, und jede verbleibende Schicht enthält eine Teilmenge von Elementen aus der direkt darunterliegenden Schicht.
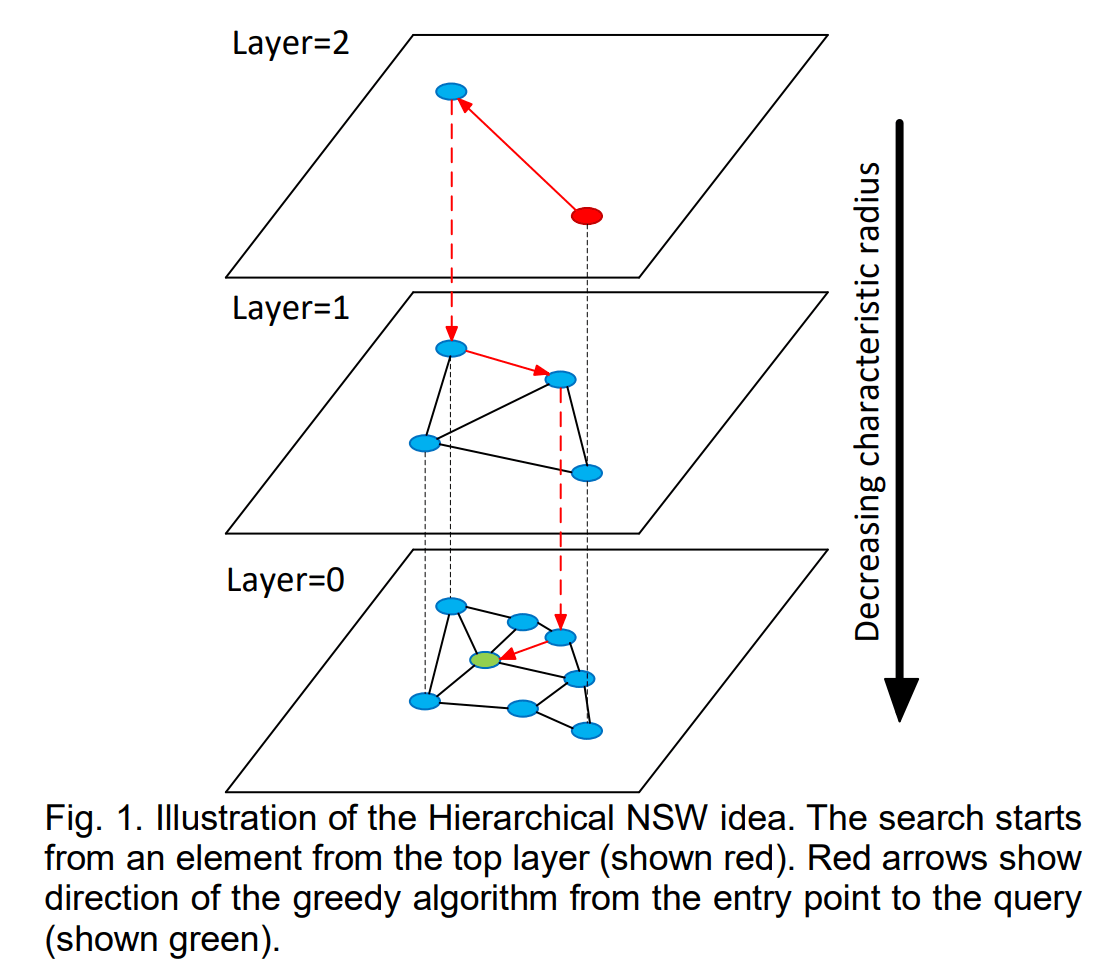 Ein Beispiel für HNSW mit 3 Schichten
Ein Beispiel für HNSW mit 3 Schichten
Quelle: https://arxiv.org/pdf/1603.09320.pdf
- Elemente in den oberen Schichten, die nur Teilmengen des Datensatzes enthalten, verbrauchen nur einen kleinen Teil des gesamten Speichers. Diese Beobachtung macht sie zu geeigneten Kandidaten für die Platzierung im DRAM. Auf diese Weise wird erwartet, dass die Mehrheit der Suchen auf HM-ANN in den oberen Schichten stattfindet, was die Nutzung der schnellen Zugriffseigenschaft von DRAM maximiert. In den Fällen von HNSW finden jedoch die meisten Suchen in der untersten Schicht statt.
