




Von Text zu Bild: Grundlagen von CLIP
Eilmeldung: Jugendliche wenden sich TikTok als ihrer bevorzugten Suchmaschine zu, und offenbar funktioniert das besser, als man denken würde. Das ist nicht überraschend, denn traditionelle Suchmaschinen finden nicht immer das, was man möchte. Besonders wenn du ein visueller Mensch bist wie ich, findest du Bilder und Videos wahrscheinlich viel intuitiver und angenehmer, als dich durch Textzeilen arbeiten zu müssen. Hast du dich jedoch schon einmal gefragt, wie Maschinen einen gegebenen Text verstehen und ihn mit den Bildern abgleichen, die sie zurückgeben?
In dieser Blogreihe stellen wir dir das Abrufen von Bildern auf Basis von Texten vor, also Text-to-Image-Dienste. Text-to-Image war schon immer eine wichtige crossmodale Anwendung, und die Branche verließ sich früher auf umständliche Lösungen, die eine riesige Menge nutzergenerierter Daten erfordern, um Bilder zu gruppieren und ihre semantischen Beziehungen herauszufinden. Das heißt, bis OpenAI letztes Jahr mit der Veröffentlichung von CLIP eine Bombe in der Branche platzen ließ. OpenAI nutzte eine erstaunliche Anzahl von 400 Millionen Text-Bild-Paaren, um CLIP zu entwickeln, damit es visuelle Konzepte auf Grundlage natürlicher Spracheingaben lernen kann. Jetzt müssen wir einige Grundkenntnisse kennenlernen, um die grundlegenden Komponenten von Suchalgorithmen, CLIP und Text-to-Image zu verstehen.
Suchalgorithmen und semantische Ähnlichkeit
Suchalgorithmen, ob traditionell oder neuartig, unimodal oder crossmodal, kommen nicht ohne das Maß der semantischen Ähnlichkeit aus, oder besser gesagt, ohne die semantische Distanz zwischen zwei Dingen. Das mag ein wenig abstrakt klingen, also schauen wir uns ein paar Beispiele an. Beginnen wir mit dem eindimensionalen Raum der ganzen Zahlen, der dir wahrscheinlich seit der Grundschule in die DNA eingebrannt ist (auch wenn es damals wahrscheinlich nicht so formuliert wurde). Nun haben wir 5 positive ganze Zahlen {1, 5, 6, 8, 10}; sag mir, welche Zahl ist 5 am nächsten? Ja, es ist 6. Glückwunsch zum Abschluss deiner Kindheit. Der Grund ist, dass 6 die kürzeste Distanz zu 5 hat, nämlich 1. Die Distanz hier ist die semantische Distanz zwischen 5 und 6.
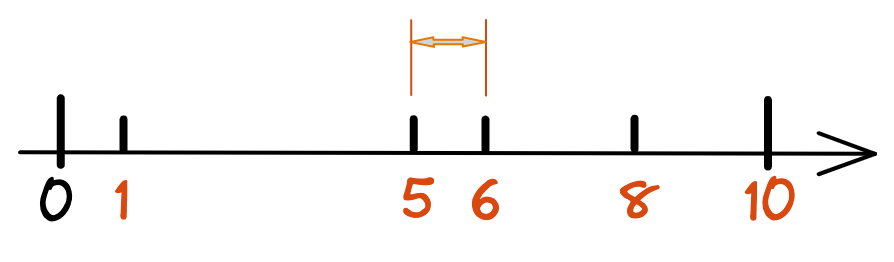 Abbildung 1 Ein eindimensionaler Raum ganzer Zahlen
Abbildung 1 Ein eindimensionaler Raum ganzer Zahlen
Da du dich nun im Bereich Machine Learning befindest, machen wir einen winzigen Schritt nach vorn, um zu sehen, wie traditionelle Textsuche funktioniert. Wenn du mit jemandem sprichst, der schon einmal Textsuche gemacht hat, wirst du höchstwahrscheinlich sehr oft TF-IDF hören. TF steht für term frequency, also Worthäufigkeit. Stell dir vor, es gibt einen hochdimensionalen Raum mit so vielen Dimensionen, wie es Wörter in einem Wörterbuch gibt. Wenn wir die Anzahl der Vorkommen jedes Wortes in einem Artikel zählen und diese Zahl als Wert in der entsprechenden Dimension dieses Raums festlegen, können wir jeden Artikel als eine Verteilung spärlicher Vektoren in diesem Wortvektorraum beschreiben (spärlich, weil ein Artikel in der Regel nur einen sehr kleinen Bruchteil der Wörter im Wörterbuch abdeckt).