- Die unterste Schicht enthält den gesamten Datensatz, wodurch sie sich für die Platzierung in PMem eignet. Da der Zugriff auf Schicht 0 langsamer ist, ist es vorzuziehen, dass pro Abfrage nur ein kleiner Teil darauf zugreift und die Zugriffshäufigkeit reduziert wird.
Graph-Konstruktionsalgorithmus
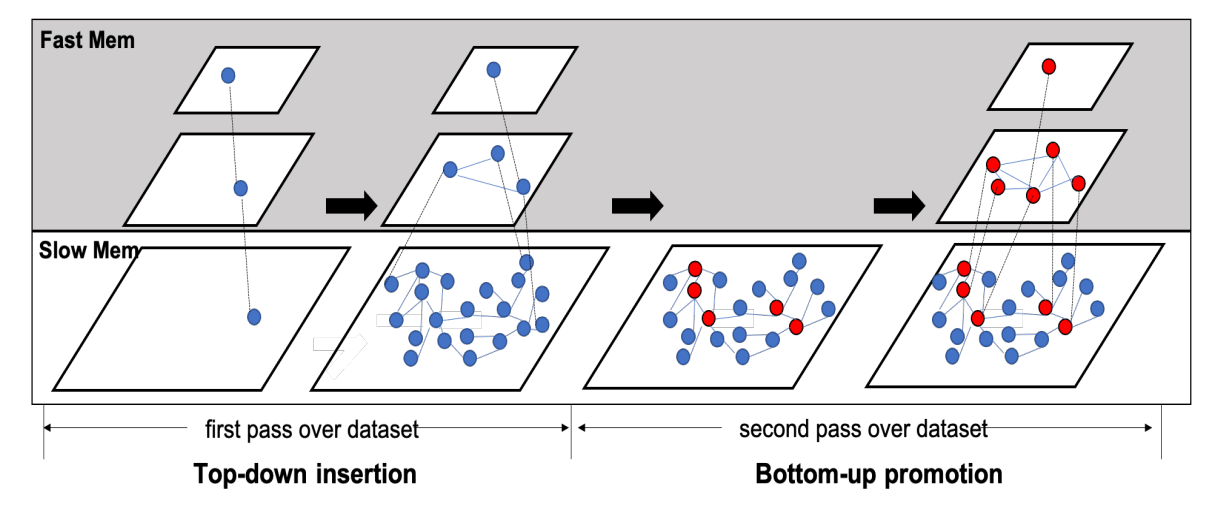 Ein Beispiel für die Graph-Konstruktion von HM-ANN
Ein Beispiel für die Graph-Konstruktion von HM-ANN
Quelle: http://nvmw.ucsd.edu/nvmw2021-program/nvmw2021-data/nvmw2021-paper63-poster.pdf
Die Kernidee der Konstruktion von HM-ANN besteht darin, hochwertige obere Schichten zu erstellen, um eine bessere Navigation für die Suche in Schicht 0 bereitzustellen. Dadurch findet der meiste Speicherzugriff im DRAM statt, und der Zugriff auf PMem wird reduziert. Um dies zu ermöglichen, verfügt der Konstruktionsalgorithmus von HM-ANN über eine Top-down-Einfügephase und eine Bottom-up-Promotion-Phase.
Die Top-down-Einfügephase erstellt einen navigierbaren Small-World-Graphen, während die unterste Schicht auf dem PMem platziert wird.
Die Bottom-up-Promotion-Phase befördert Pivot-Punkte aus der unteren Schicht, um obere Schichten zu bilden, die im DRAM platziert werden, ohne viel Genauigkeit zu verlieren. Wenn in Schicht 1 eine hochwertige Projektion von Elementen aus Schicht 0 erstellt wird, findet die Suche in Schicht 0 die genauen nächsten Nachbarn der Abfrage mit nur wenigen Hops.
- Anstatt HNSWs zufällige Auswahl für die Promotion zu verwenden, nutzt HM-ANN eine High-Degree-Promotion-Strategie, um Elemente mit dem höchsten Grad in Schicht 0 in Schicht 1 zu befördern. Für höhere Schichten befördert HM-ANN Knoten mit hohem Grad basierend auf einer Promotion-Rate in die obere Schicht.
- HM-ANN befördert mehr Knoten von Schicht 0 nach Schicht 1 und legt eine größere maximale Anzahl von Nachbarn für jedes Element in Schicht 1 fest. Die Anzahl der Knoten in den oberen Schichten wird durch den verfügbaren DRAM-Speicher bestimmt. Da Schicht 0 nicht im DRAM gespeichert wird, erhöht eine dichtere Speicherung jeder im DRAM gespeicherten Schicht die Suchqualität.
Graph-Suchalgorithmus
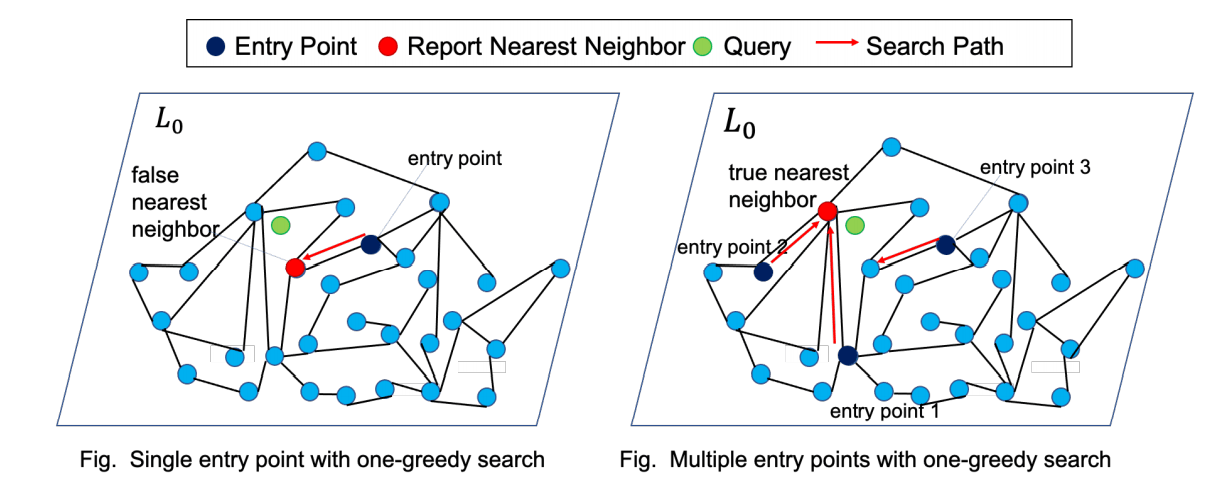 Ein Beispiel für die Graph-Suche von HM-ANN
Ein Beispiel für die Graph-Suche von HM-ANN
Quelle: http://nvmw.ucsd.edu/nvmw2021-program/nvmw2021-data/nvmw2021-paper63-poster.pdf
Der Suchalgorithmus besteht aus zwei Phasen: schnelle Speichersuche und parallele Schicht-0-Suche mit Prefetching.