 Abbildung 2 Eine Demonstration des Wortvektorraums
Abbildung 2 Eine Demonstration des Wortvektorraums
Das ist eine sehr einfache, aber praktische Denkweise. Wie oben gezeigt, sollten, wenn zwei Artikel in ihrem Bereich oder Inhalt ähnlich sind, die Vektoren, die diesen beiden Artikeln entsprechen, im Wortvektorraum nicht so weit voneinander entfernt sein. Wenn die beiden Artikel identisch sind, beträgt die Distanz zwischen ihren Wortvektoren 0. In der Textsuche erweitern wir den eindimensionalen Raum positiver ganzer Zahlen aus unserem ersten Beispiel zu einem hochdimensionalen Wortvektorraum, aber im Grunde verfolgen sie denselben Ansatz: einen Raum definieren, der verwendet werden kann, um die Semantik der Daten zu beschreiben und die Distanz zwischen ihnen zu bestimmen.
Machen wir einen weiteren winzigen Schritt (ja, du hast es kommen sehen). Da wir Texte nun erledigt haben, warum nicht auch die Semantik von Bildern in den Wortvektorraum abbilden, damit wir Text-Bild-Cross-Modalität erreichen können?
Aber natürlich ist es nicht so einfach. Texte liefern uns ihre Semantik im Grunde kostenlos: Sie haben „Wörter“ als natürliche semantische Einheit. Bilder haben das nicht. Wir können ihre einzelnen Pixel nicht verwenden, um ihre Bedeutungen zu definieren.
Das Rätsel der Vektorisierung ohne natürliche semantische Einheiten plagte früher den Bereich der Bildsuche und unstrukturierter Daten im Allgemeinen. Die meisten Datentypen (Bilder, Videos, Audio, Punktwolken usw.) verfügen nicht über natürliche semantische Einheiten. Es konnte nicht effektiv gelöst werden, bis Daten und Rechenleistung billig genug wurden und neuronale Netze populär wurden. Sehen wir uns an, wie dieses Problem durch neuronale Netze gelöst wird.
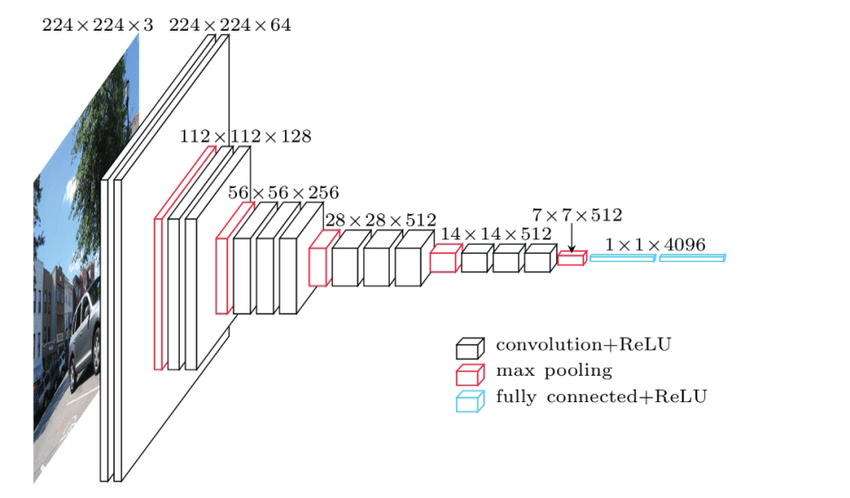 Figure 3 Convolutional Neural Network Layers and Architectures
Figure 3 Convolutional Neural Network Layers and Architectures
Eine der großartigen Eigenschaften eines tiefen neuronalen Netzes ist, dass es „tief genug“ ist (gern geschehen). In der obigen Abbildung ist die Eingabe links ein 224 x 224-Bild, und die Ausgabe rechts ist ein 4096-dimensionaler Vektor. Von links nach rechts durchläuft ein Bild viele Schichten des neuronalen Netzes, und das neuronale Netz komprimiert die räumlichen Informationen der Pixel des ursprünglichen Bildes schrittweise zu semantischen Informationen. In diesem Prozess können wir sehen, dass die räumliche Dimension schmaler wird, während die semantische Dimension länger wird (nicht die genaueste Aussage, aber ich habe keine bessere Formulierung gefunden). Im Wesentlichen ist dieser Prozess eine Abbildung der Semantik des Bildes auf einen reellen Vektorraum mit 4096 Dimensionen. Im Vergleich zu den zuvor beschriebenen Techniken hat die Vektorisierung über tiefe neuronale Netze mehrere offensichtliche Vorteile:
- Sie erfordert nicht, dass die Originaldaten natürliche, direkt segmentierbare semantische Einheiten wie „Wörter“ besitzen.