Schnelle Speichersuche
Wie bei HNSW beginnt die Suche im DRAM am Einstiegspunkt in der obersten Schicht und führt dann eine 1-greedy-Suche von oben bis Schicht 2 durch. Um den Suchraum in Schicht 0 einzugrenzen, führt HM-ANN die Suche in Schicht 1 mit einem Suchbudget mit efSearchL1 durch, das die Größe der Kandidatenliste in Schicht 1 begrenzt. Diese Kandidaten der Liste werden als mehrere Einstiegspunkte für die Suche in Schicht 0 verwendet, um die Suchqualität in Schicht 0 zu verbessern. Während HNSW nur einen Einstiegspunkt verwendet, wird die Lücke zwischen Schicht 0 und Schicht 1 in HM-ANN spezieller behandelt als Lücken zwischen beliebigen anderen zwei Schichten.
Parallele Schicht-0-Suche mit Prefetching
In der untersten Schicht partitioniert HM-ANN die zuvor erwähnten Kandidaten aus der Suche in Schicht 1 gleichmäßig und betrachtet sie als Einstiegspunkte, um eine parallele Multi-Start-1-greedy-Suche mit Threads durchzuführen. Die besten Kandidaten aus jeder Suche werden gesammelt, um die besten Kandidaten zu finden. Wie bekannt, bedeutet das Hinabgehen von Schicht 1 zu Schicht 0 genau den Übergang zu PMem. Die parallele Suche verbirgt die Latenz von PMem und nutzt die Speicherbandbreite optimal aus, um die Suchqualität zu verbessern, ohne die Suchzeit zu erhöhen.
HM-ANN implementiert einen softwareverwalteten Puffer in DRAM, um Daten aus PMem vorab abzurufen, bevor der Speicherzugriff erfolgt. Beim Durchsuchen von Schicht 1 kopiert HM-ANN asynchron Nachbarelemente dieser Kandidaten in efSearchL1 sowie die Verbindungen der Nachbarelemente in Schicht 1 von PMem in den Puffer. Wenn die Suche in Schicht 0 erfolgt, ist ein Teil der noch zuzugreifenden Daten bereits im DRAM vorab abgerufen, was die Latenz beim Zugriff auf PMem verbirgt und zu einer kürzeren Abfragezeit führt. Dies entspricht dem Designziel von HM-ANN, bei dem die meisten Speicherzugriffe im DRAM erfolgen und Speicherzugriffe in PMem reduziert werden.
Evaluation
In diesem Paper wird eine umfangreiche Evaluation durchgeführt. Alle Experimente werden auf einer Maschine mit Intel Xeon Gold 6252 CPU@2.3GHz durchgeführt. Sie verwendet DDR4 (96GB) als schnellen Speicher und Optane DC PMM (1.5TB) als langsamen Speicher. Fünf Datensätze werden evaluiert: BIGANN, DEEP1B, SIFT1M, DEEP1M und GIST1M. Für Tests im Milliardenmaßstab werden die folgenden Verfahren einbezogen: quantisierungsbasierte Methoden im Milliardenmaßstab (IMI+OPQ und L&C), die nicht kompressionsbasierten Methoden (HNSW und NSG).