- Die Definition von „Datenähnlichkeit“ ist flexibel und wird durch die Trainingsdaten und die Zielfunktion bestimmt und kann an anwendungsspezifische Merkmale angepasst werden.
- Der Datenvektorisierungsprozess ist der Inferenzprozess des Modells, der hauptsächlich Matrixoperationen umfasst und die Beschleunigungsmöglichkeiten moderner GPUs nutzen kann.
Was CLIP getan hat, ist, Texte und Bilder modalitätsübergreifend zu verbinden. Auf der Datenseite hat OpenAI einen groß angelegten Datensatz von Text-Bild-Paaren entwickelt, WIT (WebImageText). Das Modell wird mit einem kontrastiven Lernansatz trainiert, um vorherzusagen, ob Bilder und Texte gepaart werden sollen. Sein Design ist recht einfach:
- Feature-Encoding für Texte bzw. Bilder durchführen;
- Text- und Bildmerkmale aus ihren jeweiligen unimodalen Merkmalsräumen in einen multimodalen Merkmalsraum projizieren;
- Innerhalb des multimodalen Raums sollte der Abstand zwischen den Merkmalsvektoren von Texten und Bildern, die Paare sein sollen (positive Stichproben), so gering wie möglich sein, und umgekehrt bei negativen Stichproben.
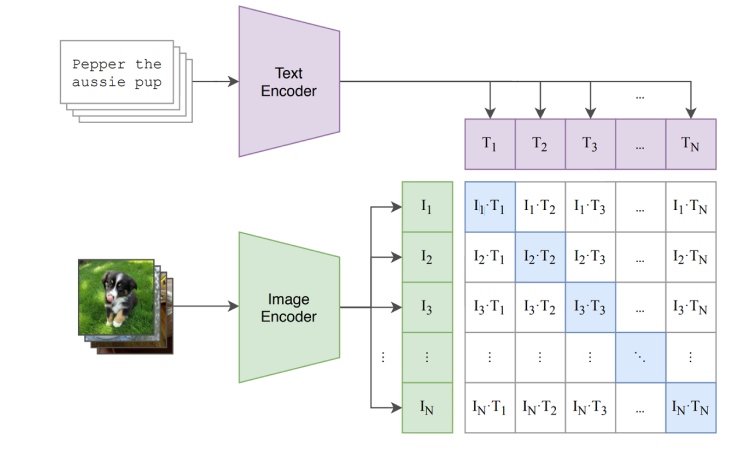 Figure 4 Learning Transferable Visual Models From Natural Language Supervision. Image source: https://arxiv.org/pdf/2103.00020.pdf
Figure 4 Learning Transferable Visual Models From Natural Language Supervision. Image source: https://arxiv.org/pdf/2103.00020.pdf
Der Schlüssel liegt hier im zweiten Schritt, nämlich darin, unimodale Merkmale aus Texten und Bildern durch die Projektionsschicht in einen multimodalen Merkmalsraum zu projizieren. Das bedeutet, dass wir die Semantik von Bildern und Texten in denselben hochdimensionalen Raum abbilden können. Dieser semantische Raum ist die Brücke, die CLIP für die modalitätsübergreifende Text-Bild-Suche bereithält. Jetzt können wir ein Stück beschreibenden Text als Vektor kodieren, die Vektoren von Bildern mit ähnlicher Semantik finden und dann über diese Bildvektoren das ursprüngliche Bild finden, das wir wollen!
Im Großen und Ganzen ist es dieselbe klassische Formel: Vektorraum plus semantische Ähnlichkeit. Die Bedeutung von CLIP besteht darin, dass es uns hilft, einen hochdimensionalen Raum zu schaffen, der die Semantik von Texten und Bildern vereinheitlicht, wobei gilt: Je ähnlicher die Semantik von Texten und Bildern ist, desto kleiner ist der Abstand zwischen den entsprechenden Vektoren.
Grundlegende Komponenten eines Text-zu-Bild-Dienstes
Ein typischer Text-zu-Bild-Dienst besteht aus drei Teilen: Anfrageseite (Texte), Suchalgorithmus (das „zu“) und zugrunde liegende Datenbanken (Bilder).
Die Datenbanken enthalten Originalbilder, ihre Vektoren und das Inferenzmodell, das die Originalbilder in semantische Vektoren kodiert. Entsprechend umfasst die Anfrageseite hauptsächlich das Inferenzmodell, das Texte in semantische Vektoren kodiert.