Algorithmusvergleich im Milliardenmaßstab
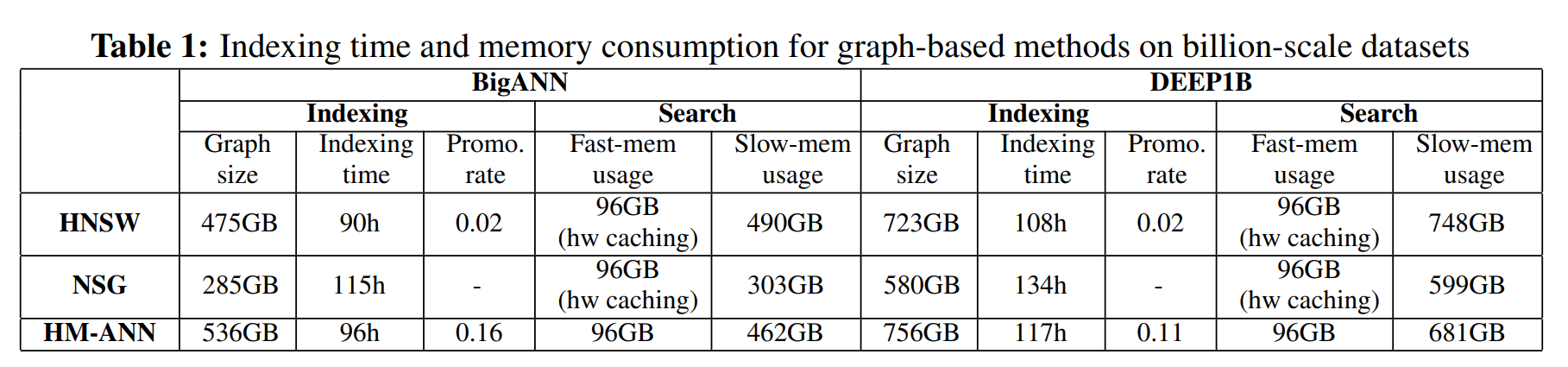 Table 1.
Table 1.
In Tabelle 1 werden die Erstellungszeit und der Speicherbedarf verschiedener graphbasierter Indizes verglichen. HNSW benötigt die kürzeste Erstellungszeit, und HM-ANN benötigt 8% zusätzliche Zeit gegenüber HNSW. In Bezug auf die gesamte Speichernutzung sind HM-ANN-Indizes 5–13% größer als HSNW, da mehr Knoten von Schicht 0 auf Schicht 1 hochgestuft werden.
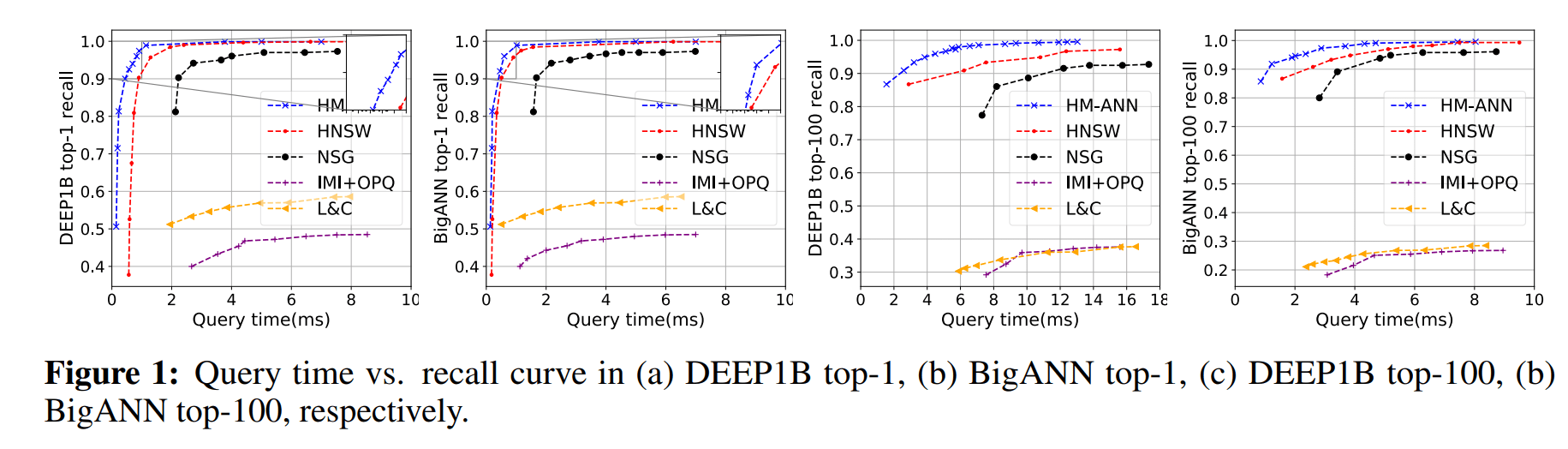 Figure 1.
Figure 1.
In Abbildung 1 wird die Abfrageleistung verschiedener Indizes analysiert. Abbildung 1 (a) und (b) zeigen, dass HM-ANN einen Top-1-Recall von > 95% innerhalb von 1ms erreicht. Abbildungen 1 (c) und (d) zeigen, dass HM-ANN einen Top-100-Recall von > 90% innerhalb von 4 ms erzielt. HM-ANN bietet die beste Latenz-vs-Recall-Leistung im Vergleich zu allen anderen Ansätzen.
Algorithmusvergleich im Millionenmaßstab
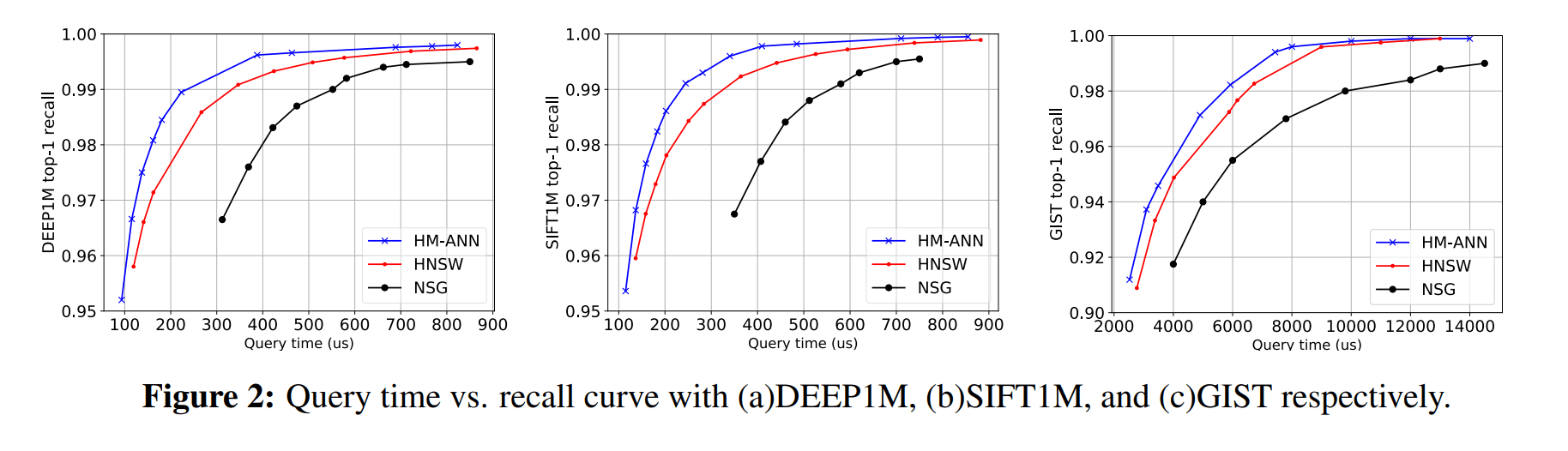 Figure 2.
Figure 2.
In Abbildung 2 wird die Abfrageleistung verschiedener Indizes in einer reinen DRAM-Umgebung analysiert. HNSW, NSG und HM-ANN werden mit den drei Datensätzen im Millionenmaßstab evaluiert, die in DRAM passen. HM-ANN erzielt weiterhin eine bessere Abfrageleistung als HNSW. Der Grund ist, dass die Gesamtzahl der Distanzberechnungen von HM-ANN niedriger ist (durchschnittlich 850/Abfrage) als die von HNSW (durchschnittlich 900/Abfrage), um das Recall-Ziel von 99% zu erreichen.