Der „zu“-Teil ist der Prozess, der Anfragen, die Vektordatenbank und die Bilddatenbank verbindet. Ein Text von der Anfrageseite wird durch ein Modell geleitet, um seinen Vektor zu erhalten, der dann in der Vektordatenbank mit den topK der ähnlichsten Bildvektoren verglichen wird. Ergebnisse werden zurückgegeben, sobald das Programm die Originalbilder findet, die den Vektoren entsprechen.
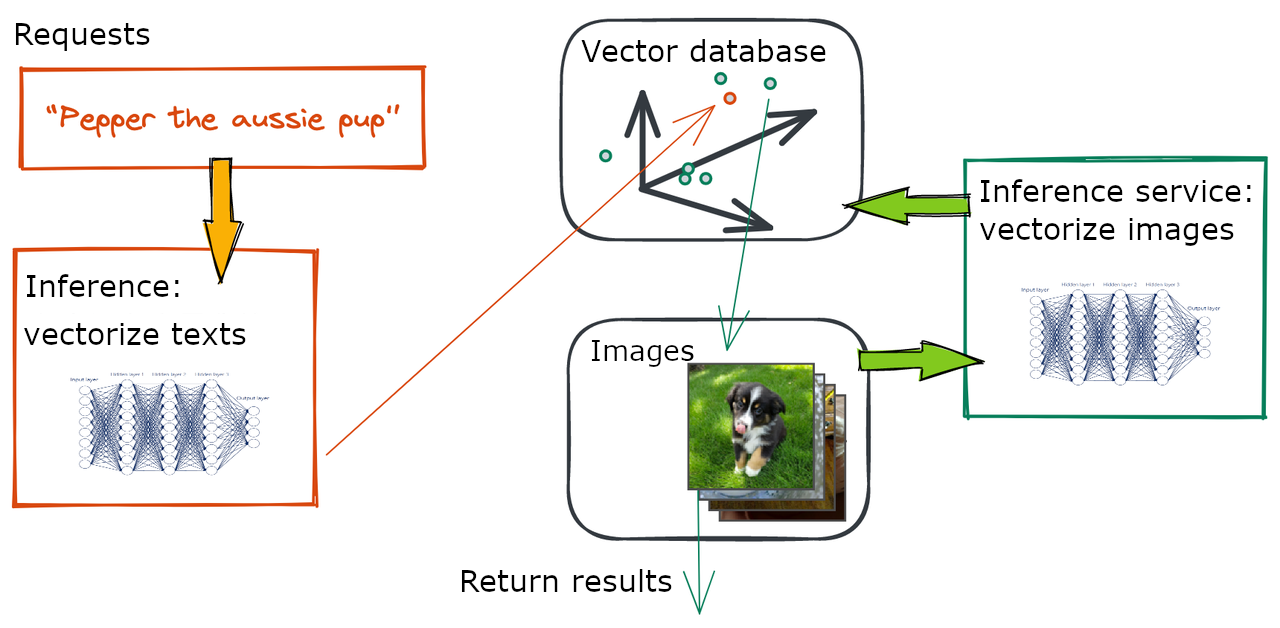 Abbildung 5 Grundkomponenten eines Text-zu-Bild-Dienstes
Abbildung 5 Grundkomponenten eines Text-zu-Bild-Dienstes
Fazit
Sie kennen nun die Grundlagen der Text-zu-Bild-Suche und von CLIP! Im nächsten Artikel werden wir das hier Gelernte praktisch anwenden, indem wir in nur fünf Minuten einen Prototyp eines Text-zu-Bild-Dienstes erstellen!
Wenn Ihnen dieser Artikel gefällt, schauen Sie sich doch unser Projekt an. Wir freuen uns über Sterne, Forks oder auch nur einen kleinen Klick von Ihnen. Stellen Sie uns auch gerne Ihre Fragen auf Slack!
Über die Reihe
„From Text to Image“ ist eine Blogreihe, die vorstellt, wie man CLIP verwendet, um einen groß angelegten Text-zu-Bild-Dienst aufzubauen, einschließlich:
- Verständnis von Suchalgorithmen, CLIP und Text-zu-Bild;
- Erstellung einer Text-zu-Bild-Demo in 5 Minuten;
- Fortgeschrittenes Thema 1: Bereitstellung einer Vektordatenbank für groß angelegten Vektorabruf
- Fortgeschrittenes Thema 2: Bereitstellung eines Inferenzdienstes, der es ermöglicht, über 1000 QPS an Inferenzanfragen zu verarbeiten
- Fortgeschrittenes Thema 3: Vektordatenkomprimierung

Weiterlesen

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.