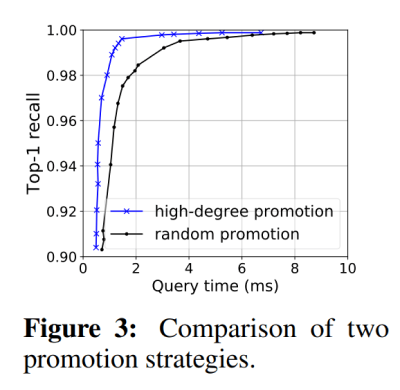
Wirksamkeit der High-Degree-Promotion
In Abbildung 3 werden die Strategien der zufälligen Promotion und der High-Degree-Promotion in derselben Konfiguration verglichen. Die High-Degree-Promotion übertrifft die Baseline. Die High-Degree-Promotion ist 1.8x, 4.3x bzw. 3.9x schneller als die zufällige Promotion, um Recall-Ziele von 95%, 99% und 99.5% zu erreichen.
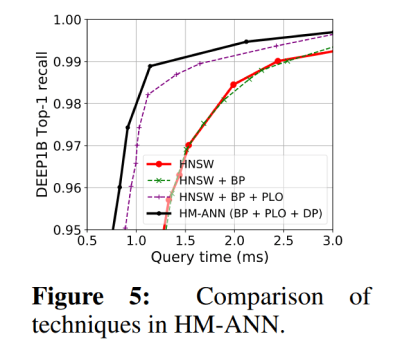
Leistungsvorteil von Speicherverwaltungstechniken
Abbildung 5 enthält eine Reihe von Schritten zwischen HNSW und HM-ANN, um zu zeigen, wie jede Optimierung von HM-ANN zu seinen Verbesserungen beiträgt. BP steht für die Bottom-up Promotion beim Aufbau des Index. PL0 steht für die parallele Schicht-0-Suche, während DP für das Vorabrufen von Daten von PMem nach DRAM steht. Schritt für Schritt wird die Suchleistung von HM-ANN weiter gesteigert.
Fazit
Ein neuer graphbasierter Indexierungs- und Suchalgorithmus namens HM-ANN bildet das hierarchische Design der graphbasierten ANNs auf die Speicherheterogenität in HM ab. Evaluationen zeigen, dass HM-ANN zu den neuen State-of-the-Art-Indizes bei Datensätzen mit einer Milliarde Punkten gehört.
Wir beobachten sowohl in der Wissenschaft als auch in der Industrie einen Trend, bei dem der Aufbau von Indizes auf persistenten Speichergeräten im Mittelpunkt steht. Um den Druck auf DRAM zu verringern, ist Disk-ANN [1] ein auf SSD aufgebauter Index, dessen Durchsatz deutlich niedriger ist als der von PMem. Der Aufbau von HM-ANN dauert jedoch immer noch einige Tage, wobei im Vergleich zu Disk-ANN keine großen Unterschiede festgestellt werden. Wir glauben, dass es möglich ist, die Aufbauzeit von HM-ANN zu optimieren, wenn wir die Eigenschaften von PMem sorgfältiger nutzen, z. B. indem wir uns der Granularität von PMem (256 Bytes) bewusst sind und Streaming-Instruktionen verwenden, um Cachelines zu umgehen. Wir glauben auch, dass in Zukunft weitere Ansätze mit dauerhaften Speichergeräten vorgeschlagen werden.
Referenz
[1]: Suhas Jayaram Subramanya and Devvrit and Rohan Kadekodi and Ravishankar Krishaswamy and Ravishankar Krishaswamy: DiskANN: Schnelle, präzise Milliarden-Punkte-Suche nach nächsten Nachbarn auf einem einzelnen Knoten, NIPS, 2019
DiskANN: Schnelle, präzise Milliarden-Punkte-Suche nach nächsten Nachbarn auf einem einzelnen Knoten
[2]: Alexander van Renen and Lukas Vogel and Viktor Leis and Thomas Neumann and Alfons Kemper: Persistent Memory I/O Primitives, CoRR & DaMoN, 2019
Weiterlesen

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.